




Florence: An Advanced Foundation Model for Computer Vision by Microsoft
Florence is a large-scale vision-language model developed by Microsoft, particularly effective for applications requiring multimodal capabilities.
Read the entire series
- Cross-Entropy Loss: Unraveling its Role in Machine Learning
- Batch vs. Layer Normalization - Unlocking Efficiency in Neural Networks
- Empowering AI and Machine Learning with Vector Databases
- Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
- Vector Databases: Redefining the Future of Search Technology
- Local Sensitivity Hashing (L.S.H.): A Comprehensive Guide
- Optimizing AI: A Guide to Stable Diffusion and Efficient Caching Strategies
- Nemo Guardrails: Elevating AI Safety and Reliability
- Data Modeling Techniques Optimized for Vector Databases
- Demystifying Color Histograms: A Guide to Image Processing and Analysis
- Exploring BGE-M3: The Future of Information Retrieval with Milvus
- Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
- TF-IDF - Understanding Term Frequency-Inverse Document Frequency in NLP
- Understanding Regularization in Neural Networks
- A Beginner's Guide to Understanding Vision Transformers (ViT)
- Understanding DETR: End-to-end Object Detection with Transformers
- Vector Database vs Graph Database
- What is Computer Vision?
- Deep Residual Learning for Image Recognition
- Decoding Transformer Models: A Study of Their Architecture and Underlying Principles
- What is Object Detection? A Comprehensive Guide
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Algorithmic)
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Methodological)
- Understanding CoCa: Advancing Image-Text Foundation Models with Contrastive Captioners
- Florence: An Advanced Foundation Model for Computer Vision by Microsoft
- The Potential Transformer Replacement: Mamba
- ALIGN Explained: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
Artificial intelligence research is shifting towards creating systems that can handle multiple tasks, similar to human adaptability. This change comes from the fact that designing specific models for individual problems is not the most effective way to achieve human-like AI. Researchers are now developing comprehensive systems that can solve various real-world tasks with minimal human input. This approach has led to the creation of foundation models like OpenAI’s GPT series. Trained on large datasets, these models adapt to various tasks through fine-tuning, showing strong performance and generalization.
This shift is especially crucial in computer vision, where traditional methods struggle to adapt across varied tasks. Computer vision faces challenges with its traditional approach of using specialized models for different tasks, which can be inefficient and limit adaptability. To address these challenges, Microsoft researchers have created Florence, a new foundation model for computer vision. Florence aims to provide a single, adaptable architecture for various visual AI tasks, including image classification, object detection, visual question answering, and video analysis. This model is a step towards a general-purpose vision system that can adjust to different applications with minimal task-specific training.
Initial results from Florence show its potential to advance computer vision. The model performs well across various tasks, often outperforming specialized models, and shows promising improvements as it scales up. These findings suggest that Florence and similar foundation models could lead to more efficient and capable visual AI systems. Let’s explore Florence's structure, training methods, abilities, and potential effects on the future of AI and computer vision.
The Landscape of Computer Vision Tasks
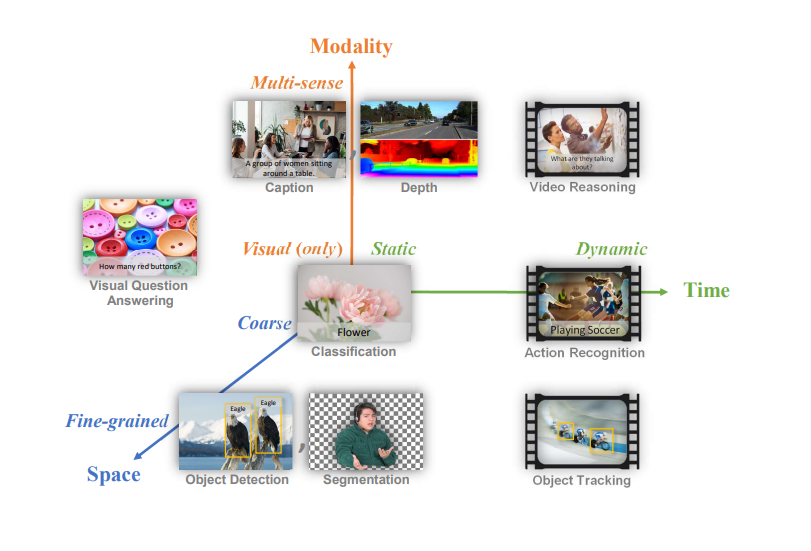
Computer vision includes a diverse set of tasks that can be categorized along three main dimensions:
 Common computer vision tasks mapped to a Space-Time-Modality space.png
Common computer vision tasks mapped to a Space-Time-Modality space.png
Figure 1: Common computer vision tasks mapped to a Space-Time-Modality space
Florence can address a wide range of computer vision challenges in three key dimensions: space, time, and modality.
Space: This dimension ranges from coarse-grained scene understanding to fine-grained object detection and segmentation. At the coarse level, we have tasks like image classification, which aims to identify an image's main subject or theme. Moving towards fine-grained analysis, we encounter tasks such as object detection, which identifies and locates multiple objects within an image, and segmentation, which requires precise delineation of object boundaries.
Time: Computer vision tasks deal with both static images and those processing dynamic video content. Static tasks include image classification, object detection, and visual question answering. Dynamic tasks involve analyzing sequences of images over time, such as action recognition in videos or object tracking.
Modality: While some tasks focus solely on visual information, others incorporate additional modalities. Pure visual tasks include image classification and object detection. Multi-modal tasks combine visual data with other types of information, such as text (in image captioning or visual question answering), depth information, or even audio in some video analysis tasks.
The Challenge: Creating a Universal Visual AI
Traditionally, these diverse tasks required specialized models, each designed and optimized for a specific type of problem. This approach, while effective, has several limitations:
Inefficiency in development and deployment: Creating and maintaining separate models for each task is resource-intensive and time-consuming.
Difficulty in transferring knowledge: Models optimized for one task often struggle to apply their learned knowledge to related tasks.
Limited ability to handle novel situations: Specialized models may perform poorly when confronted with scenarios that differ significantly from their training data.
Florence aims to address these limitations. The goal is to develop a foundation model that can serve as a general-purpose vision system, adaptable to various downstream tasks with minimal modifications. To achieve this goal, Florence's architecture integrates multiple components, each designed to tackle different aspects of visual understanding.
Florence's Architecture: Unifying Multiple Approaches
As mentioned above, Florence is a large-scale vision-language model developed by Microsoft. It's designed to unify multiple computer vision and language processing tasks within a single framework. This allows Florence to perform a variety of tasks, including image recognition, object detection, and more complex capabilities such as visual question answering and image captioning. The model leverages a combination of vision and language understanding to process and interpret textual and visual data, making it particularly effective for applications requiring multimodal capabilities.
Now, let’s learn about Florence’s architecture and how it works.
Florence's versatility stems from its unified architecture, which combines elements from several existing model types.
 Overview of building Florence, showing the workflow from data curation to deployment.png
Overview of building Florence, showing the workflow from data curation to deployment.png
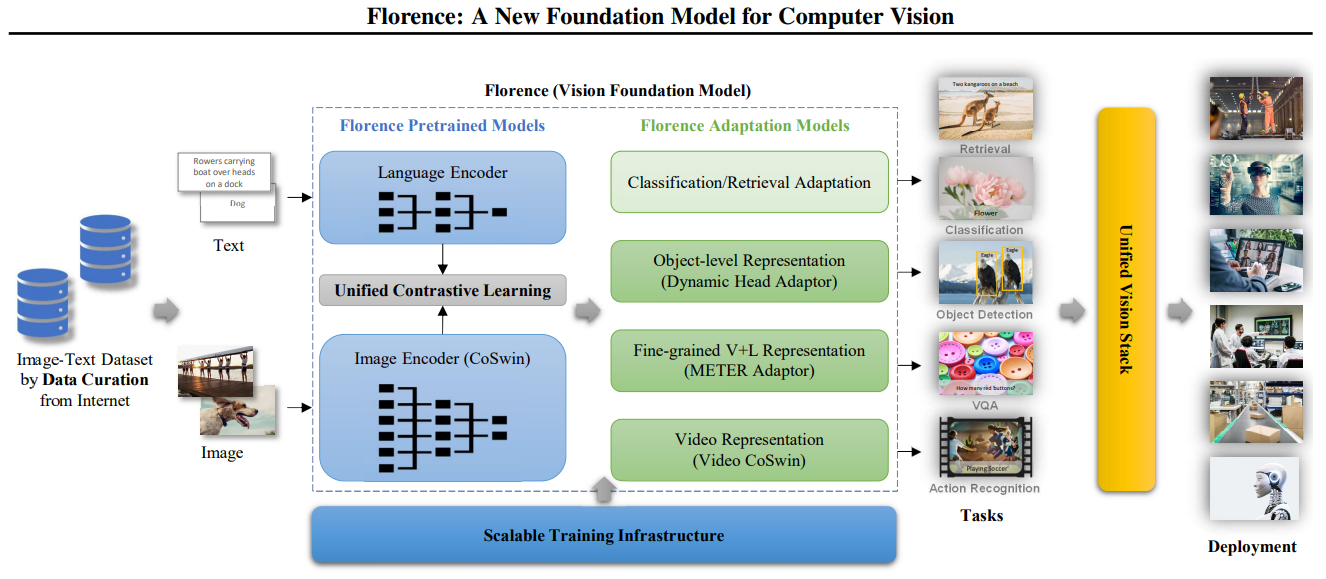
Figure 2: Overview of building Florence, showing the workflow from data curation to deployment
The architecture has two main components: Florence Pretrained Models and Florence Adaptation Models.
Florence Pretrained Models
The Florence pre-trained models consist of several key components, each designed to effectively process and align visual and textual data.
Language Encoder: This component processes textual input, allowing the model to understand and generate language related to visual content. It's similar to models like BERT or GPT but specifically designed to work alongside visual information.
Image Encoder (CoSwin): Based on a hierarchical Vision Transformer called CoSwin, this encoder handles visual information, transforming raw pixel data into meaningful representations. It builds on the success of transformer architectures in natural language processing, adapting them for image processing.
Unified Contrastive Learning: This module aligns visual and textual representations, enabling the model to understand the relationships between images and their descriptions. It helps the model learn which texts correspond to which images and vice versa.
Florence Adaptation Models:
These models take the representations from the pre-trained models and adapt them for specific tasks:
Classification/Retrieval Adaptation: This component allows Florence to perform image classification and cross-modal retrieval tasks. For example, it can classify an image into predefined categories or find images that match a given text description.
Object-level Representation (Dynamic Head Adaptor): This adaptor enables fine-grained object detection and segmentation tasks. It allows the model to classify what's in an image and locate and outline specific objects.
 Dynamic Head adapter used for object-level visual representation learning.png
Dynamic Head adapter used for object-level visual representation learning.png
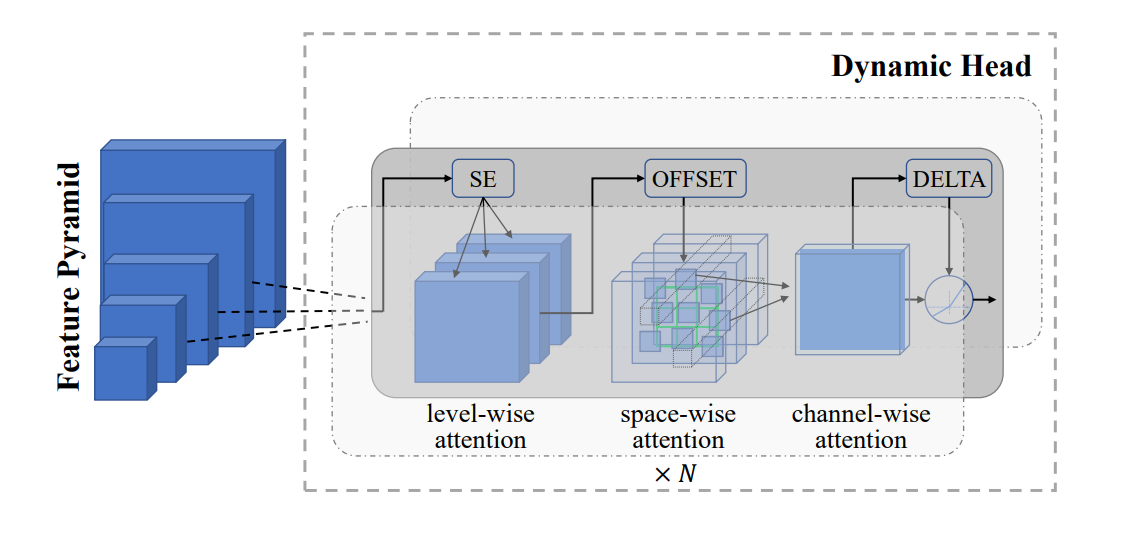
Figure 3: Dynamic Head adapter used for object-level visual representation learning
The Dynamic Head adapter, shown in the image above, processes visual information through a series of attention mechanisms:
The input is a Feature Pyramid containing visual information at different scales. For example, in an image of a busy street scene:
The largest block might represent the overall layout of buildings and roads.
Middle blocks might capture individual cars and pedestrians.
The smallest block could focus on fine details like license plates or facial features.
The adapter applies three types of attention:
Level-wise attention (SE): This focuses on important features across different levels of the pyramid. In our street scene, SE might emphasize the car level for a vehicle detection task or the facial feature level for a person recognition task.
Space-wise attention: This attends to relevant spatial locations within each level, represented by the 3D grid. For instance, it might focus on the sidewalk areas when looking for pedestrians or the road areas when detecting vehicles.
Channel-wise attention: This emphasizes important feature channels, shown as the final block. Some channels might be more relevant for detecting shapes, while others might be better for color information.
The OFFSET and DELTA components fine-tune the spatial predictions. They help precisely locate object boundaries, such as accurately outlining a car or a person in the street scene.
This multi-stage attention process enables the model to detect and segment objects by focusing on the most relevant information at different scales and spatial locations. For example, it could simultaneously detect large objects like buses, medium-sized objects like cars, and small objects like traffic signs in the street scene.
- Fine-grained V+L Representation (METER Adaptor): This module supports vision-language tasks such as visual question answering and image captioning. It enables the model to understand complex relationships between visual and textual information.
 METER adapter used as Florence V+L adaptation model.png
METER adapter used as Florence V+L adaptation model.png
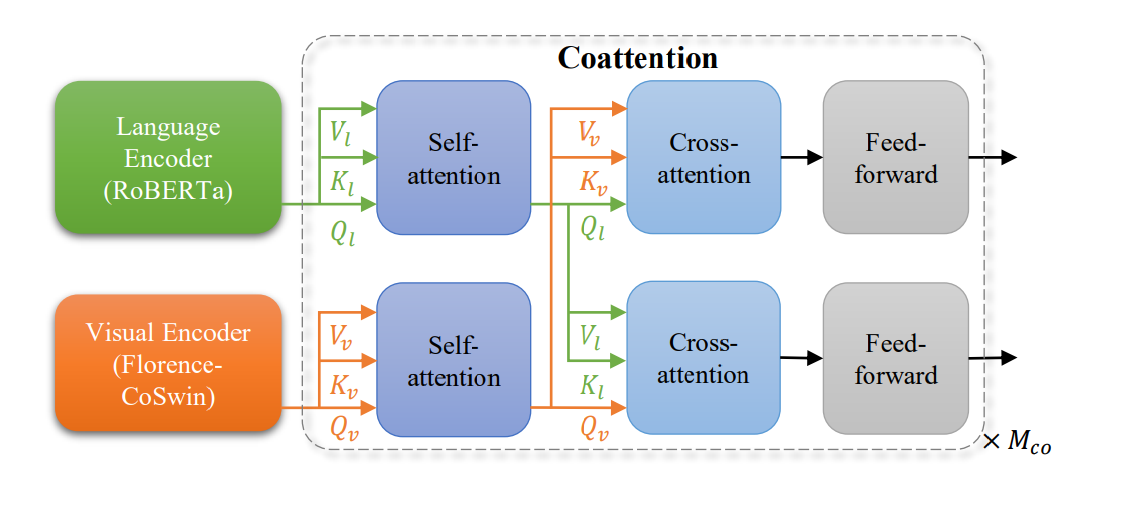
Figure 4: METER adapter used as Florence V+L adaptation model
The METER adapter, illustrated in the image above, uses a co-attention mechanism to fuse visual and textual information. Let's see how it works:
The Language Encoder (RoBERTa) processes textual input. For example, it might process the question: “What color is the car parked next to the fire hydrant?”
The Visual Encoder (Florence-CoSwin) processes visual input. This would analyze the image of the street scene.
Both inputs go through separate self-attention layers, allowing each modality to process its information independently. The text self-attention might focus on keywords like color, car, and fire hydrant, while the visual self-attention might highlight areas of the image containing cars and fire hydrants.
The outputs of these self-attention layers then feed into cross-attention layers. This is where the visual and textual information is combined:
The text features attend to relevant parts of the image (Vl, Kl, Ql arrows pointing down). For our example, this might link the words car and fire hydrant to their visual representations in the image.
The image features attend to relevant parts of the text (Vv, Kv, Qv arrows pointing up). This could involve associating the visual features of the car with the word color in the question.
Finally, both streams go through feed-forward layers, further processing this combined information.
This process is repeated Mco times, allowing for multiple rounds of refinement.
This architecture allows the model to process text and images separately at first, then gradually combine the information, enabling it to understand complex relationships between visual and textual content. Our example would allow the model to identify the correct car based on its proximity to the fire hydrant, determine its color, and formulate an answer like: The car parked next to the fire hydrant is blue.
- Video Representation (Video CoSwin): This adaptor extends Florence's capabilities to handle video data, enabling tasks like action recognition. It builds on the image processing capabilities to understand sequences of images over time.
This unified structure allows Florence to handle a wide range of tasks, from image classification to video recognition, with a single base model and task-specific adaptors.
Florence's Capabilities: A Multi-Talented Visual AI
Florence’s adaptability is evident in its ability to perform the following tasks.
Zero-shot Image Classification
Florence demonstrates strong zero-shot classification across 12 datasets, outperforming models like CLIP and FLIP in most cases. It performs particularly well on fine-grained tasks, achieving scores like 93.2% on Stanford Cars and 95.9% on Oxford Pets, and handles large-scale datasets such as ImageNet with an 83.7% accuracy. This performance shows Florence can generalize to recognize unseen categories, using its understanding of language and visual features.
Linear Probe Classification
When a linear classifier is used on top of frozen features, Florence surpasses models like SimCLRv2, ViT, and EfficientNet on most datasets. This versatility on diverse and fine-grained classification tasks suggests Florence’s learned representations are rich and adaptable to new tasks.
Object Detection
Florence’s object detection performance is evaluated on multiple datasets, scoring 62.4 mAP on COCO, 39.3 mAP on Object365, and 16.2 AP50 on Visual Genome. These results highlight its ability to classify, locate, and identify multiple objects within complex scenes.
Visual Question Answering (VQA)
Florence achieves an accuracy of 80.36% on the VQA v2 dataset, showing its capacity to combine image content with questions asked. This reflects its ability to integrate visual and textual information.
Image-Text Retrieval
Florence performs effectively in cross-modal retrieval, with results on the Flickr30K dataset showing a 97.2% R@1 for image-to-text and 87.9% R@1 for text-to-image, and on the MSCOCO dataset with 81.8% R@1 for image-to-text and 63.2% R@1 for text-to-image. This ability to align visual and text representations supports robust cross-modal search capabilities.
Video Action Recognition
Despite being trained on static images, Florence adapts well to video tasks, achieving top-1 accuracies of 86.5% on Kinetics-400 and 87.8% on Kinetics-600. This performance shows Florence can capture temporal information and recognize actions in videos, handling motion and sequences without specific training on video data.
For more evaluation and experiment results, check out Florence’s paper.
How Florence and Vector Databases Enhance Multimodal Search
Florence's capabilities, particularly in image-text retrieval and zero-shot classification, align well with the strengths of vector databases. By combining the two, we can maximize their potential, creating robust multimedia search and analysis systems.
Understanding Vector Databases
Vector databases are specialized systems designed to store, index, and query high-dimensional vectors, which represent complex data such as images, text, or audio. These vectors, often produced by models like Florence, allow for efficient similarity-based searches across vast datasets. This capability makes vector databases key in applications that need fast, accurate data matching based on semantic or content similarity.
Milvus: An Open-source Vector Database Built for Scale
Milvus, the most popular open-source vector database on GitHub with over 30,000 stars at the time of writing, is particularly well-suited for AI-powered applications. It combines scalability, performance, and flexible indexing to manage the large, complex datasets that models like Florence generate. It offers a wide range of features, such as:
Hybrid and Multimodal Search: Milvus supports hybrid sparse and dense search, combines vector similarity search with scalar filters, and allows for multimodal search.
Scalability: Built to scale horizontally, Milvus can manage billions of vectors, ensuring it keeps pace with Florence’s capability to process expansive datasets.
Diverse Index Types: With 15 indexing types, Milvus offers users the flexibility to optimize query speed, accuracy, or memory, fitting a range of application needs.
GPU Acceleration: Milvus leverages GPU acceleration for indexing and search, which aligns well with Florence’s GPU-based inference and maximizes end-to-end system efficiency.
Real-time Updates: Milvus supports real-time data insertion and updates, allowing Florence-based systems to incorporate new data seamlessly without major disruptions.
This combination of Florence and Milvus has many applications. Some of them are:
Multimodal RAG: Traditional RAG systems focus on retrieving relevant text to enhance the generative process of LLMs, producing more accurate and personalized responses. Multimodal RAG expands beyond text by integrating additional data types—images, audio, videos, and more—into the embedding, retrieval, and generation process using multimodal AI models like Florence and Milvus.
Large-scale visual search engines: Users could find images based on detailed text descriptions or upload images to find similar ones across massive datasets.
Content recommendation systems: By storing Florence embeddings for various content items (images, videos, articles), Milvus could power personalized recommendations based on user preferences and behavior.
Automated tagging and categorization: Florence's zero-shot capabilities, combined with Milvus's fast retrieval, could enable the automatic tagging of new images by finding similar, already-tagged items in the database.
Visual question answering at scale: Store embeddings of image-question-answer triplets in Milvus, enabling rapid retrieval of relevant information for new questions about images.
Together, Florence and vector databases like Milvus provide a powerful foundation for scalable, multimodal AI systems. With continued advancements in both technologies, we can expect a growing range of applications that capitalize on Florence's visual understanding and Milvus’s high-performance search capabilities.
Conclusion
Florence marks a notable advancement in computer vision, combining several methodologies into one robust and adaptable model. By integrating with vector databases like Milvus, Florence enables a range of applications from multimodal RAG to large-scale visual search and personalized recommendation systems.
As the technology evolves, we expect to see more advanced visual AI systems that could enhance human-computer interactions and streamline AI-driven assistants. These developments may also lead to better automation in various industries and introduce new tools for creativity and content creation.
Further Resources
 Denis Kuria
Denis KuriaDenis is a machine learning engineer who enjoys writing guides to help other developers. He has a bachelor's in computer science and loves hiking and exploring the world.
- The Landscape of Computer Vision Tasks
- The Challenge: Creating a Universal Visual AI
- Florence's Architecture: Unifying Multiple Approaches
- Florence's Capabilities: A Multi-Talented Visual AI
- How Florence and Vector Databases Enhance Multimodal Search
- Conclusion
- Further Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Understanding Regularization in Neural Networks
Regularization prevents a machine-learning model from overfitting during the training process. We'll discuss its concept and key regularization techniques.

The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Methodological)
In this article, we'll explore the evolution of MAS from a methodological or approach-based perspective.

The Potential Transformer Replacement: Mamba
Mamba is a new architecture for sequence modeling, designed to offer an alternative to the Transformer models commonly used in machine learning.