




How Vector Databases are Revolutionizing Unstructured Data Search in AI Applications
Vector databases have become instrumental in revolutionizing unstructured data search within AI applications. One of their widely recognized roles is in retrieval-augmented generation (RAG), a process that connects relevant documents with LLMs. However, their applications and capabilities extend far beyond RAG; they are more broadly applicable for a variety of different types of unstructured data, i.e., any type of data that does not conform to a predefined data model, such as text, images, audio, molecules, and graphs.
At the recent Brazil Unstructured Data Meetup, Frank Liu, the head of Artificial intelligence and machine learning at Zilliz, spoke about how vector databases are transforming the landscape of unstructured data search in AI applications. His insights shed light on the broad and impactful capabilities of these databases.
Watch the replay of Frank's meetup talk Follow the demo
What Are Vectors?
Before covering vector databases and their role in AI applications, it is important to understand what vectors are as they are the building blocks of vector databases. A vector is a list of numbers that encodes information in a way that computers can process. Imagine you have an image, like the one shown below:
 Fig 1- An image represented in vector format
Fig 1- An image represented in vector format
To you, it's a beautiful flower, but to a computer, this image needs to be converted into a format it can understand. This is where vector embeddings come into play.
The image of the above flower is transformed into a vector embedding—a structured array of numbers. Each number in the vector represents a particular feature of the image, such as color, texture, or shape. The combination of these numbers provides a compact and efficient representation of the image that the computer can use for various tasks, such as searching for similar images, categorizing objects, or even generating new images. Here is a visualization of how the vector embeddings are generated and stored in a vector database like Milvus.
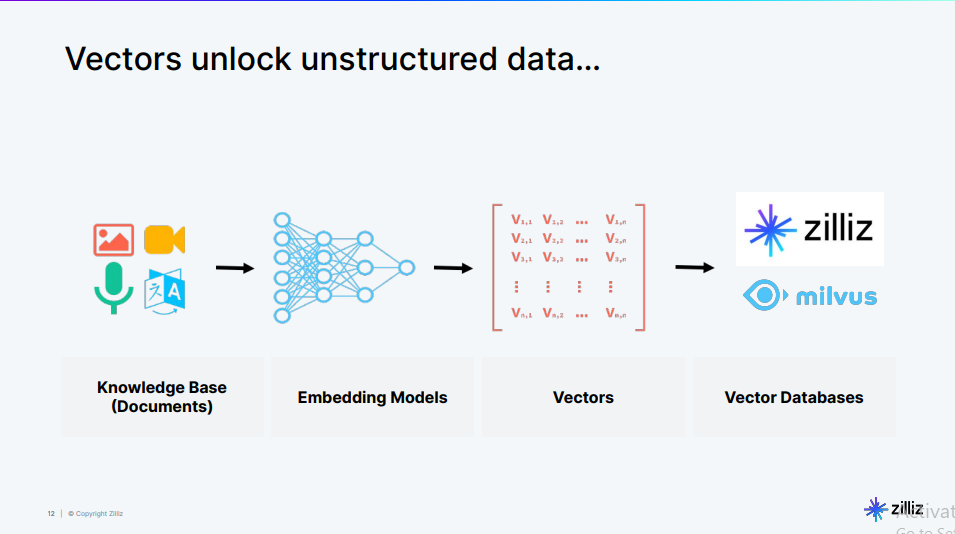 Fig 2- Vector embedding generations and storage process
Fig 2- Vector embedding generations and storage process
The process begins with a knowledge base containing various types of data. The data is then processed by embedding models, which convert it into vectors. Finally, the vectors are stored in a vector database like Milvus ready for retrieval.
Data embedding is not limited to images. Text, audio, and even more complex data types like molecules and graphs can be transformed into vector embeddings. By representing data as vectors, we can leverage the power of vector databases to perform efficient and accurate searches.
Let’s see how vector databases are being utilized in the different fields.
Different Use Cases Powered by Vector Databases
Vector databases are transforming the way we handle and search unstructured data across a multitude of applications. From enhancing the capabilities of AI systems to making more effective recommendations, the possibilities are vast and impactful. Let's jump into some specific use cases powered by vector databases.
Retrieval-Augmented Generation (RAG)
Vector databases are transforming RAG by enabling more efficient and semantically meaningful retrieval of relevant information. Traditional keyword-based search methods often fall short when dealing with complex queries or nuanced contexts. Vector databases address this limitation by storing and searching data based on semantic similarity rather than exact matches.
In RAG, documents are converted into high-dimensional vectors that capture their semantic meaning. When a query is received, it's also converted into a vector, and the vector database quickly finds the most semantically similar documents. This approach allows for more nuanced and context-aware information retrieval, which is crucial for generating accurate and relevant responses.
Consider a customer support chatbot for a tech company. When a user asks, "How do I troubleshoot my device that won't turn on?" the vector database can retrieve relevant documents even if they don't contain those exact words. It might pull information about power issues, battery problems, and general troubleshooting steps. The LLM then uses this retrieved information to generate a comprehensive and contextually relevant response, significantly improving the quality of customer support.
Recommender System
Vector databases are revolutionizing recommender systems by enabling more sophisticated and efficient similarity computations. Traditional recommender systems often struggle with the "cold start" problem and can be computationally expensive when dealing with large datasets. Vector databases address these issues by allowing fast, approximate nearest-neighbor searches in high-dimensional spaces.
In a vector database-powered recommender system, both users and items are represented as vectors in a shared embedding space. These embeddings capture complex features and preferences, allowing for more nuanced recommendations. The vector database can quickly find similar users or items, enabling real-time personalization even with massive datasets.
For example, a music streaming service like Spotify uses vector databases to power its recommendation engine. Each song is represented as a vector, capturing various attributes like genre, tempo, mood, and listening patterns. User preferences are also encoded as vectors. When a user listens to a new song, the system can quickly find similar songs in the vector space, allowing for the discovery of new music that aligns with the user's taste, even if it's from an unfamiliar artist or genre.
Molecular Similarity Search
Vector databases are transforming molecular similarity search in drug discovery by enabling more efficient and accurate identification of similar compounds. Traditional methods often rely on 2D structure similarity, which can miss important 3D conformational similarities or functional group relationships.
With vector databases, images of molecules are represented as high-dimensional vectors that capture complex structural and chemical properties. This allows researchers to search for molecules with similar properties or potential biological activities, even if their 2D structures appear different. The speed of vector databases also allows for rapid screening of vast chemical libraries.
Take the example of a pharmaceutical company searching for new antibiotic candidates. They have a known antibiotic molecule that works well but has severe side effects. Using a vector database, they can quickly search millions of compounds to find molecules with similar antibacterial properties but potentially different side effect profiles. The vector representation might capture features like charge distribution, potential binding sites, and 3D shape, allowing the discovery of structurally diverse but functionally similar molecules that traditional 2D similarity searches might miss.
Multimodal Similarity Search
Vector databases are revolutionizing multimodal search by providing a unified way to represent and search across different types of data (text, images, audio, etc.). Traditional search systems often struggle with cross-modal queries or finding relationships between different data types.
In a vector database-powered multimodal system, all data types are projected into a shared high-dimensional space where similarities can be computed regardless of the original data type. This allows for more flexible and powerful search capabilities, enabling us to find related content across different modalities.
For example, an e-commerce platform implements a multimodal search system using vector databases. A user can upload an image of a piece of furniture they like and provide a text description of the desired color and material. The system converts both the image and text into vectors in a shared space. It then searches the vector database to find products that match both the visual style from the image and the specific attributes from the text description. This allows users to find exactly what they're looking for, even if they can't fully articulate it in words alone, greatly enhancing the shopping experience.
These are just a few use cases that are being revolutionized by vector databases. Frank shared the following slide with even more use cases.
 Fig 3- Vector databases use cases
Fig 3- Vector databases use cases
The above list is not exhaustive. It is just a representation of what is possible when it comes to enhancing data search in AI applications through vector databases.
Since you now understand the importance of vector databases in various fields. Let’s implement one of the use cases so that you can see them in action. We will utilize Milvus as it is the most popular vector database in terms of GitHub starts.
Implementing a Multimodal Similarity Search System Using Milvus, Radient, ImageBind, and Meta-Chameleon-7b
To implement a multimodal similarity search system using the above tools. You need to install them in your environment and import them.
Setting Up Your Environment
Start by installing the required libraries and downloading the necessary models.
!pip install -U radient
!pip install -U yt-dlp
!pip install pymilvus
!pip install -U git+https://github.com/facebookresearch/chameleon.git@main
!git clone https://huggingface.co/eastwind/meta-chameleon-7b
!yt-dlp "https://www.youtube.com/watch?v=wwk1QIDswcQ" -o ~/google_io_preshow.mp4
!pip install git+https://github.com/fzliu/ImageBind@main
Here is what each of the above libraries does:
Radient: Creates and executes workflows to process and analyze multimodal data, integrating various data processing steps.
yt-dlp: A command-line tool for downloading videos from YouTube. In this article, we will use this video from Google's pre-show.
PyMilvus: The Python SDK for interacting with the Milvus vector database and Milvus lite, enabling efficient similarity search and retrieval of large-scale data.
Chameleon: A vision-language model developed by Meta AI, capable of understanding and generating text based on visual inputs, useful for integrating multimodal data inputs.
Meta-Chameleon-7b: A specific model from the Chameleon series, designed for advanced vision-language tasks, providing context-aware responses by integrating visual and textual data.
ImageBind: A multimodal embedding model.
After installing the libraries, we need to import them into your code to be able to use their functions.
from pathlib import Path
from radient import make_operator
from radient import Workflow
Notice we import radient only. This is because Radient handles the integration and utilization of the embedding model and PyMilvus within its workflows. Hence we do not need to manually import them.
The make_operator function allows us to create various operators that will form the building blocks of our workflow. The Workflow class will chain these operators together in a logical sequence.
After the importations, you are ready to implement the multimodal similarity search system.
Creating Operators
Start by specifying the specific tasks that the workflow will perform.
path = Path('/content/google.mp4') // pass the youtube downloaded video path here
read = make_operator(optype="source", method="local", task_params={"path": str(path)})
demux = make_operator(optype="transform", method="video-demux", task_params={"interval": 5.8})
vectorize = make_operator (optype="vectorizer", method="imagebind", modality="multimodal", task_params={})
store = make_operator (optype="sink", method="milvus", task_params={"operation": "insert"})
Let's break down each operator in detail:
read: This is asourceoperator that reads the local video file. It takes the file path as a parameter and is responsible for loading the video data into our workflow.demux: This is atransformoperator that demuxes (separates) the video into frames at 5.8-second intervals. This step is crucial for breaking down the continuous video stream into discrete images that can be processed individually.vectorize: This operator uses theImageBindmodel to create vector embeddings for multimodal data. ImageBind is a powerful model that can create unified embeddings for different modalities (like images, text, and audio), allowing us to represent our video frames in a high-dimensional vector space.store: This is a sink operator that inserts the vectorized data into the Milvus lite. A lightweight version of Milvus
After creating the operators, the next step is to create a workflow using them.
Constructing the Insertion Workflow
Next, we construct a workflow to insert our processed video data into the Milvus database:
insert_wf = (Workflow()
.add(read, name="read")
.add(demux, name="demux")
.add(vectorize, name="vectorize")
.add(store, name="store")
)
insert_wf()
This workflow begins by reading the video file, and then demuxes it into individual frames. Each frame is subsequently vectorized using the ImageBind model. The resulting vectors are stored in the Milvus database.
If everything runs smoothly, you should see an output similar to the one below:
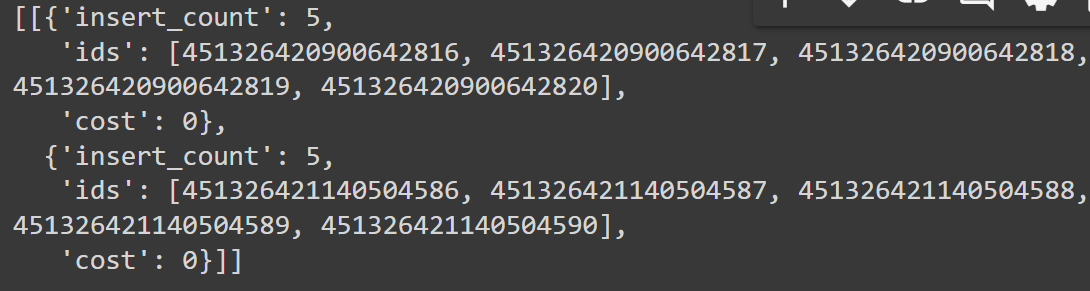 Fig 4- Results of the insertion operation
Fig 4- Results of the insertion operation
The output shows a confirmation that your video was processed and inserted into Milvus. It shows the result of the insertion operation, indicating the number of records inserted, their IDs, and the computational cost.
Setting Up the Search Workflow
After inserting our data, we need to set up a workflow for searching. This workflow will allow us to find relevant video frames based on text queries:
vectorize = make_operator("vectorizer", "imagebind", modality="text")
search = make_operator("sink", "milvus", task_params={"operation": "search", "output_fields": None})
search_wf = (Workflow()
.add(vectorize, name="vectorize")
.add(search, name="search")
)
This search workflow consists of two main steps:
The
vectorizeoperator takes text input and converts it into a vector embedding using ImageBind. This allows us to represent our text query in the same vector space as our video frames.The
searchoperator then uses this vector to perform a similarity search in the Milvus database, finding the most similar video frames to our query.
Since we have the search workflow, let’s perform a search.
Performing a Multimodal Search
This is a multimodal search as we are using text to search a video. To be precise, we are searching the video frames.
prompt = "What was unusual about the coffee mug?"
search_wf(data=prompt)
search_vars = {
"limit": 1, # top-k limit
"output_fields": ["*"] # output fields
}
results = search_wf(
extra_vars={"search": search_vars},
data=prompt
)
results[0][0][0]["entity"]["data"]
Here, we define a search prompt asking about an unusual coffee mug. The search_vars dictionary specifies that we want the top 1 result and all output fields.
We then execute the search workflow with these inputs. The workflow vectorizes our text prompt, searches for similar vectors in Milvus, and returns the results. The nested indexing [0][0][0] accesses the first (and in this case, only) search result, and ["entity"]["data"] retrieves the actual data associated with this result.
The above code returns the path of the frame that best fits our query.
/root/.radient/data/video_demux/6bc783e9-c789-4340-b45c-204621145f2b/frame_0001.png
Let’s visualize this returned frame to see what is unusual with the mug.
from PIL import Image
image_path = "/root/.radient/data/video_demux/6bc783e9-c789-4340-b45c-204621145f2b/frame_0001.png"
image = Image.open(image_path)
import matplotlib.pyplot as plt
plt.imshow(image)
plt.show()
This code opens the image file corresponding to our search result using the PIL (Python Imaging Library) and displays it using matplotlib. This visual representation helps us understand what the system found in response to our query about an unusual coffee mug.
Here is the output:
 Fig 5- A person coming out of a Mug
Fig 5- A person coming out of a Mug
As you can see this frame shows an unusual Mug as you cannot fit a person in a normal mug. The unusual activity is that there is a person coming out of a mug.
Leveraging Meta-Chameleon-7b for Image Description
To further enhance our multimodal search system, we can use the Meta-Chameleon-7b model to generate a description of the image:
from chameleon.inference.chameleon import ChameleonInferenceModel
import os
# Verify the file path and existence
image_path = '/root/.radient/data/video_demux/6bc783e9-c789-4340-b45c-204621145f2b/frame_0001.png'
print(f"Image path: {image_path}")
print(f"File exists: {os.path.exists(image_path)}")
print(f"File size: {os.path.getsize(image_path)} bytes")
# Initialize the model
model = ChameleonInferenceModel(
"./meta-chameleon-7b/models/7b/",
"./meta-chameleon-7b/tokenizer/text_tokenizer.json",
"./meta-chameleon-7b/tokenizer/vqgan.yaml",
"./meta-chameleon-7b/tokenizer/vqgan.ckpt",
)
try:
tokens = model.generate(
prompt_ui=[
{"type": "image", "value": f"file:{image_path}"}, # Remove the space after 'file:'
{"type": "text", "value": prompt},
{"type": "sentinel", "value": "<END-OF-TURN>"},
]
)
result = model.decode_text(tokens)[0]
print("Generated description:")
print(result)
except Exception as e:
print(f"Error: {e}")
import traceback
traceback.print_exc()
This code initializes the Meta-Chameleon-7b model, a vision-language model capable of understanding and describing images in context. We provide it with both the image and our original text prompt, allowing it to generate a description that's relevant to our query.
The generate method takes a list of inputs, including the image file path, our text prompt, and a sentinel token to mark the end of the input. The model then generates a sequence of tokens, which we decode into human-readable text. Here is a sample of how the output should look like:
 Fig 6- Output of describing and image using a vision-language model
Fig 6- Output of describing and image using a vision-language model
This implementation showcases how vector databases like Milvus can be integrated into larger AI systems, enabling efficient similarity search across different modalities.
Conclusion
Frank did a good job in showing us how vector databases have emerged as a transformative technology in the field of AI and machine learning, particularly for handling unstructured data. As demonstrated, their applications extend far beyond simple retrieval-augmented generation (RAG) systems, revolutionizing various domains including customer support, recommendation systems, drug discovery, and multimodal search. Go on and implement even more sophisticated vector database-powered AI applications. Here are some resources for your reference.
For a more detailed understanding, including the history of embeddings, watch the replay of the meetup talk.
Further Resources
Keep Reading

Zilliz Cloud Launches in AWS Australia, Expanding Global Reach to Australia and Neighboring Markets
We're thrilled to announce that Zilliz Cloud is now available in the AWS Sydney, Australia region (ap-southeast-2).

AI Agents Are Quietly Transforming E-Commerce — Here’s How
Discover how AI agents transform e-commerce with autonomous decision-making, enhanced product discovery, and vector search capabilities for today's retailers.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.