




What is Computer Vision?
Computer Vision is a field of Artificial Intelligence that enables machines to capture and interpret visual information from the world just like humans do.
Read the entire series
- Cross-Entropy Loss: Unraveling its Role in Machine Learning
- Batch vs. Layer Normalization - Unlocking Efficiency in Neural Networks
- Empowering AI and Machine Learning with Vector Databases
- Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
- Vector Databases: Redefining the Future of Search Technology
- Local Sensitivity Hashing (L.S.H.): A Comprehensive Guide
- Optimizing AI: A Guide to Stable Diffusion and Efficient Caching Strategies
- Nemo Guardrails: Elevating AI Safety and Reliability
- Data Modeling Techniques Optimized for Vector Databases
- Demystifying Color Histograms: A Guide to Image Processing and Analysis
- Exploring BGE-M3: The Future of Information Retrieval with Milvus
- Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
- TF-IDF - Understanding Term Frequency-Inverse Document Frequency in NLP
- Understanding Regularization in Neural Networks
- A Beginner's Guide to Understanding Vision Transformers (ViT)
- Understanding DETR: End-to-end Object Detection with Transformers
- Vector Database vs Graph Database
- What is Computer Vision?
- Deep Residual Learning for Image Recognition
- Decoding Transformer Models: A Study of Their Architecture and Underlying Principles
- What is Object Detection? A Comprehensive Guide
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Algorithmic)
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Methodological)
- Understanding CoCa: Advancing Image-Text Foundation Models with Contrastive Captioners
- Florence: An Advanced Foundation Model for Computer Vision by Microsoft
- The Potential Transformer Replacement: Mamba
- ALIGN Explained: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
Introduction
Computer Vision is a field of Artificial Intelligence that enables machines to capture and interpret visual information from the world just like humans do. Computer vision aims to automate the human vision system to recognize objects, understand scenes, and make judgments after analyzing the visual data.
Over the past two decades, computer vision applications have dramatically increased thanks to advancements in camera technology, the rise of computational resources, and the availability of large amounts of data. In healthcare, computer vision aids in the early detection of fatal diseases such as brain tumors or breast cancer. In automotive, it powers self-driving cars to recognize objects and understand road conditions. Manufacturing benefits from automated quality control, while retail uses computer vision for inventory management and personalized shopping experiences. The diverse applications of computer vision are increasing efficiency and driving innovation across various sectors, significantly benefiting the world.
What Exactly is Computer Vision?
Computer Vision gives computers the capability of humans to see, analyze, and interpret visuals in the real world. Imagine teaching a computer to recognize objects, such as identifying whether a photo contains a dog or a cat or recognizing from a video whether the sport being played is hockey or cricket. Sounds interesting, right?
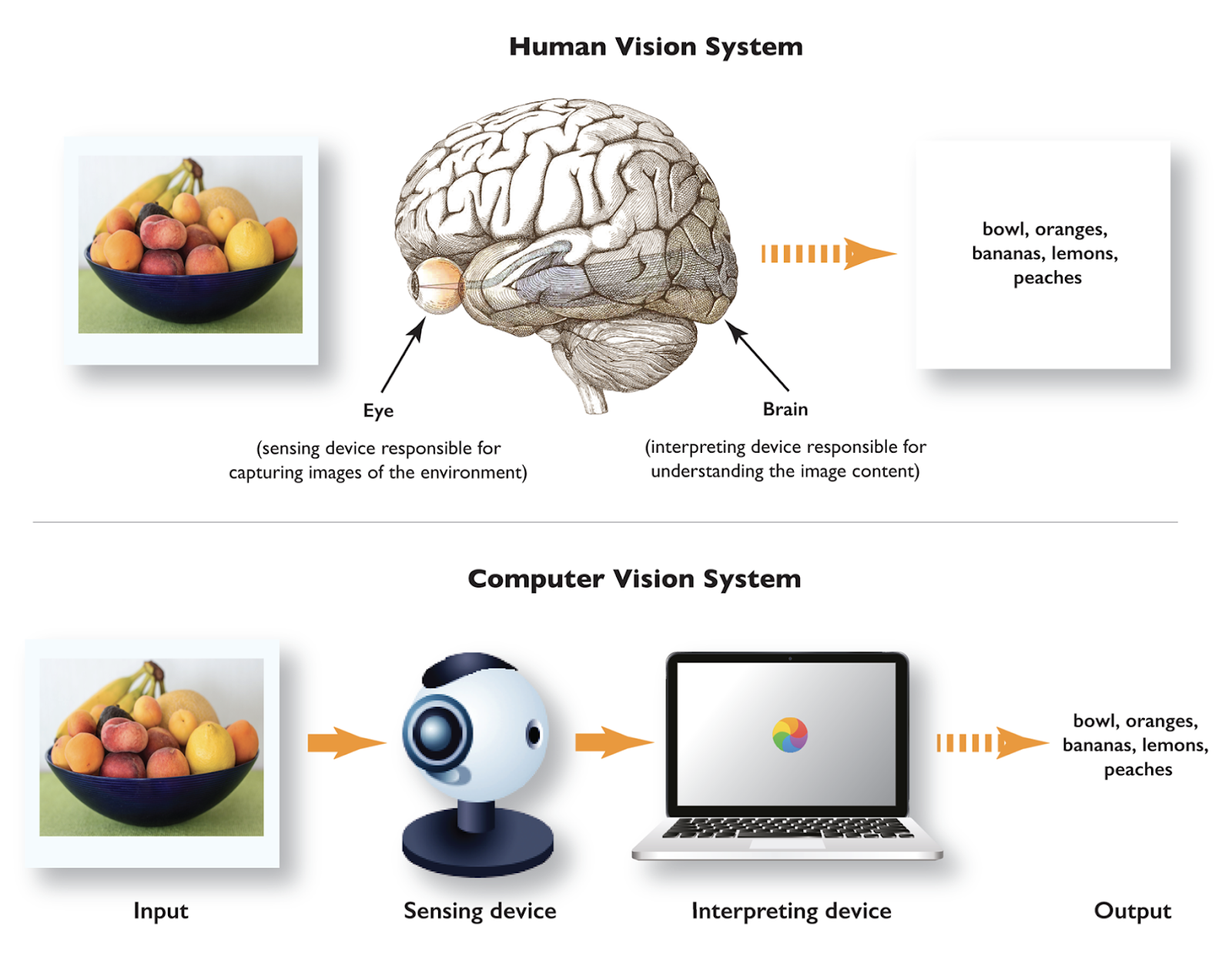 what is computer vision.png
what is computer vision.png
What is Computer Vision? (Source)
In our everyday life, we frequently use applications powered by computer vision. One of them is face ID recognition in our smartphones. Once your face is scanned while setting up the face ID, the algorithm detects the key points on your face and stores the information for future uses. Another example is Snapchat filters that let you add dog ears or funny hats to your face. Additionally, using visual search, users can upload photos of products they like while shopping online on e-commerce websites, and the system will find similar products. Therefore, computer vision already plays an integral role in our routine tasks.
How Computer Vision Works
Several stages are involved in the basic working of computer vision algorithms, as described below.
Image Acquisition—The first step is to acquire an image or a video by capturing it with devices such as a camera or a sensor. This data is raw and serves as input to the next preprocessing step.
Data Preprocessing—The raw data undergoes preprocessing to remove unwanted noise and enhance the image quality, making it suitable for further analysis.
Feature Extraction—The processed data is then passed to computer vision algorithms to extract features (patterns) from the image. Some initial features are edges, shapes, and textures. With further iterations of the algorithm, it can detect more advanced features.
High-Level Understanding—The final stage of the process is high-level understanding. Here, the extracted features are subjected to inference to interpret the image. The output is based on the specific task performed, such as classification, detection, or another.
Tasks in Computer Vision
- Image Classification—Image classification categorizes an image into several predefined categories/classes. This is a supervised task, as the model inputs the images and their labels. For example, an image classification algorithm trained to recognize flowers can classify images such as ‘sunflowers,’ ‘pansies,’ or ‘daffodils.’
 Image Classification of Flowers.png
Image Classification of Flowers.png
Image Classification of Flowers (Source)
- Object Detection—Object detection identifies and locates what object is in the image. The model requires input as images along with the type (class) of the object to be detected and its coordinates. So, instead of simply saying that an image contains a dog and a cat, object detection shows where they are located in the image. The algorithm can also detect multiple objects at the same time.
 Object Detection of Animals.png
Object Detection of Animals.png
Object Detection of Animals (Source)
- Semantic Segmentation—Semantic segmentation labels each pixel in an image with a specific class. Unlike object detection, which focuses on bounding boxes around objects, semantic segmentation provides a detailed understanding of the scene. For example, in the case of autonomous driving, it might not be enough just to give a bounding box on the lanes, sidewalks, and obstacles; instead, we want a clear marking that can finely segregate the boundaries of objects.
 Semantic Segmentation for Autonomous Driving.png
Semantic Segmentation for Autonomous Driving.png
Semantic Segmentation for Autonomous Driving (Source)
- Instance Segmentation—Instance segmentation is an extension of semantic segmentation that differentiates between multiple instances of the same object class. For example, in an image with several cars, instance segmentation would not only label all the vehicles but also distinguish between individual cars, assigning a unique label to each one.
 Instance Segmentation of Cars.png
Instance Segmentation of Cars.png
Instance Segmentation of Cars (Source)
- Keypoint Detection—Keypoint detection identifies specific points of interest within an object, such as the corners of a box or the joints in a human body. This technique is often used in applications like facial recognition, where detecting key facial features like eyes, nose, and mouth is necessary for accurate identification. This technique can also be used for object tracking wherein the key points define the objects, and their trajectory can be monitored, such as in the application of action recognition.
 Keypoint Detection for Facial Recognition.png
Keypoint Detection for Facial Recognition.png
Keypoint Detection for Facial Recognition (Source)
Computer Vision Techniques and Models
Computer vision models in the context of Deep Learning are the algorithms designed to process and analyze visual data such as images or videos. They require a large amount of training data, an architecture for feature extraction, and an inference pipeline to solve computer vision problems such as image classification, object detection, and so on when presented with new data. Let’s explore some of the most popular computer vision models.
Convolutional Neural Networks (CNNs)
Convolutional Neural Networks (CNNs), released in the late ’90s, were one of the most popular computer vision models in deep learning that revolutionized image classification and feature extraction. They work by applying convolutional filters to input images, which helps hierarchically extract features from simple features in earlier layers, such as colors and edges, to identify larger elements in subsequent layers, leading to the identification of the target object.
 Convolutional Neural Network Architecture.png
Convolutional Neural Network Architecture.png
Convolutional Neural Network Architecture (Source)
Object Detection Models
Various object detection models are available in the market but differ based on their computational efficiency, real-time analysis, and accuracy. The ones below are the most commonly used.
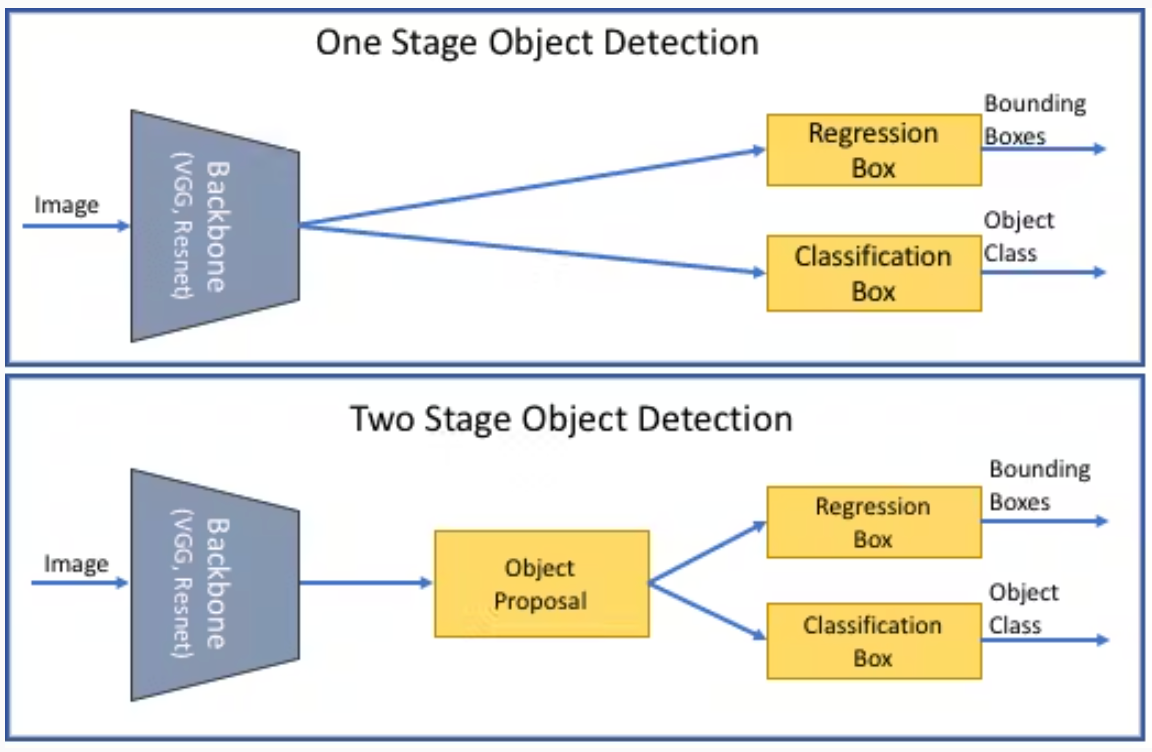 Difference between One and Two Stage Object Detection.png
Difference between One and Two Stage Object Detection.png
Difference between One and Two Stage Object Detection (Source)
YOLO (You Only Look Once)— YOLO processes the entire image in a single pass, simultaneously predicting bounding boxes and class probabilities. This approach makes YOLO exceptionally fast and suitable for real-time applications like autonomous driving. However, its speed can come at the cost of accuracy, particularly with small or densely packed objects.
Faster R-CNN— Faster R-CNN is a two-stage detector that generates region proposals and then refines these proposals to classify and locate objects. Due to the two-stage process, this model is slower than YOLO but it achieves high accuracy in complex scenes. Faster R-CNN is ideal for applications where precision is more critical than speed.
SSD (Singleshot Multibox Detector)— Like YOLO, SSD processes the image in a single pass but uses multiple feature maps at different scales to detect objects of various sizes. SSD is faster than Faster R-CNN but generally more accurate than YOLO, making it suitable for scenarios that require both efficiency and reliability.
RetinaNet— RetinaNet is a one-stage detector like YOLO and SSD but addresses the class imbalance challenge with a novel focal loss function. This approach makes it particularly effective for detecting small objects in cluttered environments. RetinaNet offers a good balance between speed and accuracy.
Image Segmentation Models
Image segmentation models partition the image into segments, each corresponding to a given object class to be predicted in the image. There are three main types of image segmentation models.
Semantic Segmentation—A class label is assigned to every pixel in the image.
Instance Segmentation—It labels each pixel and differentiates between different instances of the same object class.
Panoptic Segmentation—This technique combines semantic segmentation and instance segmentation. It provides a unified output in which each pixel is classified and, if applicable, assigned an instance ID.
Some popular image segmentation models are U-Net, FCNs, Mask R-CNN, and DeepLab.
Generative Models
Unlike discriminative models, which focus on predicting labels or classes based on input data, generative models aim to understand and capture the underlying distribution of the data, allowing them to create new samples that are similar to the original data. Some common generative models are Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), Autoregressive models, and Flow-based models. These models can be applied to image synthesis (creating realistic images), super-resolution (enhancing image quality), style transfer (applying artistic styles to images), and data augmentation (generating additional training data).
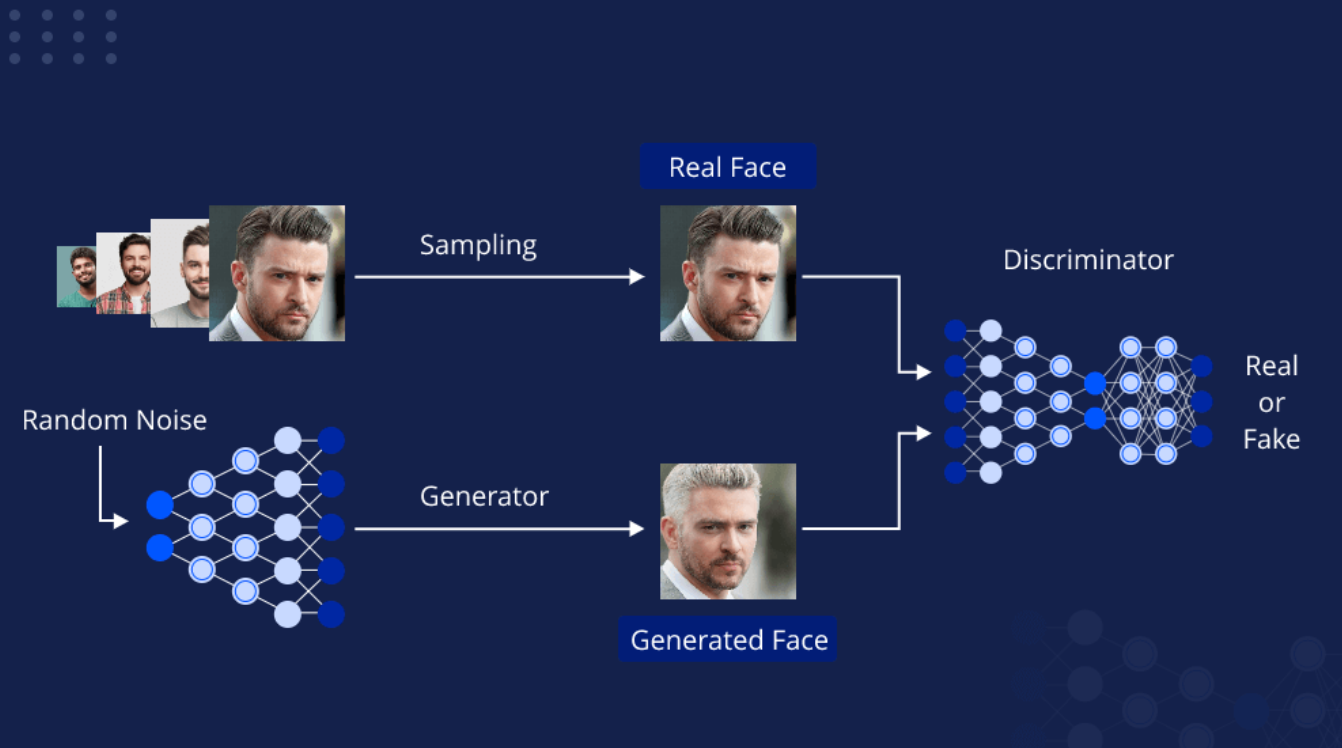 Basic Pipeline of GANs.png
Basic Pipeline of GANs.png
Basic Pipeline of GANs (Source)
Feature Extraction Models
Feature extraction models are the backbone of any computer vision pipeline. These models capture the input data's essential characteristics (features) for subsequent downstream computer vision task processing. They help reduce the dimensionality of the input data, enhance relevant information, and make the systems more robust. Some popular traditional feature extraction methods are SIFT (Scale-Invariant Feature Transform), SURF (Speeded-Up Robust Features), and HOG (Histogram of Oriented Gradients). While these models required manual tuning and couldn’t capture complex patterns, deep learning models such as CNNs came to the rescue. Currently, to extract features for new tasks with limited data, pre-trained CNN models such as VGGNet, ResNet, and Inception can be leveraged for finetuning on the new dataset.
Object Tracking Models
Object tracking models monitor and follow objects as they move across video frames. These models continuously update the object's position, maintaining its identity over time despite changes in appearance, scale, or background. It typically starts with an object detection phase, where the object is identified in the first frame. The tracking model then predicts the object's location in subsequent frames, often using techniques like optical flow, Kalman filters, or deep learning-based trackers. These models are applicable for surveillance, autonomous vehicles, sports analytics, augmented reality, etc.
3D Vision Models
3D vision models are algorithms that interpret and reconstruct three-dimensional structures from two-dimensional images or video. These models enable machines to perceive depth, shape, and spatial relationships, allowing them to understand the world in three dimensions. They use techniques like stereo vision (combining two or more images from different angles), structure from motion (inferring 3D structure from motion cues in videos), and depth estimation (predicting the distance of objects from the camera). Some applications of 3D vision models are in autonomous vehicles, robotics, augmented reality, and medical imaging.
 Simple 3D Vision Model Visualization.png
Simple 3D Vision Model Visualization.png
Simple 3D Vision Model Visualization (Source)
Vision Transformers
Vision Transformers (ViTs) apply transformer architectures, originally designed for natural language processing (NLP), to image analysis. Unlike traditional CNNs, ViTs process images as sequences of patches, treating each patch similarly to a word in a sentence. They divide an image into fixed-size patches, flatten them, and then linearly embed them into vectors. These vectors, along with positional encodings, are fed into a standard transformer model. ViT models have shown remarkable performance for computer vision tasks compared to CNNs; as a result, they are currently state-of-the-art models. There are three main types of ViT models: Standard ViTs, Hybrid models (CNNs and transformers combined), and DeiT (Data-efficient Image Transformers), which require less training data to achieve high performance.
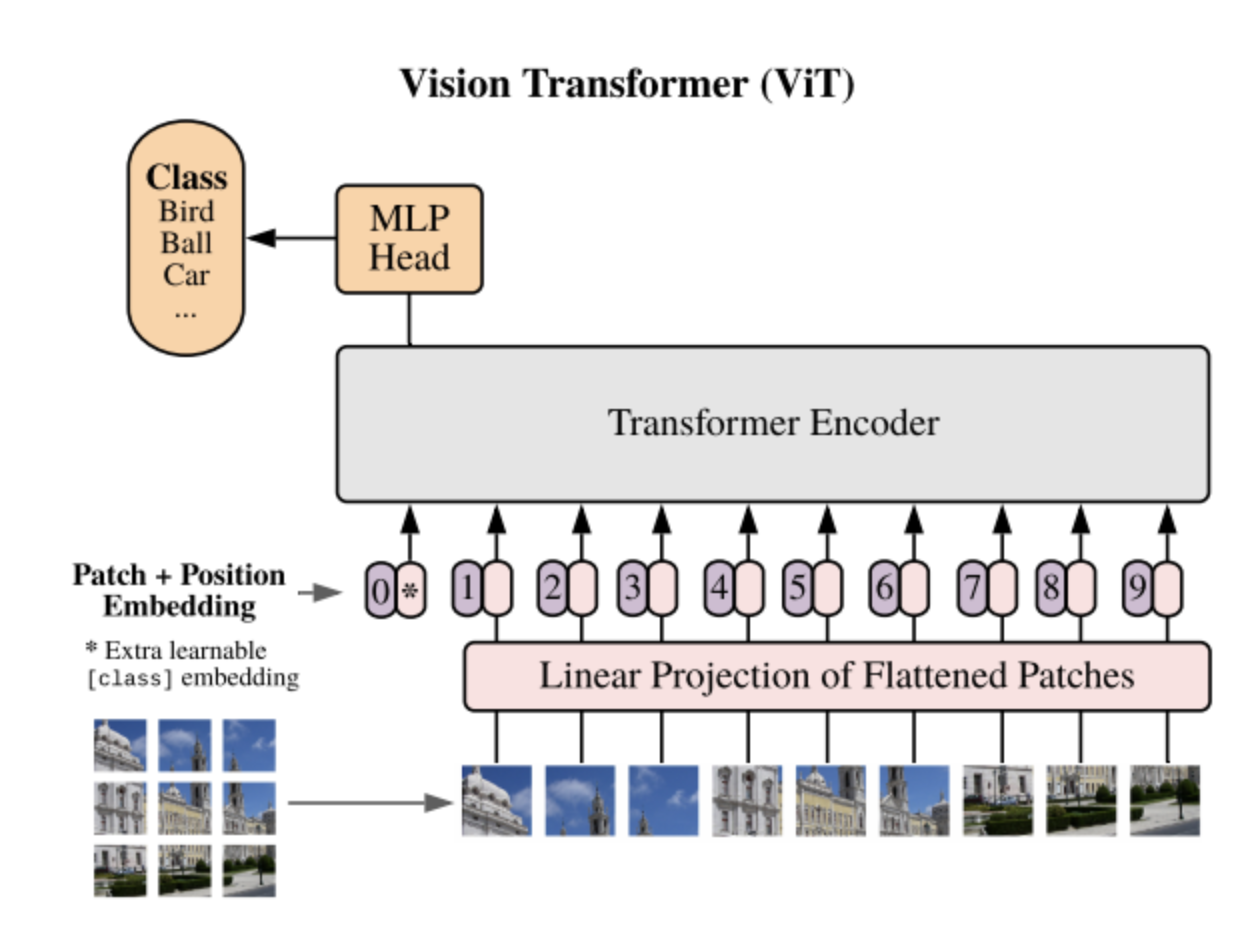 ViT Architecture.png
ViT Architecture.png
ViT Architecture (Source)
Efficient Image Search with Vision Transformers and Vector Databases
Efficient image search requires finding images similar to a query image within a vast dataset, a process crucial for applications like visual search engines, digital asset management, and content recommendation systems.
Vector databases such as Milvus and Zilliz Cloud (the fully managed Milvus) play a key role in this image search process by storing images as high-dimensional vectors—numerical representations of features extracted from images using advanced computer vision models. These vectors capture the essential characteristics of the images, enabling the database to efficiently retrieve similar images by comparing the distances between vectors in the high-dimensional space.
Vision Transformers (ViTs) enhance this process by dividing images into patches and using self-attention mechanisms to capture global relationships between these patches. After processing, ViTs output a feature vector that represents the entire image. When an image is input into the system, the ViT generates its feature vector, which is then stored in the vector database.
To retrieve similar images, the query image is processed by the ViT to generate its feature vector. The vector database then compares this query vector to the vectors of all stored images, retrieving the most similar ones based on their proximity in the vector space. This approach ensures highly accurate and efficient image retrieval, even in large datasets, by leveraging the powerful feature extraction capabilities of ViTs.
By combining ViTs with vector databases, organizations can achieve faster, more accurate image search capabilities, significantly improving the performance of various image-based applications across industries.
Summary
Computer vision is a transformative field that allows machines to interpret and understand visual information from the world. Computer vision systems replicate human vision functions and automate various processes by performing tasks like image classification, object detection, and image segmentation. The field has evolved significantly, starting with foundational models like CNNs, Faster R-CNN, and U-Net. Today, advanced approaches such as generative models, 3D vision models, and Vision Transformers (ViTs) are reshaping how visual data is processed and analyzed. Additionally, integrating advanced computer vision techniques like ViT with vector databases unlocks powerful applications that benefit various industries.
Recommended Readings
 Yesha Shastri
Yesha ShastriYesha Shastri, Freelance Technical Writer in AI/ML
- Introduction
- What Exactly is Computer Vision?
- How Computer Vision Works
- Computer Vision Techniques and Models
- Efficient Image Search with Vision Transformers and Vector Databases
- Summary
- Recommended Readings
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
We can easily implement the BM25 algorithm to turn a document and a query into a sparse vector with Milvus. Then, these sparse vectors can be used for vector search to find the most relevant documents according to a specific query.
A Beginner's Guide to Understanding Vision Transformers (ViT)
Vision Transformers (ViTs) are neural network models that use transformers to perform computer vision tasks like object detection and image classification.

What is Object Detection? A Comprehensive Guide
Object detection is a computer vision technique that uses neural networks to classify and locate objects, such as humans, buildings, or cars, in images or video.