




Understanding DETR: End-to-end Object Detection with Transformers
DETR (DEtection TRansformer) is a deep learning model for end-to-end object detection using transformers.
Read the entire series
- Cross-Entropy Loss: Unraveling its Role in Machine Learning
- Batch vs. Layer Normalization - Unlocking Efficiency in Neural Networks
- Empowering AI and Machine Learning with Vector Databases
- Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
- Vector Databases: Redefining the Future of Search Technology
- Local Sensitivity Hashing (L.S.H.): A Comprehensive Guide
- Optimizing AI: A Guide to Stable Diffusion and Efficient Caching Strategies
- Nemo Guardrails: Elevating AI Safety and Reliability
- Data Modeling Techniques Optimized for Vector Databases
- Demystifying Color Histograms: A Guide to Image Processing and Analysis
- Exploring BGE-M3: The Future of Information Retrieval with Milvus
- Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
- TF-IDF - Understanding Term Frequency-Inverse Document Frequency in NLP
- Understanding Regularization in Neural Networks
- A Beginner's Guide to Understanding Vision Transformers (ViT)
- Understanding DETR: End-to-end Object Detection with Transformers
- Vector Database vs Graph Database
- What is Computer Vision?
- Deep Residual Learning for Image Recognition
- Decoding Transformer Models: A Study of Their Architecture and Underlying Principles
- What is Object Detection? A Comprehensive Guide
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Algorithmic)
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Methodological)
- Understanding CoCa: Advancing Image-Text Foundation Models with Contrastive Captioners
- Florence: An Advanced Foundation Model for Computer Vision by Microsoft
- The Potential Transformer Replacement: Mamba
- ALIGN Explained: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
Launched by Facebook AI Research in 2020, DETR (DEtection TRansformer) is a deep learning model for end-to-end object detection using transformers. Due to their great performance, Transformers have been widely used for modeling sequential data in natural language processing (NLP) tasks such as machine translation and language modeling. The self-attention mechanism in transformers enables them to focus on certain parts of the input data, which are more important for feature learning. This mechanism also allows the DETR model to reason more effectively. Likewise, DETR has utilized the benefits of transformer architecture for object detection in computer vision. DETR eliminates the need for multi-stage pipelines, which first generate region proposals followed by classification, and instead treats the task as a single-stage approach.
This blog will explore DETR's concepts, architecture, strengths, and performance. We’ll also shed some light on combining the DETR model and vector databases like Milvus for advanced data retrieval applications like image retrieval systems and multimodal search solutions.
What is Object Detection?
Before diving into the concept of DETR, let’s first understand object detection.
Object detection is a computer vision technique for identifying and locating objects within images or video frames. Think of object detection as if you have a friend who is good at spotting things. You show your friend a photo, and they point out and name everything they see in the photo, like, "Hey, there's a dog, and there's a tree, and over there is a person!" This "smart friend" is what object detection technology does using computer algorithms and models.
Object detection combines two primary tasks:
Object Classification: Identifying what objects are present in the image.
Object Localization: Determining where each object is located within the image, typically by drawing bounding boxes around them.
By detecting and identifying objects in images, object detection helps make sense of visual information in various fields, such as automatic tagging, automobile safety, retail, security, and more.
What is DETR (DEtection TRansformer)?
DETR is a deep learning model for object detection that leverages transformers to predict bounding boxes and class labels for an image. Transformers are neural networks consisting of an encoder-decoder architecture with self-attention mechanisms. With transformers, DETR can capture global context and relationships between objects in an image, leading to more accurate detections.
Traditional object detection approaches like YOLO (You Only Look Once) and R-CNN (Region Convolutional Neural Network) generate many region proposals or anchor boxes and filter them using Non-Maximum Suppression (NMS). This approach makes the architecture complex and training inefficient.
In contrast, DETR makes object detection a direct set prediction problem. Its goal is to consider all the objects in the image as a set and predict their bounding boxes and classes in a single pass. This new approach improves the detection accuracy, especially when many objects are close to each other.
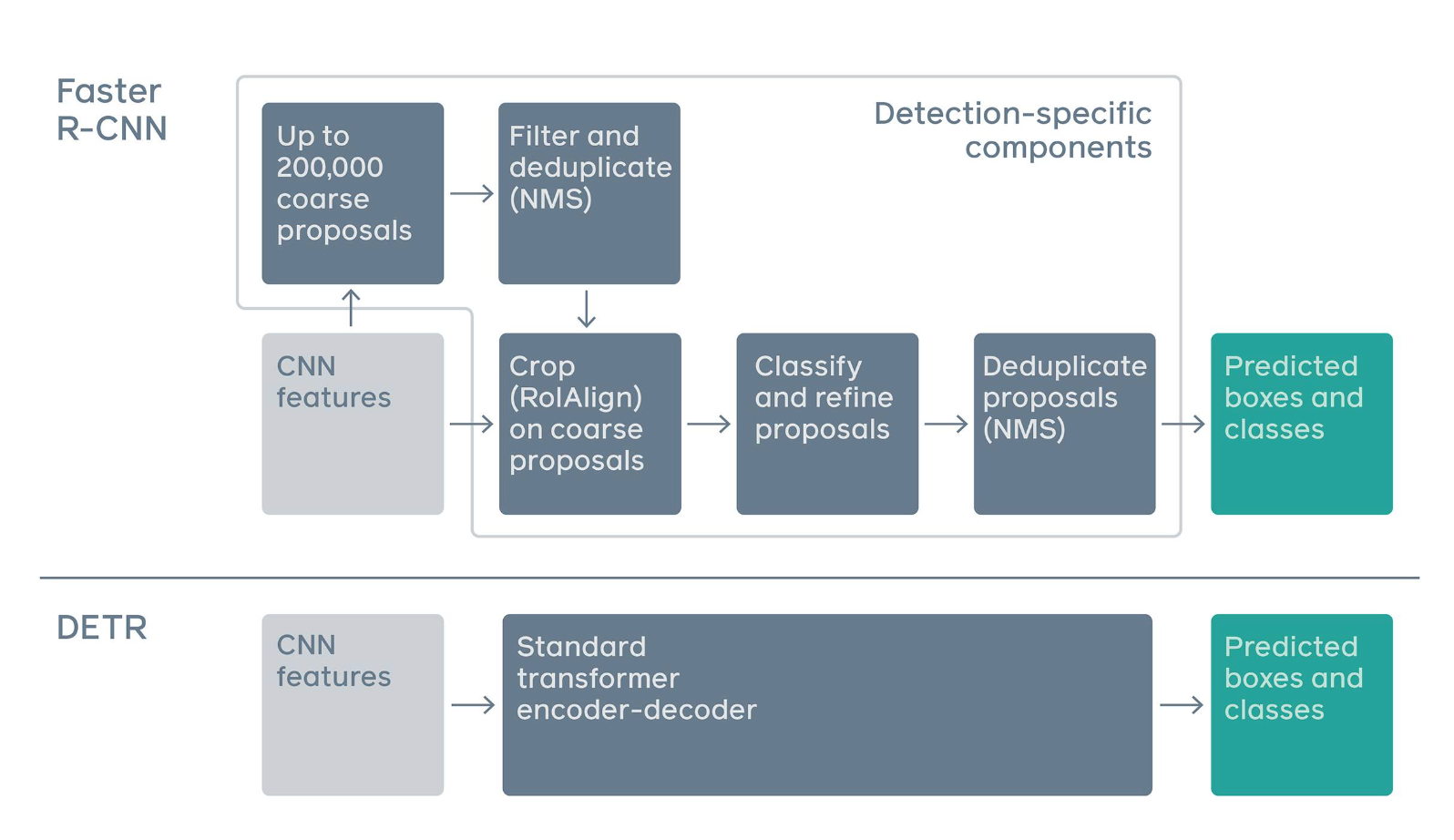 Difference between pipelines of Faster R-CNN (Region Convolutional Neural Network) and DETR (Source)
Difference between pipelines of Faster R-CNN (Region Convolutional Neural Network) and DETR (Source)
Figure 1: Difference between pipelines of Faster R-CNN (Region Convolutional Neural Network) and DETR (Source)
How Does DETR Work?
The DETR Architecture
The main components of DETR architecture are the Convolutional Neural Network (CNN) backbone, the transformer encoder and decoder, and the prediction heads. The DETR architecture is as shown in the figure below:
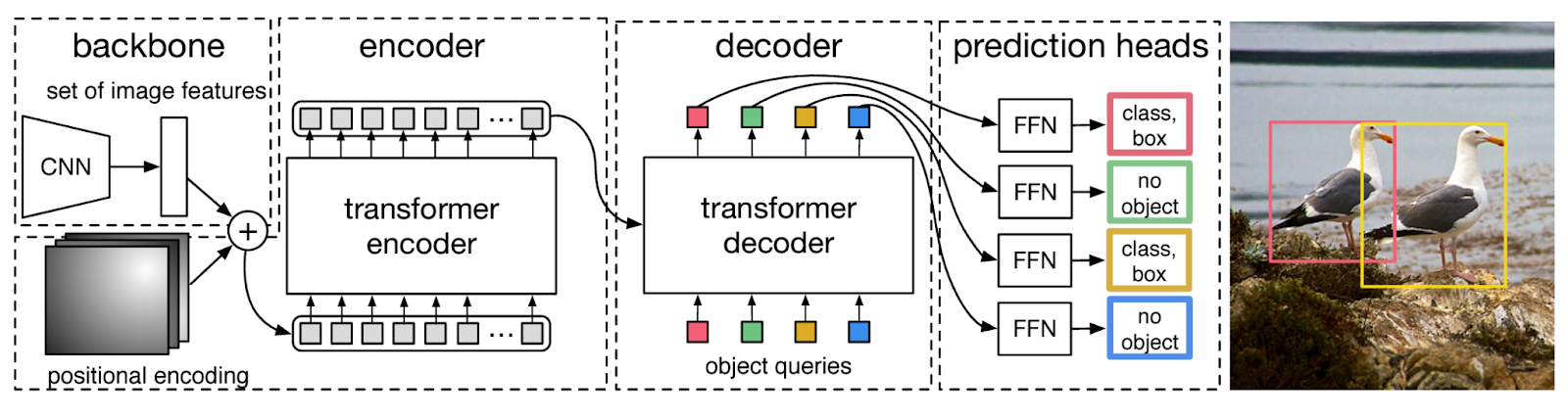 DETR architecture
DETR architecture
DETR architecture (Source)
CNN Backbone: The image is first passed through a CNN backbone which outputs feature representations of the image at a high level. Some examples of popular CNN backbones are Visual Geometry Group (VGG) and ResNet. These features contain spatial information about the objects in the image, which is then passed as input to the transformer encoder.
Transformer Encoder: The transformer encoder encodes these features into a sequence of feature vectors. As the encoder contains multi-headed self-attention blocks, it allows for capturing contextual information through long-range dependencies between different parts of an image. At this stage, another crucial element of the pipeline is the addition of positional encodings to CNN's output. As transformers do not inherently have spatial understanding, these positional encodings inform them about the relative positions of the objects in the image.
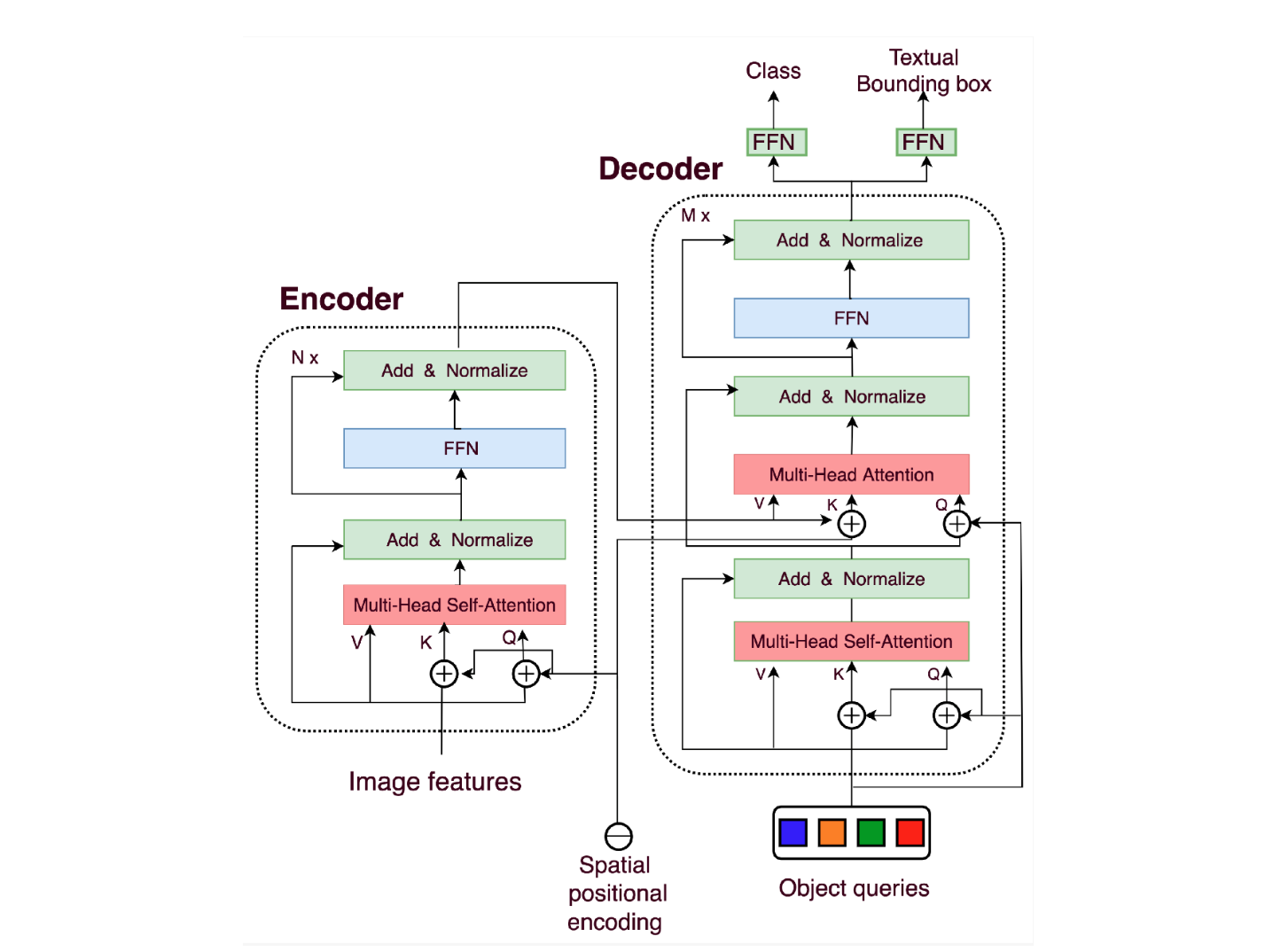 Transformer architecture used in DETR
Transformer architecture used in DETR
Transformer architecture used in DETR (Source)
Transformer Decoder: The transformer decoder learns relationships between the CNN encoded features and the learnable object queries. Typically, we require queries, keys, and values to calculate self-attention in NLP. Therefore, in computer vision, DETR introduces the concept of object queries, which refer to the learnable representations of the objects the model needs to predict. The number of object queries is predetermined and remains fixed. The keys denote the spatial locations in the image, while the values contain information about the features.
Prediction Heads: The prediction heads output the bounding boxes and classes of the detected objects. They consist of feed-forward network heads that either predict the bounding box and class for the detected objects or a ‘no-object’ class for no detections. Furthermore, DETR employs the technique of bipartite matching to ensure that the predicted bounding boxes are associated with the ground truth objects. This method also helps refine the model training.
Training Loss
One of the main components of the training pipeline is the training loss. The training loss combines classification and regression losses as the model predicts bounding boxes and classes.
1) Set Prediction Loss: DETR uses a set prediction loss to measure the accuracy of the predicted classes of objects. We get an idea about the missing object classes by calculating the difference between the predicted and ground-truth object classes.
2) Bounding Box Loss: DETR uses a bounding box loss, which measures the disparity between the predicted and ground-truth coordinates of bounding boxes. This loss helps locate the objects precisely in the image.
DETR Strengths and Disadvantages
Strengths
Simplified architecture: DETR eliminates the need for multi-stage pipelines by performing bounding box and class prediction all in one go. It streamlines the pipeline of object detection through its end-to-end approach.
Awareness of global context: As transformers use a self-attention mechanism, DETR can capture global context by looking at the positions and relations of other objects in the image, as opposed to earlier object detection methods, which predicted each object in isolation.
Efficient training: Previous architectures, such as recurrent neural networks, made predictions sequentially, which made them slower and less efficient. However, with the set-based approach, DETR makes the final set of predictions in parallel, which makes the training pipeline simpler and more efficient.
Disadvantages
Computational resources: DETR is a transformer-based model, so it requires high computational resources to train, especially when the data size is huge with high-resolution images or the backbone model is large.
Fixed object query count: DETR requires mentioning a fixed number of object query counts beforehand, which can limit scenes requiring predicting a variable number of objects. Adjusting the model to handle different object counts dynamically is a challenge.
Inference Speed: While DETR simplifies the training pipeline, the inference speed can be slower than traditional methods due to the transformer architecture's complexity, making it unsuitable for real-time use cases.
DETR Experiment and Results
DETR is a supervised deep learning model. It is trained using large datasets such as the COCO object detection dataset and Pascal VOC. Data augmentation techniques such as flipping, cropping, zooming in and out, and random jittering help the model achieve better generalization. In the experiments, four different DETR models are considered:
Basic DETR built with ResNet-50 backbone
DETR built with ResNet-101 backbone
and two other models denoted by ‘DC5’ comprise the dilated C5 stage.
The ‘DC5’ models enhance the resolution of feature maps by a factor of two in the final stage of CNN, leading to better predictions for smaller objects.
The main aim of the DETR paper was to evaluate DETR on the COCO 2017 object detection dataset against a competitive Faster R-CNN baseline. Upon the initial release, DETR surpassed the Faster R-CNN baseline; however, Faster R-CNN ResNet50 FPN V2 currently performs better than DETR models.
The table below compares the results of DETR variants with different Faster RCNN baselines, as shown in the paper.
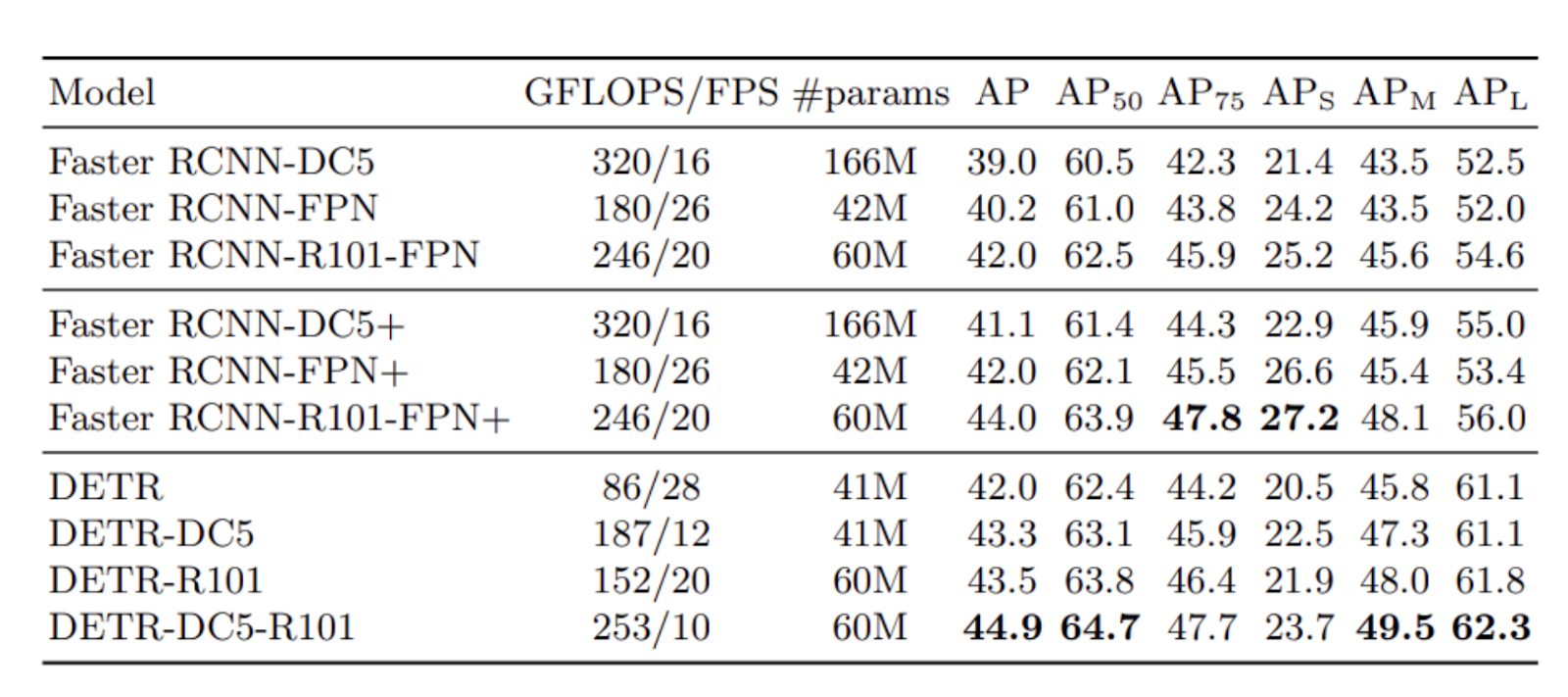 Comparison of results of DETR variants with Faster R-CNN variants
Comparison of results of DETR variants with Faster R-CNN variants
Comparison of results of DETR variants with Faster R-CNN variants (Source)
The results show that DETR models achieved comparable performances with Faster R-CNN models. The best-performing model is the DETR-DC5-R101 model, with an mAP score 44.9. Additionally, it is worth noting that DETR models demonstrate significantly better performance on large objects than on small objects.
To reproduce the DETR experiment and performance comparison results, see the code and pre-trained models on GitHub.
Integrating DETR and Vector Databases for Enhanced Image Retrieval and Multimodal Search
DETR is a state-of-the-art object detection model that uses transformers to accurately identify and locate objects within images, producing high-dimensional feature vectors that encapsulate the visual characteristics of these objects. On the other hand, vector databases, such as Milvus and Zilliz Cloud (the fully managed Milvus), are specialized storage and retrieval systems designed to manage and perform efficient vector similarity searches on high-dimensional vectors.
By leveraging DETR to extract feature vectors from images and storing them in a vector database, we can create advanced image retrieval systems, multimodal search solutions, and many more applications in computer vision and data retrieval.
For example, in an e-commerce application, DETR can analyze product images to generate feature vectors, which are then stored in a vector database like Milvus. When a user queries with a new image, the system can quickly retrieve similar products by comparing the query's feature vector against the stored vectors, thereby providing accurate and efficient image search capabilities.
Additionally, vector databases can store and index vectors of different data types, such as text, audio, and video, alongside image vectors extracted by DETR for multimodal search. This approach enables users to perform complex searches combining multiple data types; for example, a user could upload a product image and provide a text description, and the system would return relevant products that match the visual and textual criteria.
This combination of technologies enables sophisticated solutions in various domains, from automated inventory management to enhanced multimedia search, improving both the accuracy and efficiency of data retrieval across different modalities.
Conclusion
DETR presents an innovative approach for object detection using transformers. The end-to-end model performs object detection and classification in one pass, unlike previous multi-stage models such as RCNN and Faster R-CNN. The direct set prediction approach allows parallel processing and makes the architecture simpler. Despite its strengths, DETR faces challenges in terms of high consumption of computational resources and inference speed. Ongoing research aims to address these limitations and further enhance the model's performance. Furthermore, using transformers presents a unified way to solve bimodal tasks involving NLP and computer vision. Hence, DETR is a promising method that could reshape how we approach object detection and bimodal tasks.
By combining vector databases and DETR technologies, we can significantly build and enhance various computer vision and data retrieval applications, such as image retrieval systems and multimodal search solutions.
Additional Resources
 Yesha Shastri
Yesha ShastriYesha Shastri, Freelance Technical Writer in AI/ML
- What is Object Detection?
- What is DETR (DEtection TRansformer)?
- How Does DETR Work?
- DETR Strengths and Disadvantages
- DETR Experiment and Results
- Integrating DETR and Vector Databases for Enhanced Image Retrieval and Multimodal Search
- Conclusion
- Additional Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Vector Databases: Redefining the Future of Search Technology
The future of search with vector databases is promising, with AI integration and context-aware experiences leading the way.

What is Object Detection? A Comprehensive Guide
Object detection is a computer vision technique that uses neural networks to classify and locate objects, such as humans, buildings, or cars, in images or video.
ALIGN Explained: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
ALIGN (A Large-scale ImaGe and Noisy-text embedding) model is designed to learn visual and language representations from noisy image-alt-text pairs.