




Multimodal RAG: Expanding Beyond Text for Smarter AI
Over the past year and a half, Retrieval Augmented Generation (RAG) has become a powerful technique for improving large language model (LLM) responses with relevant contextual information, significantly reducing the risk of hallucinations—where LLMs generate responses that sound plausible but are factually incorrect.
However, real-world data often extends far beyond text—we also encounter images, videos, tables, and various document formats. This is where Multimodal RAG becomes critical, allowing the integration of different data types to provide even more reliable knowledge to AI models.
In this post, we'll talk about:
- The evolution of RAG, from traditional text-based RAG to Multimodal RAG
- How the Milvus vector database enables the storage and search of diverse data types
- The role of NVIDIA GPUs in accelerating these complex operations
- The potential applications and benefits of this technology
Whether you're an AI enthusiast or a developer looking to add RAG to your projects, this post will provide valuable insights into a technology that's set to redefine the capabilities of RAG systems.
The Evolution of RAG: From Text-centric to Multimodal
Traditional RAG
Text based RAG enhances LLM responses by retrieving relevant text-based context from a knowledge base. Below is an overview of a typical RAG workflow:
- The user submits a text query to the system.
- The query is transformed into a vector embedding, which is then used to search a vector database , such as Milvus, where text passages are stored as embeddings. The vector database retrieves passages that closely match the query based on vector similarity.
- The relevant text passages are passed to the LLM as supplementary context, enriching its understanding of the query.
- The LLM processes the query alongside the provided context, generating a more informed and accurate response.
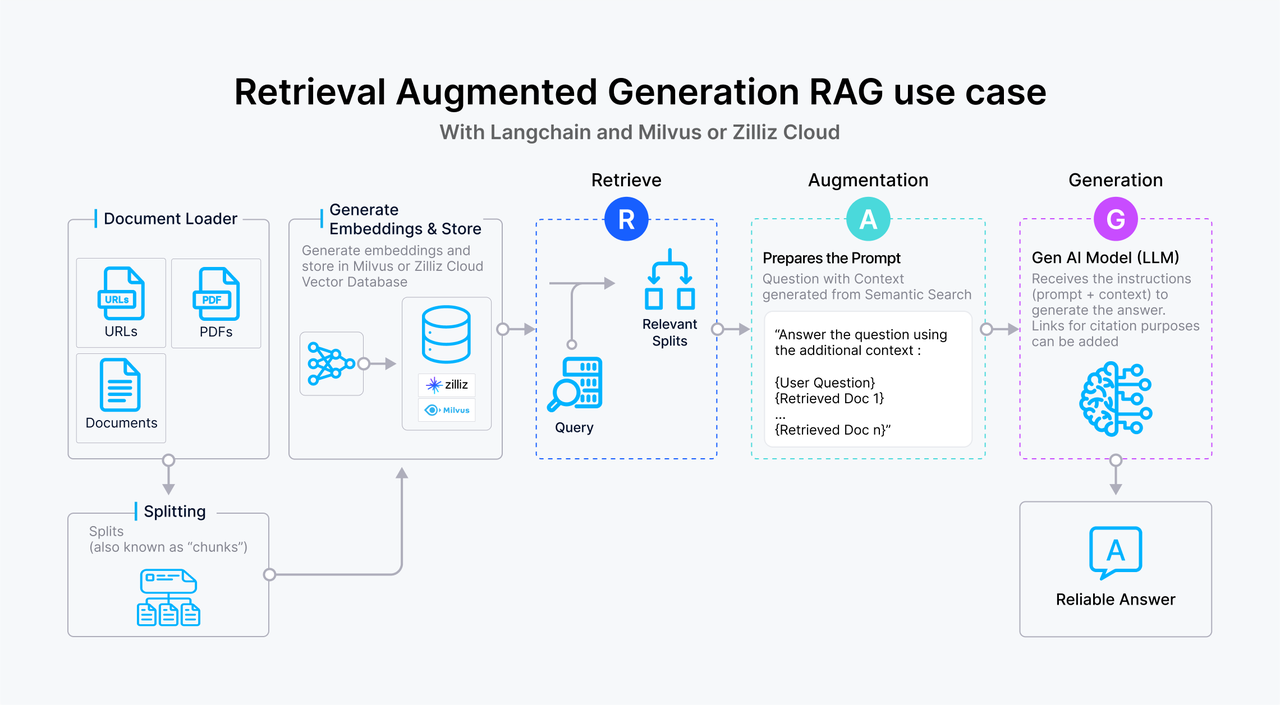 Figure 1- How RAG works.png
Figure 1- How RAG works.png
Figure: How RAG works
Traditional RAG has been highly effective for improving the LLM output, but it remains limited to textual data. In many real-world applications, knowledge extends far beyond text—incorporating images, charts, and other modalities that provide critical context.
Multimodal RAG: Expanding Beyond Text
Multimodal RAG addresses the above limitation by enabling the use of different data types, providing better context to LLMs.
A key player in this evolution is LLaVA (Large Language and Vision Assistant), a multimodal model designed to integrate both language (text) and vision (images) to enhance the capabilities of large language models (LLMs). LLaVA extracts meaningful information from visual content and converts it into textual descriptions, which can be processed by embedding models and stored in vector databases like Milvus.
Below is an example of how LlaVA works with embedding models and vector databases.
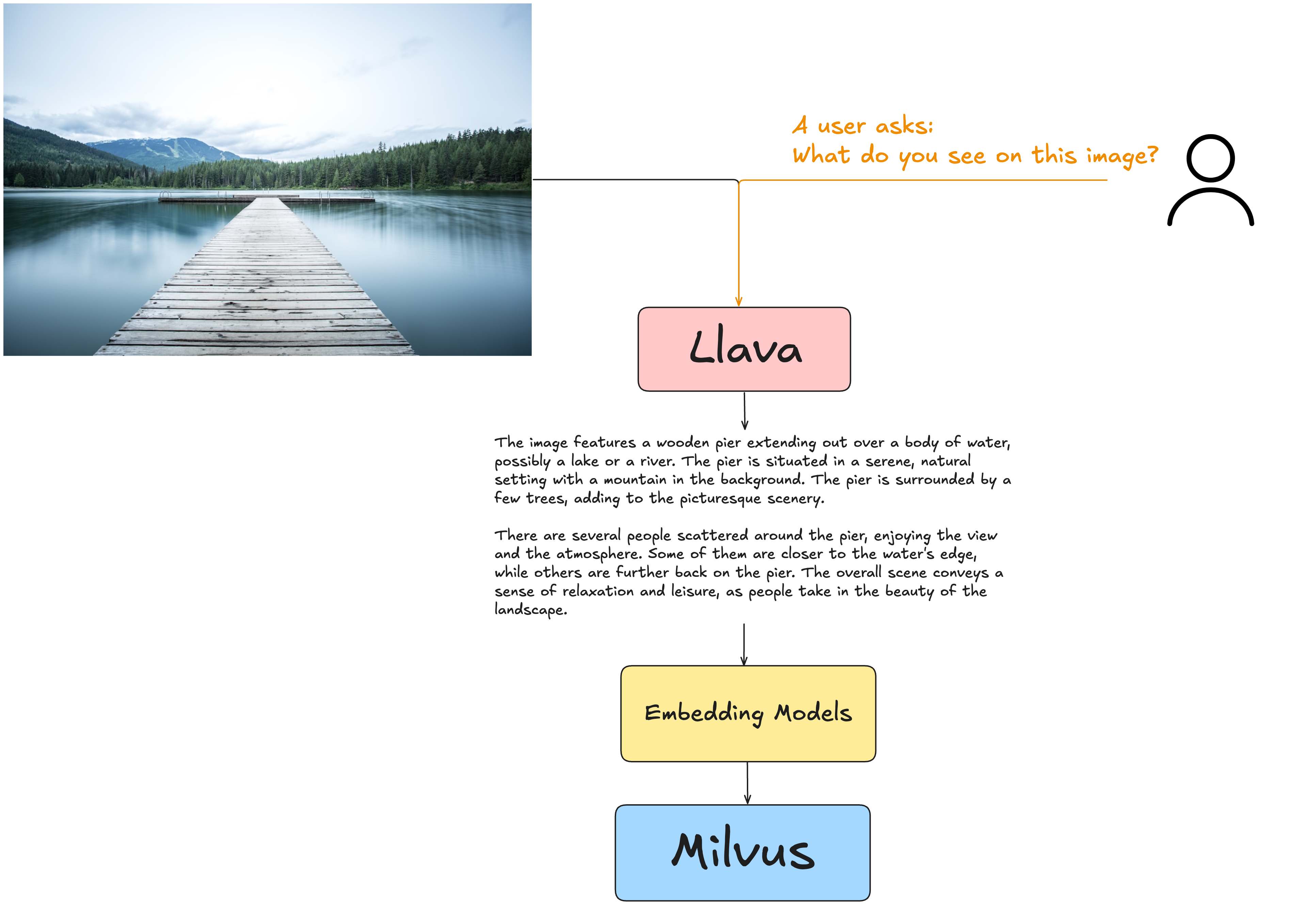 Figure: An example of what LlaVa can produce when asked about an image
Figure: An example of what LlaVa can produce when asked about an image
Figure: An example of what LlaVa can produce when asked about an image
Key Components of a Multimodal RAG Pipeline
To process diverse data types, a Multimodal RAG pipeline converts all modalities into a unified format, typically text. This conversion is usually achieved using specialized Vision Language Models (VLMs), which handle general images and graphical data like charts. VLMs extract meaningful information from these non-textual sources and transform it into text-based embeddings that can be used by large language models (LLMs) for context generation.
In addition to VLMs, several other critical components also ensure that Multimodal RAG systems operate efficiently and at scale. Below are the key components of such a pipeline, along with some prime examples that illustrate how these components are implemented.
Vision Language Models (VLMs): These models process and convert visual content—such as images, charts, and graphs—into textual or embedded formats that LLMs can utilize.
- Example: Neva 22B (NVIDIA): A fine-tuned variant of LLaVA, optimized for general image understanding, capable of interpreting and generating textual descriptions from visual inputs.
- Example: DePlot (Google): Specialized in processing and analyzing graphical data like charts and plots, making it ideal for more technical visual content.
Vector Databases: Vector databases are a cruial component of multimodal RAG system that store and retrieve vector embeddings for various data types, including text, images, and other modalities. They perform similarity searches, ensuring that the most relevant information is quickly accessible to the LLM.
Example: Milvus is a prime example of vector databases that supports NVIDIA GPU-accelerated vector search, providing exceptional performance for large-scale multimodal data.
- GPU Acceleration: Milvus uses NVIDIA GPUs to speed up vector indexing and querying.
- Scalability: It handles billion-scale similarity searches, making it suitable for high-volume applications.
- Efficiency: The combination of GPU indexing and querying ensures maximum throughput and real-time responses with minimal latency.
Text Embedding Models: These models convert textual inputs into vector embeddings, which are essential for similarity searches in a RAG system.
- Example: NV Embed: A GPU-accelerated embedding model that efficiently transforms text into embeddings for fast retrieval in vector databases, offering significant speed advantages over CPU-based solutions.
Large Language Models (LLMs): LLMs form the core of the RAG system, generating responses based on the query and the retrieved contextual data. These models are often fine-tuned for specific tasks to improve response accuracy.
- Example: Llama 3.1 (70B Instruct Variant): Developed by Meta, this version is fine-tuned for instruction-following tasks, enhancing its ability to generate precise, task-oriented responses.
Orchestration Frameworks: These frameworks manage the flow of data across the entire pipeline—from processing the initial query, retrieving the relevant multimodal content, to generating the final response.
- Example: LlamaIndex: A framework that orchestrates the query processing, context retrieval, and response generation, ensuring smooth coordination between all components of the multimodal RAG system
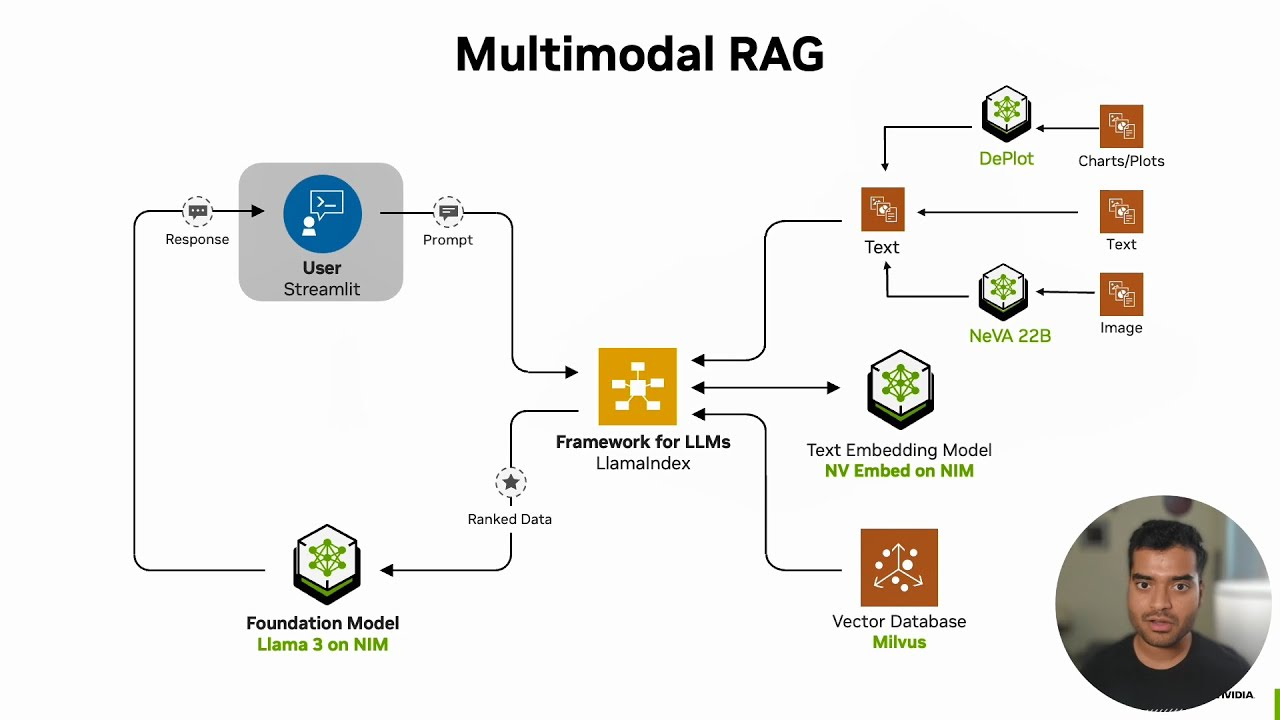 Figure: A multimodal RAG architecture (Credit NVIDIA)
Figure: A multimodal RAG architecture (Credit NVIDIA)
Figure: A multimodal RAG architecture (Credit NVIDIA)
The diagram above illustrates the architecture of an example Multimodal RAG pipeline presented by NVIDIA built on several key components: Llama 3 serves as the foundational large language model (LLM), with LlamaIndex orchestrating the entire workflow. NV Embed handles text embedding, while Milvus acts as the vector database for fast retrieval. NeVA 22B processes images, and DePlot manages charts and plots, enabling the system to handle a wide variety of data formats.
For more information about how to build a multimodal RAG, check out the below resources:
- Video: Building Multimodal AI RAG with LlamaIndex, NVIDIA NIM, and Milvus | LLM App Development
- Tutorial: Build a Multimodal RAG with Gemini, BGE-M3, Milvus and LangChain
- Tutorial: Build Better Multimodal RAG Pipelines with FiftyOne, LlamaIndex, and Milvus
- Tutorial: Multimodal RAG locally with CLIP and Llama3
Key Features of Multimodal RAG Systems
This Multimodal RAG system uses many advanced features that make it possible to process and understand diverse data types:
- Multi-format Processing: This multimodal RAG system handles a wide range of document types, including text files, PDFs, PowerPoint presentations, and images. Making it useful for different purposes such as research, business intelligence, etc.
- Image Analysis via Vision Language Models: With the integration of models like NeVA 22B, the system can analyze and describe visual content, such as images and diagrams.
- Efficient Indexing and retrieval: Leveraging Milvus in combination with NVIDIA GPUs, the system offers lightning-fast vector indexing and similarity search. This capability allows it to efficiently process vast amounts of data, making it ideal for applications that require real-time retrieval of multimodal information.
By combining these powerful features, this Multimodal RAG system delivers comprehensive solutions for extracting insights from diverse types of data. Whether you're working with text, images, or a combination of both, the system enables you to leverage various formats to enhance understanding and decision-making.
Conclusion: Advancing AI-Powered Content Understanding
In this blog post, we have covered how to build a multimodal RAG application using NVIDIA GPUs and Milvus. Milvus, with its GPU-accelerated vector search capabilities, plays a crucial role here, ensuring high performance and scalability. We encourage you to experiment by checking out the Notebook on Github explore further.
We'd love to hear what you think!
If you like this blog post, we’d really appreciate it if you could give us a star on GitHub! You’re also welcome to join our Milvus community on Discord to share your experiences. If you're interested in learning more, check out our Bootcamp repository on GitHub for examples of how to build Multimodal RAG apps with Milvus.
Further Resources
- Top 10 Multimodal AI Models of 2024
- Evaluate Your Multimodal RAG Using Trulens
- Exploring Multimodal Embeddings with FiftyOne and Milvus
- Exploring OpenAI CLIP: The Future of Multi-Modal AI Learning
- Generative AI Resource Hub | Zilliz
- Top Performing AI Models for Your GenAI Apps | Zilliz
- Vector Database Comparison

Keep Reading

Migrating Self-Managed Milvus to Zilliz Cloud for >99% Latency Reduction
Step-by-step guide to migrating 50M vectors from self-managed Milvus to Zilliz Cloud using milvus-backup. Achieve >99% query latency reduction with zero data loss.

Our Journey to 35K+ GitHub Stars: The Real Story of Building Milvus from Scratch
Join us in celebrating Milvus, the vector database that hit 35.5K stars on GitHub. Discover our story and how we’re making AI solutions easier for developers.

Milvus WebUI: A Visual Management Tool for Your Vector Database
Explore Milvus WebUI to monitor, manage, and optimize your vector database with real-time insights, performance tracking, and system health monitoring.