




Zilliz Cloud Serverless
High-Performance Vector Database
Made Serverless.Same features, but a fraction of the cost.
Build GenAl apps without infrastructure worries. Zilliz Cloud Serverless provides an auto-scaling vector database, with costs that increase only as your business grows.
A hassle-free vector database for GenAl
Free yourself from database setup, maintenance, and scaling concerns. Give your GenAl apps a powerful, serverless database that grows with your needs.
Up to 50x cost savings with automatic scaling
Start small, and compute resources dynamically adjust to match your app’s demands. Perfect for fluctuating workloads. Our serverless service ensures you only pay for what you use-never for idle servers.

Data portability for evolving needs
Transfer your data to Zilliz dedicated clusters or open-source Milvus as your needs change. Retain control over your data and infrastructure choices with one-click migration options.
Why is our serverless so cost-efficient?
Zilliz Cloud Serverless is 50x more cost-efficient than in-memory vector databases. It uses a tiered storage system with DRAM, SSD, and object storage to automatically optimize data placement. This approach ensures fast access for active data while reducing costs for less frequently used information, all without manual management.
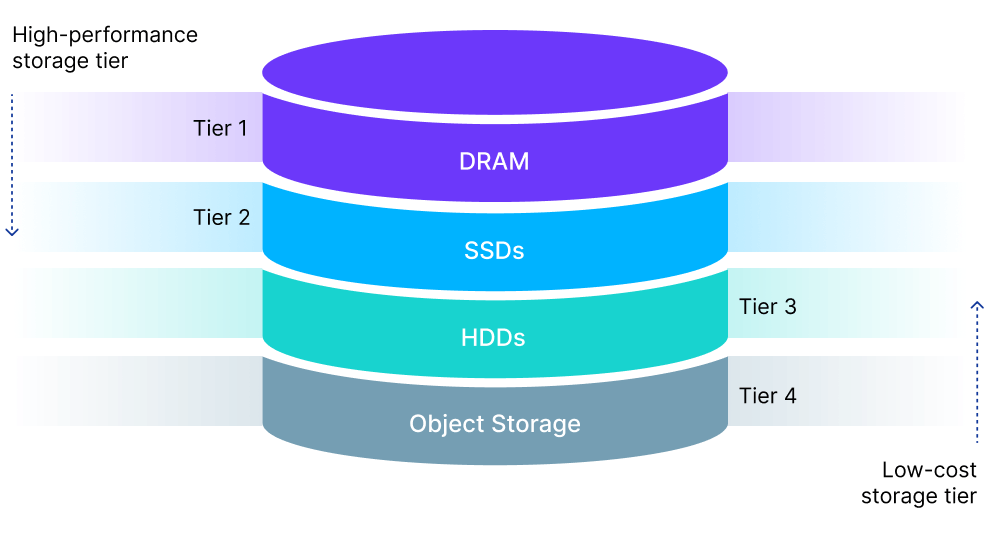
Tiered Storage
Implement tiered storage to reduce costs by storing infrequently accessed data on less expensive hardware.
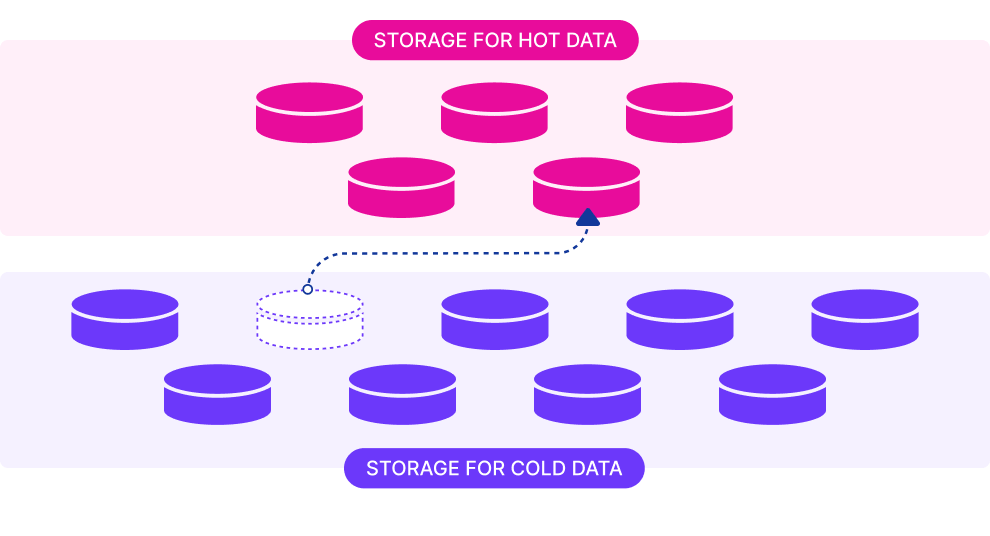
Hot Cold Data Separation
Maintain high performance by storing frequently accessed data on high-speed local disks.
Benchmarks
Recall
Dataset / Size
8.8 M
1536 dim
10 M
768 dim
138 M
1536 dim
Recall
Build faster with a comprehensive suite of vector database features

High Performance Vector Search
Store, index, and manage massive embedding vectors generated by deep neural networks and other machine learning (ML) models.

Low Latency with High Recall
Instill confidence in your data with low latency and high recall, ensuring reliable and accurate real-time decision-making.
- Learn more

Hybrid Search
Enable querying across multiple vector fields, supporting multimodal, sparse-dense, and dense-text combinations for more accurate results.
- Learn more

Various Similarity Metrics
Choose the right similarity metric (Cosine, Euclidean, IP, etc) to improve the classification and clustering performance.
- Learn more

Tunable Consistency
Gain flexibility with multiple consistency levels to align data accuracy and performance with your unique application needs.

Scale as Needed
Effortlessly scale horizontally with component-based architecture, ensuring peak performance and efficiency, regardless of workload fluctuations.