




Exploring OpenAI CLIP: The Future of Multi-Modal AI Learning
Multimodal AI learning can get input and understand information from various modalities like text, images, and audio together, leading to a deeper understanding of the world. Learn more about OpenAI's CLIP (Contrastive Language-Image Pre-training), a popular multimodal model for text and image data.
Read the entire series
- OpenAI's ChatGPT
- Unlocking the Secrets of GPT-4.0 and Large Language Models
- Top LLMs of 2024: Only the Worthy
- Large Language Models and Search
- Introduction to the Falcon 180B Large Language Model (LLM)
- OpenAI Whisper: Transforming Speech-to-Text with Advanced AI
- Exploring OpenAI CLIP: The Future of Multi-Modal AI Learning
- What are Private LLMs? Running Large Language Models Privately - privateGPT and Beyond
- LLM-Eval: A Streamlined Approach to Evaluating LLM Conversations
- Mastering Cohere's Reranker for Enhanced AI Performance
- Efficient Memory Management for Large Language Model Serving with PagedAttention
- LoRA Explained: Low-Rank Adaptation for Fine-Tuning LLMs
- Knowledge Distillation: Transferring Knowledge from Large, Computationally Expensive LLMs to Smaller Ones Without Sacrificing Validity
- RouteLLM: An Open-Source Framework for Navigating Cost-Quality Trade-Offs in LLM Deployment
- Prover-Verifier Games Improve Legibility of LLM Outputs
- Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
- Unlocking the Power of Many-Shot In-Context Learning in LLMs
- Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text
- Teaching LLMs to Rank Better: The Power of Fine-Grained Relevance Scoring
- Everything You Need to Know About LLM Guardrails
- Chain-of-Retrieval Augmented Generation
- Chain of Agents (COA): Large Language Models Collaborating on Long-Context Tasks
Artificial intelligence (AI) is transforming and witnessing a shift to a new approach, multimodal AI learning. These systems can get input and understand information from various modalities as humans do. Text, images, and audio can be processed together, leading to a more refined understanding of the world.
At the forefront of this multimodal learning transformation stands OpenAI's CLIP (Contrastive Language-Image Pre-training), a model for text and image data. The CLIP model, including variants like clip-vit-base-patch32, has propelled AI learning to expanding the horizons of our understanding by enabling the use of both 'eyes' and 'tongue.' Its advancements inspire us to envision a future where AI can truly comprehend the world.
What is OpenAI CLIP?
Multi-modal AI has been of interest in artificial intelligence (AI). OpenAI CLIP, the Contrastive Language-Image Pretraining model, aims to understand the image as well as natural language. This concept of associating image-caption pairs created with popular datasets like ImageNet and other medical and astronomical images has reduced the need for domain-specific training for computer vision AI models. Engineers have shown that OpenAI CLIP can recognize the names of more than 40,000 famous faces with just a few examples.
Why is this big news? The chained associations used to create OpenAI CLIP were created using models similar to unsupervised transformer models, so while it is capable of doing things like identifying if an image contains any cat-like qualities, it makes mistakes with things that operate on a subtext level, like styles of art, as art is uniquely known for its depth of metaphor and innuendo across any number of famous masterpieces. The world of business and industry now is beginning to shift from simple black box models that merely start to "figure out" a dataset under the hood to a world in which we want to ensure that our models are "doing the math" correctly and don't misunderstand the fundamentals. Organizations now will be hungry for multi-modal AI that can better understand the real world as OpenAI CLIP continues to grow and become multi-lingual. For example, the Shinrinyoku Project in Japan, which measures gender-specific sentiment for discussing trees versus women in Japan's Flickr data, is mostly driven by the team's use of a similar approach.
Background and Development
Can you depict the relationship between a zebra and a picture of a zebra? Of course you can. Now, what about the text "a small black and white zebra" and a zebra image? It becomes a more difficult task when asked in the open-domain, as most AI models are typically trained on single data modalities such as images or text. OpenAI CLIP, particularly the clip-vit-base-patch32 variant, is a novel model that uses multimodal training to learn to pair sentences and image tokens, and has quickly become a leading solution in the field.
Weaknesses of Traditional Vision Models
It was built to test and overcome some of the weaknesses of traditional methods such as:
Costly datasets: Traditionally, vision models are trained on dataset annotated by humans which is expensive and time consuming. The example OpenAI cite's is that the ImageNet dataset had over 25,000 workers to label 14 million images for 2,000 object categories.
Narrow: The Imagenet model is pretty narrow and only knows 1000 ImageNet categories and it can't generalize beyond that.
Limited real-world applicability: Traditional vision models are often developed and trained on specific datasets that may not align with diverse real-world scenarios, potentially leading to suboptimal performance in practical applications.
To overcome these limitations, the OpenAI team took a different approach. The CLIP model was pre-trained on a dataset of 400 million image-text pairs collected from the internet. The model architecture consists of two main components: an image encoder and a text encoder. These encoders map images and text into a shared, high-dimensional embedding space.
The training process uses a contrastive learning approach, where the model learns to maximize the similarity between embeddings of matched image-text pairs while minimizing similarity for unmatched pairs. This contrastive objective helps the model learn to align visual and textual representations in the shared embedding space.
One of CLIP's most notable features is its zero-shot capability. Because it learns to associate images with natural language descriptions, CLIP can recognize and classify images into categories it wasn't explicitly trained on, simply by comparing image embeddings to text embeddings of category names or descriptions. This capability is made possible by the sophisticated image encoder used in models like clip-vit-base-patch32.
CLIP's approach has influenced the development of subsequent multi-modal AI systems. Models like DALL-E, which generates images from text descriptions, build upon similar principles of aligning visual and textual representations. More recent systems like GPT-4 with vision capabilities and LLaVA (Large Language and Vision Assistant) further extend these ideas, integrating visual understanding more deeply with large language models. These advancements often build upon the foundational work done in CLIP's image encoder and text encoder components.
It's worth noting that while CLIP demonstrated zero-shot performance across a wide range of tasks, it doesn't always outperform specialized models fine-tuned for specific tasks. However, its flexibility understand robustness and generalizability make it a powerful tool for many applications, especially where adaptability to new categories or tasks is important. The versatility of CLIP's image encoder, as seen in variants like clip-vit-base-patch32, contributes significantly to this adaptability.
The Impact of CLIP
The impact of CLIP extends beyond image classification. It has been used for tasks like image retrieval, where it can find images that match text descriptions, and even for guiding image generation in text-to-image models. Its ability to create meaningful connections between images and text it hasn't seen during training opens up possibilities for creative applications and more intuitive human-AI interactions in visual domains.
 Contrastive pre-training
Contrastive pre-training
In a significant move towards exploring the capabilities of OpenAI CLIP, researchers showcased both its strengths and weaknesses using a technique known as prompt engineering (or natural language prompts).
Zero-Shot Learning with CLIP
Being Zero-Shot means CLIP can recognize new objects and generate new connections without any training on that specific example. Popular image generation models like DALL-E and Stable Diffusion use CLIP for encoding image understanding in their architectures.
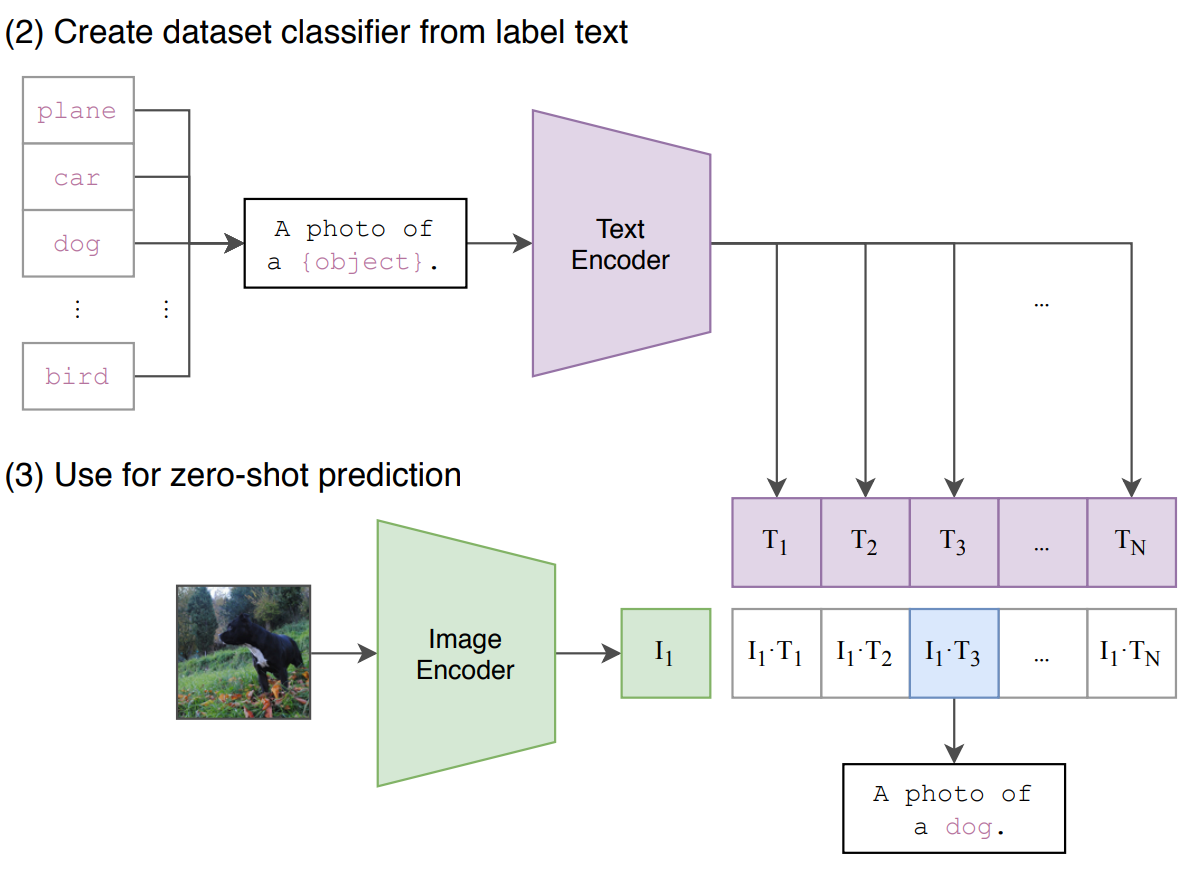 Image Generation Model Architecture
Image Generation Model Architecture
Older SOTA image classification models’ capabilities were limited to the datasets they were trained on; for instance, ImageNet models’ zero-shot capabilities are limited to just classifying 1000 classes it was trained on.
If one wanted to perform any other vision task, they had to attach a new head to the ImageNet model, curate a labeled dataset, and finetune the model. But CLIP can be used off-the-shelf for a variety of computer vision tasks without the need for any finetuning or labeled data.
CLIP is versatile enough to handle numerous visual classification tasks without the requirement for extra training data. To utilize CLIP for a different task, one simply needs to inform its text encoder about the visual concepts related to the task. Consequently, CLIP generates a linear classifier based on its visual representations. Remarkably, the precision and accuracy of this classifier frequently rivals that of models trained with full supervision.
Unsplash uses CLIP to label their image. We can see a demo of the remarkable zero-shot prediction capability of CLIP on a few random samples from different datasets.
 Image Labeling
Image Labeling
Efficient indexing of CLIP Embeddings
If we use CLIP for zero-shot tasks on data with many target classes or large groups of images, doing it manually could exhaust computing resources and time. On the other hand, we can efficiently index the clip embeddings using a vector database. For instance, consider labeling an extensive collection of images on UnSplash by categories. We can save the computed image embeddings in an efficient and diverse vector store like Zilliz! Find the top k of each category label's most similar image vectors.
Using a vector store for massive zero-shot image labeling is just one of the few use cases in which vector stores like Zilliz can efficiently help us fully leverage the true potential of strong multimodal models like CLIP. We can extend the utility of this combo for many other use cases, like semantic search, unsupervised data exploration, and more!
Implementing CLIP: A guide
Let’s perform zero-shot image classification using a pre-trained CLIP model from HugginFace. The HF hub hosts quite a few options for various pre-trained CLIP model variants. We will use <openai-/clip-vit-bse-patch32> model and will perform image classification using the transformers library on some sampler from the MS-COCO dataset.
Step 1. OpenAI CLIP ViT-Base Model can be loaded by using libraries like Transformers from Hugging Face by the following code:
from transformers import CLIPProcessor, CLIPModel model = CLIPModel.from\_pretrained("openai/clip-vit-base-patch32") processor = CLIPProcessor.from\_pretrained("openai/clip-vit-base-patch32")
Step 2. Now, you can retrieve a couple of images from COCO dataset by running the following piece of code:
from PIL import Image import requests image\_1 = Image.open(requests.get("http\://images.cocodataset.org/val2014/COCO\_val2014\_000000159977.jpg",stream=True).raw) image\_2 = Image.open(requests.get('http\://images.cocodataset.org/val2014/COCO\_val2014\_000000555472.jpg',stream=True).raw) images = \[image\_1,image\_2]
Step 3. To visualize the images as an output, below is the code snippet with a visual output:
import numpy as np import cv2 from google.colab.patches import cv2\_imshow def visualize(image): image\_arr = np.array(image) image\_arr = cv2.cvtColor(image\_arr, cv2.COLOR\_BGR2RGB) cv2\_imshow(image\_arr) for img in images: visualize(img)

Step 4. At this step, you can perform zero-shot inference on the images using CLIP by running the simple code below:
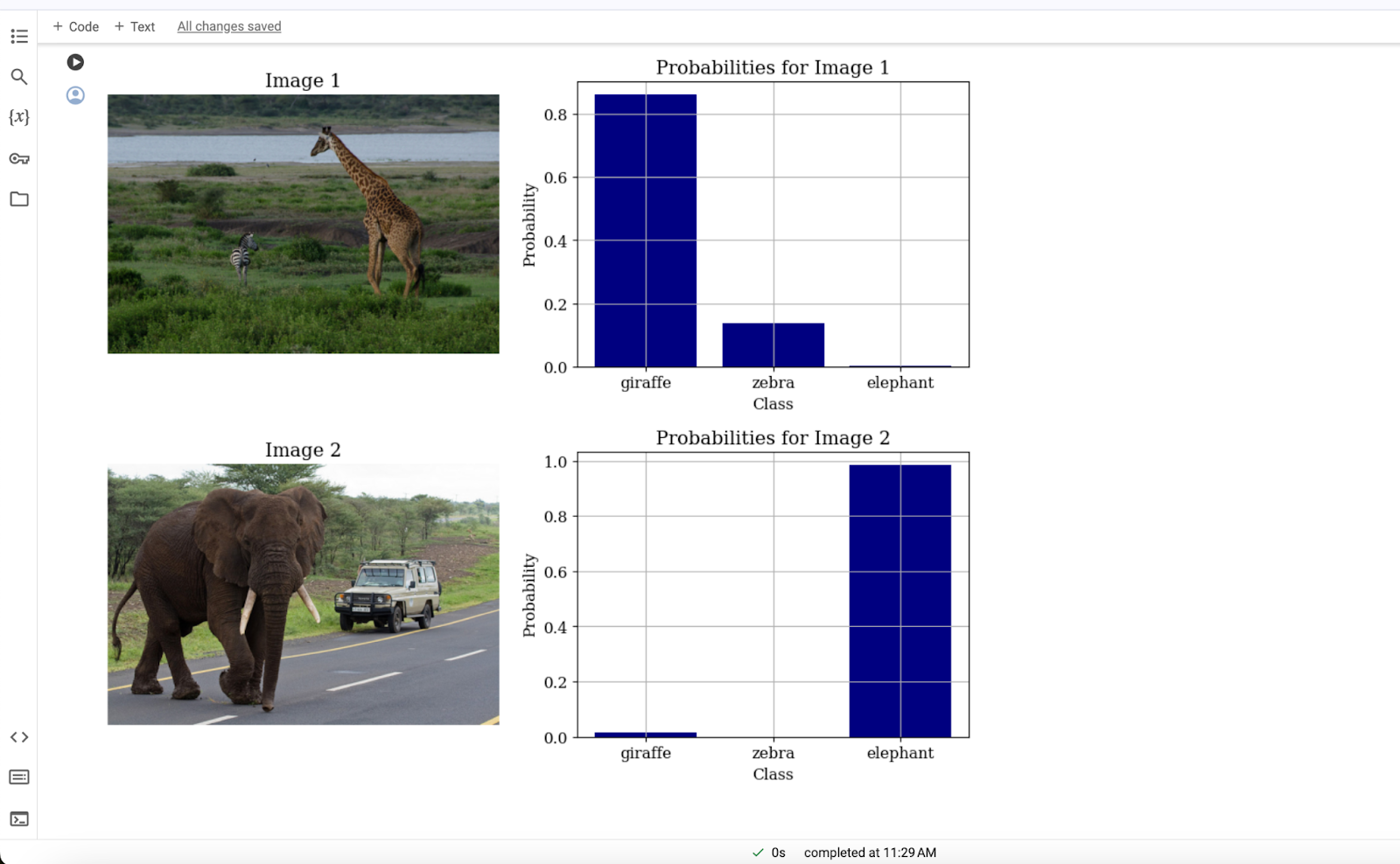
classes = \['giraffe', 'zebra', 'elephant'] inputs = processor(text=classes, images=images, return\_tensors="pt", padding=True) outputs = model(\*\*inputs) logits\_per\_image = outputs.logits\_per\_image probs = logits\_per\_image.softmax(dim=1)
Step 5. Finally, to get segregation on the images, you can simply visualize the results for both of the images in terms of graphs; the following code will produce an output of images with graphs:
# Visualize results for both images using separate graphs import matplotlib.pyplot as plt # Set the font family and size plt.rc('font', family='serif', size=12) # Loop through both images and their probabilities for i in range(2): # Create a new figure plt.figure(figsize=(12, 4)) # Create two subplots in the figure ax1 = plt.subplot(1, 2, 1) ax2 = plt.subplot(1, 2, 2) # Display the image in the first subplot ax1.imshow(images\[i]) ax1.axis('off') ax1.set\_title(f"Image {i+1}") # Create a bar plot of the probabilities in the second subplot ax2.bar(classes, probs\[i].detach().numpy(), color="navy") ax2.set\_xlabel('Class') ax2.set\_ylabel('Probability') ax2.set\_title(f"Probabilities for Image {i+1}") ax2.grid(True) # Show the plot plt.show()
Conclusion
OpenAI CLIP stands as a transformative benchmark in multi-modal AI learning. While llms have advanced natural language processing due to the availability of expressive training corpora, CLIP demonstrates a novel approach in machine learning. It successfully cross-trains simple modal architectures by leveraging token labels of cross-modal data, contrasting with traditional methodologies focused on computer vision, speech, and audio processing domains.
CLIP's innovation lies in its zero-shot learning and optimization of text-to-image retrieval. This approach enables the model to perform various image classification tasks without extensive prior learning, a capability that sets it apart from conventional models. The pre-training process during text-to-image retrieval allows CLIP to be versatile and customizable, making it applicable across a wide range of domains including image search, medical diagnostics, and e-commerce.
The impact of CLIP extends beyond its immediate applications. It has paved the way for groundbreaking advancements in AI, influencing the development of subsequent technologies such as image generation models in the stable diffusion series. By changing how machines learn and interact with visual and textual information, CLIP has opened new avenues for innovation in artificial intelligence, promising exciting developments in the field of multimodal learning and beyond.
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
- What is OpenAI CLIP?
- Background and Development
- Zero-Shot Learning with CLIP
- Efficient indexing of CLIP Embeddings
- Implementing CLIP: A guide
- Conclusion
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Unlocking the Secrets of GPT-4.0 and Large Language Models
Unlocking the Secrets of GPT-4.0 and Large Language Models
Teaching LLMs to Rank Better: The Power of Fine-Grained Relevance Scoring
We’ll explore the limitations of binary relevance labels, how fine-grained relevance scoring works, and why it’s a game-changer for zero-shot text rankers

Chain of Agents (COA): Large Language Models Collaborating on Long-Context Tasks
Discover how Chain-of-Agents enhances Large Language Models by effectively managing context injection, improving response quality while addressing token limitations.