




TF-IDF - Understanding Term Frequency-Inverse Document Frequency in NLP
We explore the significance of Term Frequency-Inverse Document Frequency (TF-IDF) and its applications, particularly in enhancing the capabilities of vector databases like Milvus.
Read the entire series
- Cross-Entropy Loss: Unraveling its Role in Machine Learning
- Batch vs. Layer Normalization - Unlocking Efficiency in Neural Networks
- Empowering AI and Machine Learning with Vector Databases
- Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
- Vector Databases: Redefining the Future of Search Technology
- Local Sensitivity Hashing (L.S.H.): A Comprehensive Guide
- Optimizing AI: A Guide to Stable Diffusion and Efficient Caching Strategies
- Nemo Guardrails: Elevating AI Safety and Reliability
- Data Modeling Techniques Optimized for Vector Databases
- Demystifying Color Histograms: A Guide to Image Processing and Analysis
- Exploring BGE-M3: The Future of Information Retrieval with Milvus
- Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
- TF-IDF - Understanding Term Frequency-Inverse Document Frequency in NLP
- Understanding Regularization in Neural Networks
- A Beginner's Guide to Understanding Vision Transformers (ViT)
- Understanding DETR: End-to-end Object Detection with Transformers
- Vector Database vs Graph Database
- What is Computer Vision?
- Deep Residual Learning for Image Recognition
- Decoding Transformer Models: A Study of Their Architecture and Underlying Principles
- What is Object Detection? A Comprehensive Guide
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Algorithmic)
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Methodological)
- Understanding CoCa: Advancing Image-Text Foundation Models with Contrastive Captioners
- Florence: An Advanced Foundation Model for Computer Vision by Microsoft
- The Potential Transformer Replacement: Mamba
- ALIGN Explained: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
In Natural Language Processing (NLP), understanding the relevance and significance of words within documents is crucial for many applications—from building intelligent search engines to automating document classification. Here, the TF-IDF (Term Frequency-Inverse Document Frequency) statistic emerges as a foundational tool that illuminates the importance of words in a way that mere frequency counts cannot.
TF-IDF helps pinpoint the relevance of a document to a specific query or topic by balancing the frequency of each word in a document against how rarely the word occurs in the entire document corpus (i.e., the whole set of documents being considered). A high TF-IDF score for a word in a document indicates that the word is not only common in that document but also rare in the overall document set—signifying that the word is likely crucial to the document's content.
For instance, in a corpus where many documents relate to technology, the word "computer" might appear often. However, if a specific document uses the word "quantum" more frequently than its occurrence in the corpus overall, then "quantum" would receive a higher TF-IDF score in this document, pointing to its importance in that particular context. On the other hand, common words like "is" and "of" appear frequently in almost all English texts and are thus given lower importance. This makes TF-IDF an excellent tool for distinguishing documents that are more relevant to less common, more specific topics within a broader discussion.
By employing TF-IDF, NLP systems can effectively rank and categorize documents, aiding in tasks such as search engine optimization, where retrieving the most relevant documents based on a user's query is crucial. The technique also supports summarization efforts by highlighting key terms that define the document's content, enabling quick and accurate information retrieval. Let's have a quick look at TF-IDF using Python:
# Example attribution: scikit-learn
# TfidfVectorizer and initializes it, preparing it to convert text documents into a TF-IDF matrix.
from sklearn.feature_extraction.text import TfidfVectorizer
# You have a list of documents (sentences) you want to analyze.
# In this example “docs” represents four different documents containing
# only once sentence each.
docs = ["This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?"]
# This step computes the TF-IDF for each word in the documents.
# The fit part learns the vocabulary of the documents and the transform part
# creates the TF-IDF matrix.
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(docs)
# This prints the vocabulary that has been learned by the vectorizer,
# showing you each unique word in your documents, ordered alphabetically.
print("Output feature names for transformation:\n")
print(vectorizer.get_feature_names_out())
# This shows the sparse matrix representation of the TF-IDF scores.
# It lists only the non-zero values, indicating which document (row) and which
# word (column) the score corresponds to.
print("\nSparse Matrix:\n")
print(tfidf_matrix)
Output:
Output feature names for transformation:
['and' 'document' 'first' 'is' 'one' 'second' 'the' 'third' 'this']
Sparse Matrix:
(0, 1) 0.46979138557992045
(0, 2) 0.5802858236844359
(0, 6) 0.38408524091481483
(0, 3) 0.38408524091481483
(0, 8) 0.38408524091481483
(1, 5) 0.5386476208856763
(1, 1) 0.6876235979836938
(1, 6) 0.281088674033753
(1, 3) 0.281088674033753
(1, 8) 0.281088674033753
(2, 4) 0.511848512707169
(2, 7) 0.511848512707169
(2, 0) 0.511848512707169
(2, 6) 0.267103787642168
(2, 3) 0.267103787642168
(2, 8) 0.267103787642168
(3, 1) 0.46979138557992045
(3, 2) 0.5802858236844359
(3, 6) 0.38408524091481483
(3, 3) 0.38408524091481483
(3, 8) 0.38408524091481483
Dense Matrix:
[[0. 0.46979139 0.58028582 0.38408524 0. 0.
0.38408524 0. 0.38408524]
[0. 0.6876236 0. 0.28108867 0. 0.53864762
0.28108867 0. 0.28108867]
[0.51184851 0. 0. 0.26710379 0.51184851 0.
0.26710379 0.51184851 0.26710379]
[0. 0.46979139 0.58028582 0.38408524 0. 0.
0.38408524 0. 0.38408524]]
['and' 'document' 'first' 'is' 'one' 'second' 'the' 'third' 'this']
The array shows that each word is indexed according to its position in this alphabetically sorted list. According to this list:
“and” is at the 0th index
“document” is at the 1st index
“first” is at the 2nd index
“is” is at the 3rd index
“one” is at the 4th index
“second” is at the 5th index
“the” is at the 6th index
“third” is at the 7th index
“this” is at the 8th index
Therefore, the entry (0, 1) 0.46979138557992045 in the sparse matrix corresponds to the word "document", which indeed appears in the first document ("This is the first document."). This matches the index 1 from the feature names list. The dense matrix represents the TF-IDF scores in a 2D array format, where each row corresponds to a specific document and each column to a word from your list of features. In this matrix, the cell values show the TF-IDF scores for each word in their respective document. A score of zero in any cell indicates that the corresponding word does not appear in that document.
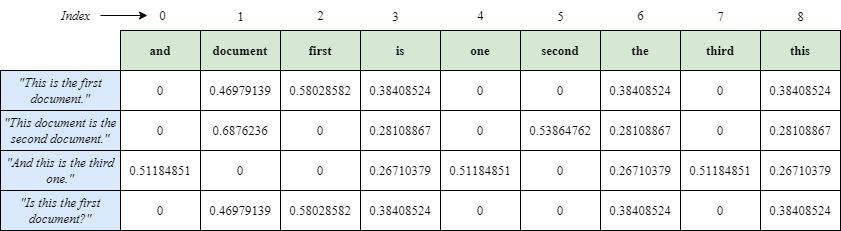
Understanding TF-IDF
- Term Frequency (TF): Term Frequency (TF) measures how frequently a term occurs in a document. In the context of text analysis and NLP, TF is calculated simply by dividing the number of times a specific word appears in a document by the total number of words in that document. This normalization adjusts for the varying lengths of documents, ensuring that the frequency of terms in longer documents doesn't inherently outweigh those in shorter documents just because they have more words.
If we denote the term by 𝑡 and the document by 𝑑 TF is calculated as:
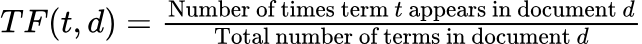
- Inverse Document Frequency (IDF): TF measures how often a specific word appears in a document. The underlying concept is that a word's relevance to a document increases with its frequency of appearance. However, if a word appears excessively, it might overshadow other words that appear less frequently but are potentially more indicative of the document's content and themes. This is why while term frequency is a helpful measure, it is often balanced with other methods, such as inverse document frequency (IDF), to provide a more nuanced insight into word significance within texts. This balance helps prevent common but less informative words from dominating the feature representation of the text. IDF is calculated as:
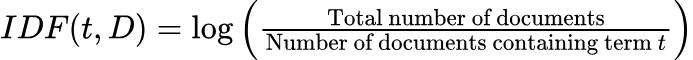
- Combining TF and IDF: TF-IDF is then calculated by multiplying these two statistics:
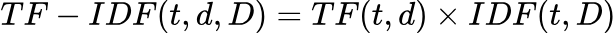
Practical Applications of TF-IDF
Understanding the output of TF-IDF can help in numerous NLP tasks such as feature extraction for machine learning models, information retrieval, and text classification. The TF-IDF scores can serve as inputs for algorithms that require numerical input rather than raw text, such as clustering algorithms or classification algorithms like SVM or Naive Bayes. Some of the applications of TF-IDF are as follow:
Enhancing Search Engines: TF-IDF can drastically improve the functionality of search engines by prioritizing documents that contain frequent terms in a query while considering the rarity of each term across all documents. This ensures that results returned are more relevant to the user’s query.
Vector Databases and Document Similarity: In vector databases, documents are transformed into vectors of TF-IDF values. These vectors can then be compared using cosine similarity to find documents that are contextually similar to each other. This approach is particularly useful in recommendation systems and document classification tasks.
Application of TF-IDF in Vector Databases
Vector databases, such as Milvus, are designed specifically to manage and query vector data efficiently. These databases are ideal for handling large volumes of high-dimensional data typically found in machine learning applications, ranging from natural language processing to image recognition. By storing data as vectors, these databases enable highly efficient similarity searches, leveraging spatial relationships and metrics like cosine similarity or Euclidean distance for quick retrieval of similar items.
TF-IDF helps convert text into a numerical form by assigning weights to words based on their occurrence frequencies across documents. These weights signify the importance of words within documents, facilitating the creation of vectorized representations of text. In vector databases like Milvus, TF-IDF can enhance the vector representations of text data, making the search and retrieval processes more efficient.
Here's how TF-IDF integrates with vector databases:
Improved Search Accuracy: By weighting words in documents through TF-IDF, vector databases can create more accurate and meaningful vector representations of text. This process involves distinguishing between common words and those that are crucial for understanding a document's context, thereby enhancing the relevance and precision of search results.
Enhanced Retrieval Efficiency: TF-IDF assists in constructing vector representations where each dimension correlates to a TF-IDF score of a term. This allows vector databases to perform efficient similarity calculations, aiding in the retrieval of documents that are contextually similar to a search query. Such capabilities are crucial in applications requiring rapid and accurate document retrieval, such as semantic search and document clustering.
Scalability and Performance: TF-IDF also helps in managing scalability in text analysis. By focusing on significant terms (those with high TF-IDF scores), it is possible to reduce the dimensionality of data, leading to more manageable vector sizes. This reduction is essential for maintaining performance, especially within large-scale vector databases, ensuring they remain responsive as data volumes grow.
Use Case in Milvus: As an open-source vector database, Milvus is optimized for scalable similarity searches using vector embeddings. It is adept at storing and searching through massive quantities of vectors, which can be generated from text data using techniques like TF-IDF. This capability makes Milvus particularly useful for industries and applications where quick access to relevant information based on text data is crucial, such as digital libraries, e-commerce product recommendations, and more.
Integrating TF-IDF with Milvus for Enhanced Text Search
Let's proceed with the Python script we previously worked on, making some enhancements to successfully store the tfidf_matrix in a Milvus vector database. Here's how we can integrate the TF-IDF vectors into Milvus, ensuring they are properly indexed for efficient querying and retrieval:
Step 1: Importing the libraries and connecting to Milvus server
from pymilvus import (
connections,
FieldSchema,
CollectionSchema,
DataType,
Collection,
utility
)
# Connect to Milvus server
connections.connect(
alias="default",
host='localhost',
port='19530'
)
The code imports necessary components from the pymilvus library, which is used to interact with the Milvus vector database. It then establishes a connection to a Milvus server running locally on the default port 19530.
Step 2: Defining the fields, creating the schema, and the collection in Milvus
# Define the fields for the Milvus collection
fields = [
FieldSchema(name = "id", dtype = DataType.INT64, is_primary = True, auto_id = True),
FieldSchema(name = "embedding", dtype = DataType.SPARSE_FLOAT_VECTOR)
]
# Create the schema and the collection in Milvus
schema = CollectionSchema(fields, description = "TF-IDF Vectors")
collection_name = "TFIDF_Collection"
collection = Collection(name = collection_name, schema = schema, consistency_level = "Strong")
This code snippet defines the fields and schema for a new Milvus collection called “TFIDF_Collection” that will store TF-IDF vectors. It sets up two fields: “id”, which is an automatically generated primary integer key, and “embedding”, which holds the floating-point vector data of a dimensionality specified by the number of features extracted by the “vectorizer”. After defining the collection schema, the script checks if the collection already exists and releases it to avoid conflicts during index modification. It also checks for an existing index on the collection and drops it if found, ensuring it is ready for new operations or schema updates.
Step 3: Inserting the data in Milvus
# Define index parameters
index_params = {
"index_type": "SPARSE_INVERTED_INDEX", # Choose an appropriate index type based on your needs
"metric_type": "IP", # Using IP distance (Inner Product)
"params": {} # Adjust the parameter based on your dataset size
}
# Create the index
collection.create_index(field_name = "embedding", index_params = index_params)
print("New index created successfully.")
collection.load()
# Insert the vectors into Milvus
mr = collection.insert([tfidf_matrix])
This code sets up and applies an index to a Milvus collection for managing TF-IDF vectors. It defines index parameters, choosing “SPARSE_INVERTED_INDEX” for efficient vector search and “Inner Product” for distance measurement, setting “nlist” to 100 to optimize search performance. After creating the index on the "embedding" field and confirming its creation, the collection is loaded for data operations. Then, the TF-IDF vectors are inserted into the Milvus collection.
Step 4: Performing similarity search
# Define a query vector (could be another TF-IDF vector)
query_vector = tfidf_matrix[0:1, :]
# Search for the top 3 most similar vectors
search_params = {
"metric_type": "IP",
"params": {}
}
results = collection.search(
query_vector,
"embedding",
search_params,
limit=3)
# Print out the results
for hits in results:
for hit in hits:
print(f"hit: {hit}")
utility.drop_collection(collection_name)
The final code defines a TF-IDF vector as a query, searches for the top three most similar vectors in a Milvus collection using the inner product metric, and prints the details of each found match. This step effectively demonstrates how to implement and utilize vector-based search capabilities for text similarity applications in Milvus.
Advanced Considerations
TF-IDF, a foundational tool in text processing, has several variations that enhance its effectiveness under different scenarios:
Sublinear TF Scaling: To reduce the impact of high term frequency, TF can be adjusted using a logarithmic scale, tf = 1 + log(tf), which moderates the weight of terms that appear very frequently, helping mitigate bias in longer documents. (Reference: https://nlp.stanford.edu/IR-book/html/htmledition/sublinear-tf-scaling-1.html)
Normalization Techniques: Applying normalization, especially L2 normalization, scales vectors to unit length, focusing similarity calculations on the angles between vectors rather than their magnitudes. This ensures consistent measurements across all document comparisons, crucial for accurate similarity and relevance assessments.
Besides TF-IDF, several other term weighting schemes might be more effective depending on specific needs:
Word Embeddings: Methods like Word2Vec or GloVe provide dense vector representations of words based on their contexts, capturing deeper semantic meanings that TF-IDF might miss, useful in applications like sentiment analysis.
Latent Semantic Analysis (LSA): LSA applies singular value decomposition to discover latent patterns in text data, reducing dimensionality while capturing underlying semantic relationships, beneficial for document clustering and retrieval tasks.
Challenges of TF-IDF and How BM25 Addresses Them
While TF-IDF has long been a popular information retrieval method based on term relevance, it has several major challenges. Best Matching 25 (BM25) is basically an extension of TF-IDF that can improve traditional TF-IDF by addressing these problems.
Below is a list of the major challenges of TF-IDF and how BM25 can solve these problems.
Term Frequency Weighting: In TF-IDF, term frequency (TF) measures the importance of a term in a document. However, document length can skew the results. Longer documents may naturally have higher term frequencies for certain terms. BM25 addresses this by using a logarithmic scaling factor for term frequency.
Inverse Document Frequency: TF-IDF uses inverse document frequency (IDF) to diminish the weight of terms that occur frequently across the entire corpus. However, IDF can be sensitive to outliers and doesn't always effectively capture the rarity of terms. BM25 addresses this by using a probabilistic model to estimate IDF, which is more robust and adapts better to varying term distributions.
Document Length Normalization: In TF-IDF, longer documents tend to have higher scores for matching terms due to higher term frequencies. This can bias search results towards longer documents. BM25 incorporates document length normalization, which adjusts the TF component based on the length of the document, thus mitigating the bias towards longer documents.
Parameter Tuning: TF-IDF doesn't have many parameters to tune, but selecting the optimal values for IDF smoothing and normalization can be challenging and may require domain knowledge. BM25 introduces additional parameters, such as the BM25-specific parameters k1 and b, which can be tuned to optimize retrieval performance for specific datasets or applications.
Scalability: TF-IDF is relatively simple and computationally efficient, but it may not scale well to large document collections or real-time retrieval systems. BM25 can be more scalable and performant in large-scale search applications, particularly when implemented with efficient indexing structures like inverted indexes.
Robustness to Noisy Data: TF-IDF can be sensitive to noise and outliers in the data, leading to suboptimal retrieval results. BM25's probabilistic approach makes it more robust to noisy data and outliers, as it focuses on the relative frequency of terms rather than their absolute occurrence.
For a more detailed discussion of BM25’s concept and mechanism and how to implement it with the Milvus vector database, refer to our blog: Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus.
Conclusion
Throughout this article, we explored the significance of Term Frequency-Inverse Document Frequency (TF-IDF) and its applications, particularly in enhancing the capabilities of vector databases like Milvus. We discussed how TF-IDF serves as a critical tool in text analysis, providing a quantitative way to ascertain the importance of words in documents relative to a corpus. This is especially beneficial in applications like search engines, document classification, and information retrieval.
We jumped into the practical aspects of implementing TF-IDF with Python, using libraries like Scikit-learn to create and manipulate TF-IDF vectors. The integration of these vectors into vector databases such as Milvus was covered, highlighting how they can be stored, indexed, and queried to facilitate efficient and meaningful search results based on textual similarity.
Further, we touched upon advanced topics, including variations like sublinear TF scaling and normalization techniques to enhance the basic TF-IDF model. Alternatives to TF-IDF, such as Word Embeddings, were also discussed as potential substitutes or complements in different scenarios, depending on the specific needs of a project.
This article underscored the adaptability and enduring relevance of TF-IDF in the field of natural language processing (NLP). As NLP continues to evolve, the exploration and experimentation with TF-IDF and its variants remain vital for those looking to leverage textual data effectively. Whether you're developing sophisticated NLP applications or just beginning to explore text analysis, the principles and techniques discussed here provide a solid foundation for further innovation and research.
Resources and Further Reading
Langchain Milvus integration (https://python.langchain.com/docs/integrations/retrievers/self_query/milvus_self_query/)
Introduction to Information Retrieval (https://nlp.stanford.edu/IR-book/)

- Understanding TF-IDF
- Practical Applications of TF-IDF
- Application of TF-IDF in Vector Databases
- Integrating TF-IDF with Milvus for Enhanced Text Search
- Advanced Considerations
- Challenges of TF-IDF and How BM25 Addresses Them
- Conclusion
- Resources and Further Reading
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Exploring BGE-M3: The Future of Information Retrieval with Milvus
The potential of BGE-M3 and Milvus is limitless, offering vast opportunities for innovation in virtually any field that relies on information retrieval.

Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
We can easily implement the BM25 algorithm to turn a document and a query into a sparse vector with Milvus. Then, these sparse vectors can be used for vector search to find the most relevant documents according to a specific query.
The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Algorithmic)
In this article, we'll discuss the evolution of MAS from its early days to the most recent developments from an algorithmic perspective.