




Decoding Transformer Models: A Study of Their Architecture and Underlying Principles
A Transformer model is a type of architecture for processing sequences, primarily used in natural language processing (NLP).
Read the entire series
- Cross-Entropy Loss: Unraveling its Role in Machine Learning
- Batch vs. Layer Normalization - Unlocking Efficiency in Neural Networks
- Empowering AI and Machine Learning with Vector Databases
- Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
- Vector Databases: Redefining the Future of Search Technology
- Local Sensitivity Hashing (L.S.H.): A Comprehensive Guide
- Optimizing AI: A Guide to Stable Diffusion and Efficient Caching Strategies
- Nemo Guardrails: Elevating AI Safety and Reliability
- Data Modeling Techniques Optimized for Vector Databases
- Demystifying Color Histograms: A Guide to Image Processing and Analysis
- Exploring BGE-M3: The Future of Information Retrieval with Milvus
- Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
- TF-IDF - Understanding Term Frequency-Inverse Document Frequency in NLP
- Understanding Regularization in Neural Networks
- A Beginner's Guide to Understanding Vision Transformers (ViT)
- Understanding DETR: End-to-end Object Detection with Transformers
- Vector Database vs Graph Database
- What is Computer Vision?
- Deep Residual Learning for Image Recognition
- Decoding Transformer Models: A Study of Their Architecture and Underlying Principles
- What is Object Detection? A Comprehensive Guide
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Algorithmic)
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Methodological)
- Understanding CoCa: Advancing Image-Text Foundation Models with Contrastive Captioners
- Florence: An Advanced Foundation Model for Computer Vision by Microsoft
- The Potential Transformer Replacement: Mamba
- ALIGN Explained: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
The introduction of the transformer model marked an evolution in natural language processing (NLP). Originally conceptualized for tasks like machine translation, the Transformer has since been adapted into various forms—each tailored for specific applications. These include the original encoder-decoder structure, and encoder-only and decoder-only variations, catering to different facets of NLP challenges.
This blog discusses the Transformer model, starting with its original encoder-decoder configuration, and provides a foundational understanding of its mechanisms and capabilities. By exploring the intricate design and the operational dynamics of the model, we aim to shed light on why the Transformer has become a cornerstone in modern NLP advancements.
Transformer Overview
Since its inception, the transformer model has been a game-changer in natural language processing (NLP). It appears in three variants: encoder-decoder, encoder-only, and decoder-only. The original model was the encoder-decoder form, which provides a comprehensive view of its foundational design.
The self-attention mechanism is at the core of the Transformer architecture, primarily developed for translating languages. Here's how it works: A sentence is broken down into pieces called tokens. These tokens are processed through multiple layers in the encoder. Each layer refines the tokens by pulling information from other tokens, enriching them with greater context through self-attention. This process yields deeper, more meaningful token representations or embeddings.
Once enhanced, these embeddings pass to the decoder. The decoder, structured similarly to the encoder, utilizes both self-attention and an additional feature known as cross-attention. Cross-attention allows the decoder to access and incorporate relevant information from the encoder's output, ensuring the translated words align well with the source context.
In practice, translating a word requires pinpointing relevant details from the source sentence—particularly from tokens closely related to the target word. The decoder then generates words in the target language one at a time, using the context of the building sentence as a guide until it reaches a special token that signifies the sentence's end. This attention-driven approach enables the model to produce translations that are not only accurate but contextually nuanced.
The Architecture of a Transformer Model
The diagram below presents the architecture of a Transformer model.
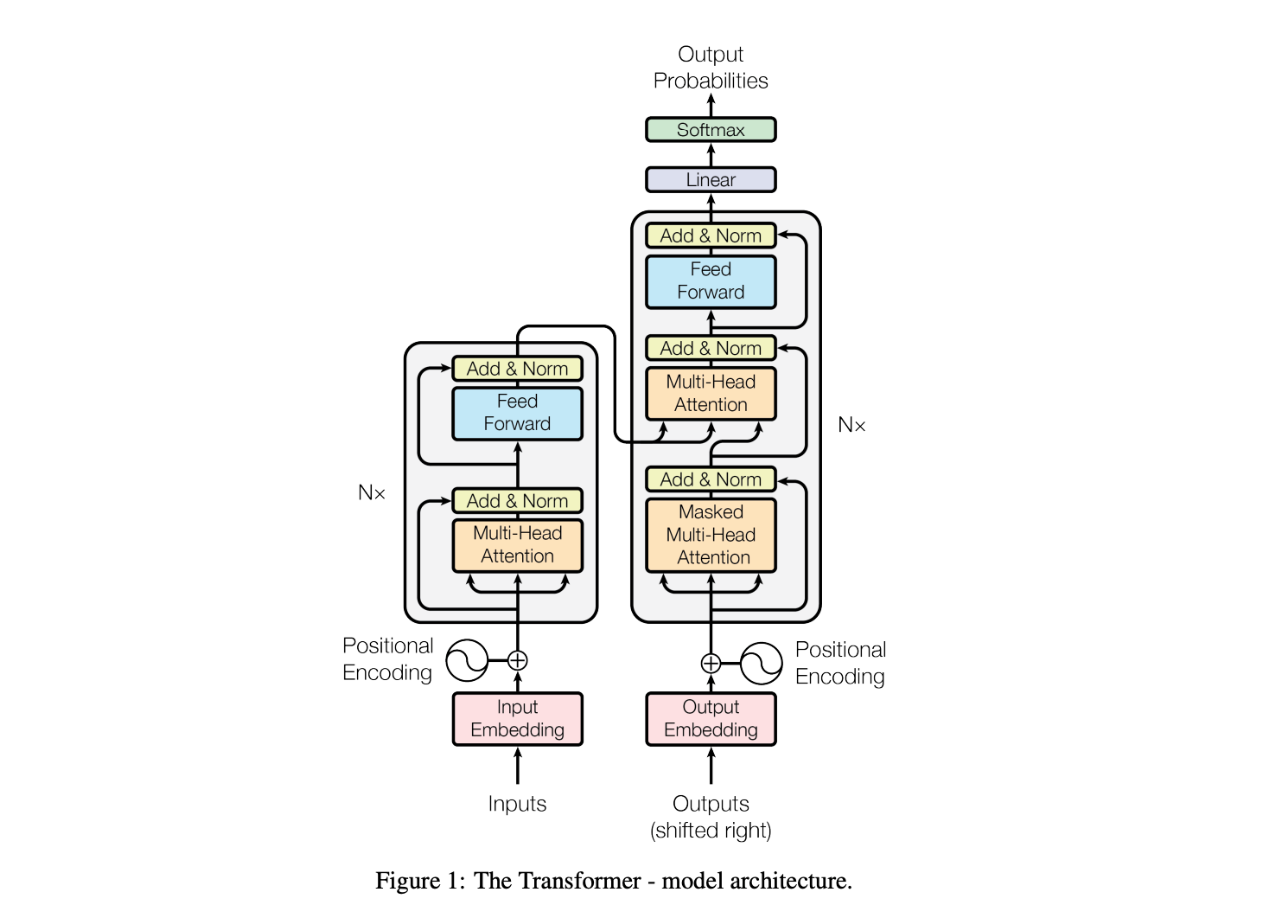 the architecture of a Transformer model..png
the architecture of a Transformer model..png
At the bottom left, the inputs represent the source text, converted into input embeddings through an embedding layer. This embedding layer is a dictionary that looks up a corresponding vector for each token. After obtaining the token embeddings, a positional encoding is added. This positional encoding helps the model understand the relative positions of tokens. It is crucial for attention mechanisms since the model itself doesn't inherently perceive token order—a vital factor in processing language.
Next, the token embeddings and positional encodings enter the Multi-Head Attention module. This module allows the model to simultaneously attend to different parts of the input sequence. A residual connection and an Add & Norm layer are applied following the attention mechanism. These structures, which include residual connections and layer normalization, are empirical techniques that enable the training of deeper networks by preventing vanishing gradients and helping the model converge more efficiently. You'll notice that these structures appear consistently across other parts of the model.
The output of the Multi-Head Attention then passes through a Feed-Forward module. This feed-forward network applies the same transformation and nonlinearity to each embedding independently, making the embeddings more representative and suitable for the task at hand. The "N×" symbol on the left of the encoder stack indicates that this is a multi-layered architecture—each layer's output becomes the input for the next layer.
On the right side of the image is the decoder, which shares an architecture similar to that of the encoder. However, there are key differences. The decoder includes a Masked Multi-Head Attention layer, which ensures that each embedding can only attend to earlier positions, preventing information from future tokens from leaking into the current position. Additionally, the decoder utilizes cross-attention, where it attends to the encoder's output (you can see the flow from the encoder's output) embeddings to align the context of the source language with the generation of the target language.
Finally, after passing through the decoder stack, the output embeddings are transformed into probabilities through a softmax layer, which predicts the next word in the target sequence. This process is repeated until a special token, typically marking the end of the sentence, is generated.
Understanding Encoder Core Concepts
There are several modules involved in the encoder; let's check each of them.
Scaled Dot-Product Attention
The core of Multi-Head Attention (MHA) is the Scaled Dot-Product Attention mechanism. To better understand MHA, let's illustrate this concept first.
Intuitively, attention means that each embedding needs to attend to related embeddings to gather contextual information. There are three roles in attention calculation: Queries(Q), Keys(K), and Values(V). Imagine you have N query embeddings and M key-value pairs. Here’s how the attention mechanism unfolds:
Relevance Calculation: The mechanism computes each query embedding's relevance to each of the M key embeddings. This is often done using a dot product between the query and each key.
Normalization: The results of these calculations are then normalized. This step ensures that the total of all relevance scores adds up to one, facilitating a proportional representation where each score reflects the degree of relevance between the query and a key.
Contextualization: Finally, each query embedding is reassembled into a new, contextualized form. This is achieved by combining the value embeddings corresponding to each key, weighted by the normalized relevance scores.
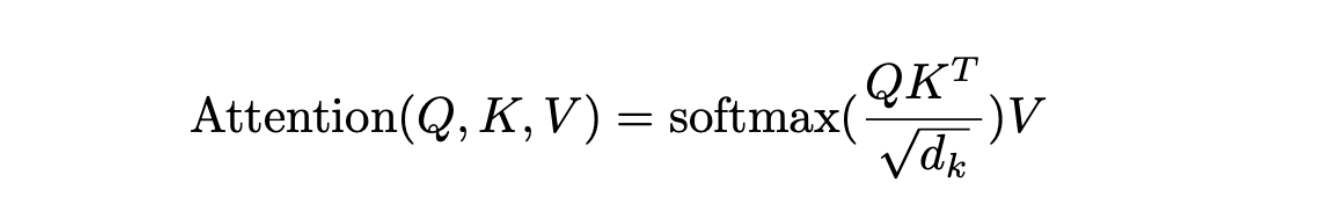 Scaled Dot-Product Attention formula.png
Scaled Dot-Product Attention formula.png
This formula above is the definition of Scaled Dot-Product Attention: All N query embeddings (with dimension ) are stacked into an matrix Q. Similarly, K and V are matrices representing M key embeddings and value embeddings, respectively. Using matrix multiplication, we obtain an matrix, where each row corresponds to a query embedding's relevance to all M key embeddings. We then apply the softmax operation to normalize the rows, ensuring that each query's relevance scores sum to 1. Next, we multiply this normalized score matrix with the V matrix to obtain the contextualized representations.
Additionally, it's important to note that the attention scores are scaled by . The original authors explain that high dimensionality leads to large dot product scores, which can cause the softmax function to disproportionately assign high attention to a single key. To mitigate this problem, the dot products are scaled by , resulting in more balanced attention weights.
Multi-Head Attention
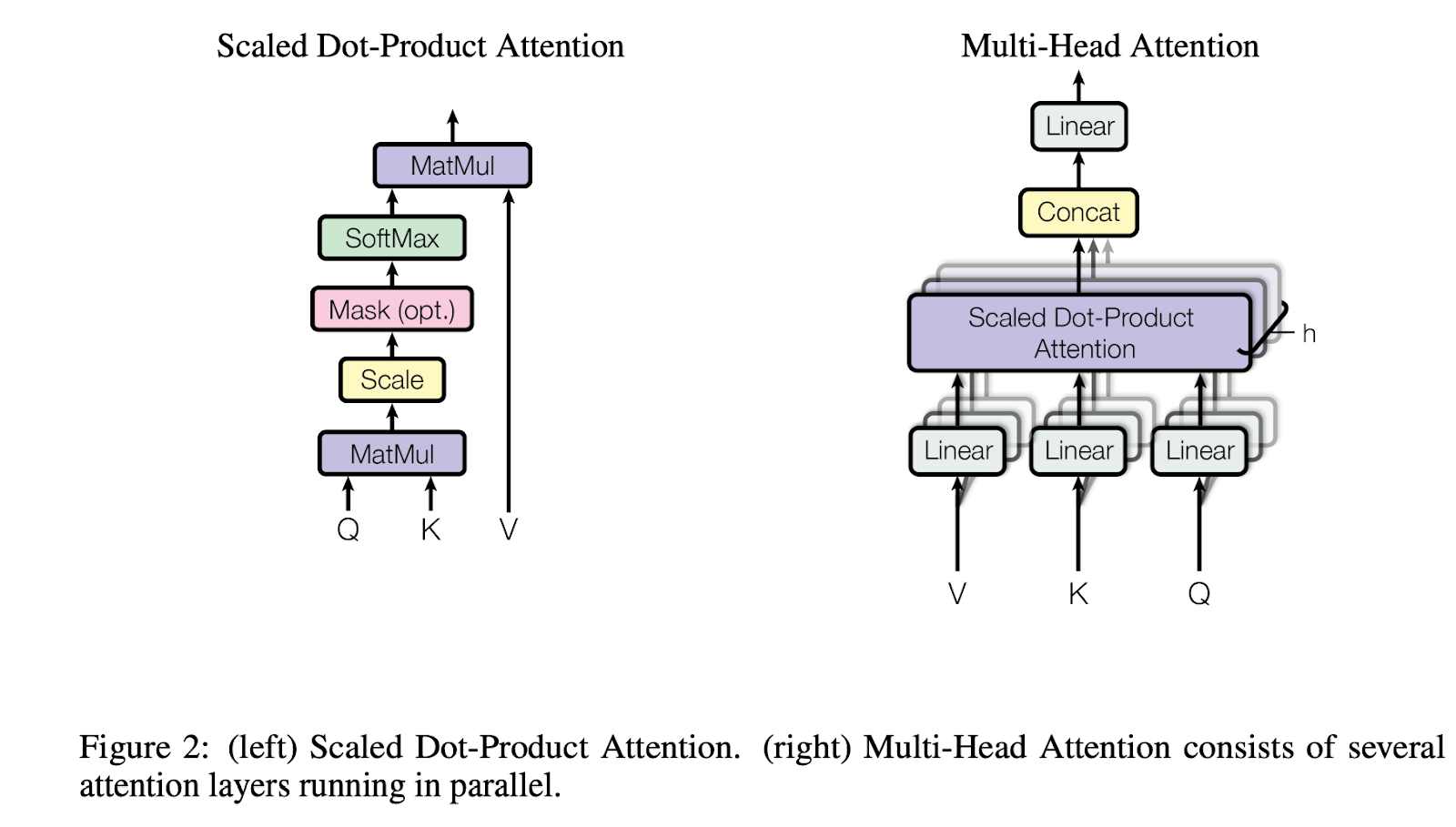 Multi-Head Attention.png
Multi-Head Attention.png
The Transformer model employs a technique known as Multi-Head Attention to enhance its processing capabilities. This mechanism begins by transforming the components of attention—Queries (Q), Keys (K), and Values (V)—through linear layers. This transformation introduces additional parameters, bolstering the model's ability to learn from more data and, consequently, its overall performance.
Within the Multi-Head Attention mechanism, these transformed Q, K, and V elements undergo the Scaled Dot-Product Attention process. The original design specifies multiple (typically eight) parallel instances of these Linear and Attention layers. This parallel processing not only speeds up computations but also introduces more parameters, further refining the embeddings.
Each parallel instance generates a unique transformed embedding from each query, known as a "head." With eight such heads, and assuming each head has a dimension of , the combined output from all heads results in a total dimension of 8x. To integrate these results back into the model’s primary workflow, another linear layer projects this concatenated output using the projection matrix , resizing it to the model's specified dimension, . This structured approach allows the Transformer to leverage multiple perspectives simultaneously, significantly enhancing its ability to discern and interpret complex data patterns.
 Multi-Head Attention formula.png
Multi-Head Attention formula.png
In the Multi-Head Attention mechanism of the Transformer, the layers , , and (where i denotes one of the 8 instances) are three linear layers dedicated to transforming the Queries (Q), Keys (K), and Values (V) for attention computation. These layers project the embeddings into dimensions , , and respectively, which are typically the same size.
The core idea behind the attention mechanism is to enhance each word's embedding by integrating contextual information from surrounding words. For instance, in translating the English sentence "Apple company designed a great smartphone." to French, the word "Apple" needs to absorb context from adjacent words like "company." This helps the model to understand "Apple" as a business entity rather than the fruit, influencing the translation towards "pomme" in a business context rather than its literal fruit meaning. This process is known as self-attention.
On the other hand, in the decoder part of the Transformer, a technique called cross-attention is used. This involves the decoder attending to different pieces of information from the encoder's output, enabling it to integrate diverse and relevant data from the source text into the translated output. This distinction in attention types helps the Transformer model effectively handle various translation nuances by focusing on the appropriate context.
Positional Encoding
Understanding positional encoding becomes more intuitive once you're familiar with the attention mechanism in the Transformer model. A key challenge with Multi-Head Attention (MHA) is that it doesn't inherently account for the order of words in a sentence.
Consider a simple sentence: "Tim gives Sherry a book." In MHA, the query (Q) embedding for "Sherry" interacts with its corresponding key (K) and value (V) embeddings without any awareness of its position in the sentence. However, the sequence in which words appear is vital for grasping their meaning.
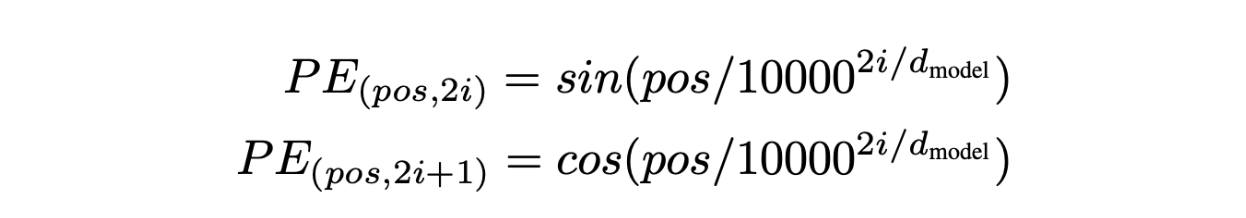 Positional Encoding formula.png
Positional Encoding formula.png
To address this, we modify the attention calculation to include positional information. For example, we want the dot product calculation, to reflect their positions, turning into This adjustment allows the model to recognize and utilize the placement of words within the sentence.
Positional encoding is implemented by adding a special embedding to each token's embedding. This positional embedding has the same dimension, , and assigns each position in the sentence a unique encoding. Cosine and sine functions generate these encodings for odd and even indices, respectively. This method ensures that the positional information is seamlessly integrated into the base embeddings, enhancing the model's ability to interpret and generate text based on the order of words.
Feed Forward Network
Following the Multi-Head Attention (MHA) stage, where embeddings are refined through interactions to form a contextualized representation, each of these embeddings is processed through a Feed Forward Network (FFN), further enhancing their representational capabilities.
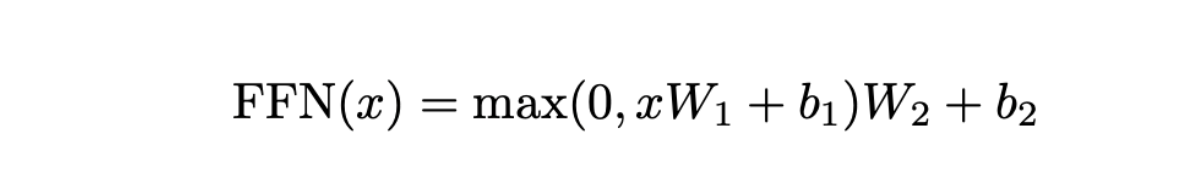 Feed Forward Network formula.png
Feed Forward Network formula.png
The FFN starts with an input, denoted as , which is an embedding of dimension , typically set to 512. The first component of the FFN is a linear layer characterized by parameters and . This layer expands the embedding from 512 dimensions to a larger, 2048-dimensional space. Following this expansion, the ReLU activation function, defined as , is applied. ReLU is a popular choice for introducing non-linearity, which is crucial for enhancing the model's ability to capture complex patterns and interactions in the data.
Next, another linear layer, equipped with parameters and , projects the embedding back down to the original 512 dimensions. This two-step process with an interjected non-linearity is essential. Without it, the entire operation would be linear, and could potentially be collapsed into the preceding MHA layer, thereby losing critical modeling flexibility.
After passing through this feed-forward layer, the embedding is transformed into a highly capable, contextualized version. When several (typically six) Transformer layers are stacked, each layer enriching the embeddings in this manner, the result is a deep, richly abstract representation of the original token embeddings. These enhanced embeddings are then ready to be decoded into the target language, equipped with nuanced and comprehensive linguistic information.
Decoder
The decoder in the Transformer model also comprises several layers, distinguished from the encoder primarily by including a masked Multi-Head Attention (MHA) mechanism. Unlike in the encoder, this MHA block in the decoder is paired with a cross-attention module that interacts with the encoder's output, which is critical for translating input sequences into the target language.
The decoding process begins with a special token,
The decoder's first task is to predict the token following
From the initial token "L'entreprise," the decoder continues to predict the subsequent tokens. For instance, after "L'entreprise," the next token predicted with the highest probability is "Apple." This step-by-step token generation continues until the decoder produces the
The decoder also incorporates a final layer that calculates the probabilities of potential next tokens, effectively determining the most likely continuation at each step of the sequence. This layer is crucial for ensuring that the output is not only grammatically correct but also contextually appropriate based on the input provided by the encoder.
Masked Multi-Head Attention
The biggest difference between decoding and encoding is how they gather contextual information for each embedding. In encoding, each embedding has access to all other embeddings (meaning it gathers contextualized information from the entire sequence). In decoding, however, the model can only gather information from the preceding text and cannot see future information that hasn't been generated yet. This is referred to as causality in language models.
| <start> | L'entreprise | <mask> | <mask> | <mask> | <mask> | <mask> |
| <start> | L'entreprise | Apple | <mask> | <mask> | <mask> | <mask> |
| <start> | L'entreprise | Apple | a | <mask> | <mask> | <mask> |
| <start> | L'entreprise | Apple | a | conçu | <mask> | <mask> |
| <start> | L'entreprise | Apple | a | conçu | un | <mask> |
| <start> | L'entreprise | Apple | a | conçu | un | excellent |
....
In the Masked MHA process, the highlighted token is the query embedding, and the tokens in the same row represent its scope of attention. "L'entreprise" shouldn't use information from "Apple"; otherwise, this would cause inconsistency in the decoding process. This ensures that each generated token has the highest probability based on the information it has received. Otherwise, if a generated token later becomes a middle token and can receive information from tokens generated after it, it might result in a different choice than when it was initially generated and could only receive information from preceding tokens. This could cause confusion in the decoding process. The practical method is to apply a mask for each token. For example, when generating the token "smartphone" from the sequence "
Cross Attention Multi-Head Attention
To ensure the decoder accurately transforms the information from an English sentence into a coherent French translation, it employs Cross-Attention Multi-Head Attention. Without this, the decoder might only generate disjointed French phrases, lacking any direct reference to the original English context. Cross-Attention MHA addresses this by integrating information from the encoder's output—the encoded English sentence embeddings—into the decoding process.
In this setup, similar to self-attention where each French token in the sequence builds context from previously generated French tokens, cross-attention allows these tokens to also access the full scope of the encoded English tokens. Here, unlike in self-attention, the keys and values in the attention mechanism are derived from these final encoded English embeddings, and there is no need for masking since the entire English sentence is available and relevant.
This architecture ensures that each French token generated is informed by a rich context of the corresponding English sentence, allowing for a translation that maintains semantic integrity and logical consistency.
Moreover, this approach illustrates a broader principle in generative AI: embedding specific conditions—like instructions, masks, or labels—into latent embeddings and employing cross-attention to integrate these into the generative model's workflow. This method offers a way to control and guide the data generation process based on predefined conditions. As different types of data can be represented as embeddings, cross-attention is an effective tool to bridge and synthesize information across various data types, enhancing the model's ability to generate contextually relevant and controlled outputs.
Final Predict Head
After Nx decoder processing, we need to decode embedding back to French token. The Final Prediction Head takes the last embedding in the sequence, generated by the decoder, and transforms it into a probability distribution over the French vocabulary. This is done using a linear layer followed by a softmax function. The linear layer scores each possible next token, and the softmax converts these scores into probabilities, allowing the model to predict the most likely next word in the sequence.
An Inference Example Using the Transformer Model
We have described the modules involved in the Transformer. To illustrate how the Transformer model works, let's go through the process of translating the English sentence "Apple company designed a great smartphone." into French from a data flow perspective:
1. Tokenization and Embedding:
The sentence is tokenized into discrete elements—words or phrases—which are indexed from a predefined vocabulary.
Each token is then converted into a vector using an embedding layer, turning words into a form the model can process.
2. Positional Encoding:
- Positional encodings are generated for each token to provide the model with information about the position of each word in the sentence. These encodings are added to the token embeddings, allowing the attention mechanisms to use the order of words.
3. Encoder Processing:
The combined embeddings enter the encoder, starting with a Self-Attention Multi-Head Attention (MHA) layer where multiple parallel linear transformations convert inputs into sets of queries, keys, and values. These interact across the sequence, enriching each token with information from the entire sentence.
The output of this interaction is then processed through a Feed-Forward Network (FFN), which introduces non-linearity and additional parameters, further enhancing the embeddings' representational capacity.
4. Layer Stacking:
- The output from one encoder layer feeds into the next, progressively enhancing the contextual richness of the embeddings. After several layers, the encoder outputs a set of highly informative embeddings, each corresponding to a token in the input sentence.
5. Decoder Initialization:
Translation begins with the decoder receiving a "
" token. This token is also embedded and encoded with positional information. The decoder processes this initial input through layers, starting with a Masked MHA. At this early stage, since "
" is the only token, it essentially attends to itself.
6. Sequential Decoding:
- As more tokens are generated ("L'entreprise Apple a," for example), each new token in the decoder can only attend to previously generated tokens to preserve the language's logical sequence.
7. Cross Attention in the Decoder:
- The Cross Attention MHA layer enables each new token in the decoder to also attend to all the encoder's embeddings. This step is crucial as it allows the decoder to access the full context of the original English sentence, ensuring the translation aligns semantically and syntactically.
8. Prediction and Token Generation:
The final decoder layer outputs probabilities for the next token. In this case, the highest-probability token, "L'entreprise," is selected and appended to the decoded sequence.
This process repeats, with each new token generated based on the preceding French tokens and the full English input until an "
" token is produced, signaling the completion of the translation.
This detailed walk-through shows how the Transformer integrates complex mechanisms like self-attention and cross-attention to process and translate language effectively, step by step.
Conclusion
The Transformer paper is a milestone in deep learning research. More importantly, compared to previous RNN methods, it can employ more parameters and efficient training, making scaling possible and ultimately leading to today's large language models (LLMs). Its encoder-decoder and self-attention, cross-attention designs also inspire the use of collections of embeddings to represent different modal data in a unified representation, naturally enabling multimodal learning. I hope this article provides you with an overview of these concepts. Additionally, a list of resources is provided for further reading.
Further Resources
 David Wang
David WangDavid Wang, Algorithm Engineer at Zilliz, brings extensive expertise in computer vision and natural language processing. His contributions to advanced embedding algorithm research, including projects like Towhee and GPTCache, reflect his commitment to advancing AI technologies. Before joining Zilliz, he worked at Alibaba Cloud for large-scale object recognition and classification projects. David holds a Master's degree from Dalian University of Technology.
- Transformer Overview
- The Architecture of a Transformer Model
- Understanding Encoder Core Concepts
- Decoder
- An Inference Example Using the Transformer Model
- Conclusion
- Further Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Nemo Guardrails: Elevating AI Safety and Reliability
In this article, we will provide an in-depth explanation of what Nemo Guardrails are, its practical applications, along with its integration.
A Beginner's Guide to Understanding Vision Transformers (ViT)
Vision Transformers (ViTs) are neural network models that use transformers to perform computer vision tasks like object detection and image classification.

Florence: An Advanced Foundation Model for Computer Vision by Microsoft
Florence is a large-scale vision-language model developed by Microsoft, particularly effective for applications requiring multimodal capabilities.