




Retrieval Augmented Generation (RAG)
LLM Limitations
Lacking domain-specific information
LLMs are trained solely on data that is publicly available. Thus, they may lack knowledge of domain-specific, proprietary, or private information that is not accessible to the public.
Prone to hallucination
LLMs can only give answers based on the information they have. They may provide incorrect or fabricated information if they don't have enough data to reference.
Costly and slow
LLMs charge for every token in queries, resulting in high costs, particularly for repetitive questions. In addition, response delays during peak times also frustrate users seeking quick answers.
Failure to access up-to-date information
LLMs are often trained on outdated data and don't update their knowledge base regularly due to high training costs. For instance, training GPT-3 can cost up to 1.4 million dollars.
Token Limit
LLMs set a limit on the number of tokens that can be added to query prompts. For example, ChatGPT-3 has a limit of 4,096 tokens, while GPT-4 (8K) has a token limit of 8,192.
Immutable pre-training data
LLMs' pre-training data may contain outdated or incorrect information. Unfortunately, such data cannot be modified, corrected, or removed.
How Zilliz Cloud Augments LLM Applications
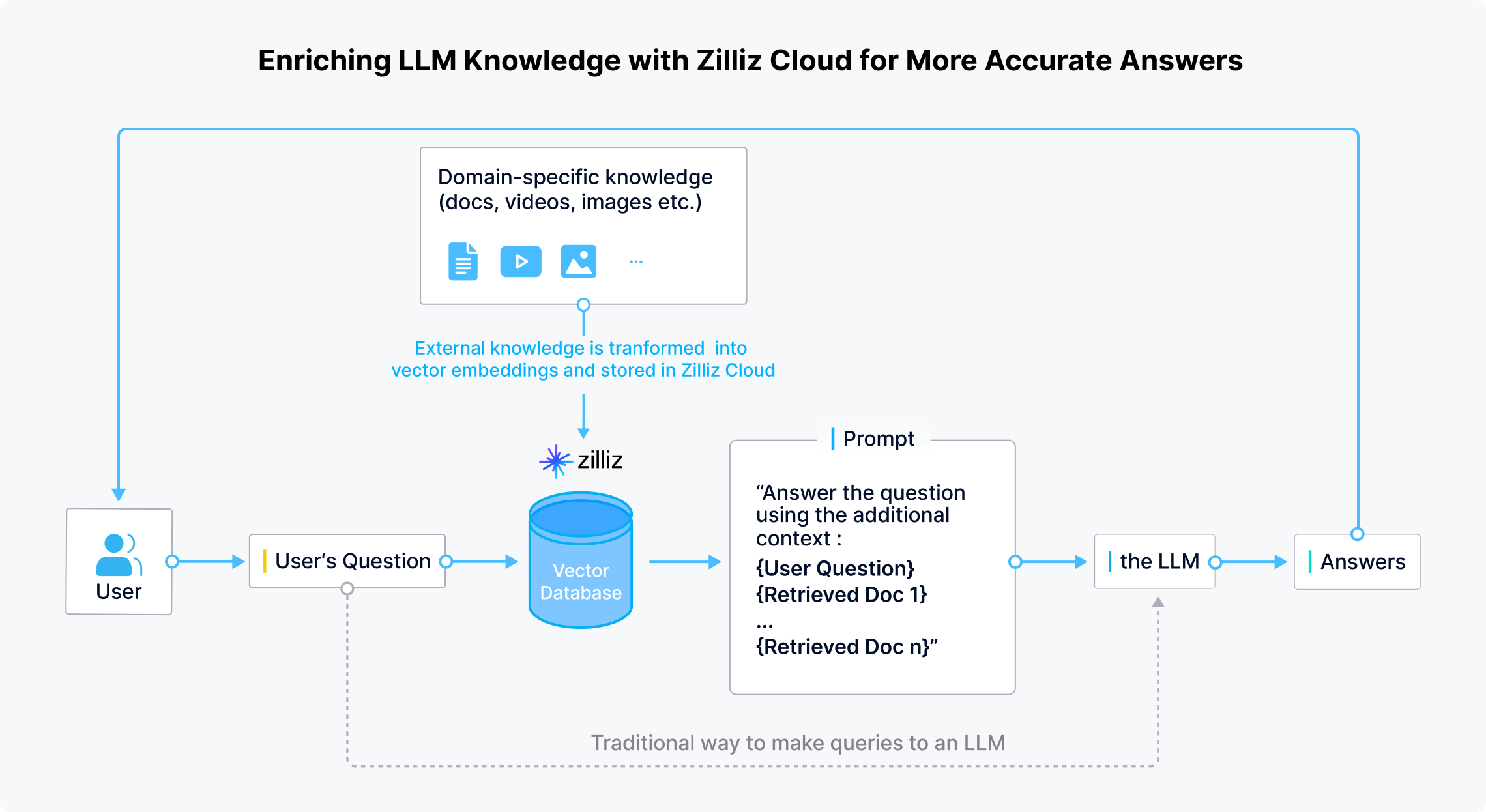
RAG for LLMs: Updating and expanding LLMs’ knowledge base for more accurate answers
Zilliz Cloud allows developers and enterprises to securely store domain-specific, up-to-date, and confidential private data outside LLMs. When a user asks a question, LLM applications use embedding models to transform the question into vectors. Zilliz Cloud then conducts similarity searches to provide the Top-K results relevant to that question. Finally, these results are combined with the original question to create a prompt that provides a comprehensive context for the LLM to generate more accurate answers.
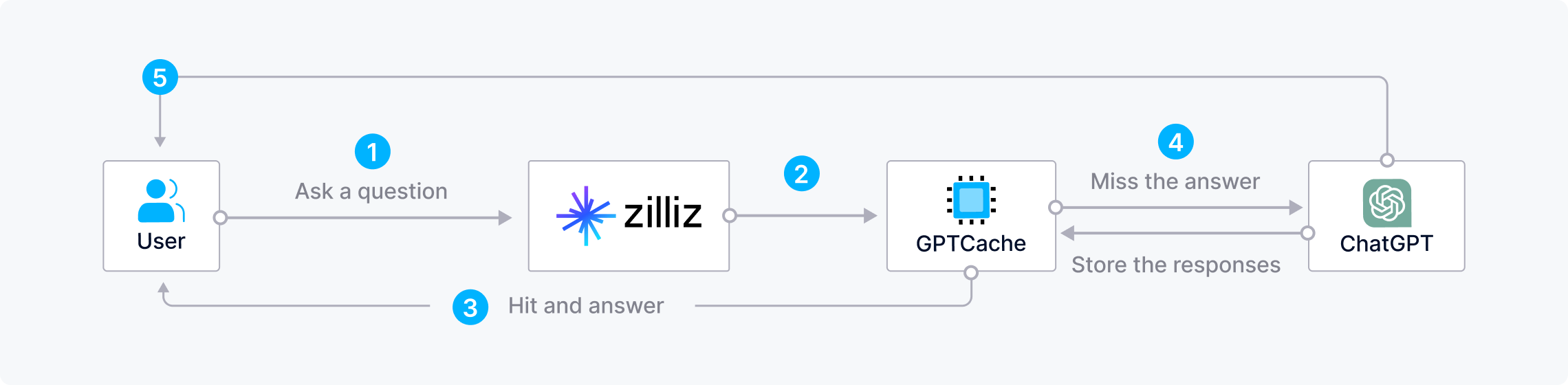
Saving time and costs when combining Zilliz Cloud with GPTCache
Frequently asking LLMs repetitive or similar questions can be costly, resource-wasting, and time-consuming, especially during peak times when responses are slow. To save time and money when building AI applications, developers can utilize Zilliz Cloud with GPTCache, an open-source semantic cache that stores LLM responses.With this architecture, Zilliz first checks GPTCache for answers when a user asks a question. If it finds an answer, Zilliz Cloud quickly returns the answer to the user. Otherwise, Zilliz Cloud sends the query to the LLM for an answer and stores it in GPTCache for future use.
The CVP Stack
ChatGPT/LLMs + a vector database + prompt-as-code
The CVP stack (ChatGPT/LLMs + a vector database + prompt-as-code) is an increasingly popular AI stack that shows the value of vector databases for LLM enhancement. We can use OSS Chat as an example to demonstrate how the CVP stack works.
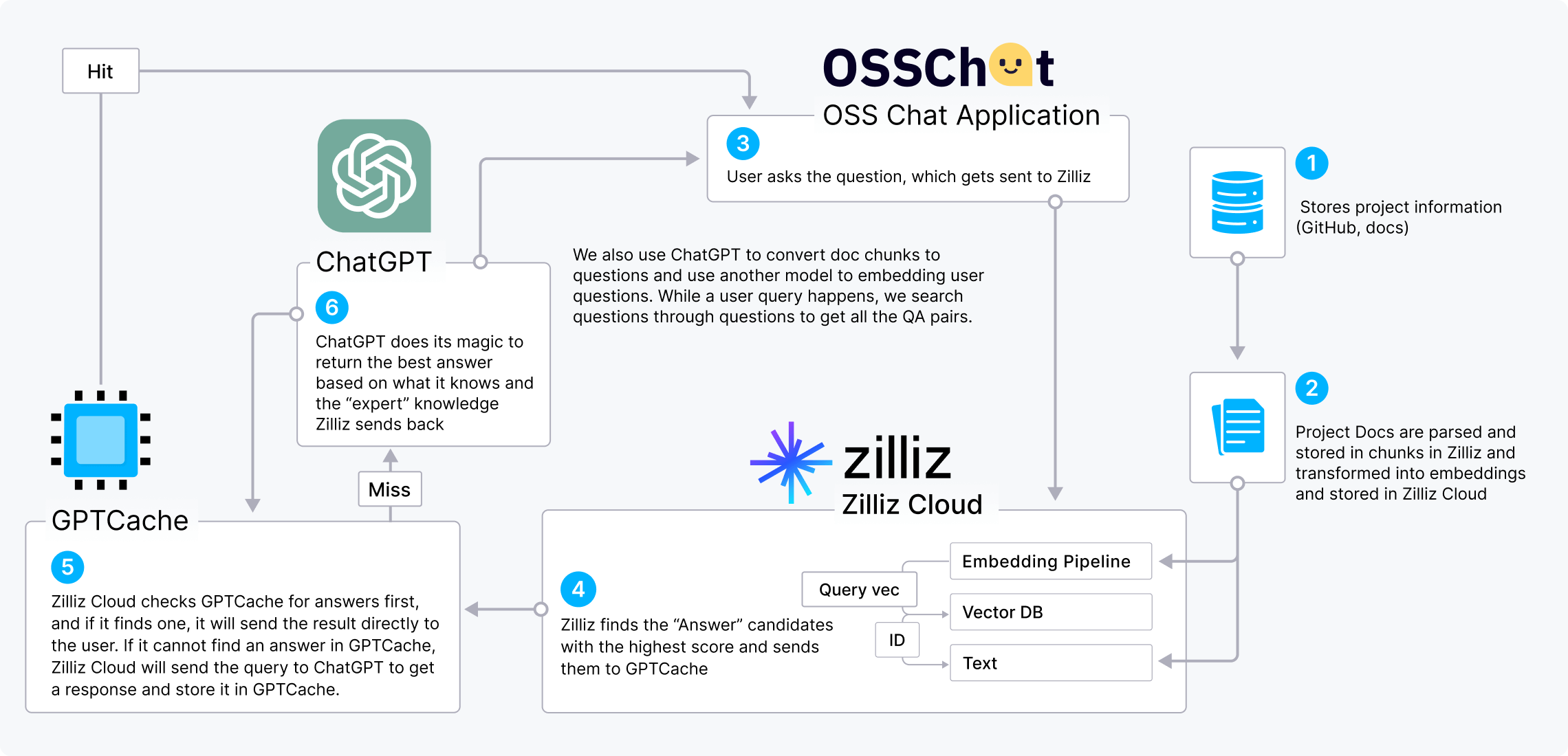
OSS Chat is a chatbot that can answer questions about GitHub projects. It collects and stores information from various GitHub repositories and their documentation pages in Zilliz Cloud in the form of embeddings. When a user asks OSS Chat about any open-source project, Zilliz Cloud conducts a similarity search to find the topk most relevant outcomes. Then these results are combined with the original question to create a prompt that gives ChatGPT a broader context, resulting in more accurate answers.
We can also incorporate the GPTCache into the CVP stack to reduce costs and speed up responses.
LLM Projects Utilizing Milvus & Zilliz Cloud
Learn how developers utilize Milvus & Zilliz Cloud to empower their generative AI applications.
- OSS Chat
- PaperGPT
- NoticeAI
- Search.anything.io
- IkuStudies
- AssistLink AI
Milvus Integrations with Popular AI Projects
OpenAI, LangChain, LlamaIndex, and many other AI pioneers are integrating with Zilliz Cloud to amplify their retrieval capabilities.



