




Understanding CoCa: Advancing Image-Text Foundation Models with Contrastive Captioners
Contrastive Captioners (CoCa) is an AI model developed by Microsoft that is designed to bridge the capabilities of language models and vision models.
Read the entire series
- Cross-Entropy Loss: Unraveling its Role in Machine Learning
- Batch vs. Layer Normalization - Unlocking Efficiency in Neural Networks
- Empowering AI and Machine Learning with Vector Databases
- Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
- Vector Databases: Redefining the Future of Search Technology
- Local Sensitivity Hashing (L.S.H.): A Comprehensive Guide
- Optimizing AI: A Guide to Stable Diffusion and Efficient Caching Strategies
- Nemo Guardrails: Elevating AI Safety and Reliability
- Data Modeling Techniques Optimized for Vector Databases
- Demystifying Color Histograms: A Guide to Image Processing and Analysis
- Exploring BGE-M3: The Future of Information Retrieval with Milvus
- Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
- TF-IDF - Understanding Term Frequency-Inverse Document Frequency in NLP
- Understanding Regularization in Neural Networks
- A Beginner's Guide to Understanding Vision Transformers (ViT)
- Understanding DETR: End-to-end Object Detection with Transformers
- Vector Database vs Graph Database
- What is Computer Vision?
- Deep Residual Learning for Image Recognition
- Decoding Transformer Models: A Study of Their Architecture and Underlying Principles
- What is Object Detection? A Comprehensive Guide
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Algorithmic)
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Methodological)
- Understanding CoCa: Advancing Image-Text Foundation Models with Contrastive Captioners
- Florence: An Advanced Foundation Model for Computer Vision by Microsoft
- The Potential Transformer Replacement: Mamba
- ALIGN Explained: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
Artificial intelligence has witnessed the rise of foundation models, large-scale systems pre-trained on vast datasets that can tackle multiple tasks through zero-shot, few-shot, or transfer learning. The success of models like BERT, T5, and GPT-3 in language processing has inspired researchers to develop similar approaches for vision and vision-language tasks. This quest has led to several strategies, each with strengths and limitations.
Pre-trained on image classification, single-encoder models provide strong visual representations but struggle with language-related tasks. Dual-encoder models, trained with contrastive losses on image-text pairs, can handle cross-modal retrieval but lack joint vision-language understanding for tasks like visual question answering. Encoder-decoder models with generative pretraining perform well in image captioning and multimodal understanding but fall short in cross-modal alignment tasks. These challenges in balancing performance across various tasks led to the development of CoCa, a model that aims to integrate the best of these strategies.
Contrastive Captioners (CoCa), introduced in the CoCa: Contrastive Captioners are Image-Text Foundation Models paper, aims to unify these approaches. By combining contrastive learning and generative captioning in a single architecture, CoCa addresses the limitations of previous methods.
CoCa has shown impressive results across various benchmark tests, often outperforming specialized models. It excels in zero-shot image classification, image-text retrieval, and image captioning. CoCa's performance also scales well with model size, suggesting potential for further improvements. Let’s explore CoCa's architecture, training process, and results, showing how it advances image-text foundation models and their applications in artificial intelligence.
Contrastive Captioners (CoCa): A Unified Approach
Contrastive Captioners (CoCa) is an AI model developed by Microsoft that is designed to bridge the capabilities of language models and vision models. This model combines elements of contrastive learning, a technique widely used in computer vision to learn effective representations by contrasting positive pairs against negative pairs, with powerful language modeling capabilities.
CoCa introduces a novel encoder-decoder architecture that combines the strengths of single-encoder, dual-encoder, and encoder-decoder paradigms. The key components of CoCa's architecture work together to effectively process visual and textual information.
CoCa Architecture Overview
The CoCa architecture, as illustrated below, consists of three main components: Image Encoders, Unimodal Text Decoders, and Multimodal Text Decoders.
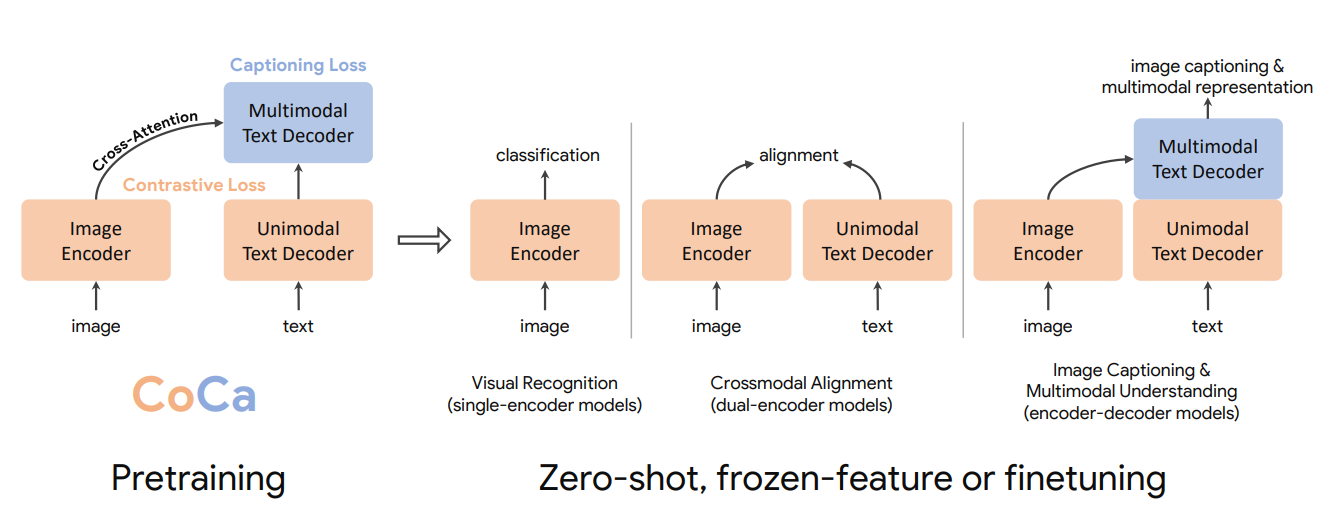 Figure 1- An overview of the pretraining process for Contrastive Captioners (CoCa) as foundational models for image-text understanding..png
Figure 1- An overview of the pretraining process for Contrastive Captioners (CoCa) as foundational models for image-text understanding..png
Figure 1: An overview of the pretraining process for Contrastive Captioners (CoCa) as foundational models for image-text understanding.
Let’s take a look at each component:
Image Encoder: This component processes the input image, similar to single-encoder models. It transforms the raw pixel data into embeddings that capture the visual content of the image.
Unimodal Text Decoder: The first part of the decoder processes text without looking at image features. This is similar to the text encoder in dual-encoder models allowing CoCa to create pure text representations.
Multimodal Text Decoder: The second part of the text decoder combines text and image information. Similar to encoder-decoder models, this enables joint vision-language understanding.
This unified architecture allows CoCa to be used for various downstream tasks with minimal adaptation. For example, the CoCa model is perfect for the following cases:
Visual Recognition: Using just the Image Encoder, CoCa can perform tasks like image classification and object detection.
Crossmodal Alignment: Using the Image Encoder and Unimodal Text Decoder, CoCa can perform tasks like image-text retrieval and zero-shot classification.
Image Captioning & Multimodal Understanding: Using the full encoder-decoder structure, CoCa can generate captions for images and answer questions about visual content.
Detailed Architecture and Training Objectives
To understand why CoCa excels across diverse tasks, let’s explore its architectural components and the training objectives that guide its learning process. Let’s start by looking at an illustration of CoCa architecture:
 Figure 2- In-depth depiction of the CoCa architecture along with its training goals.png
Figure 2- In-depth depiction of the CoCa architecture along with its training goals.png
Figure 2: In-depth depiction of the CoCa architecture along with its training goals
The image encoder encodes the input image into a set of embeddings. These embeddings are then used in two ways:
They are passed through an attentional pooling layer to create a single vector representation of the image for contrastive learning.
They are used as input to the multimodal text decoder for caption generation.
The unimodal text decoder first processes the text input, which creates a pure text representation without any influence from the image. This representation is used for the contrastive loss. The text then passes through the multimodal text decoder, combining the text representation with the image features through cross-attention mechanisms.
CoCa employs three core training objectives: Single-Encoder Classification, Dual-Encoder Contrastive Learning, and Encoder-Decoder Captioning. Each of these objectives contributes to CoCa's ability to handle image classification and text generation tasks effectively.
Single-Encoder Classification
In the classic single-encoder classification task, CoCa uses a cross-entropy loss to guide its learning process:
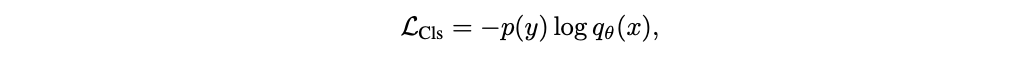 Figure 3- Cross-entropy loss formula.png
Figure 3- Cross-entropy loss formula.png
Figure 3: Cross-entropy loss formula
Where:
p(y)is the true label distribution, which could be a one-hot, multi-hot, or smoothed label distribution.q_θ(x)is the predicted probability distribution from the model.
Let's take a look at what the above true label distributions entail:
A one-hot distribution represents a single correct category for each image. For instance, if there are three possible categories, the ground truth label for a specific image might look like
[1, 0, 0]if the image belongs to the first category.A multi-hot distribution allows for multiple correct categories. This is used when an image can belong to more than one category. For example, the ground truth label might be
[1, 1, 0]if the image fits the first and second categories.A smoothed label distribution assigns probability mass to non-target labels to account for uncertainty or prevent overconfidence. It might be something like
[0.9, 0.05, 0.05]for three categories, instead of hard one-hot values.
This loss function measures the discrepancy between the true label distribution p(y) and the model’s prediction q_θ(x). Minimizing this loss ensures that CoCa learns to classify images accurately into predefined categories. This approach works well for visual recognition tasks but doesn't incorporate free-form text descriptions, leading to the second objective.
Dual-Encoder Contrastive Learning
CoCa uses a contrastive loss to align image and text representations in a shared embedding space. The contrastive loss function is defined as:
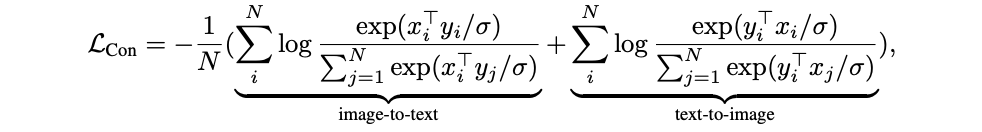 Figure 4- contrastive loss function formula.png
Figure 4- contrastive loss function formula.png
Figure 4: contrastive loss function formula
Where:
x_iandy_jare normalized image and text embeddings, respectively, for the i-th and j-th pairs.Nis the batch size.σis the temperature parameter that controls the concentration of the distribution.
This loss function encourages the model to align the image and text embeddings. It has two components:
Image-to-text matching: This term maximizes the similarity between an image x_i and its corresponding text y_i, while minimizing its similarity with other texts y_j in the batch.
log( exp(x_i^T * y_i / σ) / Σ_j^N exp(x_i^T * y_j / σ) )
Text-to-image matching: This term maximizes the similarity between a text y_i and its corresponding image x_i, while minimizing its similarity with other images x_j.
log( exp(y_i^T * x_i / σ) / Σ_j^N exp(y_i^T * x_j / σ) )
Minimizing this loss encourages the model to assign high similarity scores to matching image-text pairs and low scores to non-matching pairs. The temperature parameter σ controls how confident the model is about its predictions, with lower values making it more confident.
Encoder-Decoder Captioning
For the captioning objective, CoCa uses a standard language modeling loss. The captioning loss is defined as:
 Figure 5- Captioning loss formula.png
Figure 5- Captioning loss formula.png
Figure 5: Captioning loss formula
Where:
y_tis the t-th token in the caption.y_<tare the previous tokens in the sequence.xrepresents the image.Tis the total number of tokens in the caption.
Given the image and previously generated tokens, this loss computes the negative log-likelihood of generating each token in a caption. By minimizing this loss, CoCa learns to generate accurate and coherent captions that describe the input images.
Combining the Losses: The CoCa Training Objective
The final CoCa objective integrates the contrastive and captioning losses into a single unified objective:
 Figure 6- Combining the Losses- The CoCa Training Objective.png
Figure 6- Combining the Losses- The CoCa Training Objective.png
Figure 6: Combining the Losses: The CoCa Training Objective
Where:
λ_Conandλ_Capare hyperparameters that balance the contributions of the contrastive and captioning losses.
This combined loss allows CoCa to learn both aligned representations (through contrastive learning) and generative capabilities (through captioning). The model can compute both losses in a single forward pass, thanks to its decoupled decoder architecture, where the tasks of localization and classification are separated within the decoder of a model. The unimodal decoder outputs are used for contrastive learning, and the multimodal decoder outputs are used for captioning. This architecture allows CoCa to handle multiple objectives efficiently without requiring separate forward passes.
By combining these training objectives, CoCa can efficiently perform tasks like image classification, caption generation, and the alignment of image-text pairs, making it a versatile model for multimodal AI tasks.
CoCa Training Process
With a clear architectural foundation, CoCa's training process ensures that it learns representations from diverse data sources. The model is trained on a combination of two large-scale datasets:
JFT-3B dataset: This is a large collection of images with associated labels. The labels are treated as short text descriptions, allowing CoCa to learn from a diverse set of image-text pairs.
ALIGN dataset: This dataset provides images with associated alt-text descriptions, offering more natural language supervision.
The training process uses a batch size of 65,536 image-text pairs, half of which come from JFT and half from ALIGN. This large batch size allows effective contrastive learning, providing a rich set of negative examples for each positive image-text pair.
CoCa is trained for 500,000 steps, which corresponds to approximately 5 epochs on JFT and 10 epochs on ALIGN. This extensive training allows the model to learn robust and generalizable representations.
The optimization process uses the Adafactor optimizer, which is designed to be memory-efficient for large-scale training. The optimizer parameters are set to β1 = 0.9 and β2 = 0.999, with a weight decay 0.01. These settings help to stabilize training and prevent overfitting.
The learning rate schedule includes a warm-up period for the first 2% of training steps, followed by a linear decay. This schedule helps the model to converge effectively, starting with small updates and gradually increasing the learning rate before reducing it to fine-tune the final representations.
During pretraining, images are processed at a resolution of 288x288 pixels. After the main training phase, the model is further trained for one epoch at a higher resolution of 576x576. This final high-resolution training helps the model capture fine-grained visual details.
CoCa for Video Recognition
Beyond static images, CoCa's learned visual representations adapt well to dynamic data, allowing it to tackle video recognition tasks without architectural changes. The figure below illustrates how CoCa is adapted for video recognition.
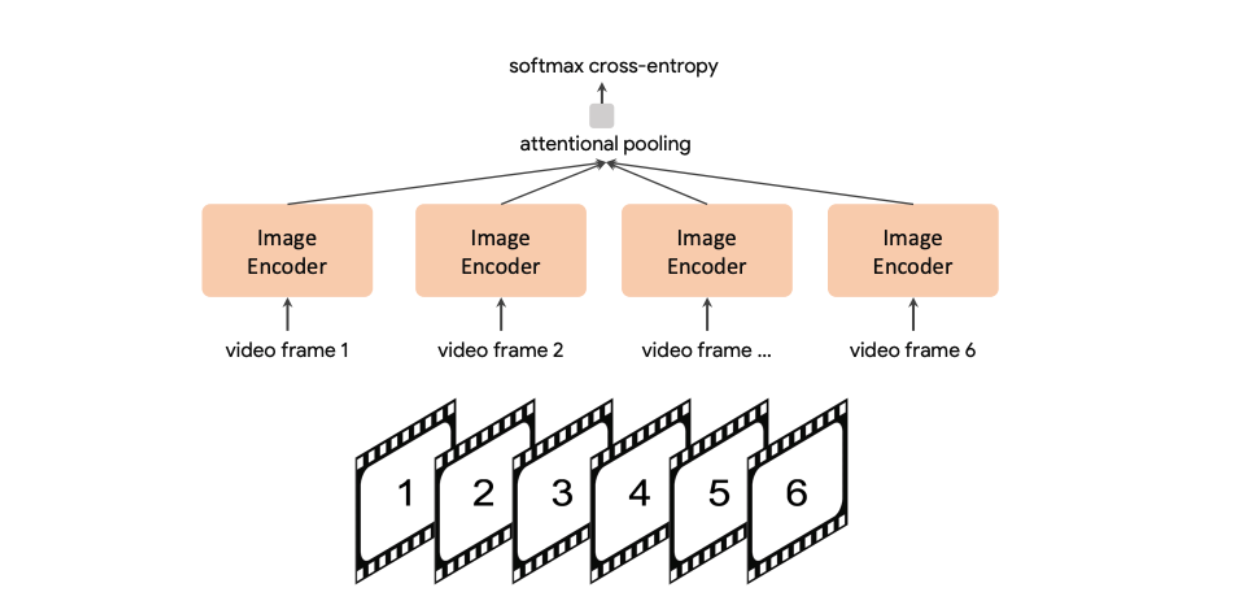 Figure 7- CoCa process for video recognition.png
Figure 7- CoCa process for video recognition.png
Figure 7: CoCa process for video recognition
Here is how the video recognition process works:
Individual frames from the video are processed by the Image Encoder. This allows CoCa to capture the visual content of each frame independently.
The outputs from multiple frames (six frames are shown in the figure) are combined using attentional pooling. This pooling mechanism allows the model to aggregate information across the temporal dimension of the video.
A softmax cross-entropy loss is applied to the pooled representation for classification. This trains the model to predict the action or content of the video based on the aggregated frame representations.
This approach to video recognition is simple yet effective. It demonstrates the flexibility of CoCa's learned representations, as they can be easily adapted to handle temporal data without requiring any architectural changes to the core model.
The effectiveness of this approach shows that the visual representations learned by CoCa capture fundamental visual features relevant to both static and dynamic visual inputs. This generalization capability is a key strength of the CoCa model.
Benchmark Results
The versatility of CoCa’s design is further evidenced by its performance on benchmark datasets, where it often surpasses specialized models. Here is a comprehensive comparison of CoCa with other image-text foundation and task-specialized models.
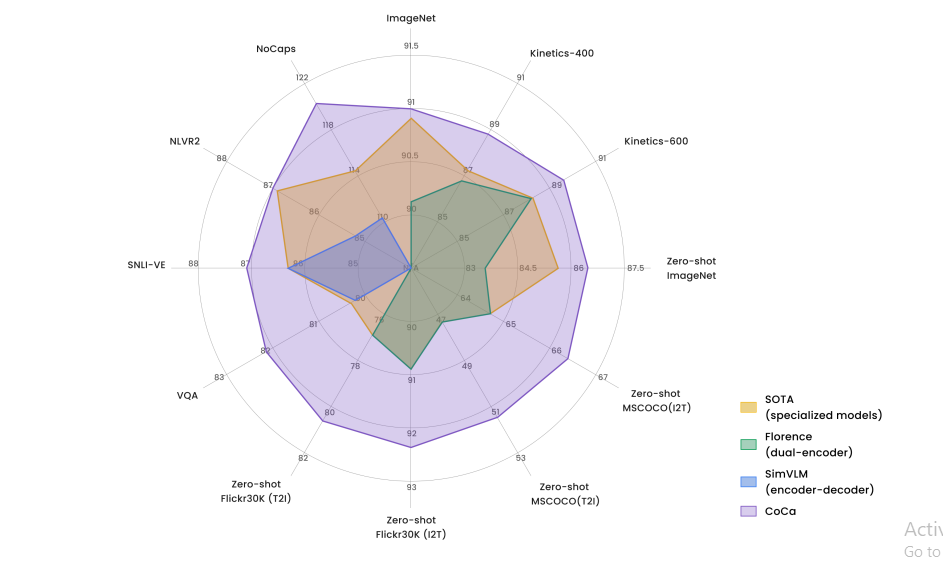 Figure 8- Comparison of CoCa with other image-text foundation models.png
Figure 8- Comparison of CoCa with other image-text foundation models.png
Figure 8: Comparison of CoCa with other image-text foundation models
Let's take a look at some of the key results:
ImageNet Classification: CoCa achieves impressive results on the ImageNet classification task, which is a standard benchmark for image recognition models. In zero-shot classification, where the model must classify images into categories it wasn't explicitly trained on, CoCa achieves 86.3% top-1 accuracy. This demonstrates the model's ability to transfer its learned representations to new tasks without additional training.
With a frozen encoder and a learned classification head, CoCa reaches 90.6% top-1 accuracy. This shows that the representations learned during pretraining are highly effective for image classification, even without fine-tuning the entire model.
When fine-tuned on the ImageNet dataset, CoCa achieves a 91.0% top-1 accuracy. This result surpasses specialized image classification models, highlighting the power of CoCa's unified training approach.
Video Action Recognition: Despite being trained only on static images, CoCa performs remarkably well on video action recognition tasks. On the Kinetics-400 dataset, CoCa achieves 88.9% top-1 accuracy when fine-tuned. For Kinetics-600, it reaches 89.4% top-1 accuracy. On the challenging Moments-in-Time dataset, CoCa attains 49.0% top-1 accuracy. These results demonstrate CoCa's ability to generalize its learned representations to dynamic visual inputs.
Image-Text Retrieval: CoCa performs well in cross-modal retrieval tasks, which require aligning visual and textual representations. On the Flickr30K dataset (1K test set), CoCa achieves 92.5% recall@1 for image-to-text retrieval and 80.4% recall@1 for text-to-image retrieval. On the larger MSCOCO dataset (5K test set), CoCa reaches 66.3% recall@1 for image-to-text retrieval and 51.2% recall@1 for text-to-image retrieval. These results demonstrate CoCa's ability to create aligned representations across modalities.
Visual Question Answering: On the VQA v2 dataset, which requires understanding both visual and textual inputs to answer questions about images, CoCa sets a new state-of-the-art with 82.3% accuracy on the test-std split. This result showcases CoCa's ability to reason about the relationship between images and text.
Visual Entailment and Reasoning: CoCa performs well on tasks that require more complex reasoning about visual and textual inputs. On the SNLI-VE visual entailment task, CoCa achieves 87.1% accuracy on the test set. For the NLVR2 visual reasoning task, CoCa reaches 87.0% accuracy on the test-P split. These results demonstrate CoCa's capacity for a nuanced understanding of the relationship between visual and textual information.
Image Captioning: CoCa sets a new standard on the challenging NoCaps image captioning benchmark, achieving a CIDEr score of 120.6. This result highlights CoCa's generative capabilities and ability to describe novel objects and scenes not seen during training.
These benchmark results demonstrate CoCa's versatility and effectiveness across a wide range of vision and language tasks. The model often surpasses specialized architectures designed for specific applications, showcasing the power of its unified training approach.
Scaling Performance
Scaling is a crucial factor in foundation models, and CoCa’s unified approach ensures that its performance improves as model size increases.
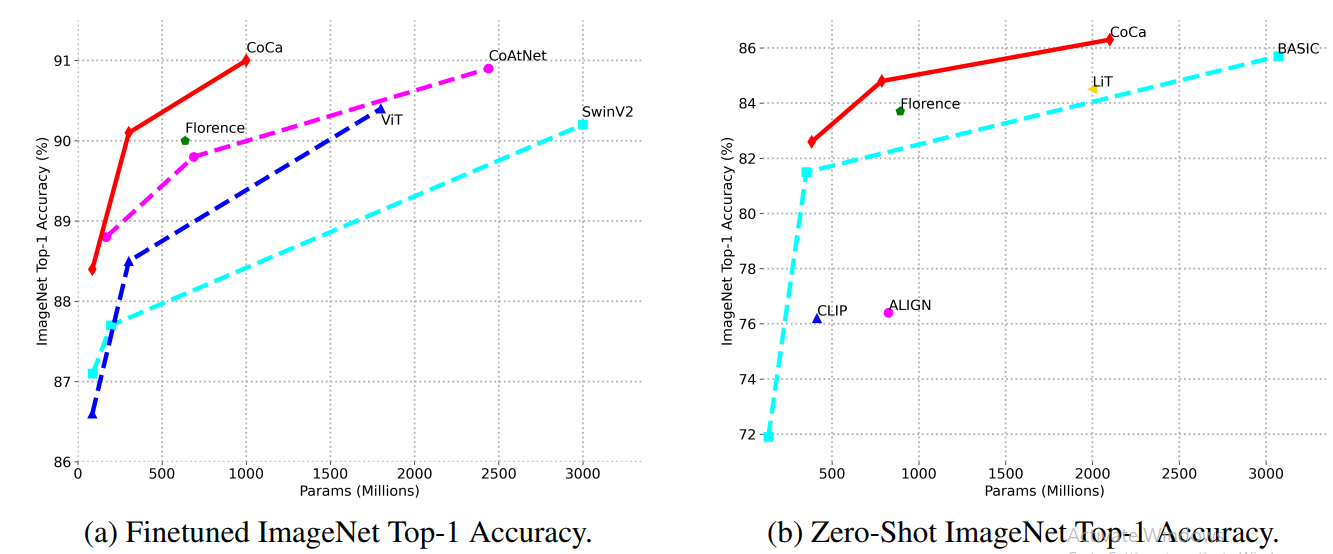 Figure 9- Image classification scaling performance of model sizes.png
Figure 9- Image classification scaling performance of model sizes.png
Figure 9: Image classification scaling performance of model sizes
The above image illustrates the scaling behavior of CoCa compared to other models for both fine-tuned and zero-shot ImageNet classification.
For fine-tuned ImageNet performance, CoCa achieves higher accuracy with fewer parameters compared to other models like CoAtNet and ViT. This efficiency is due to CoCa's unified training approach, which allows it to learn more effective representations from the same amount of data.
The zero-shot ImageNet performance shows even more impressive scaling. CoCa's zero-shot accuracy increases rapidly with model size, outperforming other models like CLIP and ALIGN. This suggests that CoCa learns more generalizable representations that can be applied to unseen tasks without additional training.
These scaling results indicate that even larger CoCa models could perform better across various tasks. This scalability is a key advantage of the CoCa approach, as it suggests a clear path for future improvements through increased model size and training data.
Why CoCa Works: Key Innovations
CoCa's impressive benchmark results and scalability can be attributed to several key design innovations that distinguish it from earlier models:
Unified Architecture: By combining elements of single-encoder, dual-encoder, and encoder-decoder models, CoCa can handle a wide range of tasks with a single architecture. This unified approach allows the model to learn representations useful for multiple vision and language tasks.
Decoupled Text Decoder: The separation of the text decoder into unimodal and multimodal parts is a crucial innovation. The unimodal part allows CoCa to create pure text representations, which are essential for tasks like cross-modal retrieval. The multimodal part enables the model to fuse image and text information for tasks that require joint reasoning.
Joint Training Objectives: The use of both contrastive and captioning losses allows CoCa to learn aligned representations and generative capabilities simultaneously. The contrastive loss encourages the model to create similar representations for related image-text pairs, while the captioning loss trains the model to generate descriptive text for images.
Efficient Training: CoCa's design allows it to compute both losses in a single forward pass. This efficiency is a significant advantage over approaches that require separate passes for different objectives, as it allows for faster training and better utilization of computational resources.
Large-scale Pretraining: By training on a combination of image-label pairs from JFT-3B and image-text pairs from ALIGN, CoCa learns rich, generalizable representations. This diverse training data helps the model to understand a wide range of visual concepts and their textual descriptions.
Integrating CoCa and Vector Databases for Enhanced Multimodal AI
To further leverage CoCa's powerful representations in real-world applications, integrating with vector databases like Milvus and Zilliz Cloud provides efficient storage and retrieval of multimodal embeddings, creating powerful systems for large-scale multimedia retrieval and analysis. Vector databases are designed to efficiently store and query high-dimensional vectors, making them ideal for managing the embeddings produced by models like CoCa.
CoCa generates aligned representations for both images and text in a shared embedding space. These embeddings can be stored in a vector database, enabling fast and efficient similarity search across large datasets of images and text. This combination allows for several powerful applications:
Multimodal Search: Users can search for images using text queries or find relevant text based on image inputs. The vector database can quickly retrieve the most similar items based on the cosine similarity of their embeddings.
Scalable Zero-shot Classification: CoCa's zero-shot classification capabilities can be extended to massive image collections by storing class embeddings in the vector database and performing nearest neighbor search.
Content-based Recommendation: By storing CoCa embeddings for items in a recommendation system, vector databases can enable content-based recommendations across modalities.
Efficient Fine-tuning: For domain-specific applications, relevant subsets of data can be quickly identified using vector similarity search, allowing for more efficient fine-tuning of the CoCa model.
Milvus: A Powerful Vector Database for CoCa and Multimodal AI Apps
Milvus is an open-source, high-performance vector database particularly well-suited for integrating with CoCa. Here's how Milvus can enhance CoCa-based applications:
Hybrid and Multimodal Search: Milvus allows combining vector similarity search with traditional filtering, enabling complex queries that consider both semantic similarity and metadata.
High-dimensional Indexing: Milvus supports efficient indexing and querying of high-dimensional vectors, which is crucial for managing CoCa's embeddings (which can have dimensions in the hundreds or thousands).
Scalability: Milvus is designed to scale horizontally and can handle billions of vectors. This scalability matches CoCa's ability to process large datasets well.
Multiple Index Types: Milvus offers 15 index types optimized for different scenarios, allowing users to balance between query speed and accuracy based on their specific needs.
GPU Acceleration: Milvus can leverage GPU acceleration for both indexing and search operations, complementing CoCa's GPU-based inference for end-to-end performance optimization.
Real-time Updates: Milvus supports real-time insertion and updates, allowing CoCa-based systems to continuously incorporate new data without significant downtime.
The synergy between CoCa and vector databases like Milvus opens up new possibilities for building scalable, efficient, and powerful multimodal AI systems. As both technologies continue to advance, we can expect to see increasingly sophisticated applications that leverage the strengths of both foundation models and vector databases.
Implications and Future Directions of Coca
As CoCa continues to advance, it holds the potential to redefine how multimodal models are developed and deployed in the future. Let's start by looking at some significant future implications for the field of AI:
Simplified Model Development: Instead of creating specialized models for different tasks, researchers and developers can potentially use a single CoCa model for a wide range of applications. This could streamline the development process and reduce the need for task-specific architectures.
Improved Transfer Learning: CoCa's strong zero-shot and few-shot performance suggests it could be particularly useful for tasks with limited labeled data. This could enable the application of advanced AI techniques to domains where large-scale labeled datasets are not available.
Multimodal AI Systems: CoCa's ability to handle both vision and language tasks could lead to more sophisticated AI systems that can understand and generate content across modalities. This could enable more natural and versatile human-AI interactions.
Efficiency in AI Development: The unified approach of CoCa could lead to more efficient use of computational resources in AI research and development. By training a single model for multiple tasks, researchers can potentially reduce the overall computational cost of developing AI systems.
Future research directions might include:
Scaling to larger models and datasets: Given CoCa's impressive scaling behavior, exploring even larger model sizes and training on larger, more diverse datasets could further improve performance.
Incorporating additional modalities: Extending the CoCa approach to include other modalities, such as audio or video, could lead to even more versatile AI models.
Exploring few-shot learning capabilities: While CoCa shows strong zero-shot performance, investigating its few-shot learning abilities could reveal new ways to adapt the model to specific tasks with minimal additional training.
Exploring domain-specific adaptations: Investigating how CoCa can be efficiently adapted to specific domains or industries could unlock new applications in healthcare, finance, or scientific research.
Conclusion
CoCa marks a key advancement in image-text foundation models by unifying different learning approaches into a single, efficient model. Thanks to its versatile training approach, it excels across various tasks, including image classification, video recognition, visual question answering, and image captioning. Its strong performance in zero-shot and few-shot scenarios makes it a valuable foundation for many AI applications.
Integrating CoCa with vector databases like Milvus enables scalable and efficient multimodal systems to handle large volumes of multimedia data. As AI research advances, models like CoCa pave the way for more integrated systems capable of understanding diverse data types.
Further resources
Papers:
[2205.01917] CoCa: Contrastive Captioners are Image-Text Foundation Models (arxiv.org)
[2108.07258] On the Opportunities and Risks of Foundation Models (arxiv.org)
[2103.00020] Learning Transferable Visual Models From Natural Language Supervision (arxiv.org)
[1504.00325] Microsoft COCO Captions: Data Collection and Evaluation Server (arxiv.org)
Image-Text Pre-training with Contrastive Captioners (research.google)
 Denis Kuria
Denis KuriaDenis is a machine learning engineer who enjoys writing guides to help other developers. He has a bachelor's in computer science and loves hiking and exploring the world.
- Contrastive Captioners (CoCa): A Unified Approach
- CoCa Training Process
- CoCa for Video Recognition
- Benchmark Results
- Scaling Performance
- Why CoCa Works: Key Innovations
- Integrating CoCa and Vector Databases for Enhanced Multimodal AI
- Implications and Future Directions of Coca
- Conclusion
- Further resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Data Modeling Techniques Optimized for Vector Databases
This post explores various data modeling techniques for optimizing the performance of vector databases.

Understanding Regularization in Neural Networks
Regularization prevents a machine-learning model from overfitting during the training process. We'll discuss its concept and key regularization techniques.

Deep Residual Learning for Image Recognition
Deep residual learning solves the degradation problem, allowing us to train a neural network while still potentially improving its performance.