




What is BERT (Bidirectional Encoder Representations from Transformers)?
Learn what Bidirectional Encoder Representations from Transformers (BERT) is and how it uses pre-training and fine-tuning to achieve its remarkable performance.
Read the entire series
- Natural Language Processing Fundamentals: Tokens, N-Grams, and Bag-of-Words Models
- Primer on Neural Networks and Embeddings for Language Models
- Sparse and Dense Embeddings
- Sentence Transformers for Long-Form Text
- Training Your Own Text Embedding Model
- Evaluating Your Embedding Model
- Class Activation Mapping (CAM): Better Interpretability in Deep Learning Models
- CLIP Object Detection: Merging AI Vision with Language Understanding
- Discover SPLADE: Revolutionizing Sparse Data Processing
- Exploring BERTopic: A New Era of Neural Topic Modeling
- Streamlining Data: Effective Strategies for Reducing Dimensionality
- All-Mpnet-Base-V2: Enhancing Sentence Embedding with AI
- Time Series Embedding in Data Analysis
- Enhancing Information Retrieval with Learned Sparse Retrieval
- What is BERT (Bidirectional Encoder Representations from Transformers)?
- What is Mixture of Experts (MoE)?
Introduction
BERT, or Bidirectional Encoder Representations from Transformers, has dramatically reshaped the landscape of natural language processing (NLP) since its debut by Google in 2018. The release of BERT caused great excitement in the community because it represented a breakthrough, outperforming models used at the time, such as recurrent neural networks (RNNs) and convolutional neural networks (CNNs), and achieving state-of-the-art results in practically every NLP task, including disambiguation of words with multiple meanings.
BERT achieved this goal by diverging from other models in three main ways:
Bidirectionality: BERT considers what comes before and after a word in a full sentence simultaneously, unlike traditional models that process text sequentially in a single direction—left to right or right to left.
Transformer Architecture: BERT uses a transformer architecture with self-attention mechanisms to capture context and understand long sequences.
Two-Phase Training: BERT undergoes generic unsupervised pre-training on billions or trillions of unlabeled data on the internet and can be supplemented with training using small labeled task-specific (e.g., summarization, Q&A) or domain-specific (e.g., legal, academic) datasets.
The performance and accuracy achieved with BERT compared to traditional models were astonishing, opening doors and minds to a vast horizon of BERT-powered applications.
Almost a decade after its release, and despite the emergence of newer large language models (LLMs), BERT remains a reference in NLP.
Understanding BERT is essential for those interested in building the AI world. But to truly appreciate BERT's capabilities, we need to explore the details. Let’s dive in.
Background on Natural Language Processing (NLP)
Natural language processing (NLP) bridges the gap between human communication and computer understanding, encompassing everything from translation services to speech recognition to virtual assistants. Before BERT, individual NLP models were created for each specific task. However, even the models that laid the groundwork for word embedding generation or contextual predictions, like Word2Vec and GPT, struggled with the complex, nuanced nature of human language due to their unidirectional training data and limits.
BERT completely changed the task-specific paradigm by outperforming all existing models in practically all common natural language processing tasks.
What is BERT and How Does It Work?
BERT, or Bidirectional Encoder Representations from Transformers, is an advanced deep-learning model for natural language processing (NLP) tasks. It is the foundation for many popular LLMs, such as GPT-3 and LLMA.
BERT is pre-trained on a vast corpus bidirectionally, enabling it to grasp context more effectively and accurately. It uses a transformer encoder-only architecture with attention mechanisms to understand complex semantic relationships, between word tokens and sequential sentence dependencies.
BERT outperformed the state-of-the-art across tasks under general language understanding, such as natural language inference, sentiment analysis, question answering, paraphrase detection, and linguistic acceptability.
BERT Uses Bidirectional Context
BERT uses a bidirectional approach to understand context. Unlike traditional NLP models that process text sequentially and often in a single direction, BERT looks at both the left and right context of words in a sentence simultaneously. This bidirectional, semantic information processing allows BERT to differentiate between multiple meanings of the same word by considering the surrounding context more thoroughly.
For instance, consider a few examples of the word “cool.” In the sentences “This is a cool place” and “It has a cool morning breeze,” traditional models might not differentiate between the word’s different meanings—something interesting or a reference to temperature. However, BERT processes full sentences simultaneously, understanding that “cool” does not share the same meaning in these two contexts.
Here is how BERT processes text:
Tokenization: BERT tokenizes the sentence into word pieces known as tokens.
Special Tokens: It adds a special token [CLS] at the beginning of the sequence of generated tokens and a token [SEP] at the end to separate sentences and indicate the end.
Transformation into Vectors: Each token is transformed into a vector through an embedding matrix and multiple layers of encoders. These layers refine the representation of each token based on the contextual information provided by all other tokens in the sequence.
Combination of Vectors: All vectors are then combined into a unified dense representation that BERT uses to understand and predict language.
For example, a user query such as "Milvus is a vector database built for scalable similarity search" would be broken down into tokens, encoded, and processed to capture the full meaning of the query.
Ex: User query: Milvus is a vector database built for scalable similarity search.
 From words to tokens
From words to tokens
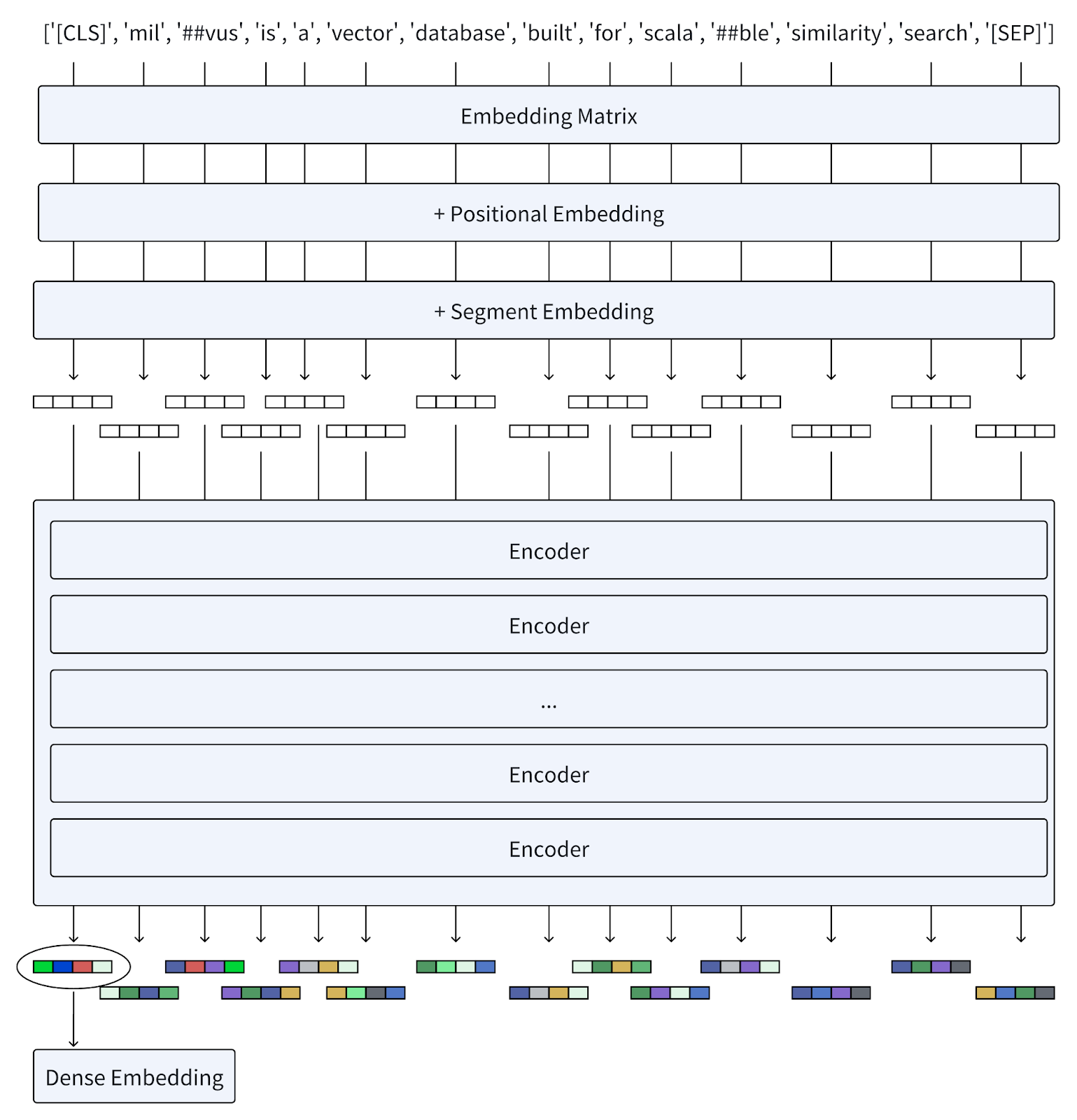 From tokens to BERT dense embeddings
From tokens to BERT dense embeddings
BERT Uses Transformer Architecture
BERT employs a transformer encoder-only architecture focusing on machine learning algorithms that understand human language input sequences. The encoder ingests vectorized inputs called embeddings. Embeddings are created for tokens (text elements, such as words), segments (like sentences), and tokens’ positions in the input. The tokenized sequence is then processed by its transformer neural network.
The Transformer architecture allows for parallel processing, making it extremely efficient. Additionally, transformers use attention mechanisms (originally proposed in the popular 2017 "Attention Is All You Need" paper) to observe relationships between words.
BERT’s Attention Mechanism
BERT’s transformer bidirectional deep learning relies on an attention mechanism that captures relationships between elements (e.g., words in a text) that allows it to interpret meaning and identify which parts of a sequence are critical for context and prediction. Just as humans tend to ignore or quickly forget details of little importance, BERT learns through differential weights that signal the importance of each word in a sentence. The most critical ones are processed by the transformer as they pass through multiple neural layers.
BERT uses a “self-attention mechanism.” Self-attention enables models to dynamically determine the relative importance of various words in a sequence, improving the ability to capture long-range dependencies. Key, value, and query inputs come from the output of the previous encoder layer.
Natural language processing models, especially transformer encoder models, use self-attention. Each position in the encoder can receive an attention score from every position in the previous encoder layer. This allows the model to weigh the importance of different words in a sentence.
Here’s how it’s done:
Each word in a sequence has three vectors associated with it in self-attention: Query (Q), Key (K), and Value (V). By taking the dot product of one word’s query and another word’s key and dividing the result by the square root of the key vector’s dimensionality, one can calculate the attention score between two words. The weighted sum is the self-attention mechanism’s output, and the scores are used to weigh the Values.
BERT Uses a Two-phase Training: Pre-training and Fine-tuning
BERT uses both pre-training and fine-tuning to achieve its remarkable performance.
Pre-training
BERT learns from a large, unlabeled dataset where it predicts randomly masked words within sentences, helping it understand language patterns and contexts without task-specific input.
Specifically, BERT was trained on a vast corpus that included Wikipedia (~2.5B words) and Google’s BooksCorpus (~800M words) using the novel Transformer architecture, which was sped up by using 64 TPUs (Tensor Processing Units) for four days.
Recognizing the computation demands, smaller BERT models were released, such as DistilBERT, which runs 60% faster while maintaining over 95% of BERT’s performance.
Fine-tuning
After pre-training, BERT is adjusted for specific natural language processing tasks by training on smaller, task-specific datasets. This process enhances accuracy for particular applications like sentiment analysis or question answering. This combined approach allows BERT to be adapted and used for various downstream natural language generation tasks with minimal modifications, making it a versatile and highly effective tool in natural language understanding and processing.
BERT Uses Two Learning methods: MLM and NSP
BERT employs two main deep and machine learning methods, namely: Masked Language Model (MLM) and Next Sentence Prediction (NSP).
Masked Language Model (MLM)
BERT randomly replaces 15% of tokenized words with a token mask and then tries to predict the correct token. For instance, in the sentence “She asked for the user [Mask] and password,” BERT’s bidirectional processing gives it a better chance of guessing the masked word correctly. This masking technique requires the model to look in both directions and use the full context of the sentence to predict the masked word.
Next Sentence Prediction (NSP)
During training, BERT ingests input pairs of sentences and learns to predict whether the second sentence is, indeed, the next one in the original text. Two sentences are processed at a time, with 50% of the second sentences in the pair being truly what comes next, while the remaining 50% are random sentences from the vectorized dataset. BERT is required to predict whether the second sentence is random or not.
BERT is trained on MLM (50%) and NSP (50%) simultaneously, enabling it to understand both the internal structure of sentences and the semantic relationships in between sentences.
Applications of BERT
BERT excels in various NLP tasks, including:
Text Classification: BERT improves accuracy in classifying whether a text expresses a positive or negative sentiment. BERT's pre-trained language representations can be fine-tuned to enhance performance in specific text classification tasks, such as spam detection, sentiment analysis, and document categorization.
Question Answering: BERT can understand questions in natural language and provide precise answers based on available texts. BERT's architecture has significantly advanced the field of question answering, enabling the model to achieve state-of-the-art results in benchmark datasets such as SQuAD (Stanford Question Answering Dataset).
Summarization: BERT can quickly analyze long documents like contracts and create accurate summaries. BERT's ability to capture the context from both directions allows it to understand the essence of a document, making it an effective tool for generating concise and coherent summaries.
Disambiguation: BERT differentiates words with multiple meanings based on bidirectional context. This feature is useful in tasks where polysemous words (words with many meanings) can lead to ambiguity. BERT's contextual understanding helps disambiguate these words more effectively than previous models.
Named Entity Recognition (NER): It extracts entities like names, organizations, and locations from text. It is used in data extraction and organization tasks. BERT's NER capabilities are widely used in automated document processing, information retrieval, and entity-based search applications.
BERT is used in a wide variety of language processing tasks, and most likely, you experience BERT daily when using Google searches, translation services, chatbots, voice assistants, or voice-operated apps. For instance, BERT's integration into Google's search engine has significantly improved the relevance and accuracy of search results, particularly for complex queries.
BERT Advantages and Limitations
BERT offers remarkable advancements in natural language processing, but it also has its challenges.
Advantages:
Enhanced Performance: BERT significantly improves performance on various natural language processing benchmarks. Its bidirectional nature and transformer architecture allow it to capture context more effectively, leading to higher accuracy in NLP tasks, from text classification to machine translation.
Versatility: It can be applied across multiple NLP tasks without needing task-specific architecture modifications. BERT's adaptability has made it a popular choice among AI-based applications, including sentiment analysis, entity recognition, and text generation. This versatility stems from its pre-trained language representations, which can be fine-tuned to suit different downstream tasks.
Limitations
Computational Resources: BERT demands high computational power and memory, which can be a barrier for real-time applications or those without access to powerful computing infrastructure. Training BERT from scratch requires significant computational resources, including multiple GPUs or TPUs, making it less accessible for smaller organizations or individual researchers.
Interpretability: BERT's complexity makes it less interpretable than simpler models, posing challenges in debugging and modifying the model. The deep learning architecture, while powerful, often acts as a "black box," making it difficult to understand the reasoning behind specific predictions or decisions made by the model.
Pre-training Requirements: BERT's effectiveness relies heavily on extensive pre-training, which requires substantial resources and time. While pre-trained models are available, fine-tuning BERT for specific tasks still requires a considerable amount of data and computational power, which may not be feasible for all use cases.
Despite these limitations, BERT's advantages often outweigh the challenges, making it a popular choice in natural language processing applications. The ongoing development of BERT variants and extensions also aims to address some of these challenges, making the model more accessible and efficient for broader use.
BERT Variants and Extensions
Several variants and extensions of BERT have been developed to address its limitations and expand its capabilities:
RoBERTa (Robustly Optimized BERT Pretraining Approach): An optimized version of BERT that adjusts key hyperparameters and removes the next-sentence prediction mechanism, improving performance on various NLP tasks. RoBERTa enhances BERT's robustness by training on more data and using longer sequences, making it more effective in capturing context.
DistilBERT: A smaller, faster, and more efficient version of BERT, suitable for environments with limited resources. DistilBERT achieves nearly the same performance as BERT while being 60% faster and using 40% fewer parameters, making it ideal for applications with critical speed and efficiency.
ALBERT (A Lite BERT): A light version of BERT that reduces model size without significantly impacting effectiveness, addressing the resource demands of BERT. ALBERT achieves this reduction by sharing parameters across layers and factorizing the embedding matrix, making it a more resource-efficient alternative while maintaining high accuracy.
ColBERT (Contextualized Late Interaction over BERT): A refined extension of BERT that focuses on efficient retrieval in large text collections. ColBERT is designed for document retrieval and ranking tasks. It balances the need for deep contextual understanding with computational efficiency.
BGE-M3 (BERT-based Generative Encoder Multilingual Model): An advanced machine-learning model that extends BERT's capabilities, particularly in multilingual tasks. BGE-M3 leverages BERT's architecture to improve performance across different languages, making it a valuable tool for global applications.
Splade (Sparse Lexical and Dense Retrieval): An evolution in generating learned sparse embeddings, building upon the foundational BERT architecture with a unique methodology to refine embedding sparsity. Splade combines the strengths of sparse and dense retrieval methods, providing a more efficient and effective approach to information retrieval tasks.
These variants and extensions showcase BERT's adaptability and ongoing relevance in the evolving field of statistical natural language processing using. They represent efforts to overcome the challenges posed by the original BERT model, making it more accessible, efficient, and effective for a broader range of applications.
Conclusion
BERT represents a significant breakthrough in natural language processing technology by using artificial intelligence and enabling a more nuanced and effective machine understanding of human language. From voice-operated applications and chatbots to services like speech-to-text captioning and translation apps, BERT’s impact is evident across various market segments and sectors of modern society.
One of BERT's key strengths is its open-source nature. Unlike other large language models like GPT-3, BERT’s code is freely available on GitHub, allowing developers and researchers to customize it for their unique tasks. This openness has fostered a vibrant community of contributors and led to the development of numerous BERT variants and extensions that address specific challenges and enhance the model's capabilities.
Furthermore, pre-trained BERT models are available for specific use cases, enabling users to leverage BERT's advanced capabilities without needing extensive computational resources. This accessibility has made BERT a foundational tool in natural language processing, with applications that continue to expand as the field evolves.
BERT is not just a tool but a paradigm shift in how machines understand human language. Its influence will continue to be felt as new models and technologies build upon the foundation that it has established.
If you wish to learn more or begin your computer vision project, for instance, welcome to join our Discord channel. We provide a wealth of resources and a supportive community to assist you in getting started.
Further Resources about GenAI, ML and Vector Databases

- Introduction
- Background on Natural Language Processing (NLP)
- What is BERT and How Does It Work?
- Applications of BERT
- BERT Advantages and Limitations
- BERT Variants and Extensions
- Conclusion
- Further Resources about GenAI, ML and Vector Databases
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Natural Language Processing Fundamentals: Tokens, N-Grams, and Bag-of-Words Models
This post covers Natural Language Processing fundamentals that are essential to understanding all of today’s language models.

Primer on Neural Networks and Embeddings for Language Models
Exploring neural network language models, specifically recurrent neural networks, and taking a sneak peek at how embeddings are generated.

Sentence Transformers for Long-Form Text
Deep diving into modern transformer-based embeddings for long-form text.