




Classification in Machine Learning: Everything You Should Know

Classification in Machine Learning: Everything You Should Know
What is Classification?
Classification is a supervised machine learning approach that categorizes data into predefined classes. Given an input, a classification model predicts the category or label the input belongs to. It’s one of the most common tasks in machine learning and is used in many real-world applications, from email spam detection to medical diagnoses.
For example, if you have a dataset of emails, a classification model can learn to label each email as either "spam" or "not spam."
How Does Classification Work?
In classification, a machine learning model is trained on a dataset to categorize data into predefined classes based on input features. The model is trained using a labeled dataset, where each input is associated with an output label. The model learns the patterns in the data during training and uses those patterns to predict the labels for new, unseen data.
For example, imagine you are tasked with classifying whether an email is spam. During the training phase, the model is fed emails along with their labels (“spam” or “not spam”). It analyzes features like the presence of certain keywords or the sender's address to identify patterns. After the model is trained, it analyzes the same features and predicts whether it belongs to the “spam” or “not spam” category when a new email arrives.
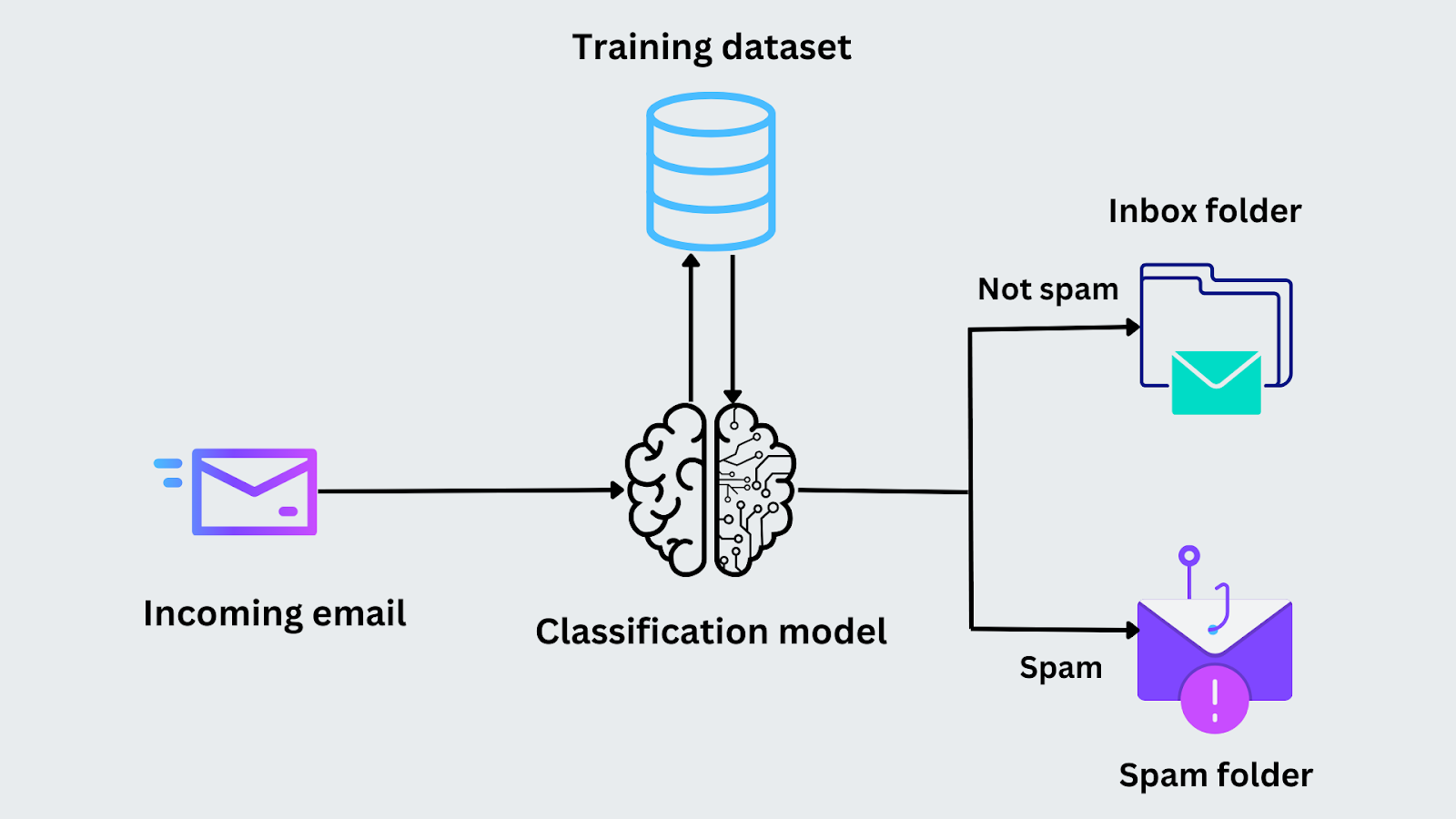 Figure- Email classification process.png
Figure- Email classification process.png
Figure: Email classification process
Types of Classification
Classification problems come in different forms depending on the nature of the data and the number of classes. Here are the most common types:
Binary Classification
Binary classification is when there are only two possible classes or outcomes. The model predicts which of the two categories the input belongs to. A classic example is email spam detection. The model must decide if an incoming email is either "spam" or "not spam." Since there are just two options, this is a binary classification task.
Multiclass Classification
In multiclass classification, the model predicts one label from more than two possible categories. Each input is assigned to exactly one class. A good example is image recognition, where the model might classify an image as "cat," "dog," or "bird." Unlike binary classification, the model deals with several distinct classes and must identify the correct one for each input.
Multilabel Classification
Multilabel classification is where each input can belong to multiple classes simultaneously. For instance, when tagging a photo, it could be labeled with "sunset," "beach," and "people" simultaneously. Each tag represents a different class, and the model learns to predict all relevant labels for an input. This differs from multiclass classification because multiple labels can be assigned to the same input.
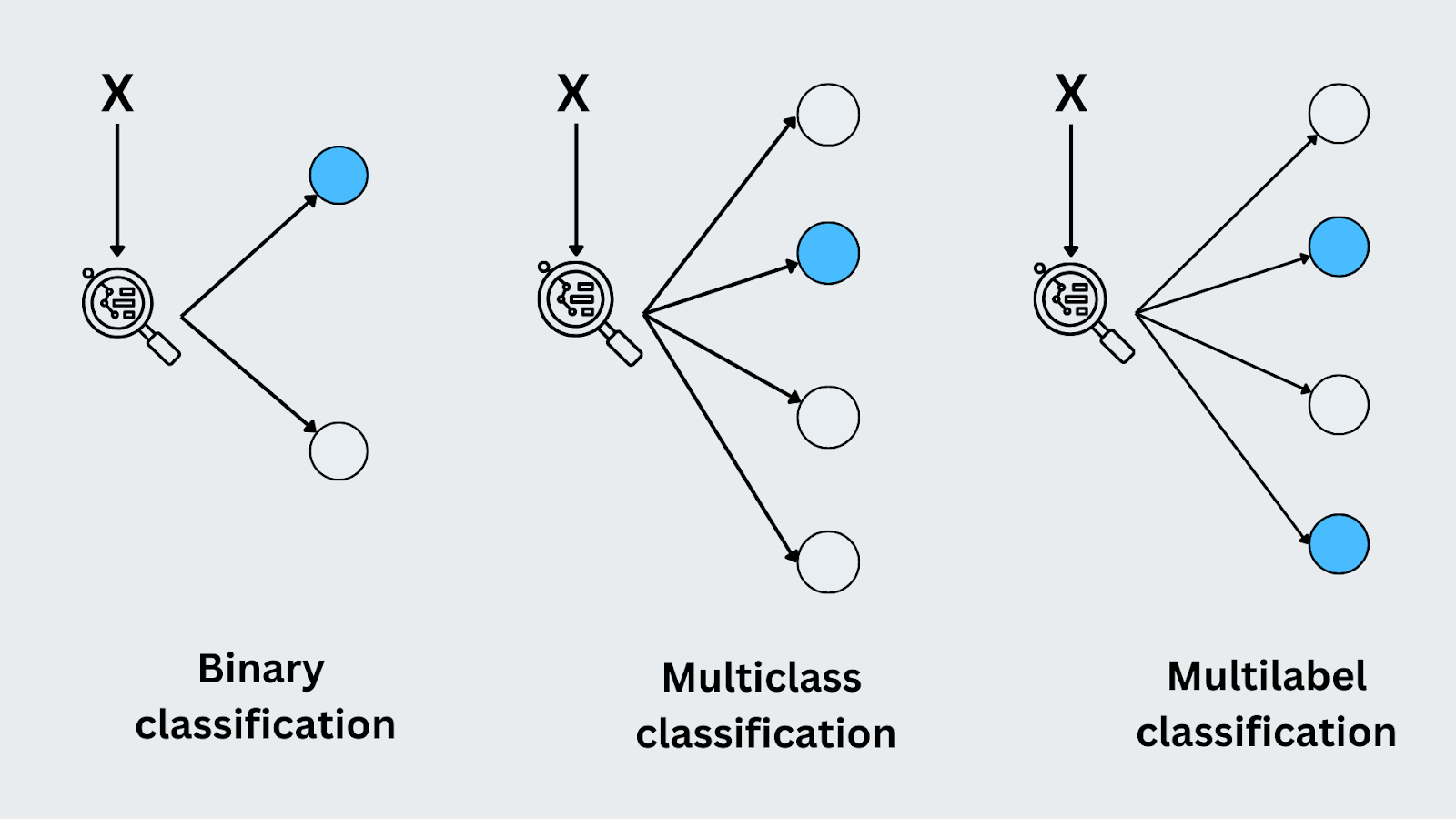 Figure- Types of classification.png
Figure- Types of classification.png
Figure: Types of classification
Learners in Classification Algorithms
In machine learning, classification algorithms can be categorized based on how they generalize from the training data. These are Lazy Learners and Eager Learners. The distinction between these two types lies in when and how they process the data for making predictions.
Lazy Learners
Lazy learners are algorithms that delay generalization until they receive a prediction query. They don’t build a model during the training phase; instead, they store the training data and only perform computations when a new input needs to be classified.
Example Algorithms: k-Nearest Neighbors (k-NN), Case-based Reasoning (CBR).
Eager Learners
Eager learners, in contrast, try to build a general model immediately during the training phase. They analyze the training data, learn the underlying patterns, and then discard the training data. Once the model is built, it can quickly predict new data.
Example Algorithms: Decision Trees, Random Forest, Support Vector Machines (SVM), Logistic Regression.
| Aspect | Lazy Learners | Eager Learners |
| Model Creation | No model is built during training; it memorizes data. | Generalizes the data into a model during training. |
| Training Time | Short training time; doesn’t build a model. | Longer training time; builds a model based on data. |
| Prediction Time | It makes slower predictions as it processes data at query time. | Faster predictions, as the model is pre-built. |
| Memory Requirement | Higher memory requirement; stores the whole dataset. | Lower memory requirement; only stores model parameters. |
| Example Algorithms | k-NN, Case-based Reasoning | Decision Trees, Logistic Regression, Random Forest |
Table: Lazy learners vs Eager learners
Classification Algorithms
Now, let’s discuss some commonly used classification algorithms.
Logistic Regression
Logistic regression uses probability only to predict the label in a binary classification task. Unlike linear regression, which predicts continuous values, logistic regression predicts probabilities for two classes by mapping outputs to a range between 0 and 1 using the logistic function (sigmoid). It’s widely used for cases with binary outcomes, like yes/no or 0/1 scenarios.
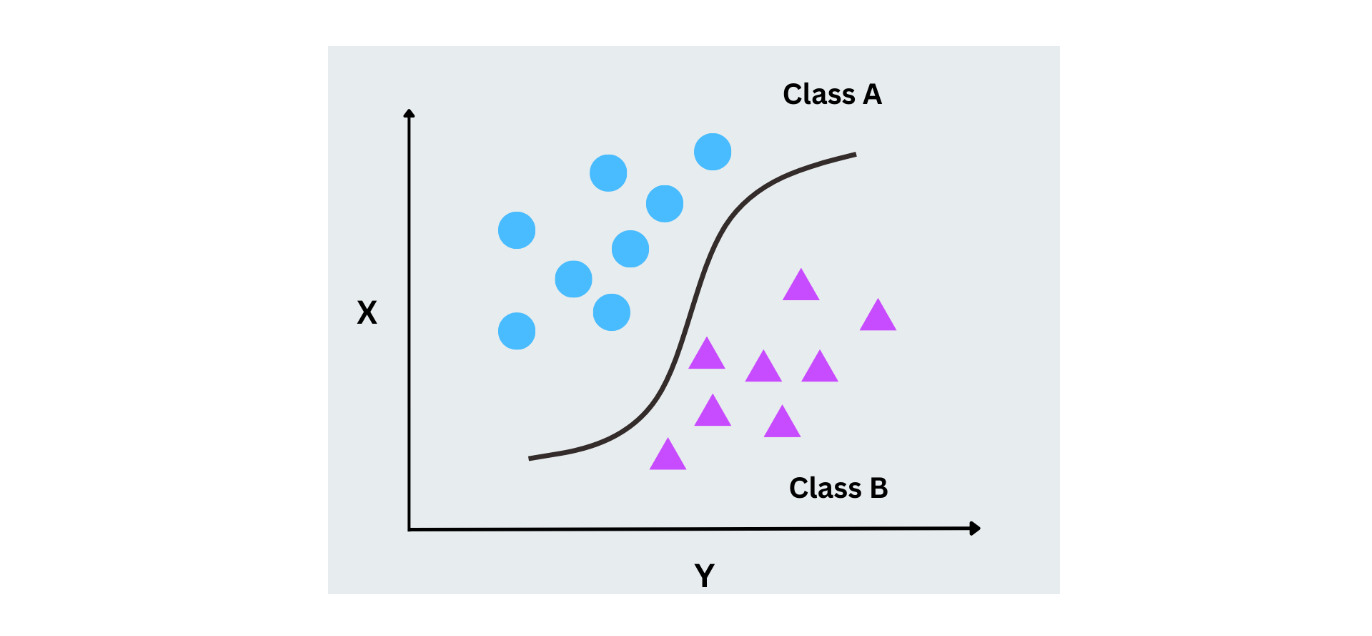 Figure- Logistic regression working.png
Figure- Logistic regression working.png
Figure- Logistic regression working
Decision Trees
A decision tree is a model that splits the data based on feature values, creating branches for each possible decision. Each node represents a feature, and branches represent decisions based on that feature's value. The process continues until the algorithm decides on the predicted class's leaf nodes. Decision trees are easy to interpret and can handle binary and multiclass classification tasks.
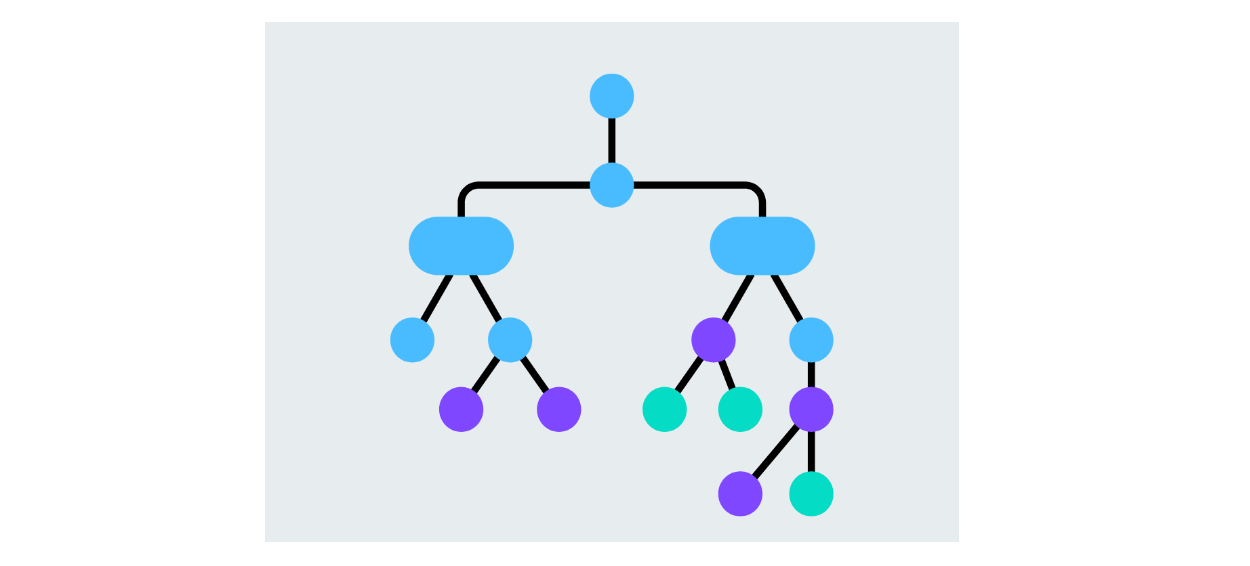 Figure- Decision tree structure.png
Figure- Decision tree structure.png
Figure: Decision tree structure
Random Forest
Random forest improves upon decision trees by constructing multiple trees and combining their predictions. Each tree in the forest is built from a random subset of the data and features. The final prediction is made by averaging the results (for regression tasks) or by majority voting (for classification tasks). This helps reduce overfitting and increases accuracy.
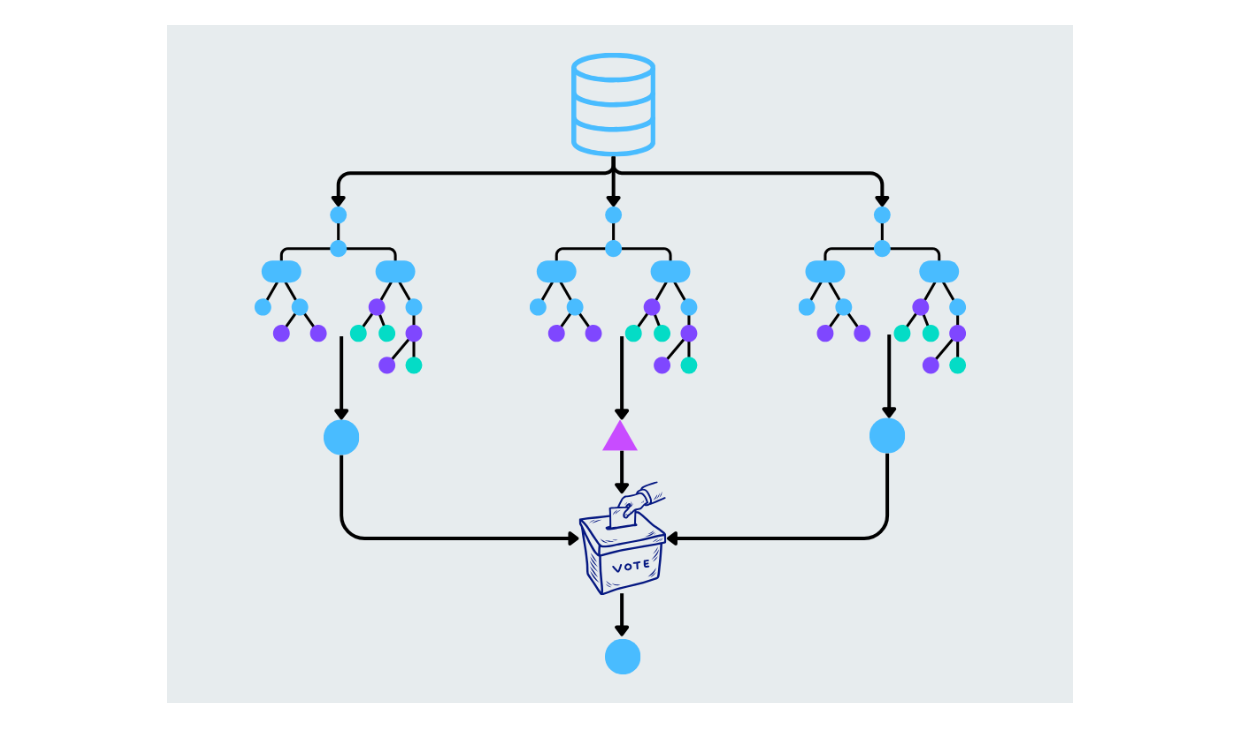 Figure- Random forest working.png
Figure- Random forest working.png
Figure: Random forest working
Support Vector Machines (SVM)
Support vector machines work by finding the optimal hyperplane that separates data points from different classes. This hyperplane is a line in two dimensions, but SVMs can also handle high-dimensional data. The key idea is to maximize the margin between each class's closest data points (support vectors). SVMs work well for binary and multiclass classification problems, especially when the data is not linearly separable.
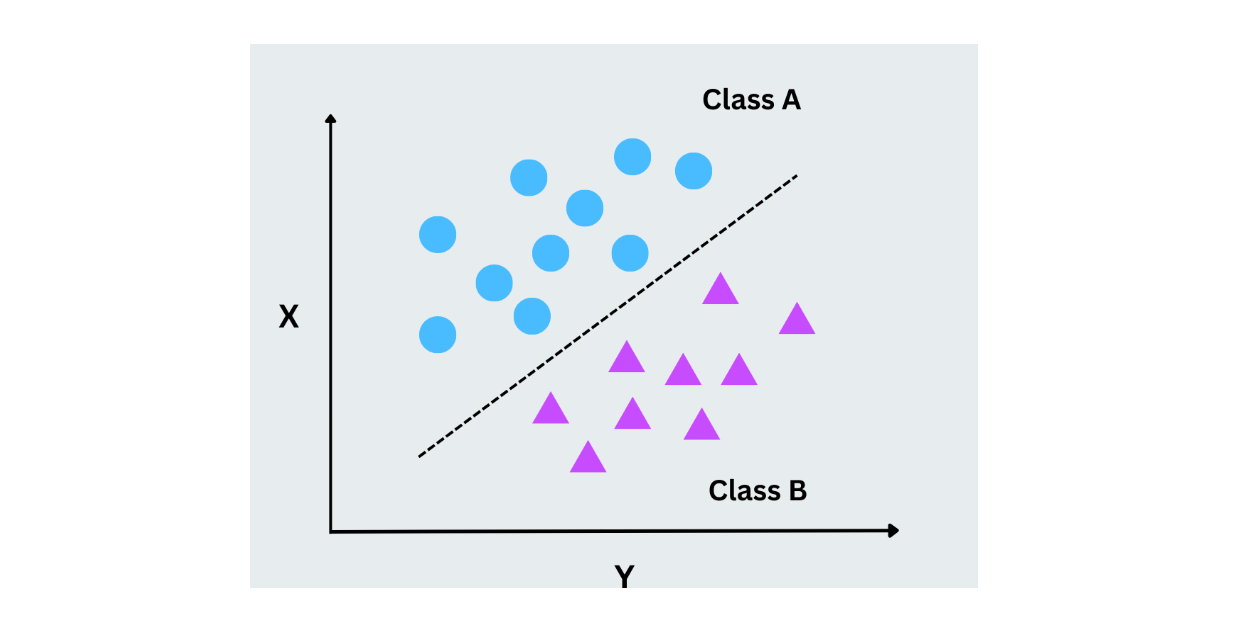 Figure- SVM working.png
Figure- SVM working.png
Figure- SVM working
k-Nearest Neighbors (k-NN)
The k-NN algorithm classifies data points based on the classes of the k nearest neighbors. When introducing a new data point, the algorithm looks at the k closest points (based on a similarity metric like Euclidean distance) and assigns the new point the majority class. It’s a simple, instance-based learning algorithm useful for smaller datasets.
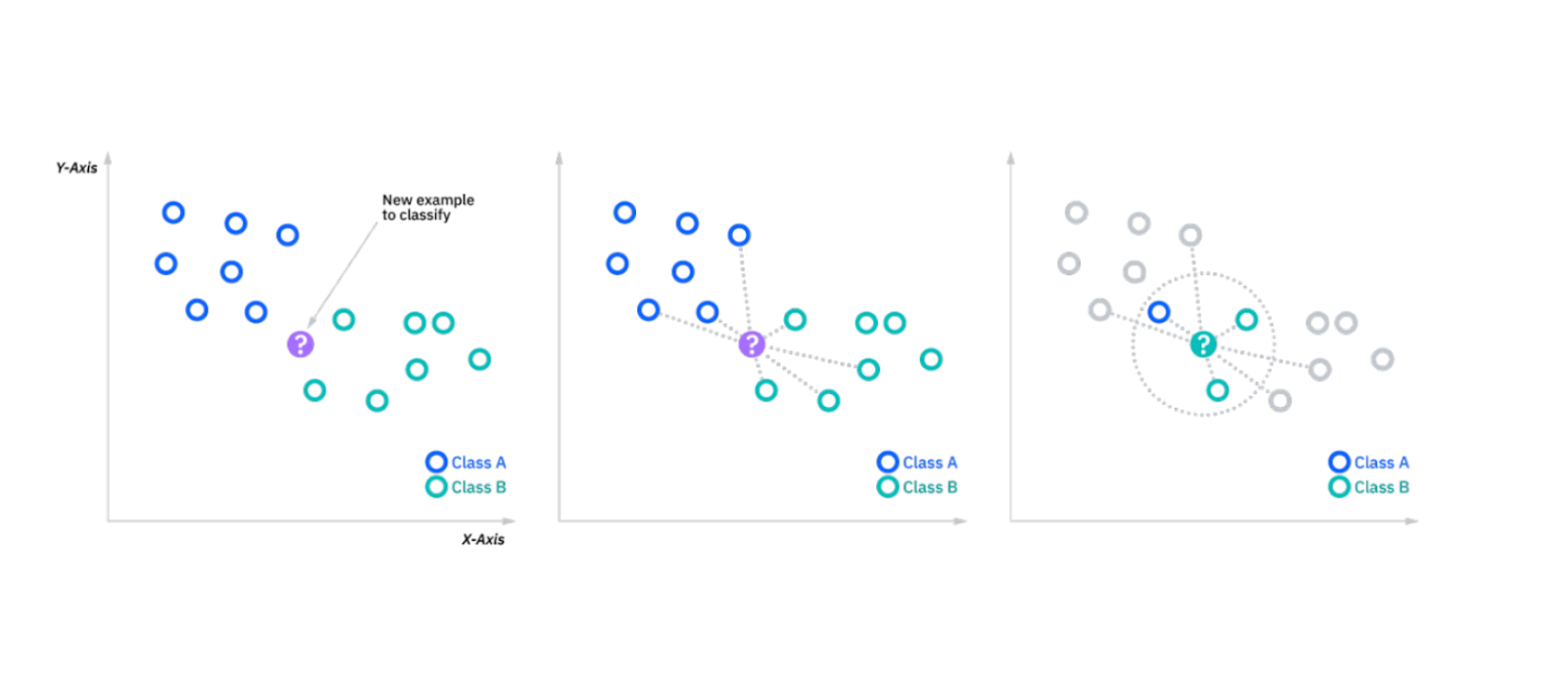 Figure- kNN algorithm working.png
Figure- kNN algorithm working.png
Figure: kNN algorithm working
Naive Bayes
Naive Bayes is based on Bayes’ Theorem and assumes that the features in the data are independent of each other (hence the term "naive"). Despite this assumption, it performs well on various real-world tasks, especially when the data has categorical features. It works by calculating the probability of each class given the input and assigning the class with the highest probability.
P(C|X) = P(X|C) . P(C)P(X))
Here, P(C∣X) is the posterior probability of the class given the input, P(X∣C) is the likelihood of the input given the class, P(C) is the prior probability of the class, and P(X) is the probability of the input. Naive Bayes selects the class with the highest posterior probability for classification based on the observed features.
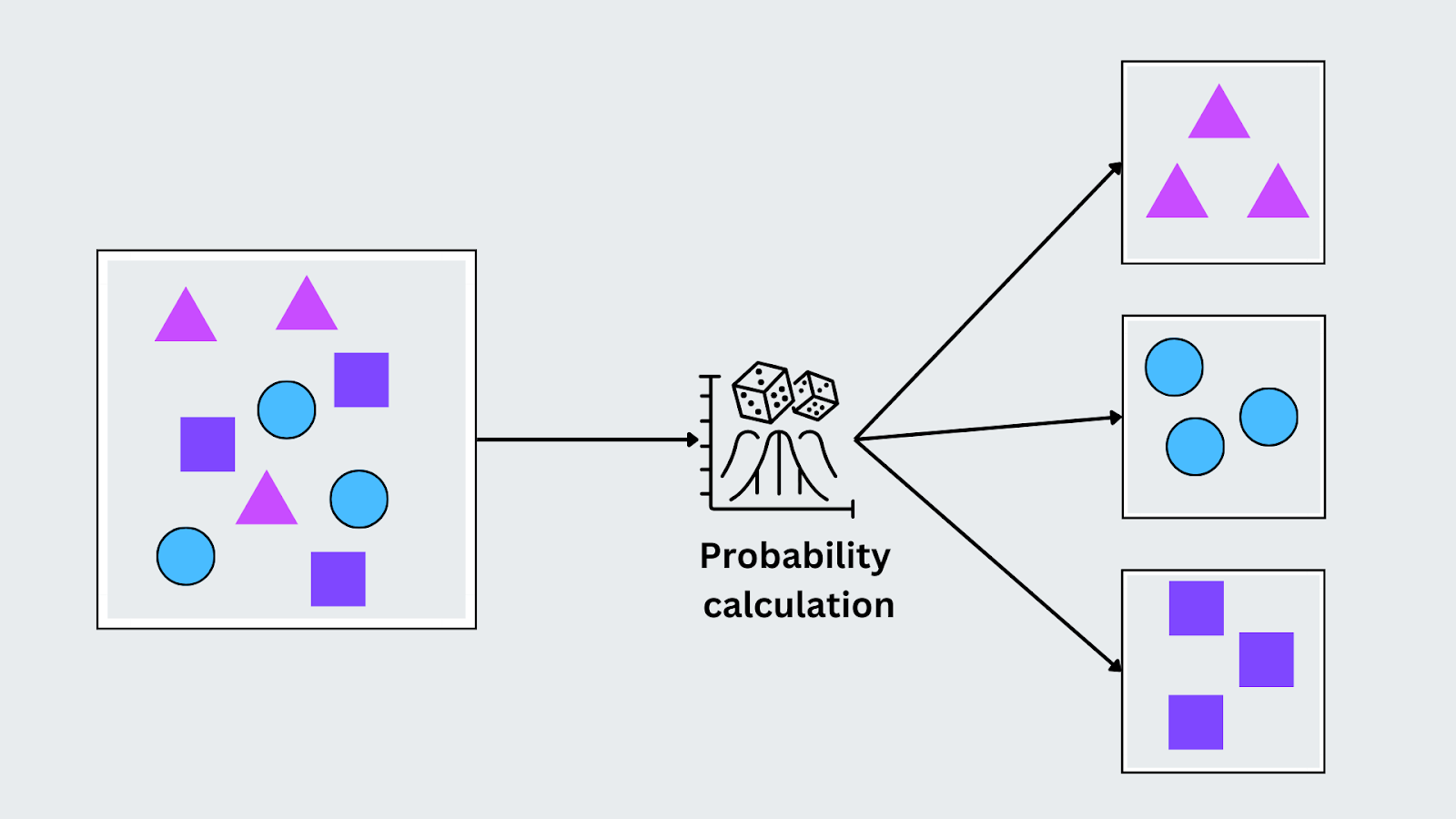 Figure- Naive Bayes algorithm working.png
Figure- Naive Bayes algorithm working.png
Figure: Naive Bayes algorithm working
Evaluation Metrics in Classification
Accuracy
Accuracy is the simplest metric and measures how often the model's predictions are correct. It is determined by dividing the number of correctly predicted cases by the total number of cases.
Formula:
Accuracy = (True positives + True Negatives)/Total number of instances
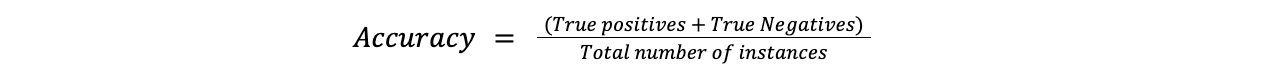 accuracy.png
accuracy.png
Precision
Precision measures how many of the predicted positive instances are truly positive. Precision is important in situations where false positives are costly. For example, predicting a normal transaction as fraudulent in fraud detection can lead to customer dissatisfaction.
Formula:
Precision = True positives/(True positives + False positives)
 precision.png
precision.png
Recall
Recall measures the proportion of positive cases accurately identified as positive. Recall is useful in cases where missing a positive instance is costly. For example, missing a diagnosis (false negative) is far more problematic in disease detection than a false alarm.
Formula:
Recall = True positives/(True positives + False negatives)
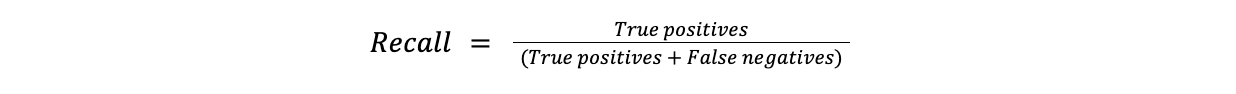 recall.png
recall.png
F1-Score
F1-Score is the harmonic average of precision and recall. It’s useful when there’s a need to balance precision and recall, specifically when one is more important than the other.
Formula:
F1Score = 2x(Precision x Recall)/(Precision + Recall)
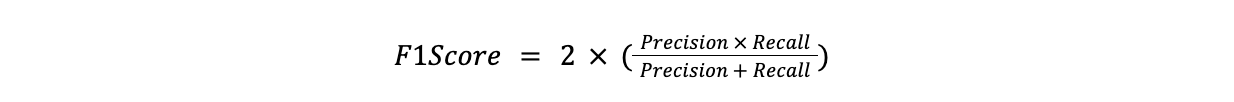 FI score.png
FI score.png
Real-World Use Cases of Classification
Classification models are widely used across various industries to solve real-world problems. Here are some practical examples:
Medical Diagnosis: Machine learning models help doctors classify patient data such as "disease" or "no disease." For instance, models are used to predict whether a patient has diabetes based on medical records.
Sentiment Analysis: Companies use sentiment analysis to understand customer feedback. For example, a model can analyze product reviews and classify them as positive, negative, or neutral, helping businesses improve their offerings based on customer sentiment.
Fraud Detection: Banks and financial institutions use classification models to detect fraudulent transactions. The model learns patterns from transaction data and classifies each as "fraudulent" or "legitimate" to prevent financial losses.
Object Recognition in Images: Object recognition models identify specific image items in industries like manufacturing and security. For instance, a model can classify pictures of products on an assembly line, ensuring that only correctly assembled items pass inspection.
Facial Recognition: Facial recognition systems are used in security and authentication. These models classify images of faces to either identify or verify a person’s identity, commonly used in unlocking smartphones, digital attendance systems, or airport security checks.
Voice Recognition: Voice recognition models convert spoken language into text or commands. For example, virtual assistants like Siri or Alexa classify spoken words into commands so users can interact with devices through voice.
Medical Diagnostic Tests: Machine learning models assist in interpreting diagnostic tests such as X-rays or MRI scans. They classify medical images as "normal" or "abnormal," helping radiologists make faster and more accurate diagnoses.
Customer Behavior Prediction: E-commerce platforms use classification models to predict customer behavior. These models classify users as "likely to buy" or "unlikely to buy" to make personalized marketing and product recommendations.
Product Categorization: Retailers use machine learning to automatically classify products such as "electronics," "clothing," or "home goods" based on their descriptions. This streamlines inventory management and improves customer search experiences.
Malware Classification: In cybersecurity, classification models detect and classify malware. By analyzing patterns in software behavior, these models classify programs as "safe" or "malicious" to protect systems from cyber threats.
Common Challenges in Classification
When building classification models, several challenges can arise that affect the model’s performance. Here are three common challenges:
Overfitting
Overfitting means when a model performs well on the training data but fails to generalize to new, unseen data. This happens when the model becomes too complex and starts to capture noise or specific details of the training set rather than the underlying patterns.
Data Imbalance
Data imbalance is when one class significantly outweighs others. For example, in fraud detection, fraudulent transactions may make up only 1% of the data, leading the model to bias heavily toward the majority class. This can result in poor detection of the minority class.
Noise in Data
Noise refers to random errors or irrelevant information in the data that can confuse the model. Noisy data may include mislabeled examples, outliers, or irrelevant features that don’t contribute to the classification task. The presence of noise can reduce the model’s performance and make it harder to detect patterns.
Classification vs. Regression
Classification and regression are both types of supervised learning algorithms, but they are used for different kinds of tasks. Below is a comparison between classification and regression based on various aspects:
| Aspect | Classification | Regression |
| Purpose | Predicts discrete labels or categories. | Predicts continuous numerical values. |
| Output | Categorical: classes like "spam" or "not spam." | Continuous: values like "price" or "temperature." |
| Example Task | Classifying emails as "spam" or "not spam." | Predicting house prices based on their features. |
| Algorithms Used | Logistic regression, Decision trees, Random forest, etc. | Linear regression, Ridge regression, Polynomial regression, etc. |
| Evaluation Metrics | Accuracy, Precision, Recall, F1-score, ROC-AUC, etc. | Mean Squared Error (MSE), R-squared, Mean Absolute Error (MAE). |
| Nature of Target Variable | The target is categorical (e.g., class labels). | Target is continuous (e.g., real numbers). |
| Output Boundaries | Has fixed class boundaries (e.g., 0 or 1 for binary). | No fixed boundary; the output is a range of real numbers. |
| Real-world Use Cases | Spam detection, fraud detection, disease classification. | Predicting sales, stock prices, and weather forecasting. |
| Modeling ComplexiIt can | It can handle both binary and multiclass outputs. | Usually simpler when predicting one continuous value. |
Table: Classification vs Regression
How Milvus Helps in Classification Tasks?
As data volume and complexity grow, traditional methods of managing and querying large datasets can become slow and inefficient. This is where Zilliz, with its high-performance, open-source vector database Milvus, plays a vital role.
Classification tasks, such as image recognition, object detection, video similarity search, spam detection, and recommendation systems, often require handling high-dimensional representations of unstructured data, like text embeddings, image features, or audio vectors. Milvus is specifically designed to efficiently manage and search through these large volumes of vector data.
Benefits of Milvus for Classification
Handling High-Dimensional Data: In classification, models often rely on vectorized data (e.g., word embeddings or image feature vectors) to make predictions. Milvus is optimized to store and manage these vectors to access large datasets quickly during model training and inference.
Fast Similarity Search: Classification models frequently need to find the closest matching data points in a dataset. Milvus accelerates this process by performing fast similarity searches on vector data, making it easier to classify new inputs based on their nearest neighbors.
Scalability for Large Datasets: Milvus ensures that performance remains fast and efficient as classification datasets grow. Milvus scales seamlessly to make the classification tasks run smoothly even with vast amounts of data, whether millions of product vectors, image embeddings, or thousands of image embeddings.
Conclusion
Classification is a machine learning technique for predicting labels or categories for data in various real-world applications, from detecting fraud to recognizing images. Successfully building and deploying classification models requires handling large amounts of data, often high-dimensional vectors. Milvus provides efficient storage, fast retrieval, and scalability for vector data. It enhances the performance of classification tasks through quick similarity searches and scales smoothly as datasets grow. With Milvus, developers can easily handle the challenges of large-scale classification tasks, making it a powerful tool in the machine-learning landscape.
FAQs on Classification
What is classification in machine learning?
Classification in machine learning is the process of predicting a category or label for a given input based on its features. A model is trained using labeled data to learn patterns and then classify new, unseen data into predefined classes, such as "spam" or "not spam."
How does a classification algorithm differ from regression?
Classification algorithms predict categorical outputs (like classes or labels), while regression algorithms predict continuous numerical values. For example, classification can determine if an email is spam, while regression might expect the price of a house.
Why is data preparation important in classification tasks?
Data preparation ensures the input data is clean, structured, and ready for the model to process. It handles missing values, normalizes the data, and selects the most relevant features. Proper preparation improves the model’s accuracy and performance.
How does Milvus help with classification tasks?
Milvus is an open-source vector database that efficiently stores and searches high-dimensional data, such as image or text embeddings. It speeds up classification through its efficient similarity search, which facilitates handling large datasets in tasks like image recognition and recommendation systems.
What are common challenges in classification, and how can they be addressed?
Common challenges include overfitting, data imbalance, and noise in the data. These can be addressed using techniques like regularization, resampling methods (e.g., SMOTE), noise reduction strategies, and scalable infrastructure like Milvus for managing large datasets efficiently.
Related Resources
- What is Classification?
- How Does Classification Work?
- Types of Classification
- Learners in Classification Algorithms
- Classification Algorithms
- Evaluation Metrics in Classification
- Real-World Use Cases of Classification
- Common Challenges in Classification
- Classification vs. Regression
- How Milvus Helps in Classification Tasks?
- Conclusion
- FAQs on Classification
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free