




A Beginner's Guide to Understanding Vision Transformers (ViT)
Vision Transformers (ViTs) are neural network models that use transformers to perform computer vision tasks like object detection and image classification.
Read the entire series
- Cross-Entropy Loss: Unraveling its Role in Machine Learning
- Batch vs. Layer Normalization - Unlocking Efficiency in Neural Networks
- Empowering AI and Machine Learning with Vector Databases
- Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
- Vector Databases: Redefining the Future of Search Technology
- Local Sensitivity Hashing (L.S.H.): A Comprehensive Guide
- Optimizing AI: A Guide to Stable Diffusion and Efficient Caching Strategies
- Nemo Guardrails: Elevating AI Safety and Reliability
- Data Modeling Techniques Optimized for Vector Databases
- Demystifying Color Histograms: A Guide to Image Processing and Analysis
- Exploring BGE-M3: The Future of Information Retrieval with Milvus
- Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
- TF-IDF - Understanding Term Frequency-Inverse Document Frequency in NLP
- Understanding Regularization in Neural Networks
- A Beginner's Guide to Understanding Vision Transformers (ViT)
- Understanding DETR: End-to-end Object Detection with Transformers
- Vector Database vs Graph Database
- What is Computer Vision?
- Deep Residual Learning for Image Recognition
- Decoding Transformer Models: A Study of Their Architecture and Underlying Principles
- What is Object Detection? A Comprehensive Guide
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Algorithmic)
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Methodological)
- Understanding CoCa: Advancing Image-Text Foundation Models with Contrastive Captioners
- Florence: An Advanced Foundation Model for Computer Vision by Microsoft
- The Potential Transformer Replacement: Mamba
- ALIGN Explained: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
Vision Transformers (ViT) are neural network models based on the transformer architecture and are purpose-built to process image data. In Transformers, attention is a mechanism that helps models focus on relevant parts of the input data to better understand and generate predictions, allowing them to process information more context-aware and flexibly. Vision Transformers apply the concept of attention to images to distinguish key elements from within vast canvases. Attention also allows ViT to capture global relationships and outperform existing vision models.
Global attention separates the transformer model from the conventional Convolutional Neural Networks (CNNs). A CNN captures and aggregates information from neighboring pixels, capturing local relationships only. ViT works on a broader canvas, and each image segment is compared across the board. While this approach increases computational complexity, ViT significantly boosts performance.
Vision Transformers have performed remarkably in object detection, image classification, and semantic segmentation tasks. This blog will explore the ViT architecture in detail and briefly explain its implementation using the Hugging Face models.
What are Transformers?
Vaswani et al. introduced the transformer architecture in the paper "Attention is All You Need" (2017). The transformer model introduced the self-attention mechanism, allowing it to build relationship contexts between different parts of the input data.
Transformers gained massive popularity, especially in Natural Language Processing (NLP), due to their deep understanding of the data and impressive results. They use the attention mechanism to derive relationships between words in a sentence. This approach allows them to gather a semantic understanding of the text and generate context-aware, information-rich vector embeddings that yield accurate results in AI modeling.
How Do Transformers Work?
Building a semantic relationship requires mapping data points onto a shared semantic n-dimensional space. Each data point is located at a specific position in the space, and the distance between the various points determines their relationship.
In NLP, the first step is to break down the natural language text into tokens. These tokens are then converted to embeddings representing their location in the semantic space. The embeddings are created such that similar tokens remain in close proximity.
For example, words like ‘car’, ‘motorcycle’, and ‘airplane’ will be mapped closer to each other since they all fall under the category of vehicles. The close data points are also said to have a higher alignment score.
 Figure 1- How vector embeddings are created
Figure 1- How vector embeddings are created
Figure 1: How vector embeddings are created
However, language is tricky, and the meanings of terms often change depending on their context. Transformers move the word embeddings within the latent space depending on the context of the text. Popular models like BERT consist of multiple encoder layers, each applying the attention mechanism to modify the embedding values. As the text sentence passes through the encoders, each word is compared with the rest of the tokens, and its embedding is modified depending on the provided context.
Once the embeddings are generated, they are passed to the final head layer, which makes predictions depending on the task. The construction of the head layer depends on the task; for example, it will output class probabilities for a classification task or another sequence for a seq-2-seq modeling task.
What are Vision Transformers?
While transformers are mostly utilized for language tasks, a variation called Vision Transformers (ViT) is used for modeling image data. The general intuition behind transformers is that data points hold a certain importance level depending on their position and context in the dataset. For example, certain words provide more meaning to the overall sentence than others and should be prioritized during modeling. The same is true for pixels or patches within a larger image.
An image can contain multiple objects in different positions, each holding a different value depending on the task. Vision transformers use the attention mechanism to capture the relationship between image patches.
 Figure 2- Applying attention to images - Source
Figure 2- Applying attention to images - Source
Figure 2: Applying attention to images - Source
The approach remains the same as with language data, but we pass image patches to the transformer architecture instead of tokens. This approach captures more information than traditional CNNs and provides a better way to model image data.
Challenges of Vision Transformers
Adopting transformers for image data adds certain computational challenges as images are much larger in size compared to individual sentences. A small image of size 255 x 255 consists of 65,025 pixels. Since the self-attention mechanism compares each pixel with the entire dataset, the CPU calculation would have to perform roughly 65,025 x 65,025 = 4.2x109 comparison operations, which is a computational nightmare. To solve this problem, the authors of the original ViT paper suggest dividing the image into patches and treating each patch as an input to the transformer. This method is far more efficient and captures sufficient information for effective training.
The Vision Transformers (ViT) Architecture
The first step in ViT encoding is generating a flattened array of image patches. The patches are passed to an initial feed-forward linear projection layer. This layer projects the flattened patches to an embedding space so the transformer can process them later.
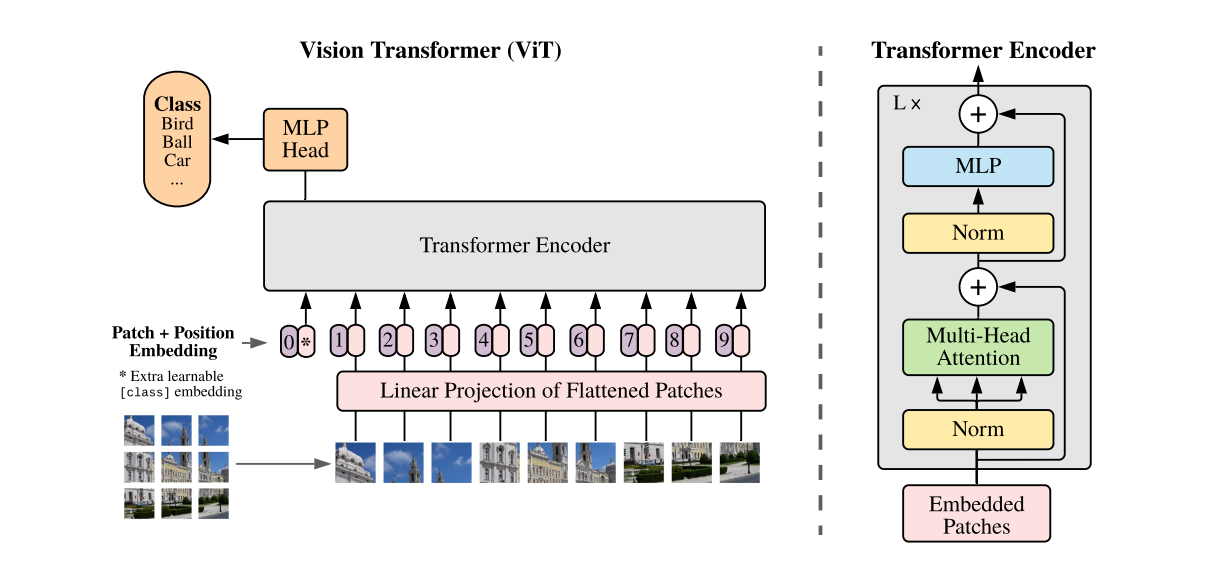 Figure 3- ViT Architecture - Source
Figure 3- ViT Architecture - Source
Figure 3: ViT Architecture - Source
Once the general image embeddings are created, two more steps are required. First, a class token (CLS) is prepended to the embeddings. This approach is adopted from the BERT network, which uses this additional token for learnable embedding. Initially, this token is a blank slate and contains no information. However, as it passes through the transformer layers, it aggregates information from all the patches, and the final output represents the entire original image. This token is used for classification tasks and fed to a classifier for final predictions.
The second step is to apply positional encoding to the patch embeddings, as transformers do not have any default mechanism to identify sequences in data. Sequences are important to highlight as jumbled-up patches will misrepresent the original image and lead to poor learning. The positional embeddings are learned during pre-training, are the same size as the patch embeddings, and are directly added to the patch embeddings.
Transformer Encoder
The encoder is the main powerhouse behind the entire transformer model. It consists of three main components:
Norm Layer: The layer normalization helps scale the activations from the other major layers and provides stability to the training. Scaling the activations also allows for easy weight updates and faster training.
Multi-Head Attention: This layer calculates the relationships amongst the different image patches. Being multi-head means that multiple attention calculations are occurring in parallel. Each head has its parameters and processes the input slightly differently. Intuitively, each head captures different information from the input and calculates an attention score, which becomes the weight of the value vectors. The output from each head is concatenated, forming a final rich representation.
Multi-Layer Perceptron (MLP): This basic feed-forward neural network introduces non-linearity and becomes the output of the transformer block. Combining it with a softmax layer can be used to output classification labels.
Implementation of Vision Transformer (ViT)
Now that we’ve discussed how a vision transformer works, we can implement a model from the Hugging Face directory. In this walkthrough, we will attempt to fine-tune a ViT model using the ‘Painting Style Classification’ dataset. You can access the full code of this implementation in this Google Colab notebook.
We start with installing and importing the relevant libraries.
pip install datasets transformers[torch]
from datasets import load_dataset, load_metric
from transformers import ViTImageProcessor, ViTForImageClassification, TrainingArguments, Trainer
import torch
import numpy as np
Next, we will load the dataset from the HuggingFace datasets library.
# pass config = 'mini' instead of 'full' for the smaller version
ds = load_dataset('keremberke/painting-style-classification', 'full')
We can understand the dataset configuration by printing the ds object.
ds
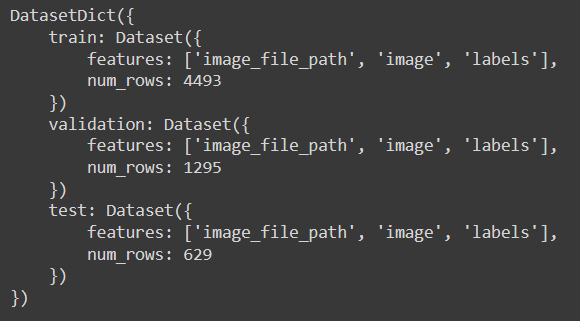
The printed result shows that the dataset contains images and labels. Moreover, it has 4493 images in the training set, 1295 in validation, and 629 in test. Ideally, a dataset should contain tens of thousands of images for proper training, which will suffice for this demonstration.
Let’s view an example image and its label.
data_index = 4000
example = ds['train'][data_index]['image']
labels = ds['train'].features['labels']
example # display image
# print label of above image
labels.int2str(ds['train'][data_index]['labels'])
 Figure 4- example image and its label. Label- ‘Romanticism’
Figure 4- example image and its label. Label- ‘Romanticism’
Figure 4: example image and its label. Label: ‘Romanticism’
Once the dataset is loaded, we can load the model. The model serves two purposes. First, it contains a preprocessor with the correct configurations to transform the input images and align them with the model's requirements. Second, it contains the model architecture containing the weights from the pre-training. We will first initialize the preprocessor and create a processing pipeline.
# Load the pretrained ViT model from HuggingFace
model_name_or_path = 'google/vit-base-patch16-224-in21k'
processor = ViTImageProcessor.from_pretrained(model_name_or_path)
The following code uses built-in functionality from Hugging Face and creates a real-time pipeline. This means that the processing is applied to an image only when the image is accessed. This saves on memory and unnecessary processing.
def transform(data_batch):
'''
Function to process batch of images altogether
'''
# Take a list of PIL images and turn them to pixel values
inputs = processor([x for x in data_batch['image']], return_tensors='pt')
inputs['labels'] = data_batch['labels']
return inputs
# the with_transform function applies transformation to the images in real-time
prepared_ds = ds.with_transform(transform)
Now, we need one final function to stack all the processed images on top of each other as torch tensors.
def collate_fn(batch):
'''
Function to stack up batch of images
'''
# batch is a list of dicts
return {
'pixel_values': torch.stack([x['pixel_values'] for x in batch]),
'labels': torch.tensor([x['labels'] for x in batch])
}
Now that data processing is set up, we will define training parameters such as the evaluation metrics and model initializations. We will compute accuracy, precision, and recall for evaluation, as this is a classification problem.
# Load accuracy, precision, and recall metrics
accuracy_metric = load_metric('accuracy')
precision_metric = load_metric('precision')
recall_metric = load_metric('recall')
def compute_metrics(p):
# Extract predictions and references
predictions = np.argmax(p.predictions, axis=1)
references = p.label_ids
# Compute accuracy
accuracy = accuracy_metric.compute(predictions=predictions, references=references)
# Compute precision (assume binary classification for simplicity)
precision = precision_metric.compute(predictions=predictions, references=references, average='macro')
# Compute recall (assume binary classification for simplicity)
recall = recall_metric.compute(predictions=predictions, references=references, average='macro')
# Combine all metrics into a single dictionary
return {
'accuracy': accuracy['accuracy'],
'precision': precision['precision'],
'recall': recall['recall']
}
Now, we initialize the model. We will pass it the model name and the number of classes in our dataset so the classification head can be initiated.
labels = ds['train'].features['labels'].names
model = ViTForImageClassification.from_pretrained(
model_name_or_path,
num_labels=len(labels),
id2label={str(i): c for i, c in enumerate(labels)},
label2id={c: str(i) for i, c in enumerate(labels)}
)
Finally, we will initialize the training parameters and create a Trainer object where we will specify the data processing functions we initialized earlier.
training_args = TrainingArguments(
output_dir="./vit-base-art",
per_device_train_batch_size=32,
evaluation_strategy="steps",
num_train_epochs=4,
fp16=True,
save_steps=100,
eval_steps=100,
logging_steps=10,
learning_rate=2e-4,
save_total_limit=2,
remove_unused_columns=False,
push_to_hub=False,
report_to='tensorboard',
load_best_model_at_end=True,
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=collate_fn,
compute_metrics=compute_metrics,
train_dataset=prepared_ds["train"],
eval_dataset=prepared_ds["validation"],
tokenizer=processor,
)
Everything is in place, and we can execute the training.
train_results = trainer.train()
trainer.save_model()
trainer.log_metrics("train", train_results.metrics)
trainer.save_metrics("train", train_results.metrics)
trainer.save_state()
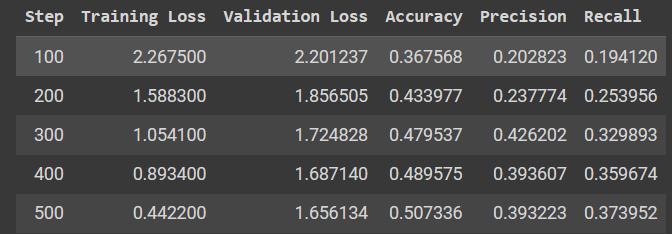 printed result
printed result
After 4 epochs, our validation accuracy reached 50.7%. The numbers might not seem too impressive, but training longer will improve them. Also, keep in mind that our dataset is limited.
Combining Vision Transformers (ViTs) with Vector Databases for Scalable and Efficient Image Retrieval
Vision Transformers (ViTs) transform how we understand and process visual data. They divide an image into patches, treating each as a token and using self-attention mechanisms to capture complex, global relationships within the image. This approach allows ViTs to generate rich, high-dimensional feature embeddings that comprehensively represent an image's visual content.
Vector databases like Milvus and Zilliz Cloud (the fully managed Milvus) are specialized systems designed to efficiently store, manage, and query high-dimensional vectors, which are often generated by machine learning models like ViTs. These databases are optimized for vector similarity searches, where the goal is to find vectors (and hence data) similar to a given query vector.
Incorporating ViTs with vector databases offers vast benefits. First, ViTs generate rich, high-dimensional embeddings of images that capture detailed visual information. These embeddings can be indexed and stored in a vector database like Milvus for fast image similarity searches. This combination enhances the capability to build powerful image retrieval systems, where users can search for images by uploading a sample and finding visually similar items quickly and accurately.
This integration can produce wide-ranging applications. In e-commerce, the vector database and ViT combination can enable image-based search features where users can find products similar to an uploaded image, improving user experience and engagement. In content management, it supports automated tagging and categorization of images based on visual features, reducing manual effort and increasing efficiency. Additionally, this synergy is useful in recommendation systems as well, where visually similar items are suggested based on the embeddings of user preferences.
Conclusion
Transformer architecture was a groundbreaking invention in the domain of artificial intelligence (AI). It allowed models to understand the importance of individual data points and yield amazing results. Vision transformers (ViT) use the same architecture but are built to process image data.
ViT treats image patches as individual data points. The patches are flattened and processed for sequential encoding and additional class embeddings. The transformer uses a multi-head attention module to calculate the alignment score between each patch. Comparing image patches helps us understand the importance of each segment relative to the entire image. Finally, a classification head adds non-linearity to the attention output and becomes the final output of the module.
The attention mechanism is a compute-heavy procedure, so model pretraining from scratch is difficult. However, the HuggingFace hub hosts various pre-trained ViT models, which can be fine-tuned for downstream tasks.
Further Resources
The resources below are a good starting point if you want to learn more about machine learning, Generative AI, vector databases, and other artificial intelligence technologies.
Paper: Attention Is All You Need
Paper: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Paper: An image is worth 16x16 words: Transformers for image recognition at scale
Blog: An Introduction to Vector Embeddings: What They Are and How to Use Them
Blog: Demystifying Color Histograms: A Guide to Image Processing and Analysis
Blog: OpenAI Whisper: Transforming Speech-to-Text with Advanced AI
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
- What are Transformers?
- How Do Transformers Work?
- What are Vision Transformers?
- Challenges of Vision Transformers
- The Vision Transformers (ViT) Architecture
- Implementation of Vision Transformer (ViT)
- Combining Vision Transformers (ViTs) with Vector Databases for Scalable and Efficient Image Retrieval
- Conclusion
- Further Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Cross-Entropy Loss: Unraveling its Role in Machine Learning
Cross Entropy loss is used for training classification models.

Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
LangChain tools and Milvus redefine the boundaries of what’s achievable with AI.

Decoding Transformer Models: A Study of Their Architecture and Underlying Principles
A Transformer model is a type of architecture for processing sequences, primarily used in natural language processing (NLP).