




What is a Vector Database and how does it work: Implementation, Optimization & Scaling for Production Applications
A vector database stores, indexes, and searches unstructured data through vector embeddings for fast information retrieval and similarity search.
Read the entire series
- Introduction to Unstructured Data
- What is a Vector Database and how does it work: Implementation, Optimization & Scaling for Production Applications
- An Introduction to Vector Embeddings: What They Are and How to Use Them
- Introduction to Vector Similarity Search
- Understanding Vector Databases: Compare Vector Databases, Vector Search Libraries, and Vector Search Plugins
- What is Information Retrieval?
- Everything You Need to Know about Vector Index Basics
- Choosing the Right Vector Index for Your Project
A vector database indexes and stores vector embeddings for fast retrieval and similarity search, with capabilities like CRUD operations, metadata filtering, and horizontal scaling designed specifically for AI applications.
Introduction: The Rise of Vector Databases in the AI Era
In the early days of ImageNet, it took 25,000 human curators to manually label the dataset. This staggering number highlights a fundamental challenge in AI: manually categorizing unstructured data simply doesn’t scale. With billions of images, videos, documents, and audio files generated daily, a paradigm shift was needed in how computers understand and interact with content.
Traditional relational database systems excel at managing structured data with predefined formats and executing precise search operations. In contrast, vector databases specialize in storing and retrieving unstructured data types, such as images, audio, videos, and textual content, through high-dimensional numerical representations known as vector embeddings. Vector databases support large language models by providing efficient data retrieval and management. Modern vector databases outperform traditional systems by 2-10x through hardware-aware optimization (AVX512, SIMD, GPUs, NVMe SSDs), highly optimized search algorithms (HNSW, IVF, DiskANN), and column-oriented storage design. Their cloud-native, decoupled architecture enables independent scaling of search, data insertion, and indexing components, allowing systems to efficiently handle billions of vectors while maintaining performance for enterprise AI applications at companies like Salesforce, PayPal, eBay, and NVIDIA.
This represents what experts call a “semantic gap”—traditional databases operate on exact matches and predefined relationships, while human understanding of content is nuanced, contextual, and multidimensional. This gap becomes increasingly problematic as AI applications demand:
Finding conceptual similarities rather than exact matches
Understanding contextual relationships between different pieces of content
Capturing the semantic essence of information beyond keywords
Processing multimodal data within a unified framework
Vector databases have emerged as the critical technology to bridge this gap, becoming an essential component in the modern AI infrastructure. They enhance the performance of machine learning models by facilitating tasks like clustering and classification.
Understanding Vector Embeddings: The Foundation
Vector embeddings serve as the critical bridge across the semantic gap. These high-dimensional numerical representations capture the semantic essence of unstructured data in a form computers can efficiently process. Modern embedding models transform raw content—whether text, images, or audio—into dense vectors where similar concepts cluster together in the vector space, regardless of surface-level differences.
For example, properly constructed embeddings would position concepts like “automobile,” “car,” and “vehicle” in proximity within the vector space, despite having different lexical forms. This property enables semantic search, recommendation systems, and AI applications to understand content beyond simple pattern matching.
The power of embeddings extends across modalities. Advanced vector databases support various unstructured data types—text, images, audio—in a unified system, enabling cross-modal searches and relationships that were previously impossible to model efficiently. These vector database capabilities are crucial for AI-driven technologies such as chatbots and image recognition systems, supporting advanced applications like semantic search and recommendation systems.
However, storing, indexing, and retrieving embeddings at scale presents unique computational challenges that traditional databases weren’t built to address.
Vector Databases: Core Concepts
Vector databases represent a paradigm shift in how we store and query unstructured data. Unlike traditional relational database systems that excel at managing structured data with predefined formats, vector databases specialize in handling unstructured data through numerical vector representations.
At their core, vector databases are designed to solve a fundamental problem: enabling efficient similarity searches across massive datasets of unstructured data. They accomplish this through three key components:
Vector Embeddings: High-dimensional numerical representations that capture semantic meaning of unstructured data (text, images, audio, etc.)
Specialized Indexing: Algorithms optimized for high-dimensional vector spaces that enable fast approximate searches. Vector database indexes vectors to enhance the speed and efficiency of similarity searches, utilizing various ML algorithms to create indexes on vector embeddings.
Distance Metrics: Mathematical functions that quantify similarity between vectors
The primary operation in a vector database is the k-nearest neighbors (KNN) query, which finds the k vectors most similar to a given query vector. For large-scale applications, these databases typically implement approximate nearest neighbor (ANN) algorithms, trading a small amount of accuracy for significant gains in search speed.
Mathematical Foundations of Vector Similarity
Understanding vector databases requires grasping the mathematical principles behind vector similarity. Here are the foundational concepts:
Vector Spaces and Embeddings
A vector embedding is a fixed-length array of floating-point numbers (they can range from 100-32,768 dimensions!) that represents unstructured data in a numerical format. These embeddings position similar items closer together in a high-dimensional vector space.
For example, the words "king" and "queen" would have vector representations that are closer to each other than either is to "automobile" in a well-trained word embedding space.
Distance Metrics
The choice of distance metric fundamentally affects how similarity is calculated. Common distance metrics include:
Euclidean Distance: The straight-line distance between two points in Euclidean space.
Cosine Similarity: Measures the cosine of the angle between two vectors, focusing on orientation rather than magnitude
Dot Product: For normalized vectors, represents how aligned two vectors are.
Manhattan Distance (L1 Norm): Sum of absolute differences between coordinates.
Different use cases may require different distance metrics. For example, cosine similarity often works well for text embeddings, while Euclidean distance may be better suited for certain types of image embeddings.
Semantic similarity between vectors in a vector space
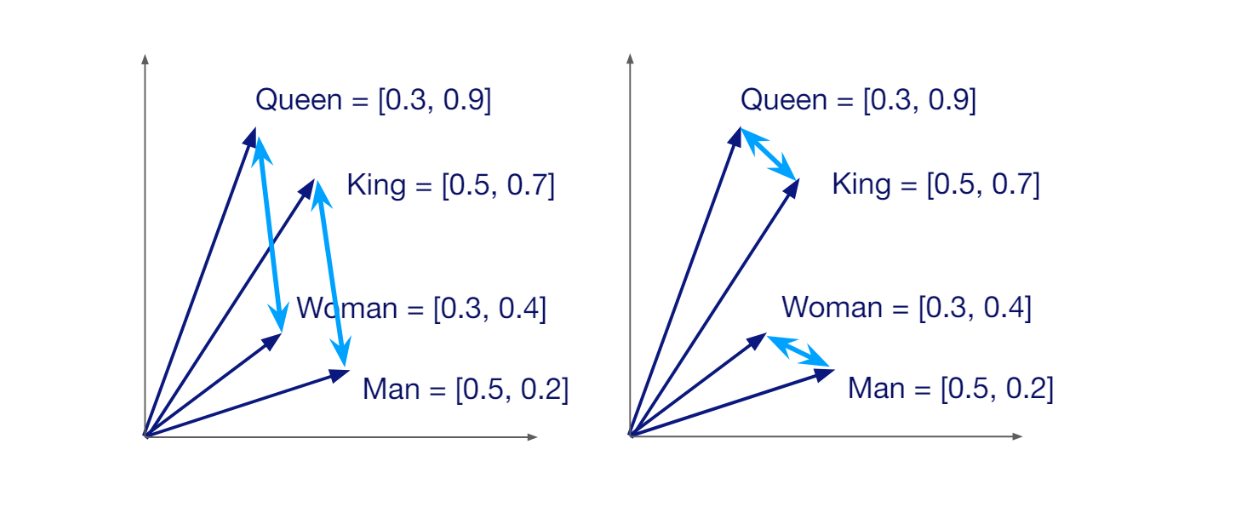 Semantic similarity between vectors in a vector space
Semantic similarity between vectors in a vector space
Understanding these mathematical foundations leads to an important question about implementation: So just add a vector index to any database, right?
Simply adding a vector index to a relational database isn't sufficient, nor is using a standalone vector index library. While vector indices provide the critical ability to find similar vectors efficiently, they lack the infrastructure needed for production applications:
They don't provide CRUD operations for managing vector data
They lack metadata storage and filtering capabilities
They offer no built-in scaling, replication, or fault tolerance
They require custom infrastructure for data persistence and management
Vector databases emerged to address these limitations, providing complete data management capabilities designed specifically for vector embeddings. They combine the semantic power of vector search with the operational capabilities of database systems.
Unlike traditional databases that operate on exact matches, vector databases focus on semantic search—finding vectors that are "most similar" to a query vector according to specific distance metrics. This fundamental difference drives the unique architecture and algorithms that power these specialized systems.
Vector Database Architecture: A Technical Framework
Modern vector databases implement a sophisticated multi-layered architecture that separates concerns, enables scalability, and ensures maintainability. This technical framework goes far beyond simple search indices to create systems capable of handling production AI workloads. Vector databases work by processing and retrieving information for AI and ML applications, utilizing algorithms for approximate nearest neighbor searches, converting various types of raw data into vectors, and efficiently managing diverse data types through semantic searches.
Four-Tier Architecture
A production vector database typically consists of four primary architectural layers:
Storage Layer: Manages persistent storage of vector data and metadata, implements specialized encoding and compression strategies, and optimizes I/O patterns for vector-specific access.
Index Layer: Maintains multiple indexing algorithms, manages their creation and updates, and implements hardware-specific optimizations for performance.
Query Layer: Processes incoming queries, determines execution strategies, handles result processing, and implements caching for repeated queries.
Service Layer: Manages client connections, handles request routing, provides monitoring and logging, and implements security and multi-tenancy.
Vector Search Workflow
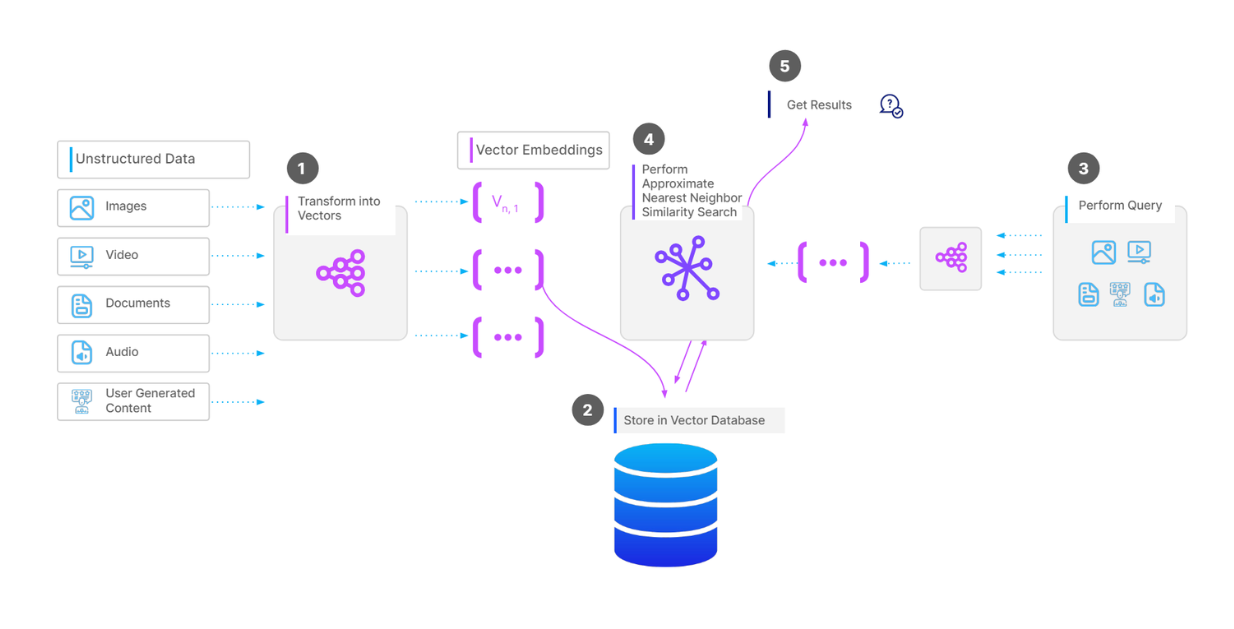 Complete workflow of a vector search operation.png
Complete workflow of a vector search operation.png
A typical vector database implementation follows this workflow:
A machine learning model transforms unstructured data (text, images, audio) into vector embeddings
These vector embeddings are stored in the database along with relevant metadata
When a user performs a query, it is converted into a vector embedding using the same model
The database compares the query vector to stored vectors using an approximate nearest neighbor algorithm
The system returns the top-K most relevant results based on vector similarity
Optional post-processing may apply additional filters or reranking
This pipeline enables efficient semantic search across massive collections of unstructured data that would be impossible with traditional database approaches.
Consistency in Vector Databases
Ensuring consistency in distributed vector databases is a challenge due to the trade-off between performance and correctness. While eventual consistency is common in large-scale systems, strong consistency models are required for mission-critical applications like fraud detection and real-time recommendations. Techniques like quorum-based writes and distributed consensus (e.g., Raft, Paxos) ensure data integrity without excessive performance trade-offs.
Production implementations adopt a shared-storage architecture featuring storage and computing disaggregation. This separation follows the principle of data plane and control plane disaggregation, with each layer being independently scalable for optimal resource utilization.
Managing Connections, Security, and Multitenancy
As these databases are used in multi-user and multi-tenant environments, securing data and managing access control are critical for maintaining confidentiality.
Security measures like encryption (both at rest and in transit) protect sensitive data, such as embeddings and metadata. Authentication and authorization ensure only authorized users can access the system, with fine-grained permissions for managing access to specific data.
Access control defines roles and permissions to restrict data access. This is particularly important for databases storing sensitive information like customer data or proprietary AI models.
Multitenancy involves isolating each tenant's data to prevent unauthorized access while enabling resource sharing. This is achieved through sharding, partitioning, or row-level security to ensure scalable and secure access for different teams or clients.
External identity and access management (IAM) systems integrate with vector databases to enforce security policies and ensure compliance with industry standards.
Advantages of Vector Databases
Vector databases offer several advantages over traditional databases, making them an ideal choice for handling vector data. Here are some of the key benefits:
Efficient Similarity Search: One of the standout features of vector databases is their ability to perform efficient semantic searches. Unlike traditional databases that rely on exact matches, vector databases excel at finding data points that are similar to a given query vector. This capability is crucial for applications like recommendation systems, where finding items similar to a user’s past interactions can significantly enhance user experience.
Handling High-Dimensional Data: Vector databases are specifically designed to manage high-dimensional data efficiently. This makes them particularly suitable for applications in natural language processing, computer vision, and genomics, where data often exists in high-dimensional spaces. By leveraging advanced indexing and search algorithms, vector databases can quickly retrieve relevant data points, even in complex, vector embedding datasets.
Scalability: Scalability is a critical requirement for modern AI applications, and vector databases are built to scale efficiently. Whether dealing with millions or billions of vectors, vector databases can handle the growing demands of AI applications through horizontal scaling. This ensures that performance remains consistent even as data volumes increase.
Flexibility: Vector databases offer remarkable flexibility in terms of data representation. They can store and manage various types of data, including numerical features, embeddings from text or images, and even complex data like molecular structures. This versatility makes vector databases a powerful tool for a wide range of applications, from text analysis to scientific research.
Real-time Applications: Many vector databases are optimized for real-time or near-real-time querying. This is particularly important for applications that require quick responses, such as fraud detection, real-time recommendations, and interactive AI systems. The ability to perform rapid similarity searches ensures that these applications can deliver timely and relevant results.
Use Cases for Vector Databases
Vector databases have a wide range of applications across various industries, demonstrating their versatility and power. Here are some notable use cases:
Natural Language Processing: In the realm of natural language processing (NLP), vector databases play a crucial role. They are used for tasks such as text classification, sentiment analysis, and language translation. By converting text into high-dimensional vector embeddings, vector databases enable efficient similarity searches and semantic understanding, enhancing the performance of NLP models.
Computer Vision: Vector databases are also widely used in computer vision applications. Tasks like image recognition, object detection, and image segmentation benefit from the ability of vector databases to handle high-dimensional image embeddings. This allows for quick and accurate retrieval of visually similar images, making vector databases indispensable in fields like autonomous driving, medical imaging, and digital asset management.
Genomics: In genomics, vector databases are used to store and analyze genetic sequences, protein structures, and other molecular data. The high-dimensional nature of this data makes vector databases an ideal choice for managing and querying large genomic datasets. Researchers can perform vector searches to find genetic sequences with similar patterns, aiding in the discovery of genetic markers and the understanding of complex biological processes.
Recommendation Systems: Vector databases are a cornerstone of modern recommendation systems. By storing user interactions and item features as vector embeddings, these databases can quickly identify items that are similar to those a user has previously interacted with. This capability enhances the accuracy and relevance of recommendations, improving user satisfaction and engagement.
Chatbots and Virtual Assistants: Vector databases are used in chatbots and virtual assistants to provide real-time contextual answers to user queries. By converting user inputs into vector embeddings, these systems can perform similarity searches to find the most relevant responses. This enables chatbots and virtual assistants to deliver more accurate and contextually appropriate answers, enhancing the overall user experience.
By leveraging the unique capabilities of vector databases, organizations across various industries can build more intelligent, responsive, and scalable AI applications.
Vector Search Algorithms: From Theory to Practice
Vector databases require specialized indexing algorithms to enable efficient similarity search in high-dimensional spaces. The algorithm selection directly impacts accuracy, speed, memory usage, and scalability.
Graph-Based Approaches
HNSW (Hierarchical Navigable Small World) creates navigable structures by connecting similar vectors, enabling efficient traversal during search. HNSW limits maximum connections per node and search scope to balance performance and accuracy, making it one of the most widely used algorithms for vector similarity search.
Cagra is a graph-based index optimized specifically for GPU acceleration. It constructs navigable graph structures that align with GPU processing patterns, enabling massively parallel vector comparisons. What makes Cagra particularly effective is its ability to balance recall and performance through configurable parameters like graph degree and search width. Using inference-grade GPUs with Cagra can be more cost-effective than expensive training-grade hardware while still delivering high throughput, especially for large-scale vector collections. However, it's worth noting that GPU indexes like Cagra may not necessarily reduce latency compared to CPU indexes unless operating under high query pressure.
Quantization Techniques
Product Quantization (PQ) decomposes high-dimensional vectors into smaller subvectors, quantizing each separately. This significantly reduces storage needs (often by 90%+) but introduces some accuracy loss.
Scalar Quantization (SQ) converts 32-bit floats to 8-bit integers, reducing memory usage by 75% with minimal accuracy impact.
On-Disk Indexing: Cost-Effective Scaling
For large-scale vector collections (100M+ vectors), in-memory indexes become prohibitively expensive. For example, 100 million 1024-dimensional vectors would require approximately 400GB of RAM. This is where on-disk indexing algorithms like DiskANN provide significant cost benefits.
DiskANN, based on the Vamana graph algorithm, enables efficient disk-based vector search while storing most of the index on NVMe SSDs rather than RAM. This approach offers several cost advantages:
Reduced hardware costs: Organizations can deploy vector search at scale using commodity hardware with modest RAM configurations
Lower operational expenses: Less RAM means lower power consumption and cooling costs in data centers
Linear cost scaling: Memory costs scale linearly with data volume, while performance remains relatively stable
Optimized I/O patterns: DiskANN's specialized design minimizes disk reads through careful graph traversal strategies
The trade-off is typically a modest increase in query latency (often just 2-3ms) compared to purely in-memory approaches, which is acceptable for many production use cases.
Specialized Index Types
Binary Embedding Indexes are specialized for computer vision, image fingerprinting, and recommendation systems where data can be represented as binary features. These indexes serve different application needs. For image deduplication, digital watermarking, and copyright detection where exact matching is critical, optimized binary indexes provide precise similarity detection. For high-throughput recommendation systems, content-based image retrieval, and large-scale feature matching where speed is prioritized over perfect recall, binary indexes offer exceptional performance advantages.
Sparse Vector Indexes are optimized for vectors where most elements are zero, with only a few non-zero values. Unlike dense vectors (where most or all dimensions contain meaningful values), sparse vectors efficiently represent data with many dimensions but few active features. This representation is particularly common in text processing where a document might use only a small subset of all possible words in a vocabulary. Sparse Vector Indexes excel in natural language processing tasks like semantic document search, full-text querying, and topic modeling. These indexes are particularly valuable for enterprise search across large document collections, legal document discovery where specific terms and concepts must be efficiently located, and academic research platforms indexing millions of papers with specialized terminology.
Advanced Query Capabilities
At the core of vector databases lies their ability to perform efficient semantic searches. Vector search capabilities range from basic similarity matching to advanced techniques for improving relevance and diversity.
Basic ANN Search
Approximate Nearest Neighbor (ANN) search is the foundational search method in vector databases. Unlike exact k-Nearest Neighbors (kNN) search, which compares a query vector against every vector in the database, ANN search uses indexing structures to quickly identify a subset of vectors likely to be most similar, dramatically improving performance.
The key components of ANN search include:
Query vectors: The vector representation of what you're searching for
Index structures: Pre-built data structures that organize vectors for efficient retrieval
Metric types: Mathematical functions like Euclidean (L2), Cosine, or Inner Product that measure similarity between vectors
Top-K results: The specified number of most similar vectors to return
Vector databases provide optimizations to improve search efficiency:
Bulk vector search: Searching with multiple query vectors in parallel
Partitioned search: Limiting search to specific data partitions
Pagination: Using limit and offset parameters for retrieving large result sets
Output field selection: Controlling which entity fields are returned with results
Advanced Search Techniques
Range Search
Range search improves result relevancy by restricting results to vectors with similarity scores falling within a specific range. Unlike standard ANN search which returns the top-K most similar vectors, range search defines an "annular region" using:
An outer boundary (radius) that sets the maximum allowable distance
An inner boundary (range_filter) that can exclude vectors that are too similar
This approach is particularly useful when you want to find "similar but not identical" items, such as product recommendations that are related but not exact duplicates of what a user has already viewed.
Filtered Search
Filtered search combines vector similarity with metadata constraints to narrow results to vectors that match specific criteria. For example, in a product catalog, you could find visually similar items but restrict results to a specific brand or price range.
Highly Scalable vector databases support two filtering approaches:
Standard filtering: Applies metadata filters before vector search, significantly reducing the candidate pool
Iterative filtering: Performs vector search first, then applies filters to each result until reaching the desired number of matches
Text Match
Text match enables precise document retrieval based on specific terms, complementing vector similarity search with exact text matching capabilities. Unlike semantic search, which finds conceptually similar content, text match focuses on finding exact occurrences of query terms.
For example, a product search might combine text match to find products that explicitly mention "waterproof" with vector similarity to find visually similar products, ensuring both semantic relevance and specific feature requirements are met.
Grouping Search
Grouping search aggregates results by a specified field to improve result diversity. For example, in a document collection where each paragraph is a separate vector, grouping ensures results come from different documents rather than multiple paragraphs from the same document.
This technique is valuable for:
Document retrieval systems where you want representation from different sources
Recommendation systems that need to present diverse options
Search systems where result diversity is as important as similarity
Hybrid Search
Hybrid search combines results from multiple vector fields, each potentially representing different aspects of the data or using different embedding models. This enables:
Sparse-dense vector combinations: Combining semantic understanding (dense vectors) with keyword matching (sparse vectors) for more comprehensive text search
Multimodal search: Finding matches across different data types, such as searching for products using both image and text inputs
Hybrid search implementations use sophisticated reranking strategies to combine results:
Weighted ranking: Prioritizes results from specific vector fields
Reciprocal Rank Fusion: Balances results across all vector fields without specific emphasis
Full-Text Search
Full-text search capabilities in modern vector databases bridge the gap between traditional text search and vector similarity. These systems:
Automatically convert raw text queries into sparse embeddings
Retrieve documents containing specific terms or phrases
Rank results based on both term relevance and semantic similarity
Complement vector search by catching exact matches that semantic search might miss
This hybrid approach is particularly valuable for comprehensive information retrieval systems that need both precise term matching and semantic understanding.
Performance Engineering: Metrics That Matter
Performance optimization in vector databases requires understanding key metrics and their tradeoffs.
The Recall-Throughput Tradeoff
Recall measures the proportion of true nearest neighbors found among returned results. Higher recall requires more extensive search, reducing throughput (queries per second). Production systems balance these metrics based on application requirements, typically targeting 80-99% recall depending on use case.
When evaluating vector database performance, standardized benchmarking environments like ANN-Benchmarks provide valuable comparative data. These tools measure critical metrics including:
Search recall: The proportion of queries for which true nearest neighbors are found among returned results
Queries per second (QPS): The rate at which the database processes queries under standardized conditions
Performance across different dataset sizes and dimensions
An alternative is an open source benchmark system called VDB Bench. VectorDBBench is an open-source benchmarking tool designed to evaluate and compare the performance of mainstream vector databases such as Milvus and Zilliz Cloud using their own datasets. It also helps developers choose the most suitable vector database for their use cases.
These benchmarks allow organizations to identify the most suitable vector database implementation for their specific requirements, considering the balance between accuracy, speed, and scalability.
Memory Management
Efficient memory management enables vector databases to scale to billions of vectors while maintaining performance:
Dynamic allocation adjusts memory usage based on workload characteristics
Caching policies retain frequently accessed vectors in memory
Vector compression techniques significantly reduce memory requirements
For datasets that exceed memory capacity, disk-based vector search solutions provide a crucial capability. These algorithms optimize I/O patterns for NVMe SSDs through techniques like beam search and graph-based navigation.
Advanced Filtering and Hybrid Search
Vector databases combine semantic similarity with traditional filtering to create powerful query capabilities:
Pre-filtering applies metadata constraints before vector search, reducing the candidate set for similarity comparison
Post-filtering executes vector search first, then applies filters to results
Metadata indexing improves filtering performance through specialized indexes for different data types
Performant vector databases support complex query patterns combining multiple vector fields with scalar constraints. Multi-vector queries find entities similar to multiple reference points simultaneously, while negative vector queries exclude vectors similar to specified examples.
Scaling Vector Databases in Production
Vector databases require thoughtful deployment strategies to ensure optimal performance at different scales:
Small-scale deployments (millions of vectors) can operate effectively on a single machine with sufficient memory
Mid-scale deployments (tens to hundreds of millions) benefit from vertical scaling with high-memory instances and SSD storage
Billion-scale deployments require horizontal scaling across multiple nodes with specialized roles
Sharding and replication form the foundation of scalable vector database architecture:
Horizontal sharding divides collections across multiple nodes
Replication creates redundant copies of data, improving both fault tolerance and query throughput
Modern systems adjust replication factors dynamically based on query patterns and reliability requirements.
Real-World Impact
The flexibility of high performant vector databases is evident in their deployment options. Systems can run across a spectrum of environments, from lightweight installations on laptops for prototyping to massive distributed clusters managing tens of billions of vectors. This scalability has enabled organizations to move from concept to production without changing database technologies.
Companies like Salesforce, PayPal, eBay, NVIDIA, IBM, and Airbnb now rely on vector databases like open source Milvus to power large-scale AI applications. These implementations span diverse use cases—from sophisticated product recommendation systems to content moderation, fraud detection, and customer support automation—all built on the foundation of vector search.
In recent years, vector databases became vital in addressing the hallucination issues common in LLMs by providing domain-specific, up-to-date, or confidential data. For example, Zilliz Cloud stores specialized data as vector embeddings. When a user asks a question, it transforms the query into vectors, performs ANN searches for the most relevant results, and combines these with the original question to create a comprehensive context for the large language models. This framework serves as the foundation for developing reliable LLM-powered applications that produce more accurate and contextually relevant responses.
Conclusion
The rise of vector databases represents more than just a new technology—it signifies a fundamental shift in how we approach data management for AI applications. By bridging the gap between unstructured data and computational systems, vector databases have become an essential component of the modern AI infrastructure, enabling applications that understand and process information in increasingly human-like ways.
The key advantages of vector databases over traditional database systems include:
High-dimensional search: Efficient similarity searches on high-dimensional vectors used in machine learning and Generative AI applications
Scalability: Horizontal scaling for efficient storage and retrieval of large vector collections
Flexibility with hybrid search: Handling various vector data types, including sparse and dense vectors
Performance: Significantly faster vector similarity searches compared to traditional databases
Customizable indexing: Support for custom indexing schemes optimized for specific use cases and data types
As AI applications become increasingly sophisticated, the demands on vector databases continue to evolve. Modern systems must balance performance, accuracy, scaling, and cost-effectiveness while integrating seamlessly with the broader AI ecosystem. For organizations looking to implement AI at scale, understanding vector database technology isn't just a technical consideration—it's a strategic imperative.
 Frank Liu
Frank LiuFrank Liu is the Director of Operations & ML Architect at Zilliz, where he serves as a maintainer for the Towhee open-source project. Prior to Zilliz, Frank co-founded Orion Innovations, an ML-powered indoor positioning startup based in Shanghai and worked as an ML engineer at Yahoo in San Francisco. In his free time, Frank enjoys playing chess, swimming, and powerlifting. Frank holds MS and BS degrees in Electrical Engineering from Stanford University.
- Introduction: The Rise of Vector Databases in the AI Era
- Understanding Vector Embeddings: The Foundation
- Vector Databases: Core Concepts
- Vector Database Architecture: A Technical Framework
- Advantages of Vector Databases
- Use Cases for Vector Databases
- Vector Search Algorithms: From Theory to Practice
- Advanced Query Capabilities
- Performance Engineering: Metrics That Matter
- Scaling Vector Databases in Production
- Real-World Impact
- Conclusion
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Understanding Vector Databases: Compare Vector Databases, Vector Search Libraries, and Vector Search Plugins
Deep diving into better understanding vector databases and comparing them to vector search libraries and vector search plugins.

Everything You Need to Know about Vector Index Basics
