




Optimizing AI: A Guide to Stable Diffusion and Efficient Caching Strategies
This blog post will explore various caching strategies for optimizing Stable Diffusion models.
Read the entire series
- Cross-Entropy Loss: Unraveling its Role in Machine Learning
- Batch vs. Layer Normalization - Unlocking Efficiency in Neural Networks
- Empowering AI and Machine Learning with Vector Databases
- Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
- Vector Databases: Redefining the Future of Search Technology
- Local Sensitivity Hashing (L.S.H.): A Comprehensive Guide
- Optimizing AI: A Guide to Stable Diffusion and Efficient Caching Strategies
- Nemo Guardrails: Elevating AI Safety and Reliability
- Data Modeling Techniques Optimized for Vector Databases
- Demystifying Color Histograms: A Guide to Image Processing and Analysis
- Exploring BGE-M3: The Future of Information Retrieval with Milvus
- Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
- TF-IDF - Understanding Term Frequency-Inverse Document Frequency in NLP
- Understanding Regularization in Neural Networks
- A Beginner's Guide to Understanding Vision Transformers (ViT)
- Understanding DETR: End-to-end Object Detection with Transformers
- Vector Database vs Graph Database
- What is Computer Vision?
- Deep Residual Learning for Image Recognition
- Decoding Transformer Models: A Study of Their Architecture and Underlying Principles
- What is Object Detection? A Comprehensive Guide
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Algorithmic)
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Methodological)
- Understanding CoCa: Advancing Image-Text Foundation Models with Contrastive Captioners
- Florence: An Advanced Foundation Model for Computer Vision by Microsoft
- The Potential Transformer Replacement: Mamba
- ALIGN Explained: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
#Optimizing AI: A Guide to Stable Diffusion and Efficient Caching Strategies
Introduction
The AI industry is moving at lightning speeds. Models and applications are becoming increasingly complex and constantly pushing the boundaries of what’s possible. Text-to-image generative models, such as OpenAI’s DALLE-2, Stable Diffusion, Midjourney, have enabled the creation of highly realistic and diverse images in seconds.
The impact of diffusion models extends beyond just generating visually appealing images. They have the potential to revolutionize various industries by enabling the creation of personalized and engaging visual content. For example, diffusion models can generate custom products, create immersive virtual experiences, or even assist in developing video games and animations.
However, as these models grow in complexity and performance, they also demand more computational power to run efficiently. This is why optimization is so crucial for AI models.
This blog post will explore various caching strategies for optimizing Stable Diffusion models.
Understanding Stable Diffusion
Stable Diffusion is an open-source deep learning model that generates high-quality images from textual descriptions. It requires only a decent GPU or a GPU server, which can be rented for a few cents an hour.
The model is trained on large datasets of image-text pairs, learning to generate images that match the given textual descriptions. It enables you to alter images using nothing but text, making it an incredibly versatile tool for various applications.
How does it work? Stable Diffusion combines the concepts of diffusion models and latent representation learning to create visually coherent and detailed images that closely match the given text input.
In general, the training process of diffusion models involves corrupting the input images with Gaussian noise at various scales and then learning to reverse this process by predicting the noise that needs to be removed at each step. The model gradually generates a clean, high-quality image that matches the given prompt by iteratively denoising the image.
##Stable Diffusion Architecture
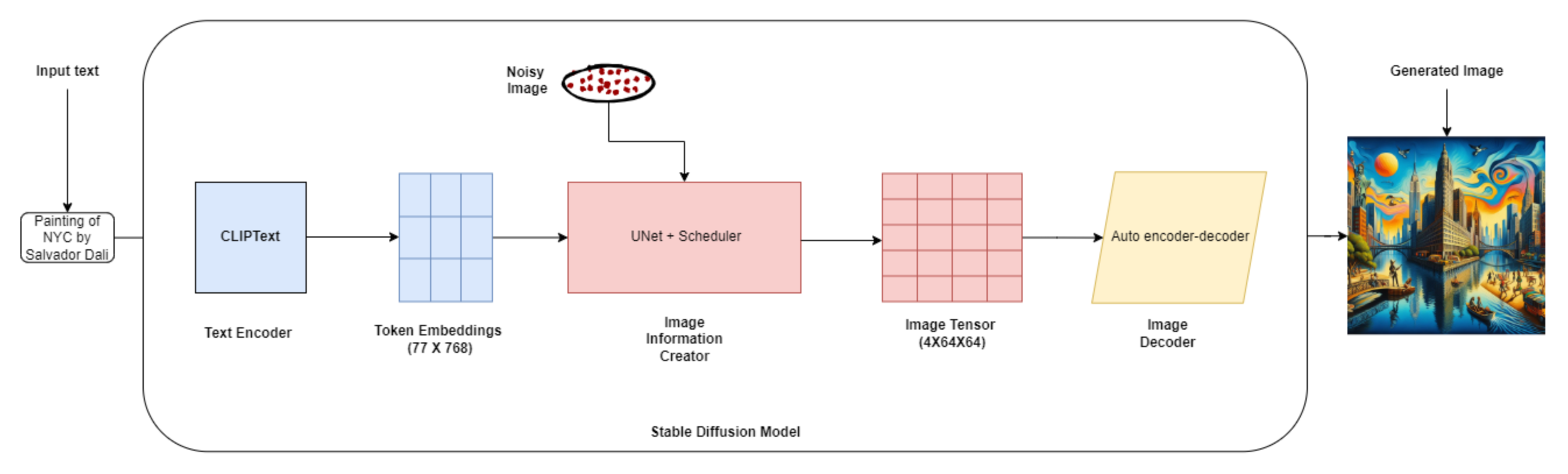 Stable Diffusion Architecture.png
Stable Diffusion Architecture.png
Stable Diffusion's architecture consists of three key components:
- Text Encoder (OpenAI’s CLIP): The text encoder maps the input text description into a latent space that can be used to condition the U-Net during image generation.
- Variational Autoencoder (VAE): The VAE is responsible for encoding images into a latent representation and decoding them back into the original image space.
- Noise estimation network (U-Net): The U-Net is a convolutional neural network that predicts the noise that needs to be removed at each denoising step, guiding the generation process toward the desired output image.
Here’s a simplified breakdown of the entire process:
- Text Encoding: Let's say you want to generate an image of "a cute puppy playing in a garden." The text encoder takes this prompt and converts it into a numerical representation.
- Latent Space Initialization: Imagine you want to generate a 256x256 pixel image. The latent space initialization would create a random noise tensor of shape (1, 256, 256, 3) as the starting point.
- Diffusion Process: The diffusion process iteratively refines the latent representation. At each step, the U-Net takes the noisy latent representation and the encoded text prompt as inputs and predicts the noise to be removed.
- Iterative Refinement: Let's say the diffusion process consists of 1000 timesteps. At each timestep, the U-Net refines the latent representation, making it less noisy and more coherent.
- Image Decoding: After the diffusion process, the final latent representation is passed through the decoder network to generate the output image. The decoder converts the latent representation into pixel values.
Why do you need to optimize?
- API Costs: Optimizing Stable Diffusion models reduces API costs by improving inference speed, reducing memory consumption, and enabling efficient resource use
- The Need for Speed: In many real-world applications, such as interactive image editing tools or real-time image generation systems, fast inference speed is crucial for providing a seamless user experience. Optimization significantly reduces inference time.
- Scalability: Optimized models can handle higher volumes of requests and scale efficiently to meet growing demands.
- Resource Efficiency: AI optimization techniques reduce memory footprint and computational requirements, allowing for cost-effective deployment.
- Deployment Flexibility: Optimized models can be deployed on various hardware platforms, including resource-constrained devices, expanding their applicability.
Now, let’s look at how caching can improve this process.
The Role of Caching in AI Models
Caching is a fundamental technique that involves storing frequently used data—or in the case of generative AI model: previously computed results—in a fast-access memory location so it can be reused.
The concept is simple: When a user prompts the model, we can save that request to the database, and the next time a user makes the same or similar prompt, the model can use some of the saved data to respond.
Given the sequential denoising process and the substantial model size, Stable Diffusion can lead to significant computational costs. However, for such resource-intensive models, caching can be a game-changer, efficiently storing and retrieving intermediate activations and embeddings generated during the inference process.
Various caching strategies can improve computational efficiency:
- Vector Databases: These purpose-built databases, capable of storing high-dimensional data as vectors, can swiftly retrieve latent representations and vector embeddings generated from a wide range of ML models. Setting up vector databases for the most common queries can reduce the need for re-computation and enhance model inference speed, making them a versatile tool in your caching strategy arsenal.
- Memoization: Memoization is an effective caching technique that stores the results of expensive function calls and retrieves the cached result when the same inputs are encountered again. This strategy optimizes recursive algorithms and functions with repetitive computations, eliminating redundant calculations and improving execution speed.
- Latent Caching: The model caches the latent representations of previously processed inputs. When a similar input is encountered, the cached latent representation can be retrieved, bypassing the need for re-computation.
- Time-based Cache: Time-based caching assigns an expiration time or time-to-live (TTL) value to each item in the cache. When the specified expiration time is reached, the item is either removed or marked as invalid, requiring a fresh retrieval from the original source to ensure data relevance and validity.
- Cache Eviction Policies: Cache eviction policies determine which items are removed from the cache when it reaches its capacity. Common eviction policies include FIFO (First In, First Out), LIFO (Last In, First Out), LRU (Least Recently Used), LFU (Least Frequently Used), and Random Replacement, each employing different criteria to select items for removal.
There are also certain novel caching strategies that have been developed specifically for diffusion models like Stable Diffusion:
- DeepCache: DeepCache accelerates diffusion models without the need for additional training. It works its magic by caching and retrieving features across denoising stages, cutting out redundant computations. By cleverly reusing high-level features and efficiently updating low-level ones, DeepCache achieves impressive speedups, while maintaining top-notch image quality.
- Approximate Caching: Approximate caching cleverly reuses intermediate noise states from prior image generations to reduce the number of denoising steps needed for new prompts. This technique can skip initial steps by leveraging the similarity between prompts, saving valuable computation time. It's paired with a smart cache management policy called LCBFU to ensure optimal model efficiency.
- Block Caching: Block caching takes advantage of the smooth changes in layer outputs over time, recognizing distinct patterns based on their position in the network. By reusing outputs from previous steps, it avoids redundant calculations. With a nifty scale-shift alignment trick and automatic scheduling, block caching keeps artifacts at bay and performance at its peak.
Implementing Caching in Stable Diffusion
Caching in Stable Diffusion aims to store and reuse intermediate computations to avoid redundant calculations and speed up the image generation process.
The key idea is to identify and cache frequently used or computationally intensive intermediate results, such as latent representations or attention maps, during the forward pass of the model.
Here’s how you can use vector databases to implement caching strategies in Stable Diffusion:
- Identify the layers or modules where caching can provide significant performance gains, such as self-attention layers or bypassing the U-net process.
- Implement a caching mechanism to store the intermediate results of these layers during the forward pass. During the forward pass of the Stable Diffusion mode, store the intermediate latent representations and embeddings in a vector database.
- During subsequent forward passes, check if the cached results are available (and valid for the current input) in the vector database. If a close match is found, retrieve the cached result instead of recomputing them (which reduces the number of denoising steps required), and use it as a starting point for the diffusion process.
- Update or invalidate the cache in the vector database when necessary, such as when the input or model parameters change.
An example of the process in pseudocode:
import faiss
class StableDiffusion:
def __init__(self, autoencoder, unet, conditioning_model):
self.autoencoder = autoencoder
self.unet = unet
self.conditioning_model = conditioning_model
self.vector_db = faiss.IndexFlatL2(latent_dim) # Initialize vector database
def generate_image(self, conditioning_input, timesteps):
latent = self.autoencoder.encode(conditioning_input)
# Query the vector database for similar latent representations
distances, indices = self.vector_db.search(latent, k=1)
if distances[0] < threshold:
# Retrieve cached latent representation
latent = self.vector_db.reconstruct(indices[0])
else:
for t in timesteps:
latent = self.diffusion_step(latent, t, conditioning_input)
# Add the new latent representation to the vector database
self.vector_db.add(latent)
image = self.autoencoder.decode(latent)
return image
Use Cases and Benefits
Optimizing Stable Diffusion models with efficient caching strategies has numerous real-world applications and benefits. Let's explore a few use cases:
- Digital Art Creation: Artists and designers can leverage optimized Stable Diffusion models to generate high-quality digital art efficiently. The model can quickly generate variations or iterations by caching frequently used styles or patterns, streamlining the creative process.
- Content Generation: Media and entertainment companies can utilize optimized Stable Diffusion models to generate diverse and engaging visual content at scale. With efficient caching, the model can quickly generate images based on similar text inputs, enabling rapid content creation and personalization.
- Product Visualization: E-commerce platforms can employ optimized Stable Diffusion models to generate realistic product images for various categories and styles. Caching frequently accessed product attributes or styles can significantly speed up the image generation process, enhancing the user experience and reducing computational costs.
Challenges and Considerations
While implementing caching in Stable Diffusion offers significant benefits, there are also challenges and considerations to keep in mind:
- Memory Management: It's important to balance between the size of the cache and the available memory. Strategies like cache eviction policies or compression techniques can help manage memory effectively.
- Indexing and Search Efficiency: As the vector database's size grows, similarity search efficiency can become a bottleneck. Choose an appropriate vector indexing strategy, such as hierarchical navigable small world (HNSW) graphs, to improve search performance and scalability. *** Cache Invalidation**: As the model evolves or new data is introduced, cached representations may become stale or invalid. Implementing cache invalidation strategies, such as time-based expiration or versioning, is crucial to ensure the freshness and accuracy of cached data.
- Scalability: The cache size can grow significantly when dealing with large-scale applications or datasets. Designing caching strategies that can scale efficiently, such as distributed caching or using cloud-based storage solutions, is essential.
- Cache Coherence: In distributed environments or multi-node setups, maintaining cache coherence across different instances of the model can be challenging. Implementing synchronization mechanisms or using distributed caching frameworks can help ensure data consistency.
- Latency and Throughput: Querying vector databases for similar inputs introduces additional latency to the image generation process. You have to balance the trade-off between cache hit rate and latency to maintain fast performance. Techniques like batch processing or asynchronous updates can help improve throughput.
To navigate these challenges, regularly monitor the caching system to help identify bottlenecks and optimize performance.
Conclusion
By leveraging vector databases and caching techniques like latent caching, block caching, approximate caching, and more, you can significantly improve your AI applications' performance, scalability, and cost-effectiveness.
Implementing these caching strategies comes with its challenges. But don't let that intimidate you – by leveraging a caching strategy, you can tackle these challenges head-on and find solutions that work for your specific project.
With optimized Stable Diffusion models at your users' fingertips, the possibilities are boundless. You have the potential to bring forth incredible creations that were once unimaginable.

- Introduction
- Understanding Stable Diffusion
- Why do you need to optimize?
- The Role of Caching in AI Models
- Implementing Caching in Stable Diffusion
- Use Cases and Benefits
- Challenges and Considerations
- Conclusion
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Demystifying Color Histograms: A Guide to Image Processing and Analysis
Mastering color histograms is indispensable for anyone involved in image processing and analysis. By understanding the nuances of color distributions and leveraging advanced techniques, practitioners can unlock the full potential of color histograms in various imaging projects and research endeavors.

Deep Residual Learning for Image Recognition
Deep residual learning solves the degradation problem, allowing us to train a neural network while still potentially improving its performance.

The Potential Transformer Replacement: Mamba
Mamba is a new architecture for sequence modeling, designed to offer an alternative to the Transformer models commonly used in machine learning.