




Milvus on GPUs with NVIDIA RAPIDS cuVS
Introduction
Performance in production is a critical factor in the success of our AI application. The quicker we can return results to the user, the better. This urgency drives the need for optimization.
Let's consider a real-world example—a Retrieval Augmented Generation (RAG) application. In a RAG system, vector search is the engine that powers the user's experience, providing relevant results based on their queries. However, we're all too aware that vector search is a resource-intensive task. The more data we store, the more expensive and time-consuming the computation becomes.
A solution needs to be found to optimize the performance of our AI applications in such cases. In a recent talk at the Unstructured Data Meetup hosted by Zilliz, Corey Nolet, Principal Engineer at NVIDIA, discussed NVIDIA's latest advancements to address this problem, which we'll explore in this article. You can also check Corey’s talk on YouTube.
Specifically, we'll focus on cuVS, a library developed by NVIDIA that contains several algorithms related to vector search and leverages the acceleration power of GPUs. We'll see how this library can improve the performance of vector search operations and optimize overall operational costs. So, without further ado, let's dive in!
Vector Search and The Role of Vector Database in It
Vector search is an information retrieval method where both the user's query and the documents being searched are represented as vectors. To perform a vector search, we need to transform our query and documents (which can be images, texts, etc.) into vectors.
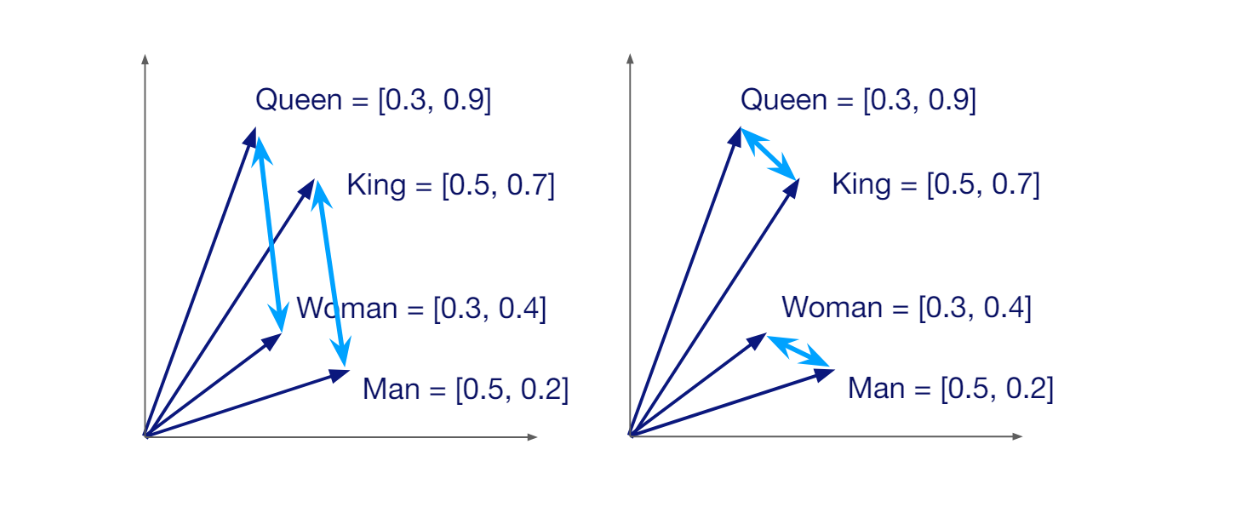
A vector has a specific dimension, which depends on the method used to generate it. For example, if we use a HuggingFace model called all-MiniLM-L6-v2 to transform our query into a vector, we'll get a vector with a dimension of 384. Vectors carry the semantic meaning of the data or documents they represent. Therefore, if two pieces of data are similar to each other, their corresponding vectors are positioned close to each other in the vector space.
 Semantic similarity between vectors in a vector space..png
Semantic similarity between vectors in a vector space..png
Semantic similarity between vectors in a vector space.
The fact that each vector carries the semantic meaning of the data it represents allows us to calculate the similarity between any random pair of vectors. If they're similar, the similarity score will be high, and vice versa. The main purpose of vector search is to find the vectors most similar to our query's vector.
Vector search implementation is relatively straightforward when dealing with a few documents. However, the complexity grows as we have more documents and need to store more vectors. The more vectors we have, the longer it takes to perform a vector search. Additionally, the operational cost increases significantly as we store more vectors in local memory. Thus, we need a scalable solution, which is where vector databases come into play.
Vector databases offer an efficient, fast, and scalable solution for storing a huge collection of vectors. They provide advanced indexing methods for faster retrieval during vector search operations, as well as easy integration with popular AI frameworks to simplify the development process of our AI applications. In vector databases such as Milvus and Zilliz Cloud (the managed Milvus), we can also store the metadata of the vectors and perform advanced filtering processes during search operations.
 Complete workflow of a vector search operation..png
Complete workflow of a vector search operation..png
Complete workflow of a vector search operation.
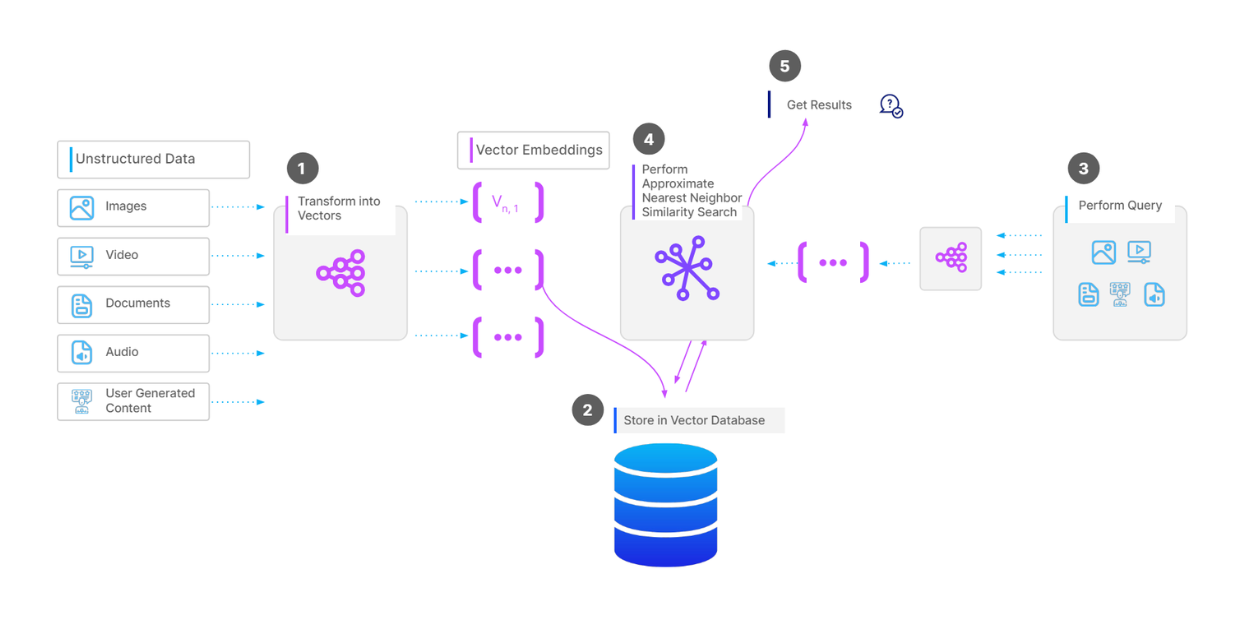
To store a collection of vectors in a vector database like Milvus, the first step is to perform data preprocessing, depending on our data type. For example, if our data is a collection of documents, we can split the text in each document into chunks. Next, we transform each chunk into a vector using an embedding model of our choice. Then, we ingest all the vectors into our vector database and build an index on them for faster retrieval during vector search operations.
When we have a query and want to perform a vector search operation, we transform the query into a vector using the same embedding model used previously, and then calculate its similarity with vectors in the database. Finally, the most similar vectors are returned to us.
Vector Search Operation on CPU
Vector search operations require intensive computation, and the computation cost increases as we store more vectors inside a vector database. Several factors directly affect the computation cost, such as index building, the total number of vectors, vector dimensionality, and the desired search result quality.
CPUs are the common go-to processing units for vector search operations due to their cost-effectiveness and easy integration with other components in AI applications. Many vector search algorithms are fully optimized for CPUs, with Hierarchical Navigable Small World (HNSW) being the most popular one.
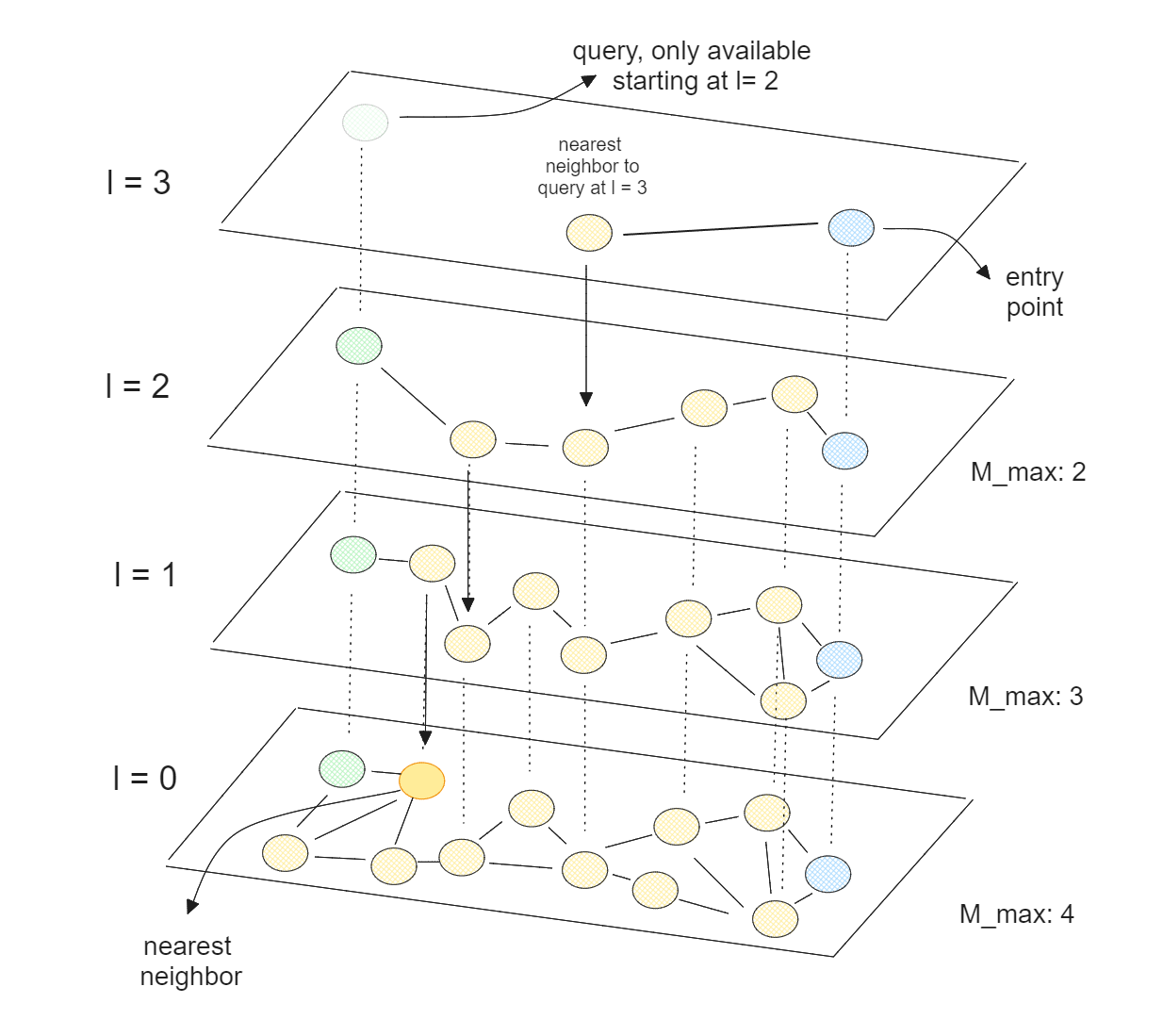
At its core, HNSW combines the concepts of skip lists and Navigable Small World (NSW). In an NSW algorithm, the graph is built by first randomly shuffling our data points. Next, data points are inserted one by one, with each point connected through a predefined number of edges to its nearest neighbors.
 Vector search using HNSW..png
Vector search using HNSW..png
Vector search using HNSW.
HNSW is a multi-layered NSW, where the lowest layer contains all data points, and the highest layer contains only a small subset of our data points. This means that the higher the layer, the more data points we skip, which corresponds to the theory of skip lists.
With HNSW, we have a graph where most nodes can be reached from any other node through a small number of iterations. This property allows HNSW to efficiently navigate through the graph quickly to find approximate nearest neighbors. Since HNSW is optimized for CPUs, we can also parallelize its execution across multiple CPU cores to further accelerate the vector search process.
However, the computation time of HNSW still suffers as we store more data inside the vector database. It can become even worse if the dimensionality of our vectors is very high. Therefore, we need another solution for cases where we have a huge number of vectors with high dimensionality.
Vector Search Operation on GPU
One solution to enhance vector search performance when dealing with a huge number of high-dimensional vectors is to operate on a GPU. To facilitate this, we can utilize NVIDIA's RAPIDS cuVS, a library containing several GPU-optimized vector search implementations. It simplifies the use of GPUs for both vector search operations and index building.
cuVS offers several nearest neighbor algorithms to choose from, including:
Brute-force: An exhaustive nearest neighbors search where the query is compared to each vector in the database.
IVF-Flat: An approximate nearest neighbor (ANN) algorithm that divides the vectors in the database into several non-intersecting partitions. The query is then compared only with vectors in the same (and optionally neighboring) partitions.
IVF-PQ: A quantized version of IVF-Flat that reduces the memory footprint of stored vectors in the database.
CAGRA: A GPU-native algorithm similar to HNSW.
 CAGRA graph construction. .png
CAGRA graph construction. .png
CAGRA graph construction. Source.
Among these nearest neighbor algorithms, we'll focus on CAGRA.
CAGRA is a graph-based algorithm introduced by NVIDIA for fast and efficient approximate nearest neighbor search, leveraging the parallel processing power of GPUs.
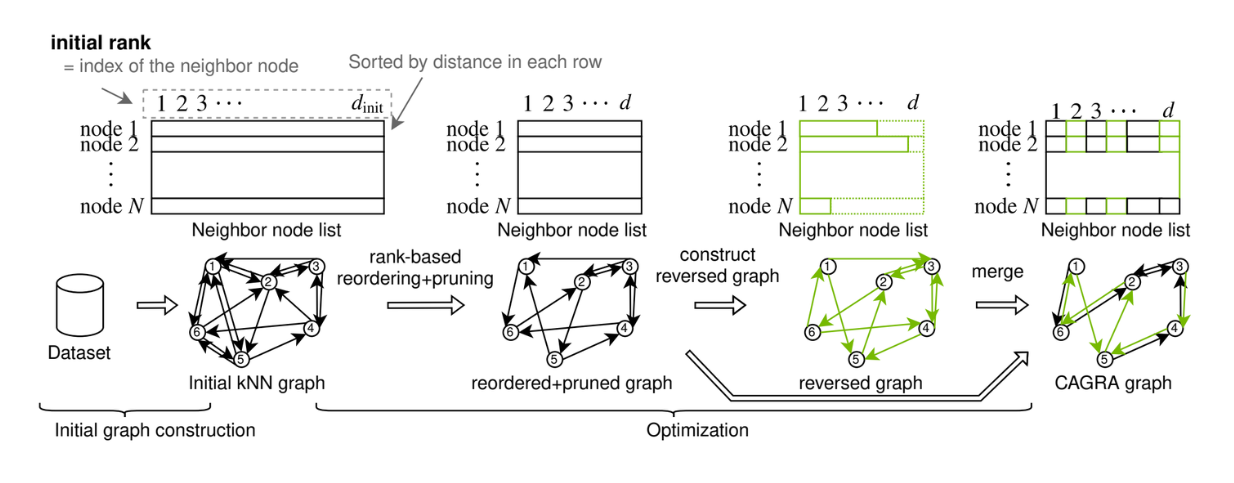
The graph in CAGRA can be built using either the IVF-PQ method or the NN-DESCENT method:
IVF-PQ Method: Utilizes an index to create a memory-efficient initial graph by connecting each point to many neighbors.
NN-DESCENT Method: Uses an iterative process to build a graph by expanding and refining connections between points.
Compared to HNSW, CAGRA's graph construction methods are easier to parallelize and contain less data interaction between tasks, which significantly improves the graph or index building time. If you’d like to learn more in detail about CAGRA, check out its official paper or the CAGRA article.
CAGRA has set a state-of-the-art performance in vector search operations. To demonstrate this, we'll compare its performance with HNSW in the next section.
CAGRA and HNSW Performance Comparison
There are two critical operations in vector search where performance is crucial: index building and the search itself. We'll compare the performance of CAGRA and HNSW in these two operations.
Let's start with index building.
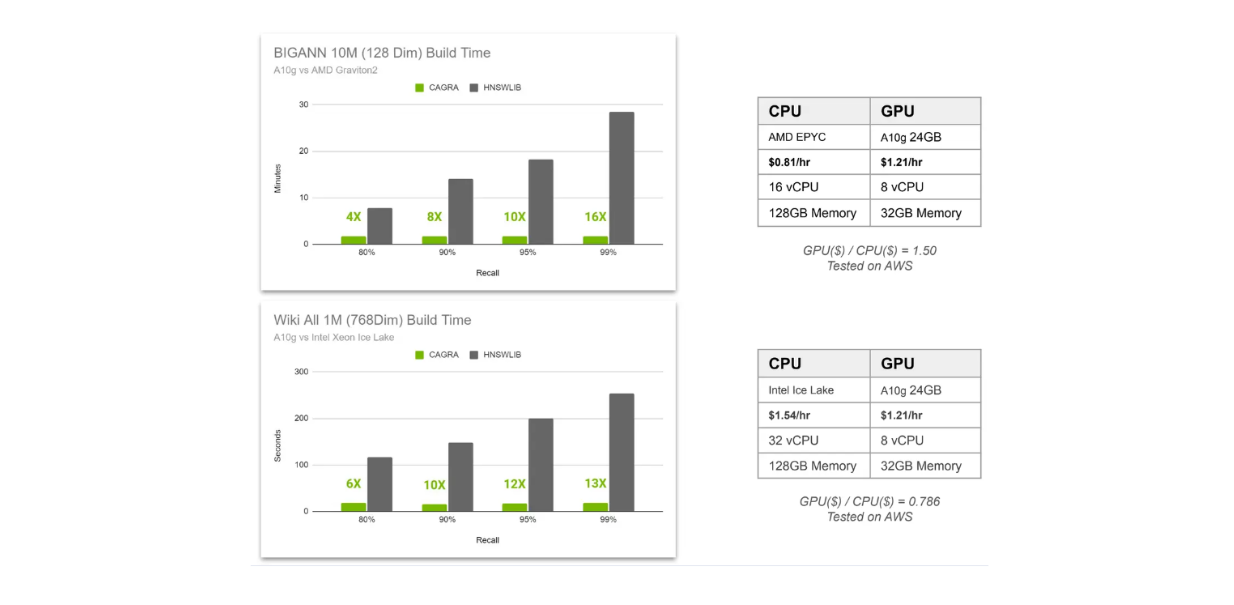 Index building time comparison CAGRA vs HNSW..png
Index building time comparison CAGRA vs HNSW..png
Index building time comparison CAGRA vs HNSW.
In the above visualization, we compare the index building time of CAGRA and HNSW in two different scenarios. First, we have 10M 128-dimensional vectors stored inside a vector database, and second, we have 1M 768-dimensional vectors. The first scenario uses AMD Graviton2 as CPU for HNSW and A10G GPU for CAGRA, while the second scenario uses Intel Xeon Ice Lake as CPU for HNSW and A10G GPU for CAGRA.
We compare the index building time at four different recall values, ranging from 80% to 99%. As you might already know, the higher the recall, the more intensive the computation needed.
This is because in a graph-based vector search, we can fine-tune two factors: the number of neighbors considered to find the nearest neighbor at each layer, and the number of nearest neighbors to consider as the entry point in each layer. The higher the recall, the more neighbors will be considered, resulting in higher retrieval accuracy but also higher computational cost.
From the visualization above, we see more value in using GPU when we want results with high recall. Also, the speed-up from using GPU increases as we increase the number of high-dimensional vectors stored in our vector database.
Next, let's compare the performance of HNSW and CAGRA using two common metrics in vector search:
Throughput: the number of queries that can be completed in a specific time interval.
Latency: the time the algorithm needs to complete one query.
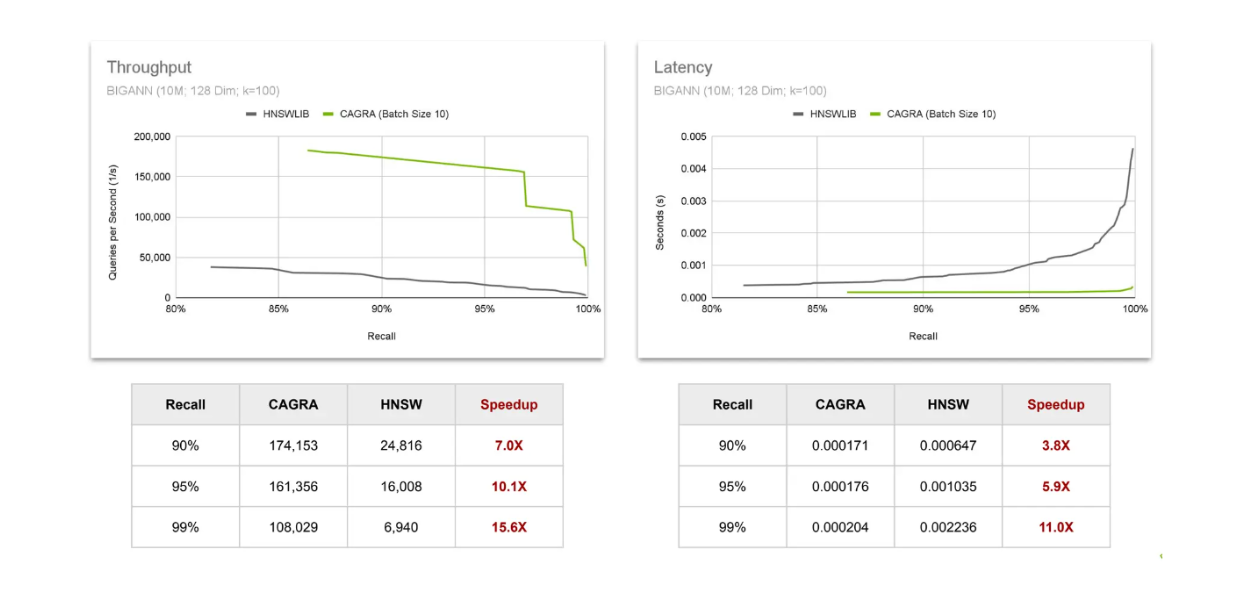 Throughput and latency comparisons CAGRA vs HNSW..png
Throughput and latency comparisons CAGRA vs HNSW..png
Throughput and latency comparisons CAGRA vs HNSW.
To assess throughput, we observe the number of queries that can be completed in a second. The results show that the speed-up from using CAGRA on GPU increases as we require results with higher recall values. The same trend is observed for latency, where the speed-up increases as the recall value increases. This confirms that the value of using GPU increases as we seek more precise results from vector search.
However, sometimes we still want to use CPU during vector search due to its simplicity and easy integration with other components in our AI application. In this case, implementing nearest neighbors algorithms with CAGRA is still helpful because we can perform vector search on both GPU and CPU afterwards.
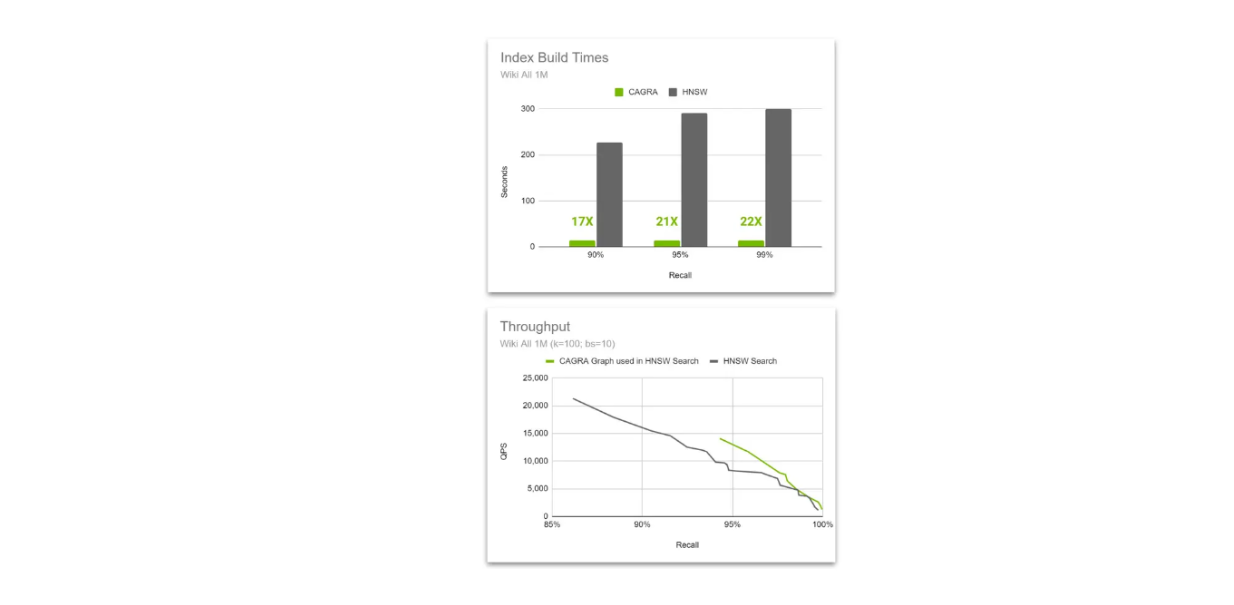 Throughput comparison between HNSW native vs CAGRA graph used in HNSW search..png
Throughput comparison between HNSW native vs CAGRA graph used in HNSW search..png
Throughput comparison between HNSW native vs CAGRA graph used in HNSW search.
The idea is to use the acceleration power of CAGRA and GPU during index building, but then switch to HNSW during vector search. This method is possible because the HNSW algorithm can perform a search using a graph built by CAGRA, and its performance is even better than the graph built with HNSW as the vector dimension increases.
CAGRA also offers a quantization method called CAGRA-Q to further compress the memory of stored vectors. This is particularly helpful for making memory allocation more efficient and allows us to store quantized vectors on smaller device memory for faster retrieval.
Let's say we have a device memory that has a smaller memory size compared to host memory. Initial performance benchmarks from NVIDIA showed that quantized vectors stored in device memory with the graph stored in host memory will have similar performance compared to original unquantized vectors and graph stored in device memory at higher recall rates.
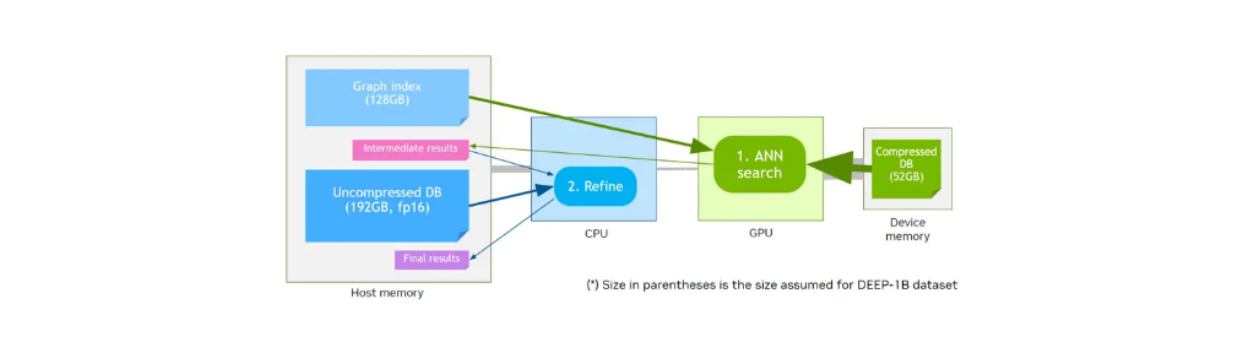 Vector search workflow by utilizing device memory and CAGRA-Q..png
Vector search workflow by utilizing device memory and CAGRA-Q..png
Vector search workflow by utilizing device memory and CAGRA-Q.
Milvus on the GPU with CuVS
Milvus supports integration with the cuVS library, allowing us to combine Milvus with CAGRA to build AI applications. Milvus' architecture consists of several nodes, such as index nodes, query nodes, and data nodes. cuVS optimizes Milvus' performance by accelerating processes within query nodes and index nodes.
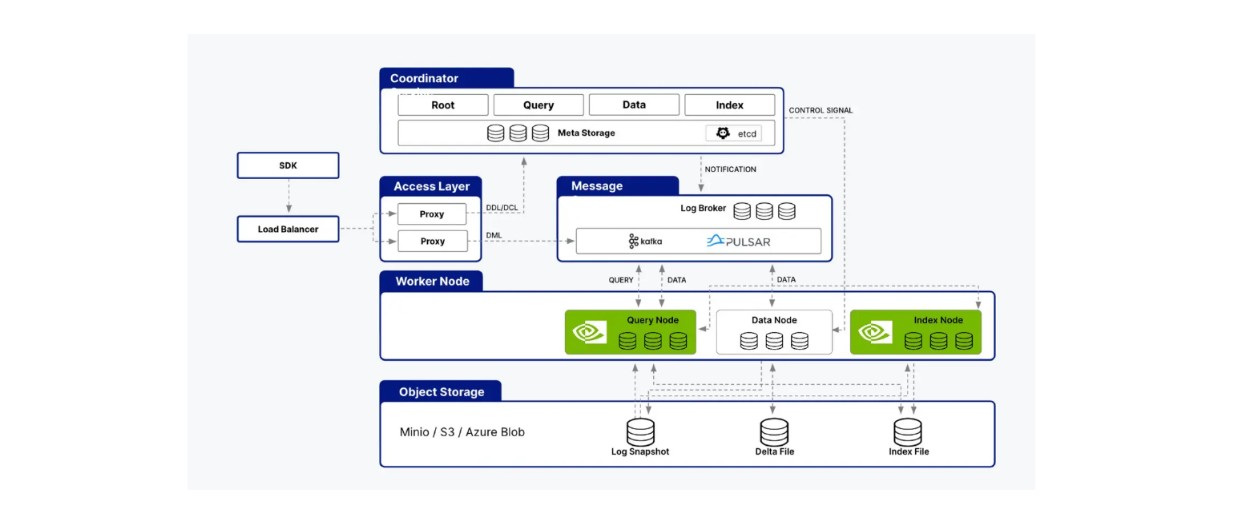 cuVS supports both query and index nodes of Milvus architecture..png
cuVS supports both query and index nodes of Milvus architecture..png
cuVS supports both query and index nodes of Milvus architecture.
As you might already know, index nodes are responsible for index building, while query nodes process user queries, perform vector searches, and return results to the user. We've seen how CAGRA improves all these aspects compared to native CPU algorithms like HNSW in the previous section.
Now, let's examine the performance of index building with cuVS and on-premise Milvus. Specifically, we'll look at the index building time using CAGRA and IVF-PQ across different numbers of vectors: 10, 20, 40, and 80 million.
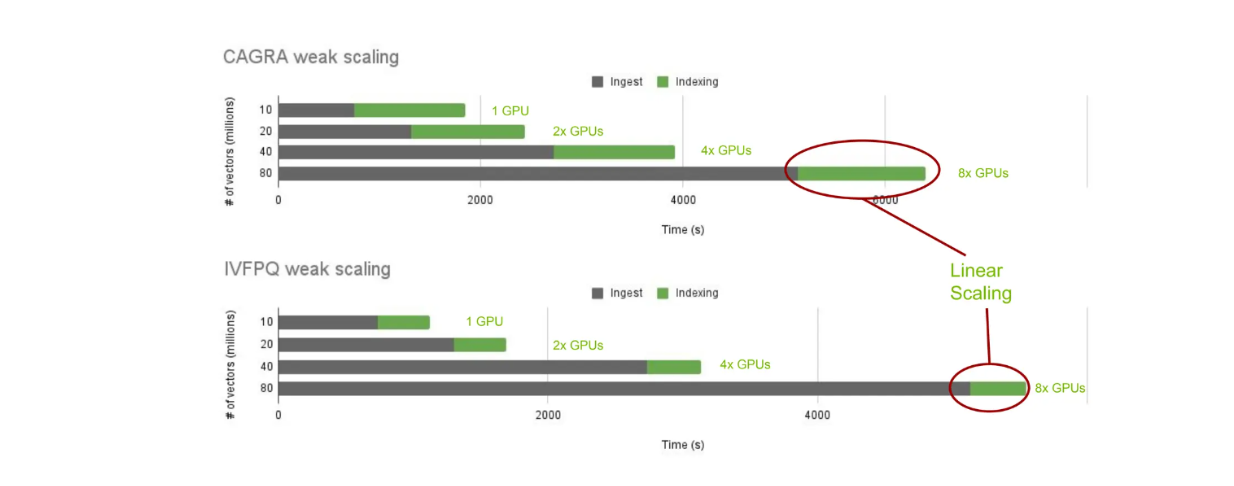 cuVS scaling of index building time across different nearest neighbors algorithms..png
cuVS scaling of index building time across different nearest neighbors algorithms..png
cuVS scaling of index building time across different nearest neighbors algorithms.
As expected, the ingest time increases as the number of stored vectors increases. However, the index building time remains constant as we linearly add more GPUs depending on the number of vectors stored. This allows us to scale and compare the index building time across different nearest neighbor algorithms with cuVS.
We know that GPUs offer faster computational operations compared to CPUs. However, the operational cost of using GPUs is also higher. Therefore, we need to compare the cost-performance ratio of using GPUs and CPUs with Milvus, as visualized below.
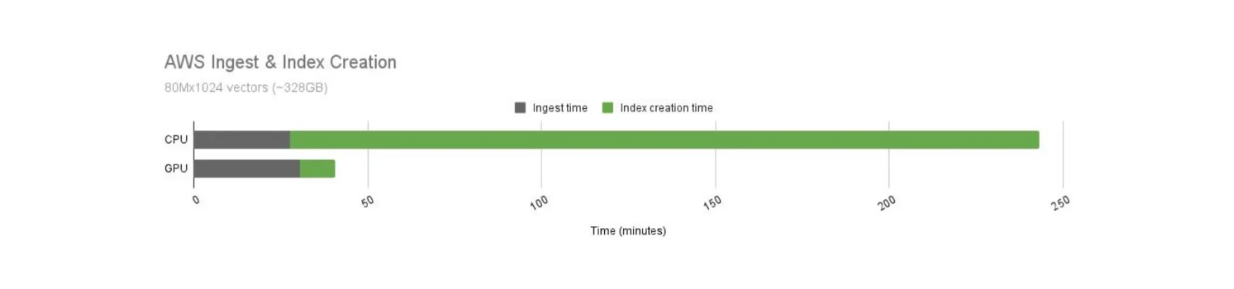 Milvus’ index building time comparison between GPU and CPU..png
Milvus’ index building time comparison between GPU and CPU..png
Milvus’ index building time comparison between GPU and CPU.
The index building time using GPUs is significantly faster than CPUs. In this use case, GPU-accelerated Milvus offers a 21x speedup compared to its CPU counterpart. However, the operational cost of GPUs is also more expensive than CPUs. The GPU costs 9.68 per hour.
When we normalize the cost-performance ratio of GPUs and CPUs, using GPUs for index building still yields better results. With the same cost, the index building time is 12.5x faster using GPUs.
In another benchmark test, we built an index for 635M 1024-dimensional vectors. Using 8 DGX H100 GPUs, the index building time with the IVF-PQ method takes around 56 minutes. In contrast, using a CPU to perform the same task would take approximately 6.22 days to complete.
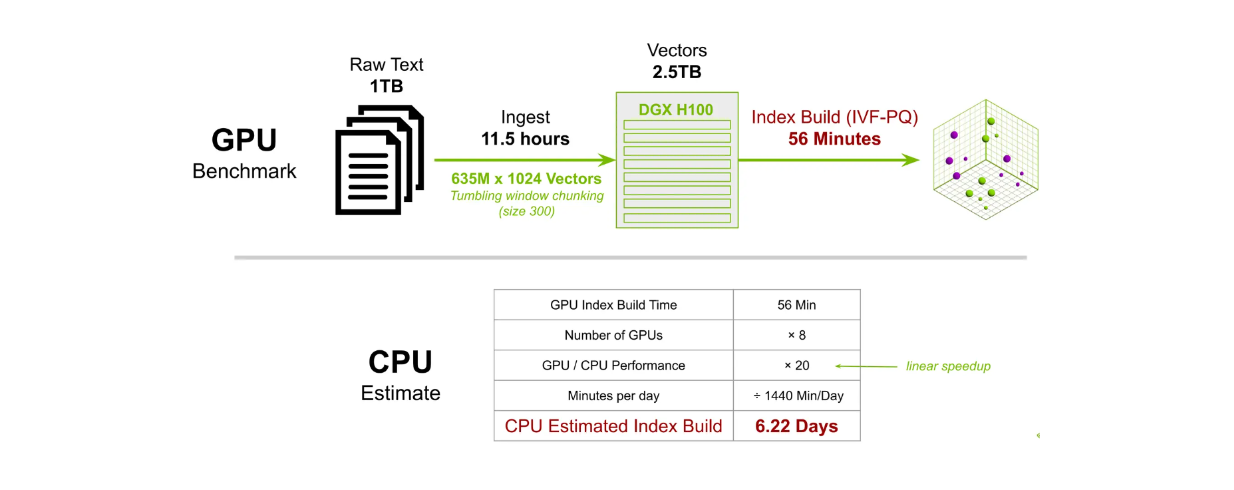 Large-scale Milvus’ index building time comparison between GPU and CPU..png
Large-scale Milvus’ index building time comparison between GPU and CPU..png
Large-scale Milvus’ index building time comparison between GPU and CPU.
Conclusion
The advancements in GPU-accelerated vector search through NVIDIA's cuVS library and CAGRA algorithm are highly beneficial for optimizing the performance of AI applications in production. Specifically, GPUs offer significant improvements over CPUs in cases involving high recall values, high vector dimensionality, and a large number of vectors.
Thanks to Milvus' integration capabilities, we can now easily incorporate cuVS into our Milvus vector database. While GPUs have higher operational costs than CPUs, the performance-cost ratio often still favors GPUs in large-scale applications, as demonstrated in the benchmarks above. If you'd like to learn more about cuVS, you can refer to the comprehensive documentation provided by the NVIDIA team.
Further Resources
Keep Reading

Introducing Zilliz CLI and Agent Skills for Zilliz Cloud
Manage your vector database from your terminal or AI coding agent. Zilliz CLI and Agent Skills work with Claude Code, Cursor, Codex, and Copilot.

Why Context Engineering Is Becoming the Full Stack of AI Agents
Discover how context engineering unifies prompts, RAG, and tools to build smarter, production-ready AI agents powered by Milvus.

Building RAG Pipelines for Real-Time Data with Cloudera and Milvus
explore how Cloudera can be integrated with Milvus to effectively implement some of the key functionalities of RAG pipelines.