




Scaling Vector Databases to Meet Enterprise Demands
In this blog, we will explore the concept of database scalability and unravel Milvus's scaling capability. We will also introduce its scalability techniques and explore how they pave the way for unparalleled performance and innovation in unstructured data management.
Read the entire series
- How to Evaluate RAG Applications
- Benchmarking Vector Database Performance: Techniques and Insights
- How to Spot Search Performance Bottleneck in Vector Databases
- Ensuring High Availability of Vector Databases
- Safeguard Data Integrity: Backup and Recovery in Vector Databases
- Scaling Vector Databases to Meet Enterprise Demands
- Introducing an Open Source Vector Database Benchmark Tool for Choosing the Ideal Vector Database for Your Project
In today's world, organizations face both opportunities and challenges due to the rapid growth of data, especially unstructured data. Scalable solutions are needed to manage and utilize this vast amount of information effectively. Vector databases, such as Milvus, are designed to handle unstructured data by representing it as numerical vectors in high-dimensional space.
In this blog, we will explore the concept of database scalability and unravel Milvus's scaling capability. We will also introduce its scalability techniques and explore how they pave the way for unparalleled performance and innovation in unstructured data management.
Understanding Database Scalability
Generally, database scalability refers to the dynamic capacity to expand or contract system resources like CPU, storage, and memory to seamlessly align with evolving business demands. There are two fundamental types of scalability: vertical and horizontal scalability.
Vertical Scalability (Scaling Up): Vertical scalability, which involves increasing the capacity of a single database server by adding resources such as CPU, memory, and storage, has its limitations. While it provides a quick and direct solution, it's important to note that there is an upper limit to how much a single server can scale before it hits hardware constraints. Understanding these limitations is key to making effective scalability decisions in real-world scenarios.
Horizontal Scalability (Scaling Out): Horizontal scalability, which involves adding additional servers to distribute workloads, offers significant benefits. This strategy partitions large datasets and distributes them across all these nodes. By gradually adding nodes to the database cluster, horizontal scalability opens up the possibility of virtually limitless expansion. It also enhances fault tolerance, as the system can seamlessly redistribute tasks among remaining nodes in the event of a node failure. Understanding these advantages is crucial for managing large datasets and ensuring system reliability.
Scalability of Milvus Vector Database
Milvus is an open-source vector database boasting scalability both vertically and horizontally. With its distributed and cloud-native architecture, Milvus seamlessly accommodates astronomical volumes of vectors up to trillions, all with lightning-fast response times measured in milliseconds. The benchmark results illustrate Milvus's ability to scale both up and out.
Below are snapshots of Milvus's performance dynamics (version 2.2.0) as computing resources are scaled up and down. Whether adding the resources of the Querynode cluster or expanding Querynode replicas, Milvus shows a tangible enhancement in its query processing capability (QPS) alongside a reduction in TP99 latency.
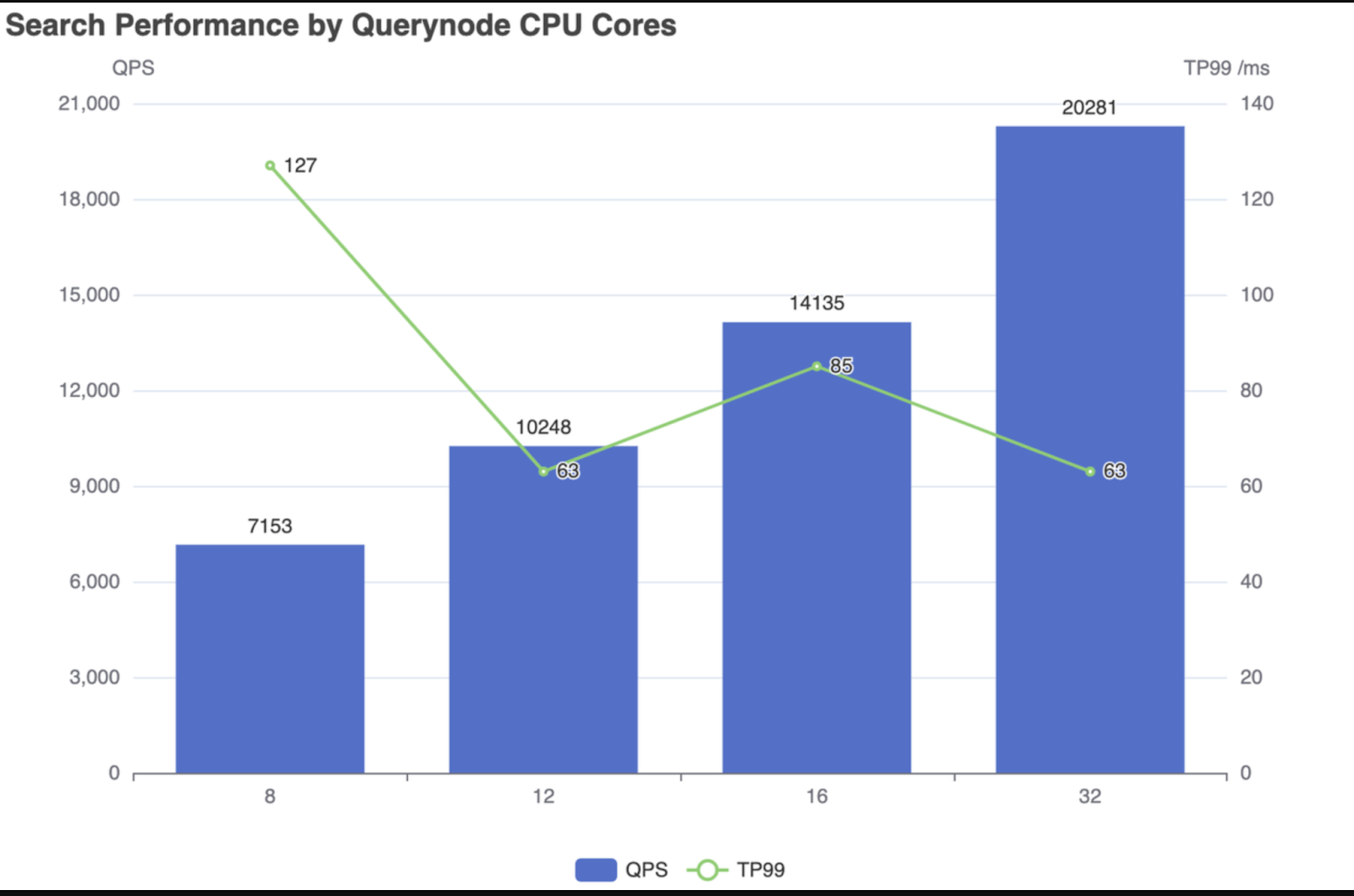 Fig 1: Search performance by scaling up Querynode CPU cores
Fig 1: Search performance by scaling up Querynode CPU cores
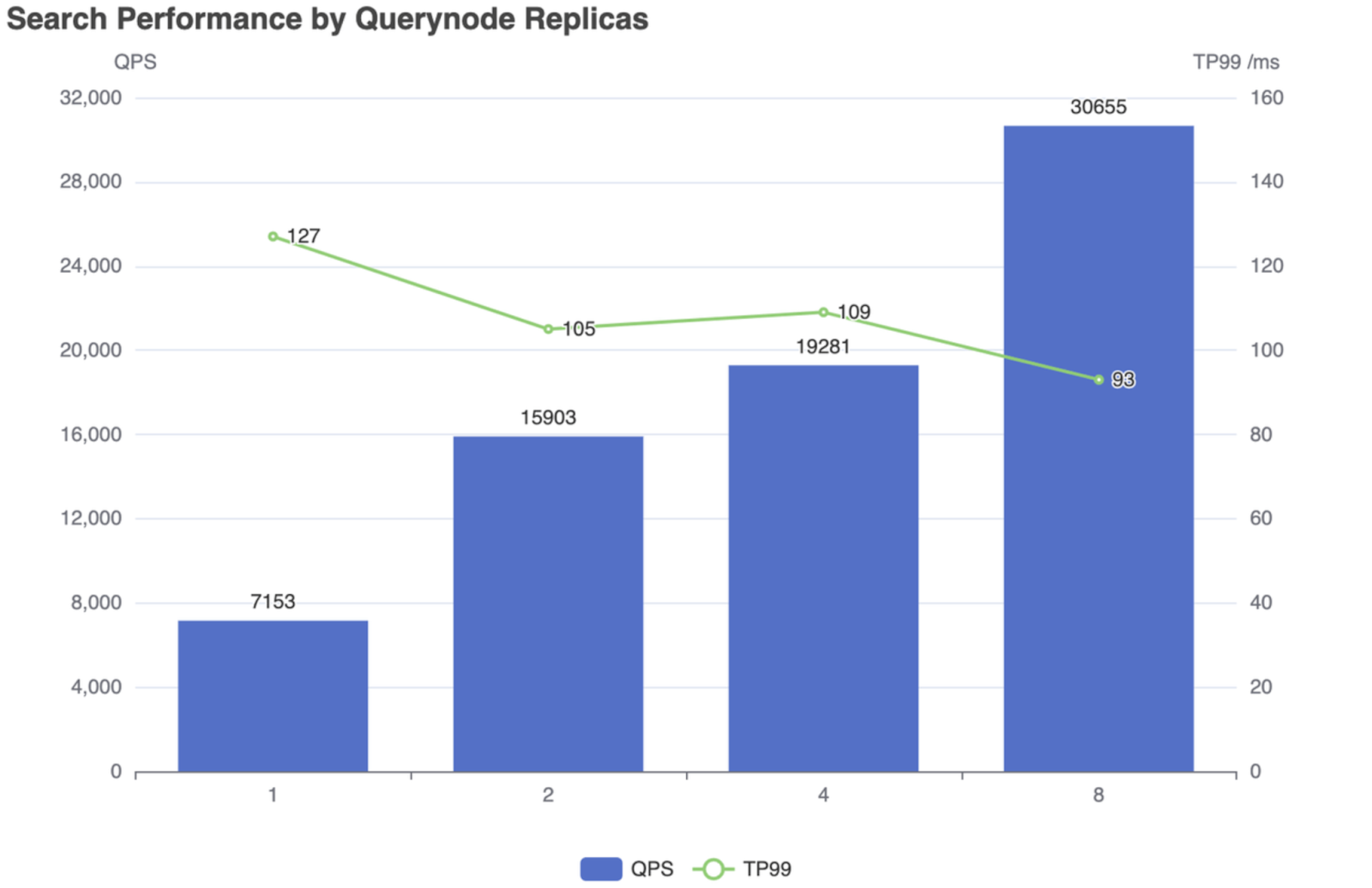 Fig 2: Search performance by scaling out Querynode replicas
Fig 2: Search performance by scaling out Querynode replicas
How Milvus Achieves Its Unparalleled Scaling
Milvus adopts two primary scaling techniques to achieve exceptional scalability: replication, partitioning, and load-balancing.
Replication
Replication is a cornerstone of Milvus's scalability strategy. By duplicating or copying computer resources across multiple nodes in a cluster, Milvus ensures that user requests are spread evenly, preventing any single node from becoming overwhelmed. This approach increases the system's capacity to handle more database read requests and adds a layer of resilience. Each node in the cluster contains a copy of the data, so in the event of a node failure, other replica nodes can seamlessly take over, minimizing downtime and ensuring uninterrupted service.
Partitioning
Partitioning is a pivotal component of Milvus's scalability framework, offering a sophisticated but efficient approach to managing and distributing large datasets across its infrastructure. At its core, partitioning involves dividing data into smaller, more manageable units called segments or partitions. These partitions are then distributed across multiple databases, enabling Milvus to scale its storage and computing capacity virtually without limit.
But how does partitioning work in practice within the Milvus ecosystem?
Data Organization and Segmentation
When data is ingested into Milvus, it is organized into collections, each representing a distinct dataset or data type. Partitioning allows these collections to be further divided into logical segments, each containing a subset of the data. This logical organization facilitates efficient data retrieval and processing, especially when subsets of data need to be accessed or manipulated independently.
Dynamic Scalability and Parallel Processing:
One key advantage of partitioning in Milvus is its ability to dynamically scale storage capacity as data volumes grow. As new data is ingested into the system, it is automatically distributed across available partitions and segments, ensuring optimal resource utilization and performance. This dynamic scalability allows organizations to seamlessly expand their data infrastructure without encountering bottlenecks or performance degradation.
Moreover, partitioning enables parallel data processing across multiple nodes within the Milvus cluster. Each node manages a subset of partitions and segments, allowing concurrent indexing, querying, and data manipulation operations. This parallel processing capability enhances read and write performance, enabling Milvus to easily handle large-scale data workloads.
Segment Size and Management:
In Milvus, segments represent the smallest data units distributed across nodes, typically ranging from 512MB to 1GB. The size of segments is carefully balanced to optimize IO cost and search performance. Smaller segments lead to faster indexing and lower search latency, albeit with increased IO operations during searches. Segment management is critical for optimizing storage efficiency and performance. Milvus uses sophisticated algorithms and data placement strategies to ensure that segments are distributed evenly across nodes and that data access patterns are optimized for maximum throughput and responsiveness.
Load Balancing
With data segmented into multiple segments, load balancing becomes crucial to ensure that the workload is evenly distributed across nodes. Milvus achieves this through background processes known as balancers, which assign segments to nodes dynamically to achieve workload balance. In case of imbalance, the balancer initiates tasks to adjust segment distribution among nodes seamlessly. Importantly, these tasks are executed transactionally, guaranteeing ongoing queries remain unaffected and ensuring seamless load balancing.
Comparing Mainstream Vector Databases on Scalability
Different vector databases cater to different types of users, so their scalability strategies differ. For example, Milvus concentrates on use cases with rapidly increasing data volumes and uses a horizontally scalable architecture with storage-compute separation. Pinecone and Qdrant are designed for users with moderate data volume and scaling demands. LanceDB and Chroma prioritize lightweight deployments over scalability.
The table below shows the scalability strategy offered by mainstream vector databases.
| Vector databases | Open Source? | Vertical Scaling | Horizontal Scaling |
| Milvus | √ | √ | √ (brillion-level) |
| Zilliz Cloud (the managed Milvus) | Closed source SaaS | √ | √ (brillion-level) |
| Pinecone | Closed source SaaS | √ | x (billion-level) |
| Qdrant | √ | √ | √ |
| Weaviate | √ | √ | √ |
| Chroma | √ | √ | x |
| LanceDB | √ | √ | x |
Refer to our comparison page to compare more mainstream vector databases.
Summary
The quest for scalable solutions for unstructured data management has never been more crucial in today’s data-driven world. As organizations grapple with the relentless influx of data, the need to effectively harness and manage this information becomes increasingly pressing.
In this post, we explored the concept and significance of database scalability in modern data management and unraveled Milvus’s capability of easily scaling out to accommodate trillions of vectors. From its meticulously engineered architecture to its innovative scalability techniques, Milvus stands at the forefront of data management, paving the way for unparalleled performance and innovation.
 Ted Xu
Ted XuTed Xu is a Principal Engineer at Zilliz.
- Understanding Database Scalability
- Scalability of Milvus Vector Database
- How Milvus Achieves Its Unparalleled Scaling
- Comparing Mainstream Vector Databases on Scalability
- Summary
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Benchmarking Vector Database Performance: Techniques and Insights
Deep diving into key evaluation metrics and tools for vector databases and offering insights to aid in evaluating vector databases for informed decision-making.

Safeguard Data Integrity: Backup and Recovery in Vector Databases
This blog explores data backup and recovery in vectorDBs, their challenges, various methods, and specialized tools to fortify the security of your data assets.

Introducing an Open Source Vector Database Benchmark Tool for Choosing the Ideal Vector Database for Your Project
Introducing VectorDBBench, an open-source vector database benchmark tool for choosing the ideal vector database for your project.