




What is Object Detection? A Comprehensive Guide
Object detection is a computer vision technique that uses neural networks to classify and locate objects, such as humans, buildings, or cars, in images or video.
Read the entire series
- Cross-Entropy Loss: Unraveling its Role in Machine Learning
- Batch vs. Layer Normalization - Unlocking Efficiency in Neural Networks
- Empowering AI and Machine Learning with Vector Databases
- Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
- Vector Databases: Redefining the Future of Search Technology
- Local Sensitivity Hashing (L.S.H.): A Comprehensive Guide
- Optimizing AI: A Guide to Stable Diffusion and Efficient Caching Strategies
- Nemo Guardrails: Elevating AI Safety and Reliability
- Data Modeling Techniques Optimized for Vector Databases
- Demystifying Color Histograms: A Guide to Image Processing and Analysis
- Exploring BGE-M3: The Future of Information Retrieval with Milvus
- Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
- TF-IDF - Understanding Term Frequency-Inverse Document Frequency in NLP
- Understanding Regularization in Neural Networks
- A Beginner's Guide to Understanding Vision Transformers (ViT)
- Understanding DETR: End-to-end Object Detection with Transformers
- Vector Database vs Graph Database
- What is Computer Vision?
- Deep Residual Learning for Image Recognition
- Decoding Transformer Models: A Study of Their Architecture and Underlying Principles
- What is Object Detection? A Comprehensive Guide
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Algorithmic)
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Methodological)
- Understanding CoCa: Advancing Image-Text Foundation Models with Contrastive Captioners
- Florence: An Advanced Foundation Model for Computer Vision by Microsoft
- The Potential Transformer Replacement: Mamba
- ALIGN Explained: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
Imagine you're developing a computer vision technique for a sports analysis system where locating objects in an image or video is crucial. Detecting and tracking players in a video of the game would allow you to count the number of players in specific areas, monitor their movements across zones, and even analyze their time spent in key locations. Achieving this level of detail is made possible by object detection—a computer vision task that not only identifies objects within an image or video but also pinpoints their precise locations.
Unlike simple image classification, which assigns a label to an entire image, object detection works to find instances of objects and marks their positions through bounding boxes. This custom object detection model is an important component in many AI applications we use every day, such as facial recognition, security surveillance, and medical imaging.
This article will help you understand how object detection works, the popular models and algorithms used, the challenges faced, and the future of this technology.
What Exactly is Object Detection?
Object detection is a computer vision technique that uses neural networks to classify and locate objects, such as humans, buildings, or cars, in images or video. Object detection models take an image as input and then output the coordinates for the bounding boxes that outline the detected objects, along with labels identifying those objects. An image might have multiple objects, each with its own bounding box and label, e.g., a car and a building. These objects can also be in different parts of the image, such as several cars in different spots. This concept is commonly known as multi-object detection.
To understand object detection even better, it's helpful to compare it with similar tasks:
Image Classification: This task simply determines the presence of a certain object in the image. For example, Is there a dog in the image?
Object Detection: It determines the object's class and localizes it within the image using a bounding box. For example, Where is the dog in the image, and what type of dog is it?
Image Segmentation: Segmentation provides pixel-level accuracy. It doesn’t just draw a box around the object like in object detection but defines the precise shape by assigning each pixel to a specific object class. For example, Which pixels belong to the dog, and what is the exact shape of the dog?
 Image Classification vs. Object Detection vs. Image Segmentation.png
Image Classification vs. Object Detection vs. Image Segmentation.png
Image Classification vs. Object Detection vs. Image Segmentation | Source
How Object Detection Works
Object detection systems have several essential components that work together to classify and localize objects.
Feature Extraction
Bounding boxes
Object Classification and Localization
Feature Extraction
The first step in object detection is extracting important features from the image. Features in object detectors are characteristics like edges, corners, or textures that help define objects. Convolutional Neural Networks (CNNs) are commonly used as feature extractors in modern deep learning-based approaches. They automatically learn and extract features by applying filters to the image through their convolutional layers. However, CNNs are not the only algorithms used for this purpose. Other methods include Region Proposal Networks (RPNs), HOG (Histogram of Oriented Gradients), and SIFT (Scale-Invariant Feature Transform).
When an input image is fed into a CNN, it passes through multiple convolution layers. The network identifies basic features like edges and corners in image recognition in early layers. As the image passes through deeper layers, the network learns more complex features, like parts of objects. This hierarchical process helps the network understand the essential features of different objects and detect them more effectively.
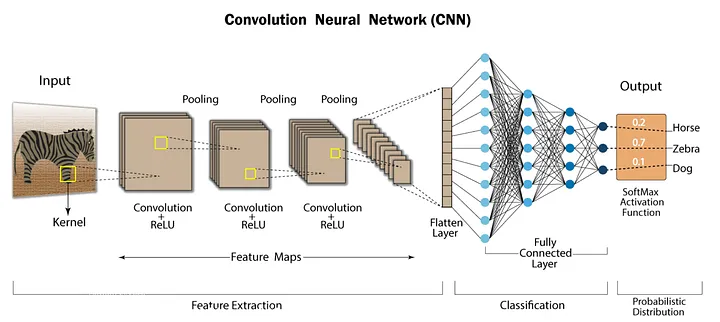 Convolutional neural network (CNN) architecture.png
Convolutional neural network (CNN) architecture.png
Convolutional neural network (CNN) architecture | source
Bounding boxes
A bounding box is a rectangle drawn around the detected object. Four values define it:
𝑥, 𝑦, width 𝑤, and height ℎ. Depending on the model, the coordinates (𝑥, 𝑦) can either represent the center of the box (in models like YOLO) or the top-left corner (in models like Faster R-CNN), while 𝑤 and ℎ determine the box's dimensions. In deep learning models, bounding box coordinates are adjusted through regression–a process where neural networks refine the predicted coordinates of the box to fit the object better. The model predicts an offset (Δ𝑥, Δ𝑦, Δ𝑤, Δℎ) to adjust the position and size of the bounding box.
To evaluate how well the predicted bounding box matches the ground truth, a metric called Intersection over Union (IOU) is used. It measures the overlap between the predicted and actual bounding boxes. Mathematically, it's defined as:
IoU=AIntersectionAUnion
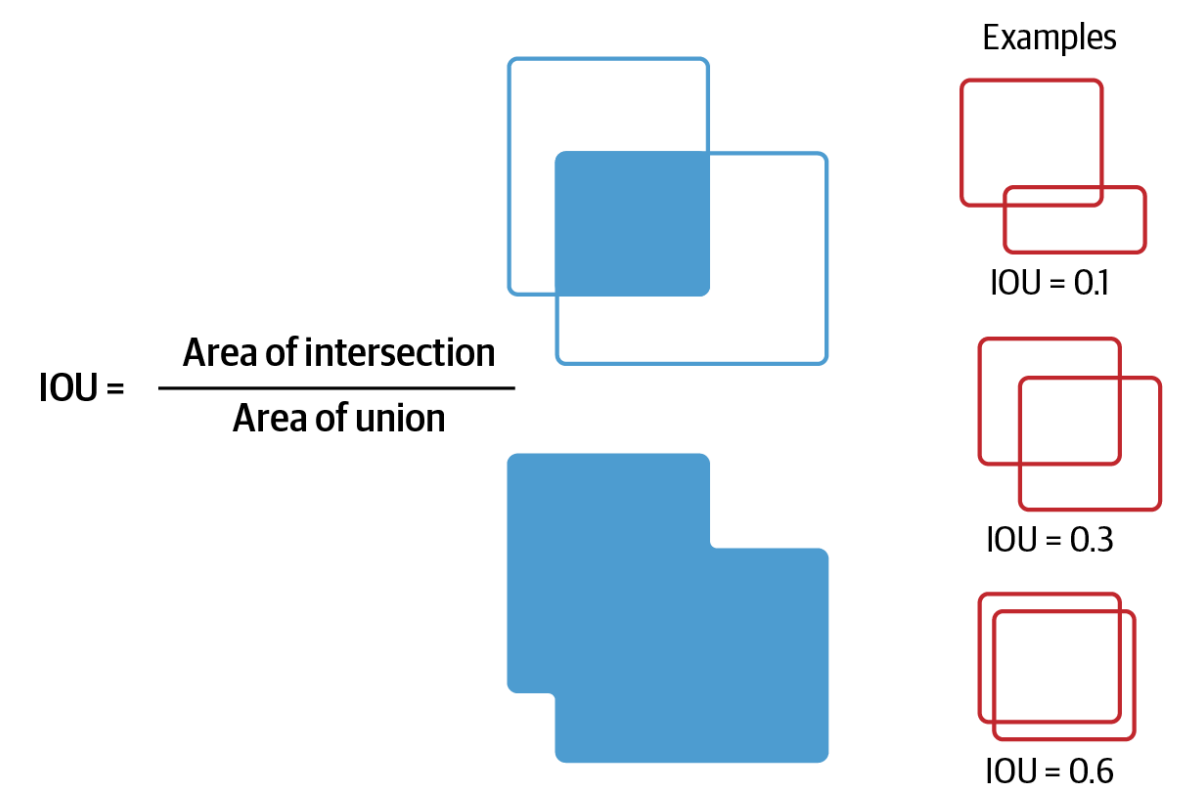 The IOU metric.png
The IOU metric.png
The IOU metric | Source
A higher IoU value means the prediction closely matches the actual object, while a lower value indicates poor localization.
Classification
Once the objects are localized, the object detection system assigns a label, such as "car" or "person," to each detected object. Classification is often performed using fully connected layers in CNNs, which take the extracted features as input and output class probabilities.
Although deep learning is now the leading approach, traditional object detection methods still exist. These methods often use hand-engineered features and algorithms, such as the Harris corner detector, Scale-invariant feature transform (SIFT), speeded-up robust features (SURF), and Histogram of oriented gradients (HOG).
Let's compare these traditional object detection methods to understand how they differ from modern deep learning-based methods.
| Aspect | Deep Learning-Based Methods | Traditional Methods |
| Feature Extraction | Automatically learns features from data using multiple layers. | Relies on handcrafted features like corners, edges, and gradients. |
| Scalability | Scalable to large datasets and complex real-world environments. | Less scalable; struggles with complex real-world scenarios and large datasets. |
| Speed | Modern models like YOLO and SSD are designed for real-time performance. | Slow due to manual extraction and reliance on iterative algorithms. |
| Accuracy | High accuracy due to deep feature learning and the ability to generalize well to different tasks. | Moderate accuracy, particularly sensitive to changes in viewpoint, scale, or lighting. |
| Methods | CNN, YOLO, R-CNN, SSD, EfficientDet. | Harris corner detector, SIFT, SURF, HOG. |
| Resource Requirements | Often requires significant computational power (GPUs) and large datasets for training. | Less computationally intensive but requires expert-designed features. |
Popular Object Detection Models Explained
Object detection has seen the rise of several influential deep learning models, each of which has unique advantages. Some of the popular deep learning anomaly detection models are:
YOLO
R-CNN Family
SSD (Single Shot Multibox Detector)
EfficientDet
YOLO
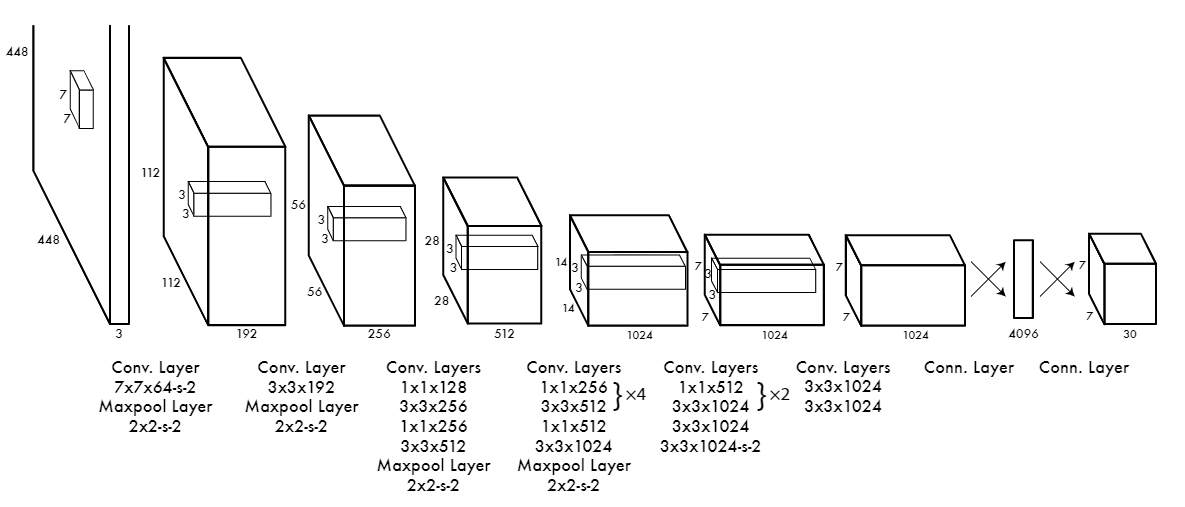 YOLO Architecture.png
YOLO Architecture.png
YOLO Architecture | Source
YOLO (You Only Look Once) is a simple yet highly efficient object detection architecture. It is one of the fastest when it comes to prediction times. For that reason, it is used in many real-time systems like security cameras. Unlike other models that take a two-step approach deep learning object detection (first propose regions and then classify objects), YOLO does it all at once. It divides the input image into a grid and, at the same time, predicts bounding boxes and object classes for each grid cell. This grid-based structure enables YOLO to make fast predictions in one pass through the network, significantly reducing processing time.
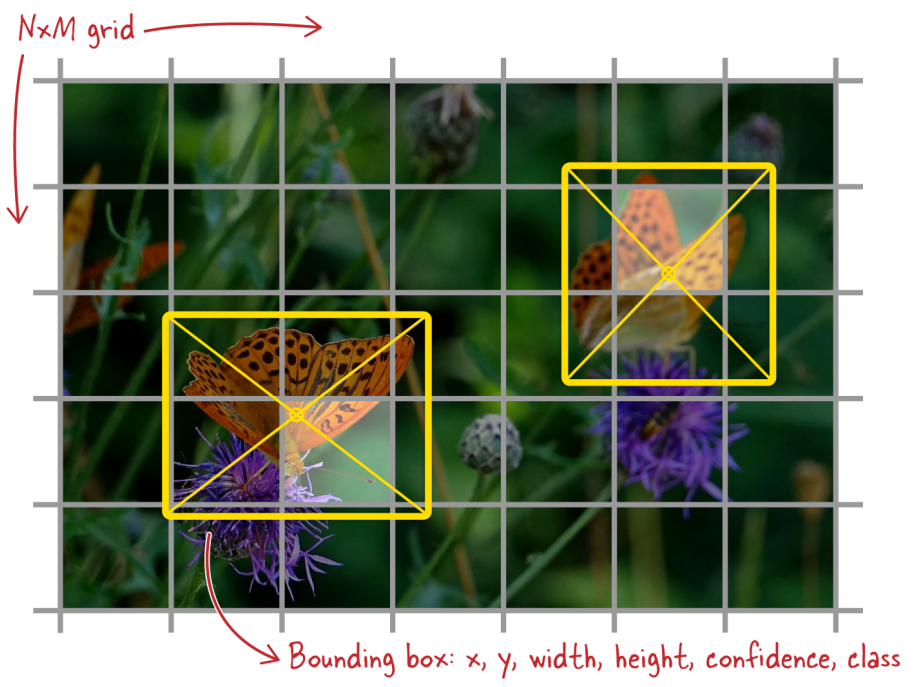 The YOLO grid.png
The YOLO grid.png
The YOLO grid | Source
x, y: The coordinates of the bounding box center relative to the grid cell.
w, h: The width and height of the bounding box are scaled to the entire image.
Confidence: The probability that the box contains an object.
Class: The object belonging to a specific class.
However, while YOLO excels in speed, it may sacrifice some accuracy, especially when detecting smaller objects. This is because YOLO divides the input image into a grid, and each grid cell can only predict one object. When small objects fall within a single grid cell or overlap the boundaries of multiple grid cells, YOLO may struggle to localize or distinguish them from surrounding objects precisely. As a result, smaller objects can be missed or inaccurately classified.
R-CNN Family
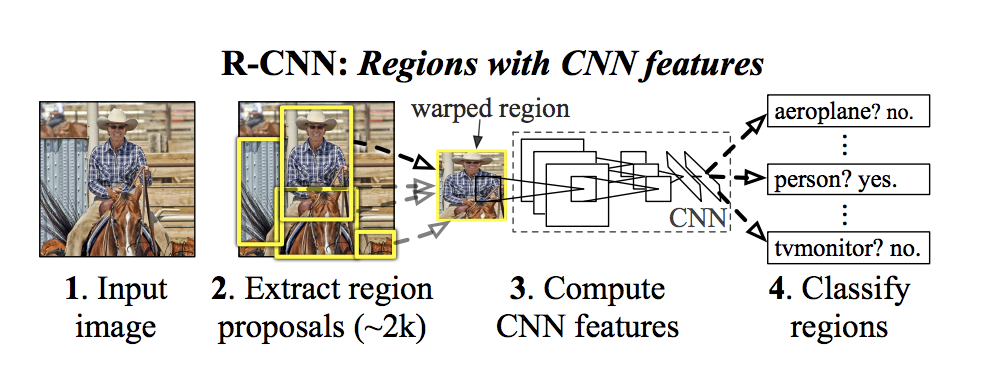 The R-CNN Architecture.png
The R-CNN Architecture.png
The R-CNN Architecture | Source
The R-CNN (Regions with Convolutional Neural Networks) models, including Fast R-CNN and Faster R-CNN, have an important role in improving object detection techniques. The original R-CNN worked by first finding areas in the image that might contain objects (using a region proposal method). Then, it used a CNN to extract and classify features from those areas, leveraging an SVM technique. Fast R-CNN made this process faster by allowing the model to reuse the same calculations for all the proposed regions and adding a way to handle multiple tasks at once.
Finally, Faster R-CNN made things even faster by introducing the Region Proposal Network (RPN).
SSD (Single Shot Multibox Detector)
 Single Shot Multi-Box Detector (SSD) architecture.png
Single Shot Multi-Box Detector (SSD) architecture.png
Single Shot Multi-Box Detector (SSD) architecture | Source
Like YOLO, Single Shot Multibox Detector (SSD) processes the image in a single pass, but it takes a more refined approach by using multiple feature maps at different scales. This enables SSD to detect objects of various sizes, particularly smaller ones. While SSD is faster than Faster R-CNN, it generally provides more accuracy than YOLO, maintaining a good balance between speed and precision.
This balance makes SSD a good choice for applications that require both efficiency and reliable detection.
EfficientDet
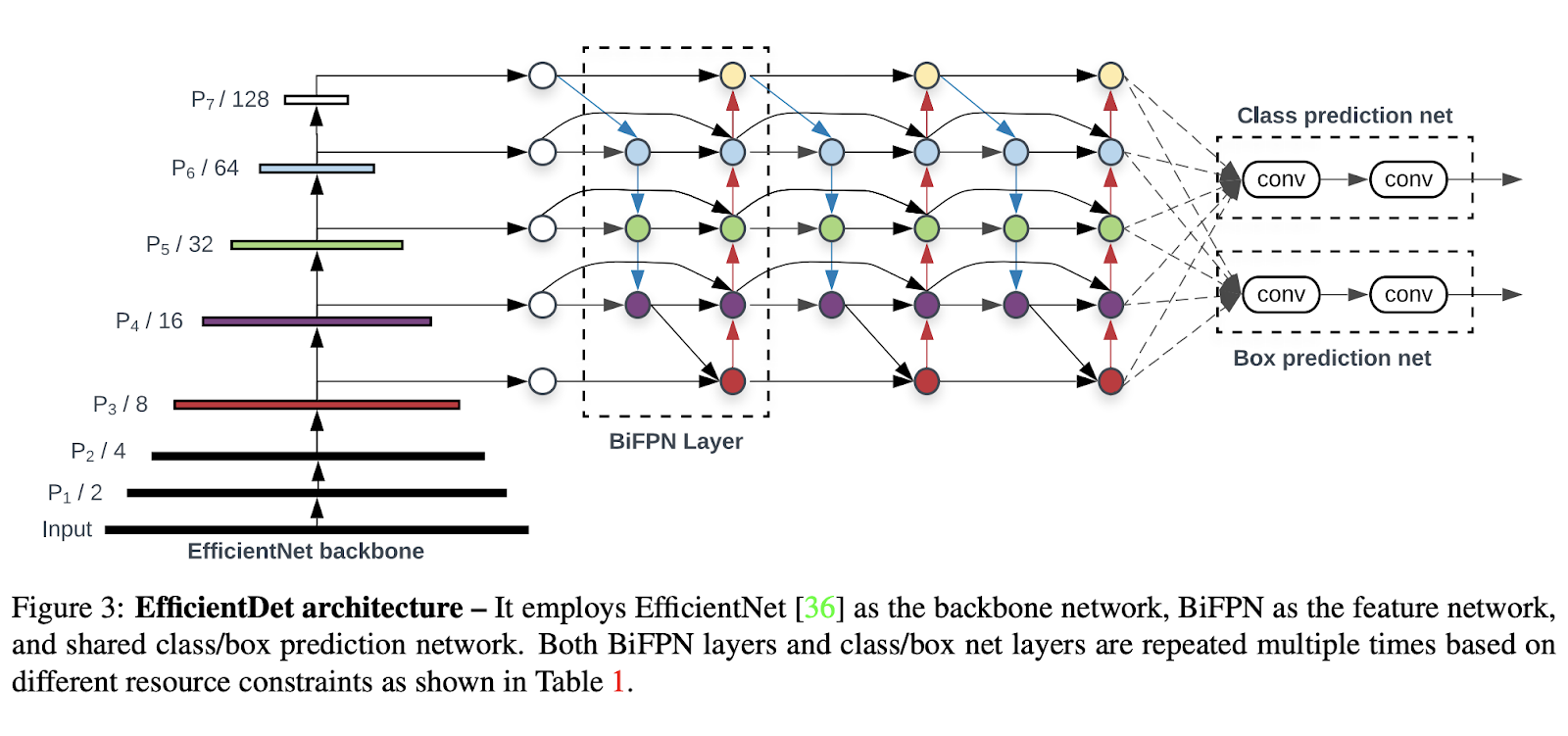 EfficientDet architecture.png
EfficientDet architecture.png
EfficientDet architecture | Source
EfficientDet is designed with efficiency in mind, aiming to achieve high accuracy while using fewer computational resources. It uses the Bidirectional Feature Pyramid Network (BiFPN), which helps improve the model's ability to detect objects at different scales. Additionally, EfficientDet uses a compound scaling method that adjusts the network's depth, width, and resolution simultaneously.
This means it scales the feature extraction, classification, and box prediction networks in a balanced way, ensuring high performance without excessive computational demands.
Applications of Object Detection
Object detection is a critical technology that helps machines interpret and understand visual data. It is crucial in improving automation, safety, and efficiency across various industries. Below are some of the most significant applications of the object recognition and detection in real-world scenarios:
Autonomous Vehicles: Autonomous vehicle systems rely heavily on object detection to recognize and identify different objects in the vehicle's surroundings. This includes detecting pedestrians, other cars, cyclists, and traffic signs. Real-time detection is important for the safe operation of these vehicles as it helps the car navigate through complex environments without human involvement.
Healthcare: In healthcare, object detection is applied in medical imaging to assist doctors and radiologists in identifying anomalies like tumors, fractures, or other conditions in various types of scans, such as X-rays, CT scans, and MRIs. This technology helps improve the speed and accuracy of diagnoses, which can be critical in life-threatening conditions like cancer or internal injuries.
Surveillance and Security: In the security and surveillance domain, object detection is used for different purposes, such as facial recognition, suspicious activity detection, and identifying unauthorized access in restricted areas. For example, cameras equipped with object detection algorithms can automatically identify and track individuals or detect abandoned objects in a public space, triggering alarms for potential security threats.
Retail and E-commerce: Modern stores use object detection to track inventory and automate checkout processes in the retail and e-commerce sectors. A prime example is Amazon Go stores, where customers can pick up products and leave without waiting in lines for traditional checkouts. The system uses cameras and object detection algorithms to automatically track which items a customer has picked, and the total is billed directly to their account.
Challenges in Object Detection
Despite its numerous advantages in different applications, object detection faces several technical challenges:
Real-time Performance: One of the main challenges in object detection is balancing speed and accuracy, especially in time-sensitive applications. Real-time systems, like those used in autonomous driving or surveillance cameras, require decisions to be made in just a few milliseconds. In critical scenarios, such as detecting pedestrians in self-driving cars, even a small delay in detection can lead to serious consequences.
Occlusion: It occurs when one object partially or fully obscures another object in an image. This creates a significant challenge for object detection models, as they rely on the full visibility of objects to correctly identify them.
Scale Variance: Objects in an image can appear at vastly different sizes, which poses a challenge for detection models. An object may appear small in one image and large in another, depending on its distance from the camera or actual size. Models must be robust enough to handle these variations and accurately detect objects at different scales.
Adverse Lighting Conditions: Poor or inconsistent lighting, particularly outdoors, can significantly impact the object detection model's accuracy.
Future Trends and Advancements
Object detection technology is constantly transforming because of technological advancements and growing demands for application across various industries. Here are some exciting future trends:
Edge Computing: Many devices, like drones and smartphones, use AI to perform tasks like object detection on the device directly. This reduces the need to send data to cloud servers for processing. For example, modern smartphones with AI-powered cameras, such as the Google Pixel, use edge computing for real-time object detection.
3D Object Detection: As fields like robotics, augmented reality (AR), and virtual reality (VR) expand, the need for detecting objects in three-dimensional space becomes increasingly important. Moving beyond traditional 2D detection, 3D object detection allows for more accurate spatial modeling. For example, Autonomous vehicles, such as those developed by Tesla and Waymo, use 3D object detection to identify pedestrians, other vehicles, and obstacles in their environment.
Hybrid Models: Combining object detection with other AI fields like tracking and reasoning enables more advanced applications, such as understanding complex scenes or predicting object behavior. For Example, In surveillance systems, hybrid models not only detect objects (like people or vehicles) but also track their movement over time and predict behavior.
Summary
Object detection has emerged as a transformative technology, enabling computers to perceive and interpret the visual world accurately. From self-driving cars navigating busy streets to medical imaging systems detecting subtle anomalies, its applications are vast and continue to expand.
We've explored the fundamental principles of an object detection model and its key components, such as feature extraction, bounding boxes, and classification. We've also examined the evolution of object detection models from traditional methods to the deep learning-based architectures that dominate the field today.
While challenges remain, such as achieving real-time performance in complex environments and handling occlusions and scale variations, the future of object detection is bright. Advancements in edge computing, 3D object detection, and hybrid models promise to enhance its capabilities further and explore new possibilities.
Related Resources
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
- What Exactly is Object Detection?
- How Object Detection Works
- Popular Object Detection Models Explained
- Applications of Object Detection
- Challenges in Object Detection
- Future Trends and Advancements
- Summary
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Empowering AI and Machine Learning with Vector Databases
How AI Databases help businesses get that competitive edge in the digital age

Data Modeling Techniques Optimized for Vector Databases
This post explores various data modeling techniques for optimizing the performance of vector databases.

Understanding CoCa: Advancing Image-Text Foundation Models with Contrastive Captioners
Contrastive Captioners (CoCa) is an AI model developed by Microsoft that is designed to bridge the capabilities of language models and vision models.