




Vector Database vs Graph Database
Learn which specialized database technology best suits your data management needs of your use cases and performance attributes.
Read the entire series
- Cross-Entropy Loss: Unraveling its Role in Machine Learning
- Batch vs. Layer Normalization - Unlocking Efficiency in Neural Networks
- Empowering AI and Machine Learning with Vector Databases
- Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
- Vector Databases: Redefining the Future of Search Technology
- Local Sensitivity Hashing (L.S.H.): A Comprehensive Guide
- Optimizing AI: A Guide to Stable Diffusion and Efficient Caching Strategies
- Nemo Guardrails: Elevating AI Safety and Reliability
- Data Modeling Techniques Optimized for Vector Databases
- Demystifying Color Histograms: A Guide to Image Processing and Analysis
- Exploring BGE-M3: The Future of Information Retrieval with Milvus
- Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
- TF-IDF - Understanding Term Frequency-Inverse Document Frequency in NLP
- Understanding Regularization in Neural Networks
- A Beginner's Guide to Understanding Vision Transformers (ViT)
- Understanding DETR: End-to-end Object Detection with Transformers
- Vector Database vs Graph Database
- What is Computer Vision?
- Deep Residual Learning for Image Recognition
- Decoding Transformer Models: A Study of Their Architecture and Underlying Principles
- What is Object Detection? A Comprehensive Guide
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Algorithmic)
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Methodological)
- Understanding CoCa: Advancing Image-Text Foundation Models with Contrastive Captioners
- Florence: An Advanced Foundation Model for Computer Vision by Microsoft
- The Potential Transformer Replacement: Mamba
- ALIGN Explained: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
The ability to efficiently manage, store, and analyze vast amounts of information has become crucial in this data-driven world. As data complexity and volume grow, traditional database systems are often challenged to meet modern requirements. This has led to the emergence of specialized database technologies, each designed to excel in specific scenarios and data types.
Two such database technologies that have gained attention in recent years are vector databases and graph databases. While both offer powerful capabilities for handling complex data structures, they serve distinct purposes and excel in different use cases.
This article will comprehensively compare vector and graph databases, helping you understand their fundamental differences, strengths, and ideal applications. By exploring their unique characteristics, querying mechanisms, and performance attributes, you'll have the knowledge to make informed decisions about which database technology best suits your specific needs. Let’s start by looking at vector databases.
What is a Vector Database?
A vector database is a specialized database system designed to store, manage, and query high-dimensional vector data efficiently. These databases represent data points as mathematical vectors in a multi-dimensional space. Each dimension corresponds to a specific feature or attribute of the data. Take a look at the image below. It illustrates how vector databases represent different objects in a high-dimensional space.
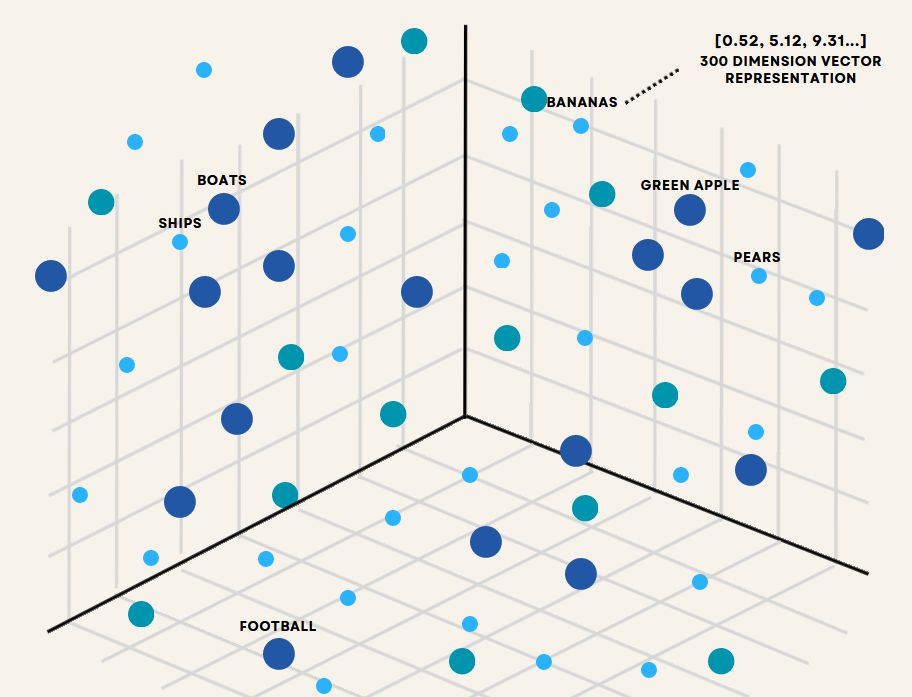 Fig 1- Data representation in a vector database
Fig 1- Data representation in a vector database
In the illustration, each item is encoded as a vector of numbers - in this case, a 300 DIMENSION VECTOR REPRESENTATION as noted in the top right corner. The positioning of the points reflects semantic relationships, with similar concepts clustered together (notice how BOATS and SHIPS are near each other). This spatial arrangement allows for quick and accurate similarity comparisons between data points based on their relative positions in the vector space. Making them ideal for applications involving machine learning, artificial intelligence, and complex data analysis.
Key Characteristics
High-dimensional data support: Vector databases can efficiently handle data with hundreds or thousands of dimensions.
Efficient Similarity search: They excel at finding the most similar items to a given query vector quickly.
Approximate Nearest Neighbor (ANN) algorithms: These databases often use ANN algorithms to balance search speed and accuracy.
Indexing structures: Specialized indexing methods like HNSW (Hierarchical Navigable Small World) or IVF (Inverted File) are used to optimize search performance.
HNSW Vector Index | Vector Database Fundamentals
- Scalability: Vector databases are designed to handle large-scale datasets and high query volumes.
Common Use Cases
Since you know what vector databases are and their characteristics, let's look at how they are applied in various real-world scenarios.
Recommendation Systems: Vector databases excel in suggesting products, content, or services based on user preferences and behavior. For instance, a streaming service might encode user viewing history and content features into vectors. When a user finishes a show, the system can swiftly query the vector database to find similar content, offering personalized recommendations that keep the viewer engaged.
Image and Video Search: The ability to find visually similar images or video frames is another strength of vector databases. This is done via reverse image search. For instance, a social media platform like Pinterest implements a visual search feature where users upload an image or select part of one. The platform converts this input into a vector and searches its database for visually similar content. This enables users to discover related images, products, or ideas based on visual input rather than relying solely on text descriptions.
Natural Language Processing (NLP): In NLP, vector databases facilitate semantic search, text classification, and language translation. A modern search engine converts both user queries and web content into vector embeddings allowing the engine to match the semantic meaning rather than just keywords.
Anomaly Detection: Vector databases identify unusual patterns for fraud detection or system monitoring. In the financial sector, a bank might encode transaction details - such as amount, location, time, and merchant type - into vectors. The system can then rapidly compare new transactions against historical patterns stored in the vector database. Transactions that deviate significantly from typical user behavior are flagged for review.
There are numerous vector databases out there but they differ in reliability. The most popular vector database in terms of Github stars is Milvus which also has a fully managed cloud version. Other vector databases are Chroma, Vald, etc.
Having understood vector databases, let us now shift gears and look at graph databases.
What is a Graph Database?
A graph database is a specialized database system designed to store, manage, and query data using graph structures. These databases represent data as nodes (entities) and edges (relationships between entities), allowing for efficient traversal and analysis of complex interconnected data. Take a look at the image below. It illustrates how graph databases represent relationships between different entities.
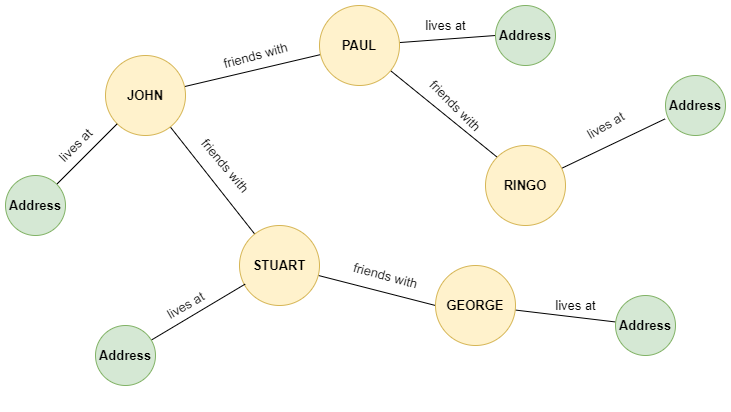 Fig 2- Data representation in a graph database
Fig 2- Data representation in a graph database
In the above illustration, there is a network of interconnected nodes representing people and addresses. The peach nodes represent individuals, while the silver nodes represent addresses. The lines connecting these nodes show relationships, with labels like “friends with” between people and “lives at” connecting people to their addresses. This structure allows for intuitive modeling of real-world relationships and enables powerful querying capabilities based on these connections. For example, you can easily trace John's network of friends or find out where George lives by following the relevant edges in the graph.
Key Characteristics
Relationship-first approach: Graph databases prioritize the connections between data points, making them ideal for highly interconnected data.
Flexible schema: They can easily adapt to changing data structures without requiring a predefined schema.
Efficient traversal: Graph databases excel at navigating complex relationships quickly, even across multiple degrees of separation.
Native graph processing: They use specialized algorithms optimized for graph operations, such as shortest path calculations and centrality measures.
ACID compliance: Many graph databases support ACID (Atomicity, Consistency, Isolation, Durability) properties for data integrity.
Common Use Cases
Having understood what graph databases are and their characteristics, let's explore how they are applied in various real-world scenarios.
Social Network Analysis: Graph databases are ideal for modeling and analyzing social connections. For instance, a social media platform might use a graph database to store user profiles as nodes and friendships as edges. This structure allows for efficient friend recommendations, influence analysis, and community detection within the network.
Fraud Detection: In the financial sector, graph databases can uncover complex fraud patterns. By representing transactions, accounts, and individuals as interconnected nodes, suspicious activities that might go unnoticed in traditional systems become apparent. For example, a bank could use a graph database to identify circular money flows or unusual patterns of connections that might indicate money laundering.
Knowledge Graphs: Companies like Google use graph databases to power their knowledge graphs, which represent real-world entities and their relationships. This enables more intelligent search results and powers features like Google's information boxes, providing users with contextual information about people, places, and things.
Supply Chain Management: Graph databases model complex supply networks, tracking the flow of goods from manufacturers to end consumers. This allows companies to optimize routes, identify bottlenecks, and perform what-if analyses to improve efficiency and resilience in their supply chains.
There are several popular graph databases available, each with its own strengths. They include; Neo4j, Amazon Neptune, JanusGraph, OrientDB, WhyHow, etc.
By now, you are familiar with the fact that vector and graph databases store data differently. But this is not the only difference that exists between the two.
Key Differences Between Vector and Graph Databases
Understanding the fundamental differences between vector and graph databases is crucial for selecting the right technology for your specific data needs. Let's compare them across various dimensions:
Data Structure and Storage
Data representation and storage form the foundation of any database technology. In vector databases, data points are represented as high-dimensional vectors, each capturing multiple attributes of the data.
Vector Database:
Data Representation: Vector databases represent data as high-dimensional vectors. Each vector consists of multiple dimensions corresponding to various attributes of the data. For example, a vector might encode an image's features, where each dimension represents a specific characteristic like color or texture.
Storage: These databases store vectors in specialized data structures optimized for high-dimensional data, such as inverted files or hierarchical navigable small world (HNSW) graphs.
Access: Data retrieval in vector databases is based on similarity search. Given a query vector, the database quickly finds and returns vectors that are closest to it in the vector space, often using Approximate Nearest Neighbor (ANN) algorithms to balance speed and accuracy.
In contrast, graph databases represent data as nodes and edges, making them ideal for modeling interconnected entities and their relationships.
Graph Database:
Data Representation: Graph databases represent data as nodes and edges. Nodes correspond to entities, while edges represent relationships between entities. This model is particularly intuitive for data with complex interconnections, such as social networks or transportation maps.
Storage: Data is stored in graph structures, with nodes and edges often indexed for efficient traversal and query processing. Many graph databases use adjacency lists or matrix representations to manage relationships.
Access: Querying in graph databases focuses on traversing the graph. Queries involve finding paths, subgraphs, or connected components, leveraging the rich relationship data stored within the graph.
Querying and Retrieval
With data structured and stored, the next critical aspect is how efficiently we can query and retrieve this data. Vector databases excel in similarity searches, crucial for applications like recommendation systems.
Vector Database:
Types of Queries: Vector databases are optimized for similarity searches, such as finding the nearest neighbors to a query vector. These queries are crucial in applications like anomaly detection.
Indexing Mechanisms: Vector databases use specialized indexing methods like HNSW and inverted files to expedite similarity searches. These indexing techniques allow for efficient retrieval of high-dimensional data, balancing speed and accuracy.
On the other hand, graph databases shine in relationship-based queries, such as shortest-path calculations.
Graph Database:
Types of Queries: Graph databases excel at queries involving relationships and paths, such as shortest path calculations, pattern matching, and network analysis. These queries are essential for applications like social network analysis and fraud detection.
Indexing Mechanisms: Graph databases use various indexing mechanisms, including adjacency lists, hash maps, and B-trees, to optimize traversal and query performance. These indexes enable efficient navigation of complex relationships and large graph structures.
Performance and Scalability
Performance and scalability determine how well a database can handle large-scale data and high query loads. Vector databases employ techniques like Approximate Nearest Neighbor (ANN) algorithms to ensure quick and accurate similarity searches even with extensive datasets.
Vector Database:
Handling Large-Scale Data: Vector databases are designed to manage large-scale datasets, often containing millions or billions of high-dimensional vectors. They employ efficient indexing and partitioning strategies to maintain performance under high query loads.
Performance Benchmarks: Vector databases typically achieve high performance for similarity searches, even with extensive datasets. They leverage ANN algorithms and distributed computing techniques to deliver fast query responses.
Graph databases, meanwhile, are optimized for handling vast interconnected data, maintaining performance through advanced indexing and traversal algorithms.
Graph Database:
Handling Large-Scale Data: Graph databases are adept at managing vast, interconnected datasets. They use advanced indexing and partitioning methods to ensure efficient query processing, even with extensive graphs.
Performance Benchmarks: Graph databases excel at complex queries involving multiple hops or traversals. They are optimized for performance in scenarios where relationships and connections are paramount, maintaining responsiveness under heavy query loads.
Flexibility and Adaptability
Flexibility and adaptability to evolving data models are crucial for modern applications. Vector databases offer straightforward schema changes, making it easy to add or modify data dimensions.
Vector Database:
Schema Changes: Vector databases are flexible regarding schema changes. Since data is represented as vectors, adding or modifying dimensions is straightforward, allowing the database to adapt to new data types and features.
Support for Different Data Types: While primarily focused on high-dimensional numerical data, vector databases can be adapted to various applications by encoding different data types into vector representations.
Graph databases excel in schema flexibility, allowing dynamic additions of nodes and relationships without predefined schemas, which is particularly beneficial for applications with rapidly changing data structures.
Graph Database:
Schema Changes: Graph databases are highly flexible, accommodating evolving data structures without requiring predefined schemas. New nodes and relationships can be added dynamically, making them ideal for applications with changing data models.
Support for Different Data Types: Graph databases support diverse data types, including structured, semi-structured, and unstructured data. Their flexible schema and rich relationship modeling capabilities allow them to adapt to various data requirements.
With these differences, you might think that vector and graph databases do not have mixed use cases. But this is not the case. Let's take a look at some use cases in which combining the two can yield the best results.
Vector and Graph Databases Mixed Use Cases
Having explored the distinct strengths of vector and graph databases, let's now look at scenarios where combining these technologies can yield powerful solutions
Hybrid Search Engines: Integrating vector databases for semantic search with graph databases for relationship-based queries enhances search capabilities, providing more relevant and contextually aware results.
Advanced Recommendation Systems: Using vector databases to model user preferences and graph databases to capture social connections improves recommendation accuracy and user engagement.
Multimodal Applications: Leveraging vector databases for handling high-dimensional data like images and text, combined with graph databases for managing relationships, creates robust multimodal systems.
With all the knowledge of vector and graph databases, the big issue becomes knowing when to use either the vector database, graph database, or both.
Choosing the Right Database for Your Needs
Choosing the right database is essential for optimizing data management and performance. Let's summarize the key factors to consider in making this decision.
Data Type: Determine whether your data is primarily high-dimensional vectors or interconnected entities.
Query Requirements: Identify the types of queries you need to perform, such as similarity searches or relationship traversals.
Scalability Needs: Assess your scalability requirements, including data volume and query load.
Flexibility: Consider how often your data model changes and the need for schema flexibility.
Decision-Making Framework:
Assess Data Characteristics: Evaluate whether your data is best represented as vectors or graphs.
Analyze Query Patterns: Determine the predominant query types and choose the database that excels in those queries.
Evaluate Performance Needs: Consider the performance benchmarks of each database for your specific use cases.
Consider Future Growth: Plan for scalability and adaptability to accommodate future data and query growth.
Example Decision Scenarios:
Scenario 1: A company needs to build a recommendation system for a streaming service. Given the importance of similarity searches and personalized recommendations, a vector database would be the ideal choice.
Scenario 2: A social media platform wants to analyze user connections and recommend friends. A graph database would be the best fit due to its strengths in modeling and traversing social networks.
Scenario 3: An e-commerce platform aims to improve product search by combining text, images, and user behavior. A hybrid approach using both vector and graph databases could provide the most comprehensive solution.
Conclusion
Vector databases excel in handling high-dimensional data and performing similarity searches, making them ideal for applications like recommendation systems and NLP. Graph databases, on the other hand, are designed for interconnected data, excelling in queries involving relationships and paths, making them perfect for social network analysis and fraud detection.
When choosing between vector and graph databases, it's essential to consider your data type, query requirements, scalability needs, and flexibility. By understanding the unique strengths of each database technology and evaluating your specific use cases, you can make informed decisions that best meet your data management needs.
Further Resources
 Denis Kuria
Denis KuriaDenis is a machine learning engineer who enjoys writing guides to help other developers. He has a bachelor's in computer science and loves hiking and exploring the world.
- What is a Vector Database?
- What is a Graph Database?
- Key Differences Between Vector and Graph Databases
- Vector and Graph Databases Mixed Use Cases
- Choosing the Right Database for Your Needs
- Conclusion
- Further Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
LangChain tools and Milvus redefine the boundaries of what’s achievable with AI.

Nemo Guardrails: Elevating AI Safety and Reliability
In this article, we will provide an in-depth explanation of what Nemo Guardrails are, its practical applications, along with its integration.

Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
We can easily implement the BM25 algorithm to turn a document and a query into a sparse vector with Milvus. Then, these sparse vectors can be used for vector search to find the most relevant documents according to a specific query.