




ALIGN Explained: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
ALIGN (A Large-scale ImaGe and Noisy-text embedding) model is designed to learn visual and language representations from noisy image-alt-text pairs.
Read the entire series
- Cross-Entropy Loss: Unraveling its Role in Machine Learning
- Batch vs. Layer Normalization - Unlocking Efficiency in Neural Networks
- Empowering AI and Machine Learning with Vector Databases
- Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
- Vector Databases: Redefining the Future of Search Technology
- Local Sensitivity Hashing (L.S.H.): A Comprehensive Guide
- Optimizing AI: A Guide to Stable Diffusion and Efficient Caching Strategies
- Nemo Guardrails: Elevating AI Safety and Reliability
- Data Modeling Techniques Optimized for Vector Databases
- Demystifying Color Histograms: A Guide to Image Processing and Analysis
- Exploring BGE-M3: The Future of Information Retrieval with Milvus
- Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
- TF-IDF - Understanding Term Frequency-Inverse Document Frequency in NLP
- Understanding Regularization in Neural Networks
- A Beginner's Guide to Understanding Vision Transformers (ViT)
- Understanding DETR: End-to-end Object Detection with Transformers
- Vector Database vs Graph Database
- What is Computer Vision?
- Deep Residual Learning for Image Recognition
- Decoding Transformer Models: A Study of Their Architecture and Underlying Principles
- What is Object Detection? A Comprehensive Guide
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Algorithmic)
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Methodological)
- Understanding CoCa: Advancing Image-Text Foundation Models with Contrastive Captioners
- Florence: An Advanced Foundation Model for Computer Vision by Microsoft
- The Potential Transformer Replacement: Mamba
- ALIGN Explained: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
In recent years, pre-trained visual and vision-language representations have become essential in advancing natural language processing (NLP) and computer vision. These closely related fields focus on learning representations for images and image-text pairs to support various visual and language understanding tasks.
Visual representation learning has traditionally depended on large, labeled datasets, such as ImageNet, containing millions of manually labeled images. Meanwhile, vision-language representation learning uses datasets like MSCOCO that consist of images paired with captions and training models to generate captions or retrieve images based on text.
While these data-driven approaches have advanced the field, they also present challenges regarding scalability, which require the creation of large datasets, human effort, and expertise. Another challenge is the noise and inconsistencies in massive datasets, which can decrease model performance and generalization.
These challenges led researchers to develop a new approach for training visual and vision-language models without relying on expensive, labeled datasets. The ALIGN model represents this change by skipping time-consuming data cleaning and using a massive dataset to handle noise and support more flexible, scalable model performance.
If you want to learn more, here is the ALIGN paper.
What is ALIGN?
ALIGN (A Large-scale ImaGe and Noisy-text embedding) model is designed to learn visual and language representations from noisy image-alt-text pairs. It uses a simple dual-encoder architecture consisting of an image and text encoder. These encoders are trained using a contrastive loss that forces the embeddings of matched image-text pairs to be similar and those of non-matched pairs to be dissimilar. This approach allows ALIGN to achieve state-of-the-art (SOTA) results on tasks including image classification, image-text retrieval, and zero-shot image classification.
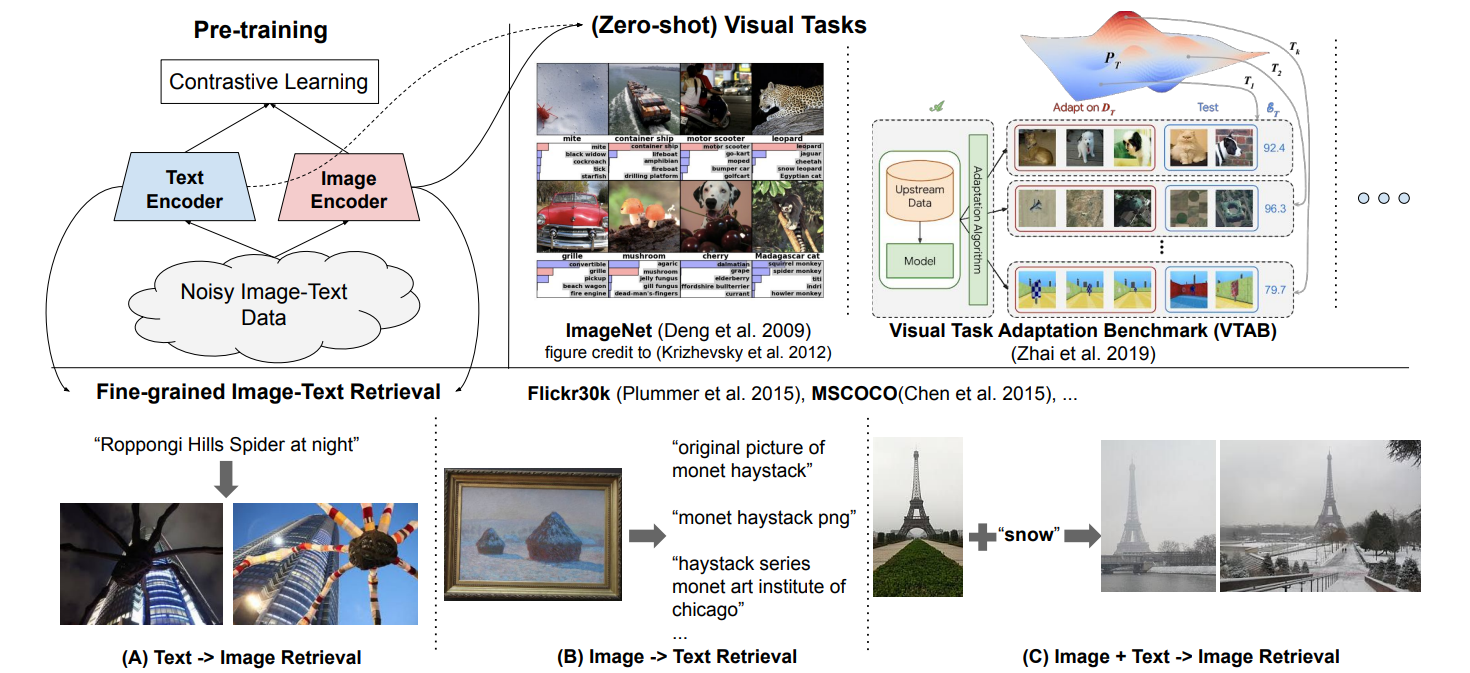 Figure- A summary of the ALIGN method.png
Figure- A summary of the ALIGN method.png
Figure: A summary of the ALIGN method | Source
Methodology
The ALIGN model’s methodology includes the following important stages:
Dataset construction
Model training and optimization
Model Evaluation
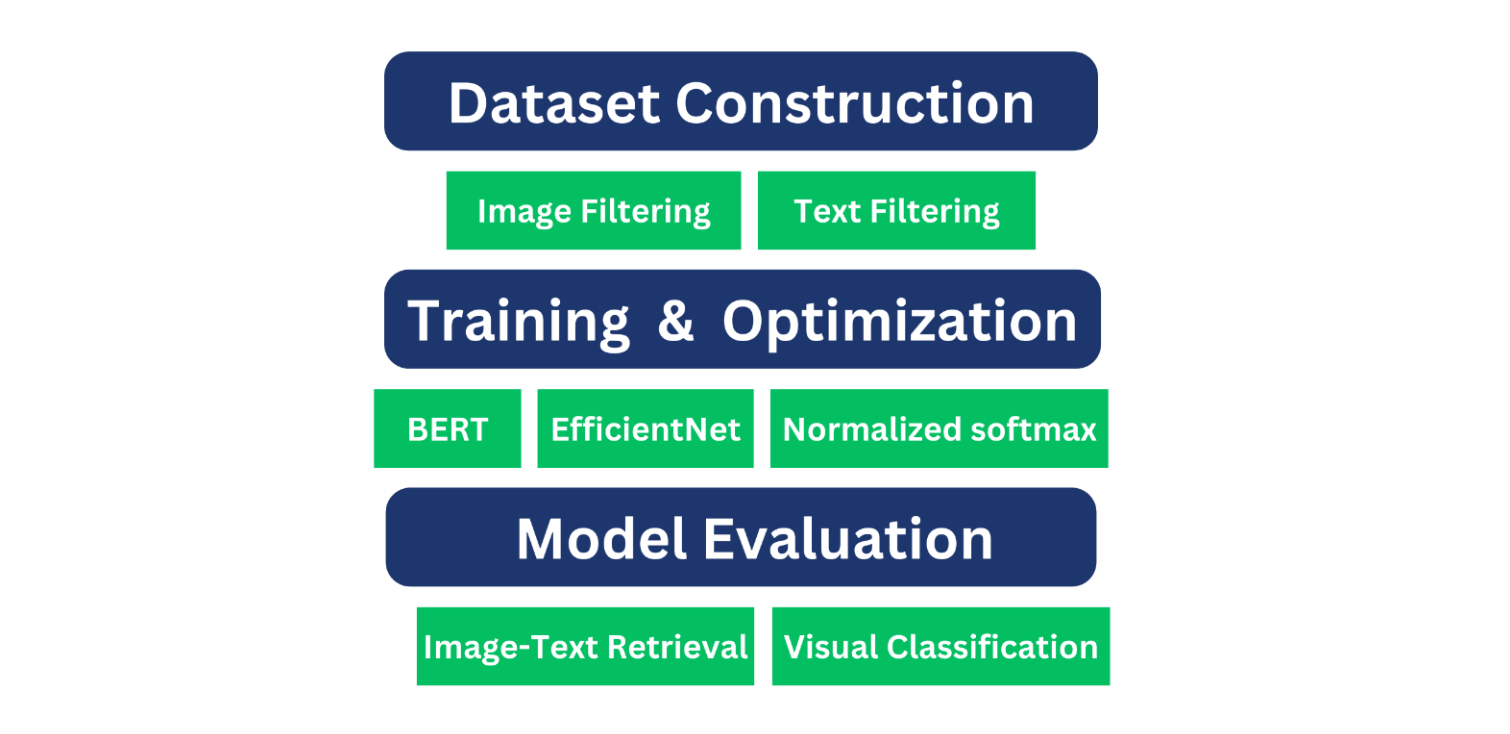 Figure- Model Development and Evaluation Pipeline.png
Figure- Model Development and Evaluation Pipeline.png
Figure: Model Development and Evaluation Pipeline
Dataset Construction
ALIGN uses a large-scale dataset of over 1.8 billion image alt-text pairs. Unlike traditional datasets like Conceptual Captions, which undergo extensive filtering, ALIGN uses minimal filtering to allow scalability while tolerating noise.
- Minimal Filtering: ALIGN applies only basic frequency-based filters instead of extensive curation. For example, the dataset excludes alt-texts shared by more than ten images to avoid irrelevant or generic content, retains images with predefined size and aspect ratio thresholds, and discards images with over 1,000 associated alt-texts to reduce redundancy. Alt-texts that are too short or long (e.g., fewer than 3 words or more than 20 words) are also removed to maintain meaningful textual content.
 Figure- Sample of image-text pairs.png
Figure- Sample of image-text pairs.png
Figure: Sample of image-text pairs | Source
Training and Optimization
The ALIGN model uses a dual-encoder architecture consisting of an EfficientNet image encoder and a BERT text encoder optimized to handle large datasets' scale and noise. The specific training components are detailed below.
EfficientNet and BERT Encoders
EfficientNet: This convolutional neural network (CNN) is optimized for computational efficiency, adjusting depth, width, and resolution to maximize accuracy. In ALIGN, EfficientNet is the image encoder that processes the input images and converts them into meaningful embeddings.
BERT: Known for bidirectional training, BERT understands word context, making it suitable as ALIGN’s text encoder. It processes the textual component of image-alt-text pairs, generating effective text embeddings.
A fully connected layer with linear activation is added to the BERT encoder to ensure compatibility between the two encoders. This layer adjusts the dimensionality of the BERT output to match that of the EfficientNet output, enabling seamless integration of the two encoders within the ALIGN framework. Both encoders are trained from scratch and optimized to maintain consistency across cross-modal tasks.
Contrastive Learning with Normalized Softmax Loss
In the ALIGN model, contrastive loss encourages alignment by minimizing the distance between matched image-text pairs and maximizing the distance between non-matched pairs within the batch. The loss function combines two components: image-to-text loss and text-to-image loss. These losses are calculated using a normalized softmax function, which measures the similarity between image and text embeddings.
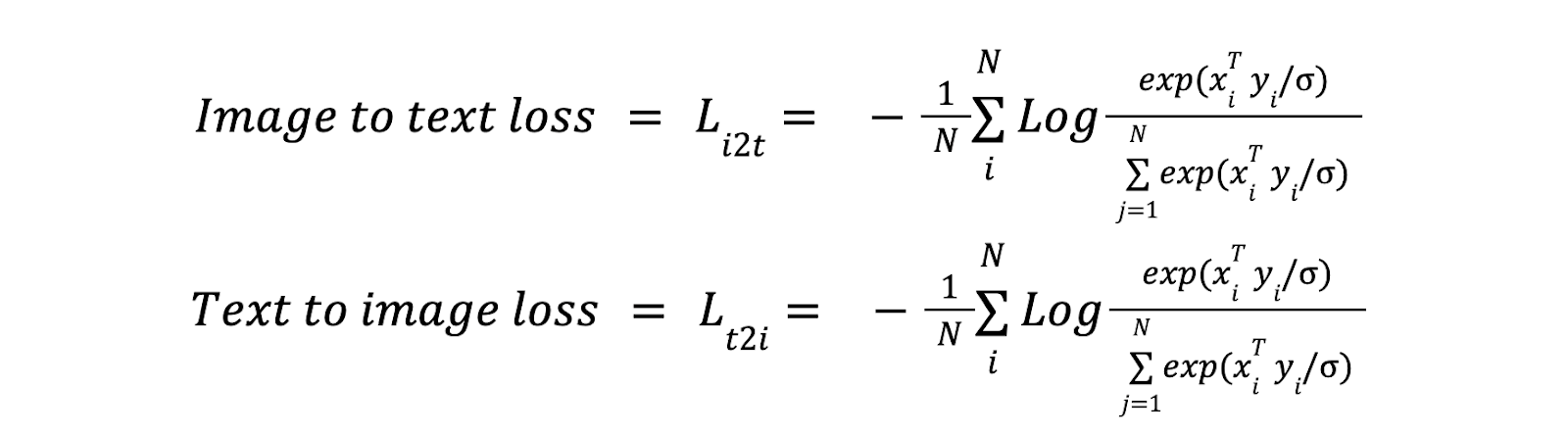 Figure- Equations.png
Figure- Equations.png
Figure: Equations
Training Techniques
Temperature Scaling: The softmax temperature helps balance embedding distances, allowing ALIGN to effectively manage the noise inherent in the dataset.
In-Batch Negatives: Negative samples are drawn from within the batch, simulating random pairings and strengthening ALIGN’s robustness against extensive data variations.
Model Evaluation
After training, the ALIGN model underwent evaluation to assess its capabilities across various visual and vision-language tasks.
Retrieval Tasks: ALIGN’s performance is tested on image-to-text and text-to-image retrieval using benchmark datasets like Flickr30K and MSCOCO. These tests are conducted with and without fine-tuning to gauge ALIGN’s adaptability. Also, ALIGN is evaluated on the Crisscrossed Captions (CxC) dataset, which extends MSCOCO annotations to support intra- and inter-modal retrieval.
Visual Classification: Zero-shot transfer of the ALIGN model was performed for visual classification tasks on the ImageNet ILSVRC-2012 benchmark and its variants. The performance was evaluated by applying the image encoder to various fine-grained classification datasets and measuring robustness on the Visual Task Adaptation Benchmark (VTAB) across multiple visual classification tasks.
Results
Various image-text retrieval and classification tasks were conducted to assess ALIGN's capabilities, including image-text matching & retrieval, zero-shot visual classification, and visual classification with image encoder only.
Image-Text Matching & Retrieval
In a zero-shot setting, ALIGN improves its image retrieval capabilities by over 7% compared to the previous SOTA, CLIP. Moreover, with fine-tuning, ALIGN significantly surpasses all existing methods, including those that utilize more complex cross-modal attention layers, such as OSCAR.

Figure: Image-text retrieval results on Flickr30K and MSCOCO datasets | Source
ALIGN achieves SOTA results in all metrics, especially by a large margin on image-to-text (+22.2% R@1) and text-to-image (20.1% R@1) tasks. R@1 stands for Recall@1. It is a metric used in information retrieval tasks, particularly in the context of ranking results.

Figure: Multimodal retrieval performance on Crisscrossed Captions (CxC) dataset | Source
ALIGN also outperforms the previous SOTA, like DEI2T, on the SITS task, improving by 5.7%.
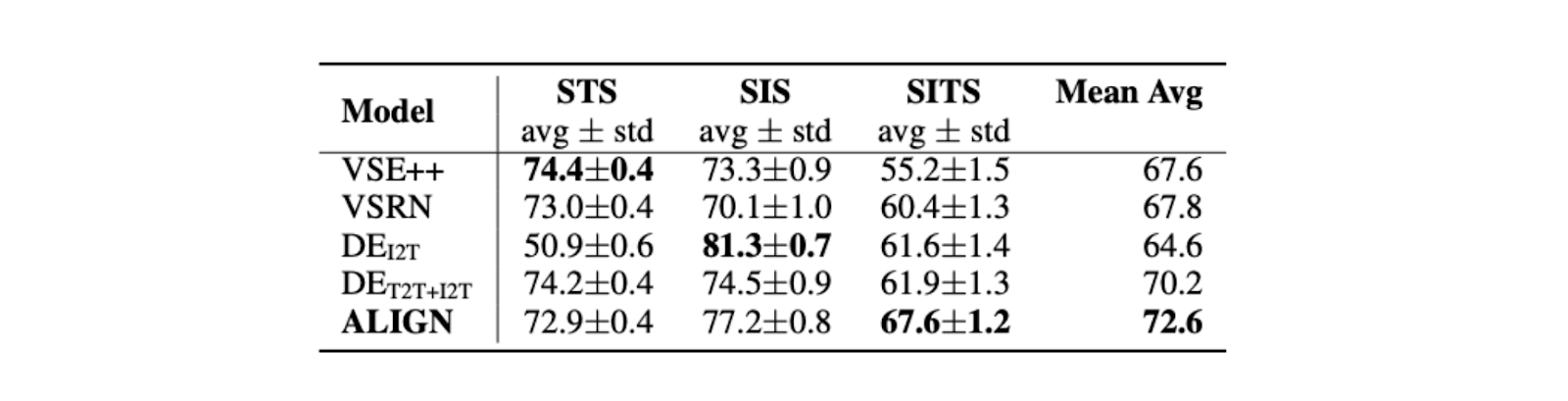 Figure- Spearman’s R Bootstrap Correlation (100) on Crisscrossed Captions (CxC) dataset.png
Figure- Spearman’s R Bootstrap Correlation (100) on Crisscrossed Captions (CxC) dataset.png
Figure: Spearman’s R Bootstrap Correlation (100) on Crisscrossed Captions (CxC) dataset | Source
Zero-shot Visual Classification
ALIGN shows great robustness on classification tasks with different image distributions. To make a fair comparison, the same prompt ensembling method as CLIP is used. Such ensembling improves ImageNet top-1 accuracy by 2.9%.
 Figure- Top-1 Accuracy of zero-shot transfer of ALIGN to image classification on ImageNet and its variants
Figure- Top-1 Accuracy of zero-shot transfer of ALIGN to image classification on ImageNet and its variants
Figure: Top-1 Accuracy of zero-shot transfer of ALIGN to image classification on ImageNet and its variants | Source
Visual Classification With Image Encoder Only
With fixed parameters, ALIGN slightly outperforms CLIP, achieving a SOTA result of 85.5% top-1 accuracy. After fine-tuning, ALIGN surpasses the accuracy of BiT and ViT models and ranks just below Meta Pseudo Labels, necessitating deeper interaction between ImageNet training and large-scale unlabeled data.
 Figure- ImageNet classification results
Figure- ImageNet classification results
Figure: ImageNet classification results | Source
ALIGN Model Applications
Beyond its performance on benchmark tasks, ALIGN proves its practical utility in real-world applications, particularly in image search. ALIGN applied it to two different tasks: image search through textual prompt and image search based on a multimodal query, i.e., image + text input.
Text-to-Image Retrieval
ALIGN retrieves images from a vast collection of 160 million CC-BY licensed images (distinct from the training set) based solely on textual queries. The queries encompass descriptions, including detailed scenes and fine-grained and instance-level concepts.
 Figure- Image retrieval with fine-grained text queries using ALIGN’s embeddings
Figure- Image retrieval with fine-grained text queries using ALIGN’s embeddings
Figure: Image retrieval with fine-grained text queries using ALIGN’s embeddings | Source
Multimodal (Image+Text) Image Retrieval
ALIGN combines image and text embeddings to retrieve relevant images for multimodal image retrieval. Specifically, given a query image and a text string, the image and text embeddings are added together to form a new query embedding for retrieval.
 Figure- Image retrieval with image+text queries
Figure- Image retrieval with image+text queries
Figure: Image retrieval with image+text queries | Source
ALIGN Implementation Using Hugging Face
ALIGN can be implemented using the Hugging Face transformer library. Here are the steps for implementing ALIGN. The code below is from HuggingFace.
Step 1: Install the Necessary Libraries
!pip install transformers
Step 2: Load Required Libraries
import requests
import torch
from PIL import Image
from transformers import AlignProcessor, AlignModel
Step 3: Loading the ALIGN Model
processor = AlignProcessor.from_pretrained("kakaobrain/align-base")
model = AlignModel.from_pretrained("kakaobrain/align-base")
Step 4: Preparing Image and Candidate Text Labels
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
candidate_labels = ["an image of a cat", "an image of a dog"]
Step 5: Preprocessing the Image and Text
inputs = processor(images=image ,text=candidate_labels, return_tensors="pt")
Step 6: Feeding Inputs to the Model
with torch.no_grad():
outputs = model(**inputs)
Step 7: Extracting Similarity Scores
# this is the image-text similarity score
logits_per_image = outputs.logits_per_image
Step 8: Converting to Probabilities
# we can take the softmax to get the label probabilities
probs = logits_per_image.softmax(dim=1)
print(probs)
After computing the image-text similarity, you may need to store the image and text feature embeddings (from EfficientNet for images and BERT for text) in a vector database like Milvus or Zilliz Cloud (managed service powered by Milvus) for efficient similarity search across large datasets. Milvus allows for efficient vector-based search, retrieving images or texts based on similarity in the latent space generated by ALIGN. For more information about Milvus, check out its documentation.
Conclusion
ALIGN is a robust and efficient solution for cross-modal and multimodal tasks. Through its simple but effective data collection and training approach, ALIGN aligns images and text with similar semantics, enabling it to handle complex queries that combine visual and textual information. This capability opens doors to more advanced search functionalities that would be challenging to achieve with a single modality (image or text) alone.
However, the ALIGN approach also highlights areas for future research.
Explore the use of diverse noisy data: Investigating the effectiveness of different types of noisy data beyond image-alt-text pairs for training visual and vision-language models.
Develop advanced architectures: Future research can focus on designing more advanced model architectures specifically tailored for learning from noisy data, potentially leading to greater efficiency and performance.
Related Resources
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
- What is ALIGN?
- Methodology
- Results
- ALIGN Model Applications
- ALIGN Implementation Using Hugging Face
- Conclusion
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Vector Databases: Redefining the Future of Search Technology
The future of search with vector databases is promising, with AI integration and context-aware experiences leading the way.
Vector Database vs Graph Database
Learn which specialized database technology best suits your data management needs of your use cases and performance attributes.

What is Object Detection? A Comprehensive Guide
Object detection is a computer vision technique that uses neural networks to classify and locate objects, such as humans, buildings, or cars, in images or video.