




Data Modeling Techniques Optimized for Vector Databases
This post explores various data modeling techniques for optimizing the performance of vector databases.
Read the entire series
- Cross-Entropy Loss: Unraveling its Role in Machine Learning
- Batch vs. Layer Normalization - Unlocking Efficiency in Neural Networks
- Empowering AI and Machine Learning with Vector Databases
- Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
- Vector Databases: Redefining the Future of Search Technology
- Local Sensitivity Hashing (L.S.H.): A Comprehensive Guide
- Optimizing AI: A Guide to Stable Diffusion and Efficient Caching Strategies
- Nemo Guardrails: Elevating AI Safety and Reliability
- Data Modeling Techniques Optimized for Vector Databases
- Demystifying Color Histograms: A Guide to Image Processing and Analysis
- Exploring BGE-M3: The Future of Information Retrieval with Milvus
- Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
- TF-IDF - Understanding Term Frequency-Inverse Document Frequency in NLP
- Understanding Regularization in Neural Networks
- A Beginner's Guide to Understanding Vision Transformers (ViT)
- Understanding DETR: End-to-end Object Detection with Transformers
- Vector Database vs Graph Database
- What is Computer Vision?
- Deep Residual Learning for Image Recognition
- Decoding Transformer Models: A Study of Their Architecture and Underlying Principles
- What is Object Detection? A Comprehensive Guide
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Algorithmic)
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Methodological)
- Understanding CoCa: Advancing Image-Text Foundation Models with Contrastive Captioners
- Florence: An Advanced Foundation Model for Computer Vision by Microsoft
- The Potential Transformer Replacement: Mamba
- ALIGN Explained: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
Data modeling processes simplify and formalize an organization's data architecture. They involve representing data and information as the blueprint for creating new databases. This enhances stakeholder understanding and collaboration while improving data quality and development efficiency.
Vector databases are unique compared to traditional databases because they focus on high-dimensional, unstructured data rather than structured data. This introduces distinctive challenges and opportunities in data modeling for vector databases, which offers grounds for discussing optimized techniques.
Vector Databases Explained
Vector databases store data in the form of vector embeddings. Each value within the vector represents a distinct data feature, collectively forming a comprehensive representation of the data. These vectors store and manage high-dimensional unstructured data like text and images. The vectorized structure allows for efficient data retrieval and advanced search mechanisms like similarity.
Vector databases also empower AI models to understand relationships between data points by providing access to a vast collection of vector embeddings.
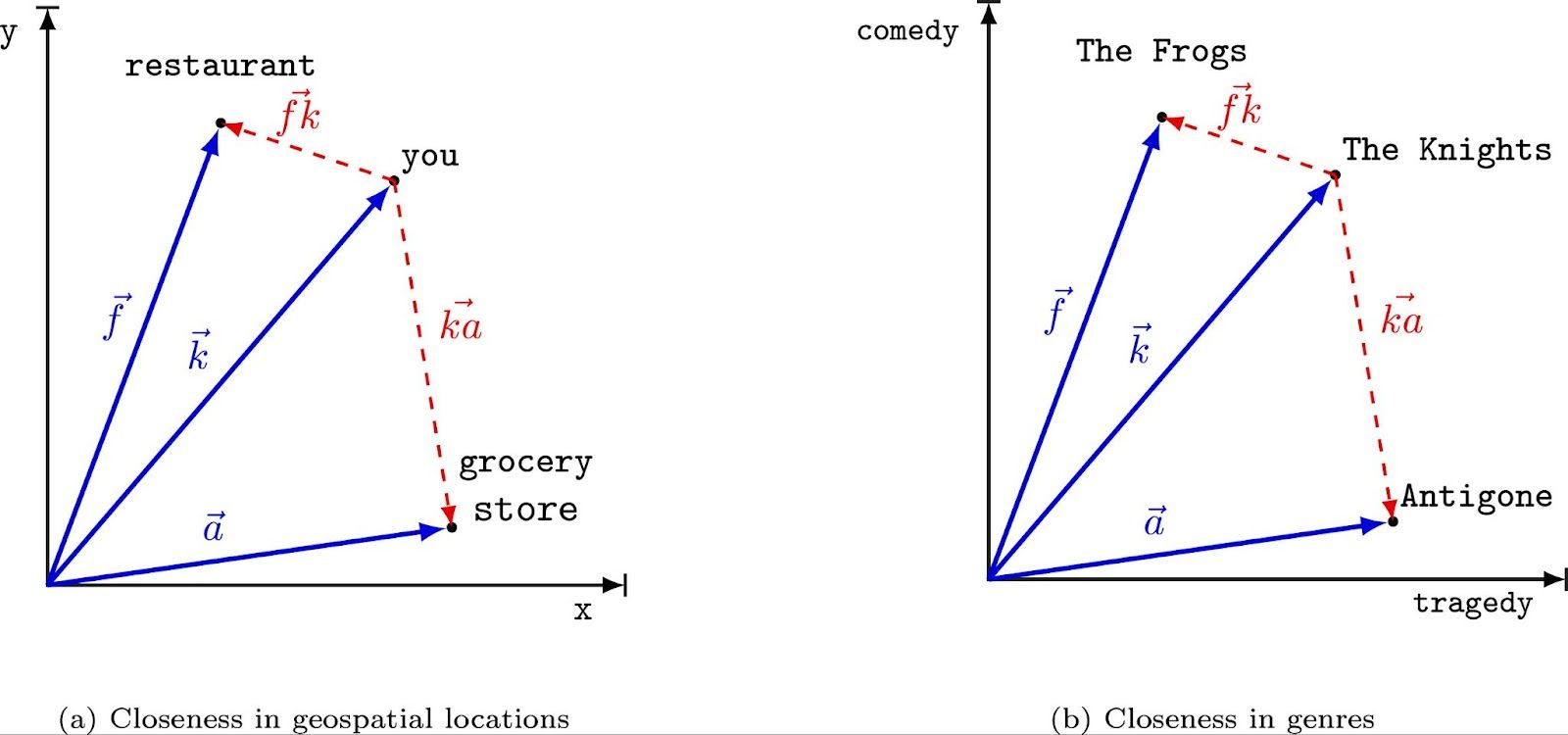
Graphical Representation of Vectors Source
However, its core capabilities require special attention to data modeling. Engineers must implement techniques like indexing to maintain the search efficiency and select the appropriate algorithms to generate embeddings.
Optimizing Data Models for Vector Databases
Vector databases focus on the storage and retrieval of vector data. Traditional databases overlook optimization possibilities for vector data and might not include functionalities like utilizing multiple query vectors. Hence, specific data modeling techniques and optimizations are employed for vector databases as discussed below:
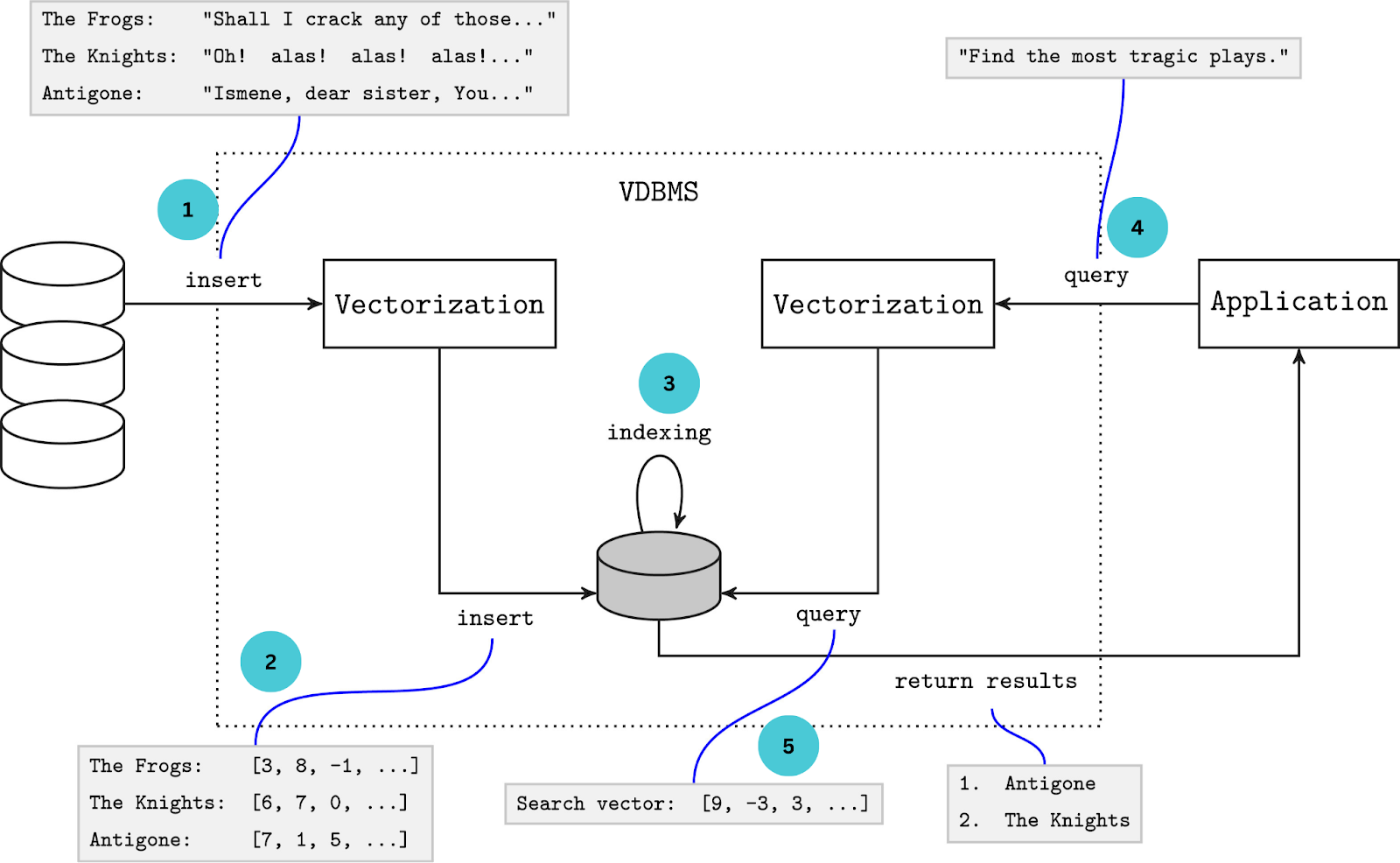
A simplified depiction of a database system showing the movement and alteration of information to and from the vector database - Source
- Embedding Strategies: Various algorithms calculate embeddings from unstructured data such as text. Some popular techniques include Sentence Transformer, OpenAI Embedding, and BGE embedding. The diagram represents how an embedding algorithm converts objects into vector representations.
Each algorithm has processing capabilities and fits different use cases. Selecting the correct algorithm is imperative to optimizing the vectorization step.
Indexing strategies: Indexing enhances query performance once data objects are vectorized and stored in the vector database. The trade-off between indexing algorithms is about balancing accuracy and speed, as vector queries typically involve approximations. Popular techniques like Product Quantization employ dimensionality reduction by dividing high-dimensional vectors into smaller parts, thereby reducing storage space at the expense of some accuracy. Other techniques involve locality-sensitive hashing and hierarchical navigable small worlds.
Distance Metric: Vector databases utilize distance metrics to compare queries with indexed vectors to find nearest neighbors. Common metrics include cosine similarity, Euclidean distance, and dot product. This capability is particularly valuable in various applications where finding similar vectors is crucial, such as image or text retrieval systems. The illustration below demonstrates how the distance between vectors on a cartesian diagram represents their similarity.
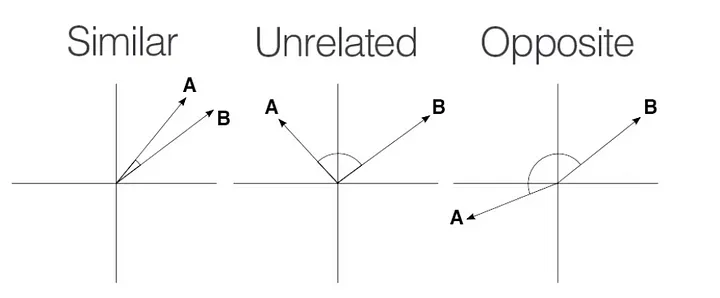
Vector Similarity - Source
Applications and Use Cases
In contrast to traditional databases, vector databases focus on high-dimensional data, which offers unique use cases. Some of the use cases are discussed below:
Semantic Search: It employs NLP and machine learning (ML) to grasp the context and significance of a user's search query. Vector databases can improve the efficiency and accuracy of semantic searches by storing, comparing, and retrieving data in vectors for similarity. Some examples of semantic search engines include Google, Bing, Yummly, and IBM Watson Discovery.
Recommendation Systems: Vector databases' similarity search capabilities power recommendation algorithms. These systems use algorithms that compare an input vector to that stored in the vector database and retrieve similar matches. This process recommends e-commerce stores and streaming websites like Netflix.
Complex Data Analytics: Vector databases drive complex data analytics tasks like clustering, classification, and anomaly detection by utilizing vector representations of data. This approach enables businesses to uncover hidden patterns, relationships, and insights within large datasets, facilitating data-driven decision-making, operational optimization, and competitive advantage.
Conclusion
The vector database represents a progressive data model that stores high-dimensional vectors, encapsulating rich unstructured data. This model diverges significantly from traditional database systems, necessitating specialized data modeling techniques and optimizations. These methods unlock the full potential of vector databases for handling complex data applications. As the future of data management in the era of AI, a deep understanding of these techniques and optimizations is crucial for data practitioners aiming to excel in sophisticated data environments.
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
- Vector Databases Explained
- Optimizing Data Models for Vector Databases
- Applications and Use Cases
- Conclusion
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
LangChain tools and Milvus redefine the boundaries of what’s achievable with AI.

Demystifying Color Histograms: A Guide to Image Processing and Analysis
Mastering color histograms is indispensable for anyone involved in image processing and analysis. By understanding the nuances of color distributions and leveraging advanced techniques, practitioners can unlock the full potential of color histograms in various imaging projects and research endeavors.

TF-IDF - Understanding Term Frequency-Inverse Document Frequency in NLP
We explore the significance of Term Frequency-Inverse Document Frequency (TF-IDF) and its applications, particularly in enhancing the capabilities of vector databases like Milvus.