




Introduction to LLM Customization
In recent years, rapid advancements in artificial intelligence have led to the development of large language models (LLMs), revolutionizing the field of natural language processing (NLP). These powerful models, such as ChatGPT, Llama, Mistral, Zephyr, and others, have demonstrated superior capabilities in understanding and generating human-like language.
However, these LLMs have limitations. They are trained on a large amount of data with a specific cut-off date, which means that if we use them to generate answers that require knowledge newer than their training data, we run the risk of getting inaccurate responses. Therefore, it is essential to tailor these models to our specific tasks and domains to unlock their full potential. This is where LLM customization comes into play.
In a recent Zilliz Unstructured Data Meetup in Seattle, the CEO of OSS4AI and Zilliz’s previous Senior Developer Advocate, Yujian Tang, discussed several options for customizing LLMs to enhance their performance on specific tasks. Before discussing the different customization options for an LLM, let's briefly explore the history of LLMs.
Watch the replay of Yujian’s talk
Brief History of LLMs
The research leading to the inception of LLMs has gone a long way, starting from the basic neural network architecture. A basic neural network layer consists of an input layer, one or more hidden layers, and an output layer, as shown in the below graphic.
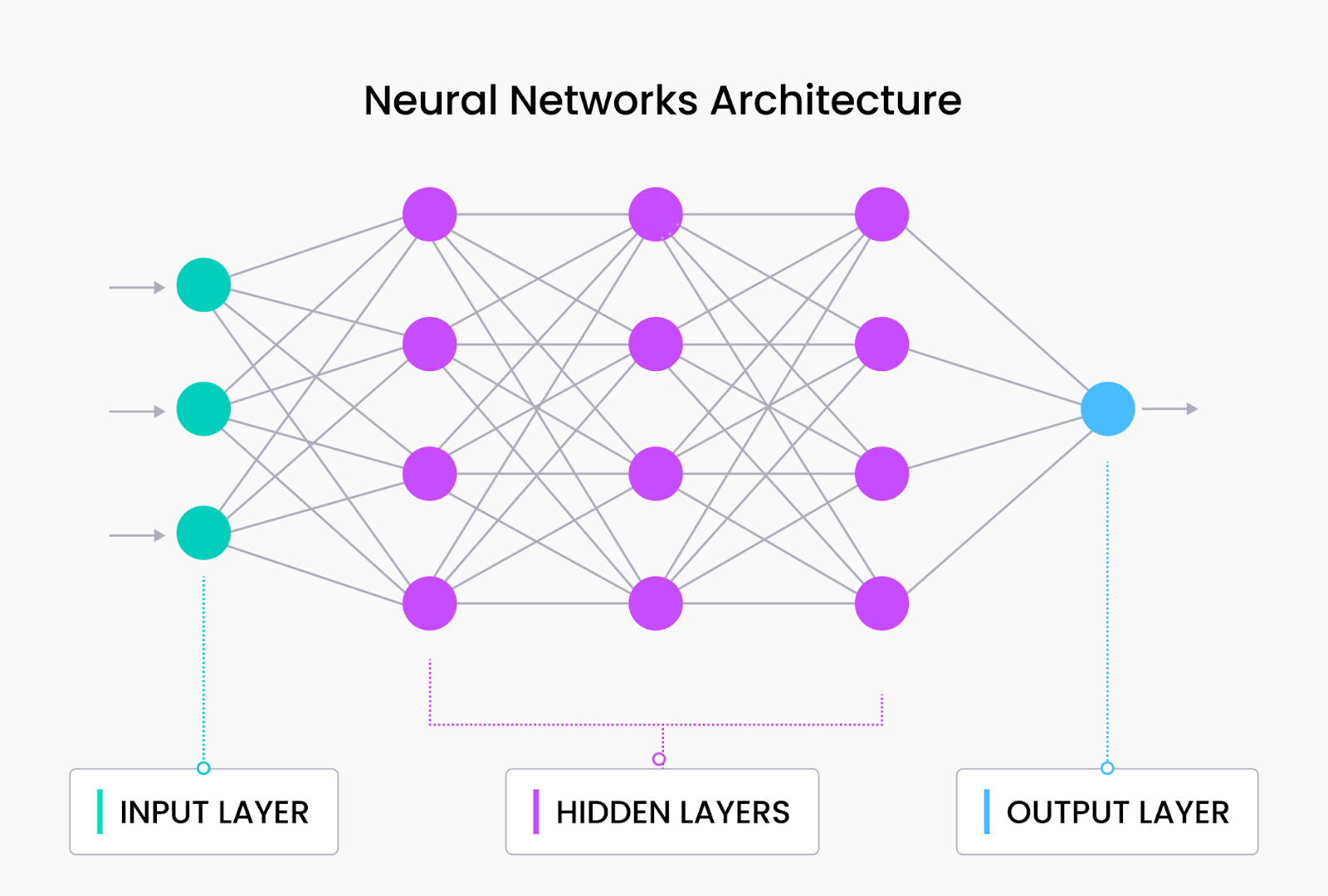 Neural network architecture
Neural network architecture
The basic neural network architecture proved very powerful for classification tasks and can handle unstructured data such as texts and images. However, it is ineffective for tasks requiring long-term dependencies or sequential processing, which is essential for natural language tasks. In basic neural networks, each input is processed independently, and the output is generated based solely on the current input. This means that neural networks don’t consider the order or context of the input concerning the whole sequence.
Without the ability to handle long-term dependencies, a neural network cannot infer the semantic meaning of a whole input sequence or text—the inception of Recurrent Neural Networks (RNNs) aimed to solve this problem.
RNNs address the problem by introducing a hidden state, which acts as a memory that captures information from what the network has previously seen. This hidden state is passed from one time step to the next, allowing the network to maintain a representation of the sequence. Adding a hidden state enables RNNs to selectively remember or forget information from the input sequence, making them more effective for input sequence dependencies than basic neural networks.
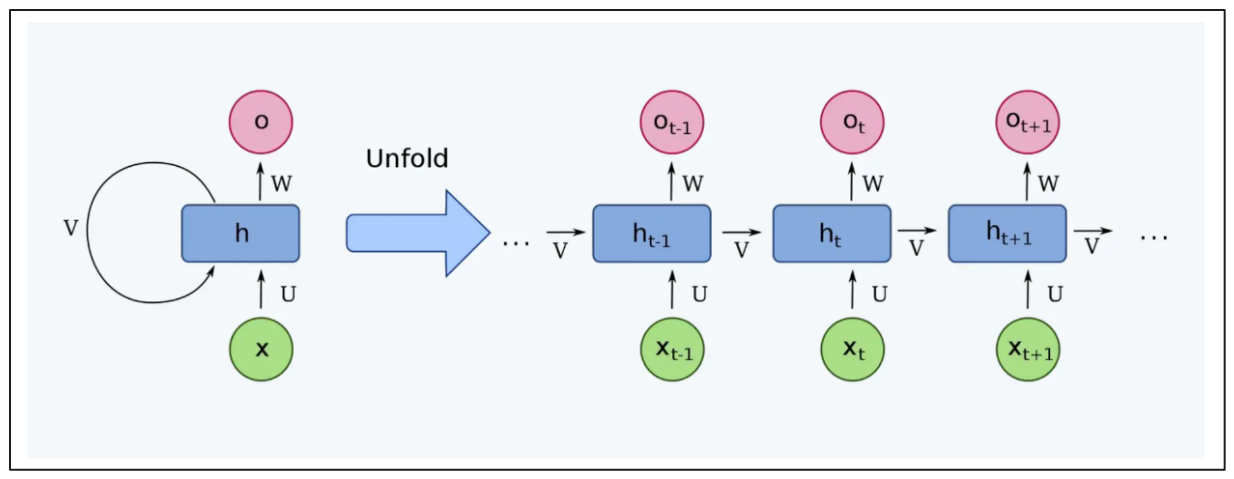 RNN architecture
RNN architecture
However, RNNs also come with several limitations, such as:
Vanishing Gradient Problem: RNNs suffer from the vanishing gradient problem, where the gradients used to update the model's parameters during training become smaller as they are backpropagated through time. This problem makes it difficult for RNNs to learn long-term dependencies in sequences.
Sequential Processing: RNNs process sequences sequentially, limiting their ability to parallelize computation and making them less computationally efficient.
These limitations of RNNs led to the development of Transformer, which uses a self-attention mechanism to process input sequences in parallel and avoid the vanishing gradient problem.
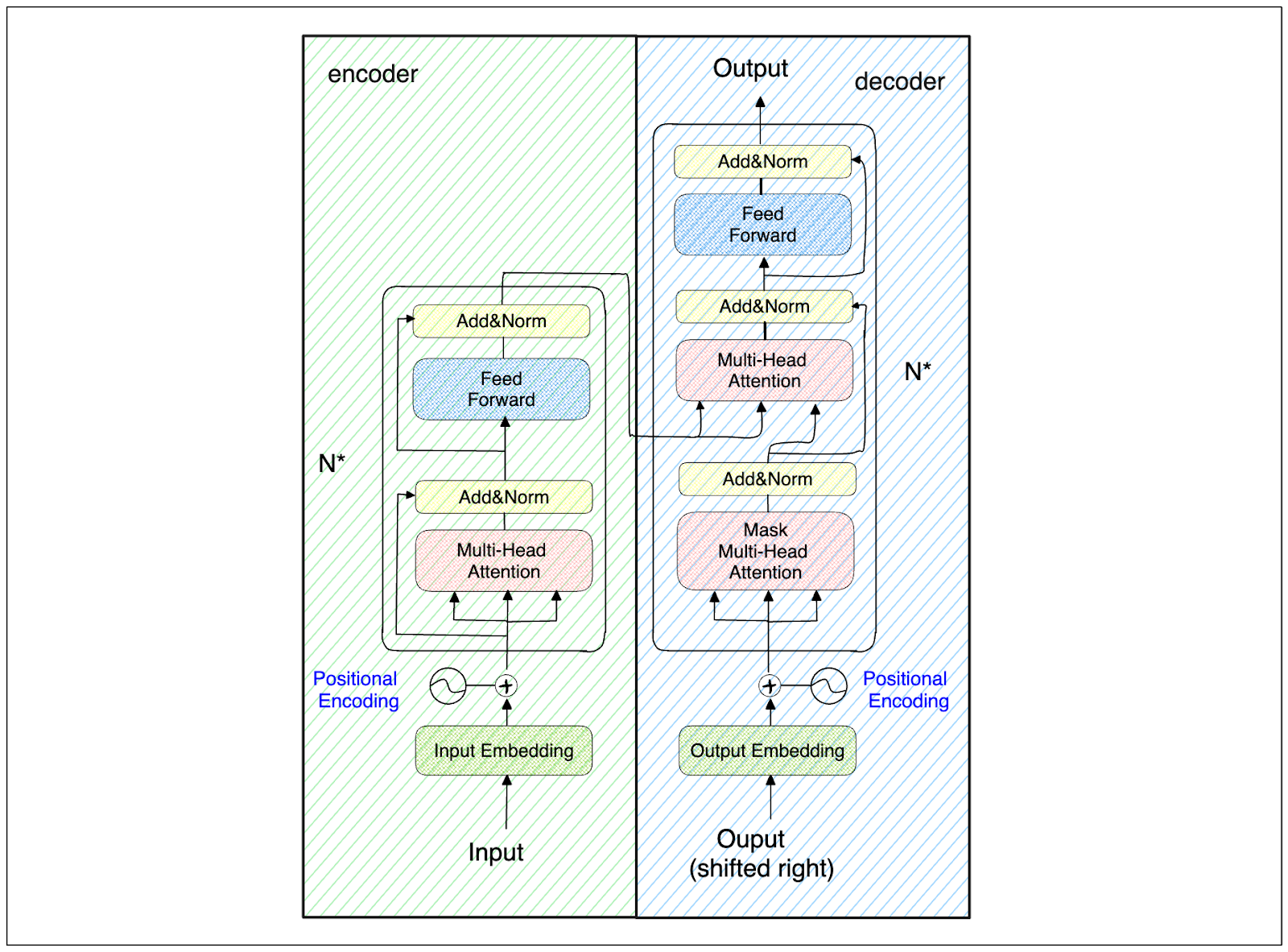 Transformer architecture
Transformer architecture
The Transformer architecture consists of several encoder and decoder blocks. Each encoder and decoder block contains a special layer called the attention layer. This layer plays a crucial role in determining the semantic meaning behind each token with respect to the whole input sequence. For example, consider the following three sentences:
Apple made a profit of $97 billion in 2023
I like to eat apple pie for profit in 2023
Apple’s bottom line increased by record numbers in 2023
If we only use a traditional approach, like a keyword-based approach, the first two sentences will be the most similar pair. We found three similar keywords in these two sentences: Apple, 2023, and profit.
However, we know that the first and third sentences are the most semantically similar pairs. The attention layer inside the Transformer architecture can capture this context and return the first and third as the most semantically similar pair.
Transformers models' powerful performance and versatility led to rapid advancements in AI across different fields, from Computer Vision to NLP and multimodal tasks.
One of the models introduced after Transformers' big success is the Generative Pretrained Transformers (GPT) model. This model uses the decoder part of Transformer architecture to predict the next token in an input sequence and is used as the backbone of many LLMs that we know so far, such as ChatGPT and Llama.
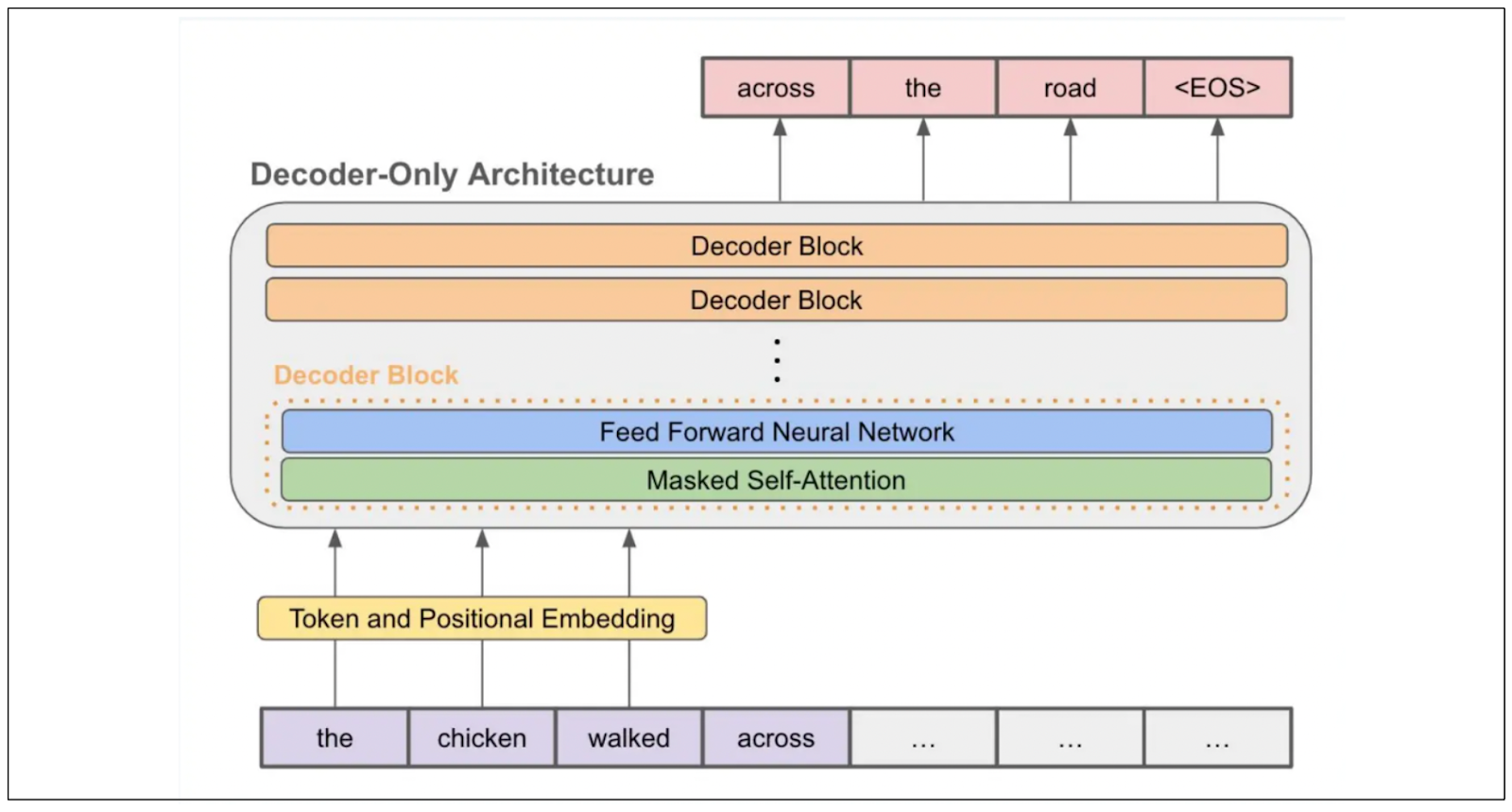 GPT architecture
GPT architecture
These LLMs are very powerful in generating human-like responses, as they’ve been trained on huge amounts of data. However, as you might already know, the training data have a cut-off date, meaning that we won’t get an accurate response from our LLMs if we ask about information newer than their training data. This is where we need to customize our LLMs.
Retrieval Augmented Generation (RAG)
The first way we can customize our LLM is through RAG, and its concept is quite straightforward. We provide LLMs with both the query and relevant contexts as inputs, enabling them to generate contextual and accurate responses by leveraging the contexts provided.
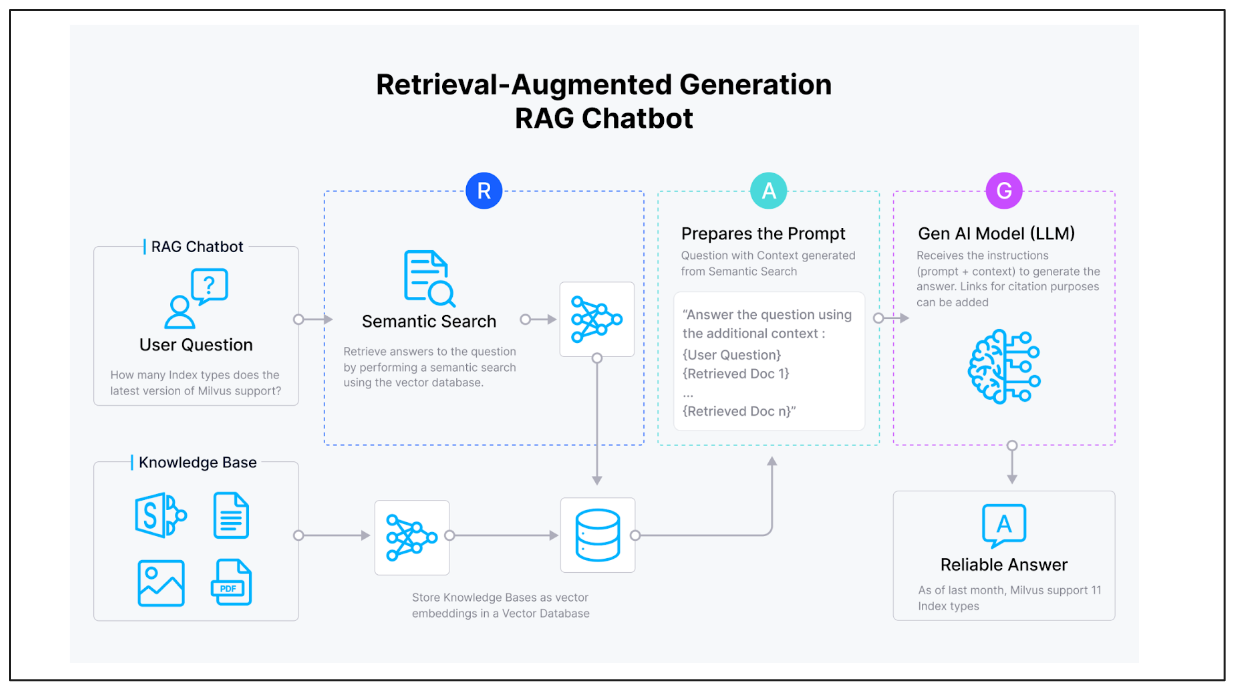 RAG architecture
RAG architecture
To leverage LLMs for RAG, we need two essential components:
Vector Embedding Model: A model that transforms our query and contexts into vector embeddings.
Vector Database: A database to store all context embeddings and perform vector search to provide the most relevant and semantically similar contexts to our LLMs based on the query.
Several models can be used to generate vector embeddings, including deep learning models from OpenAI or sentence transformers. Alternatively, traditional bag-of-words-based models like TF-IDF or BM25 can also be employed.
Milvus is a popular open-source vector database. It stores the necessary data, consisting of two types: vector embeddings generated by the model and their metadata. For example, consider a chunk of text from an article published by Towards Data Science on the first day of June 2023. The data stored in the Milvus vector database might look like this:
 Example of a vector embedding data and its metadata
Example of a vector embedding data and its metadata
The metadata is useful for performing various filters during vector search operations to provide our LLMs with more precise contexts. For example, you might want to fetch contexts from a specific publication or those published after a certain date (e.g., 2020).
Once we have the query and know the specific metadata we want to filter, a vector database like Milvus will perform its job. It’ll perform a vector search to find the most semantically similar contexts to our query that fulfill the metadata filtering conditions.
Fine-Tuning
Another approach to customizing LLMs is through fine-tuning. The concept is straightforward: we train a pre-trained LLM on our own data, resulting in models with new weights tailored to perform tasks specific to our data domain.
There are several ways to fine-tune LLMs:
Full Fine-Tuning: This approach modifies the weights of all parameters within the original LLM. However, it involves a costly computation process.
LORA: This approach introduces low-rank adapters within the LLM architecture. The original weights are frozen during fine-tuning, and only the adapters’ weights are updated.
QLORA: This approach introduces quantization to the original LORA method, reducing computation costs and resources while preserving reasonable performance.
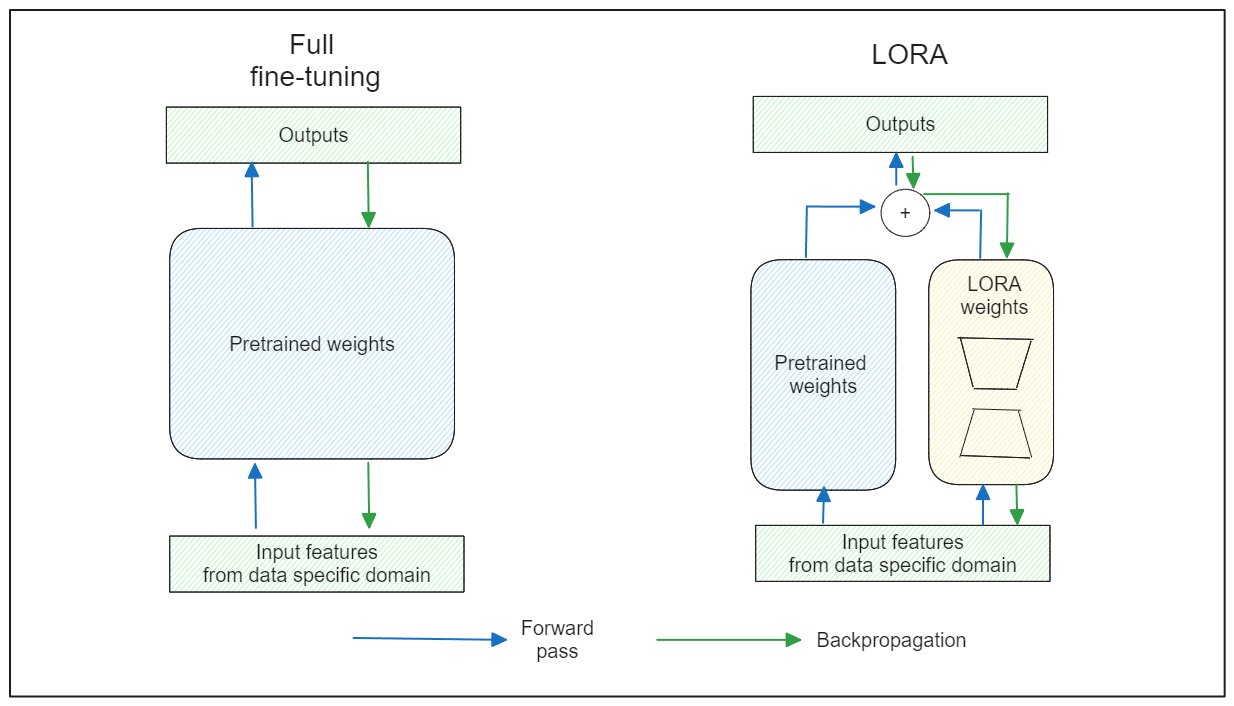 Full fine-tuning vs LORA
Full fine-tuning vs LORA
Now that we know the different fine-tuning methods, let's discuss the different techniques of fine-tuning:
Supervised Fine-Tuning: In this method, we provide our LLMs with our own training data and corresponding labels. We then train our LLMs like any supervised machine learning model.
Reinforcement Learning from Human Feedback (RLHF): This method incorporates reinforcement learning theory. We collect various responses from the LLM based on a query and then evaluate the quality of each response. Over time, our LLMs produce responses that align with our preferences.
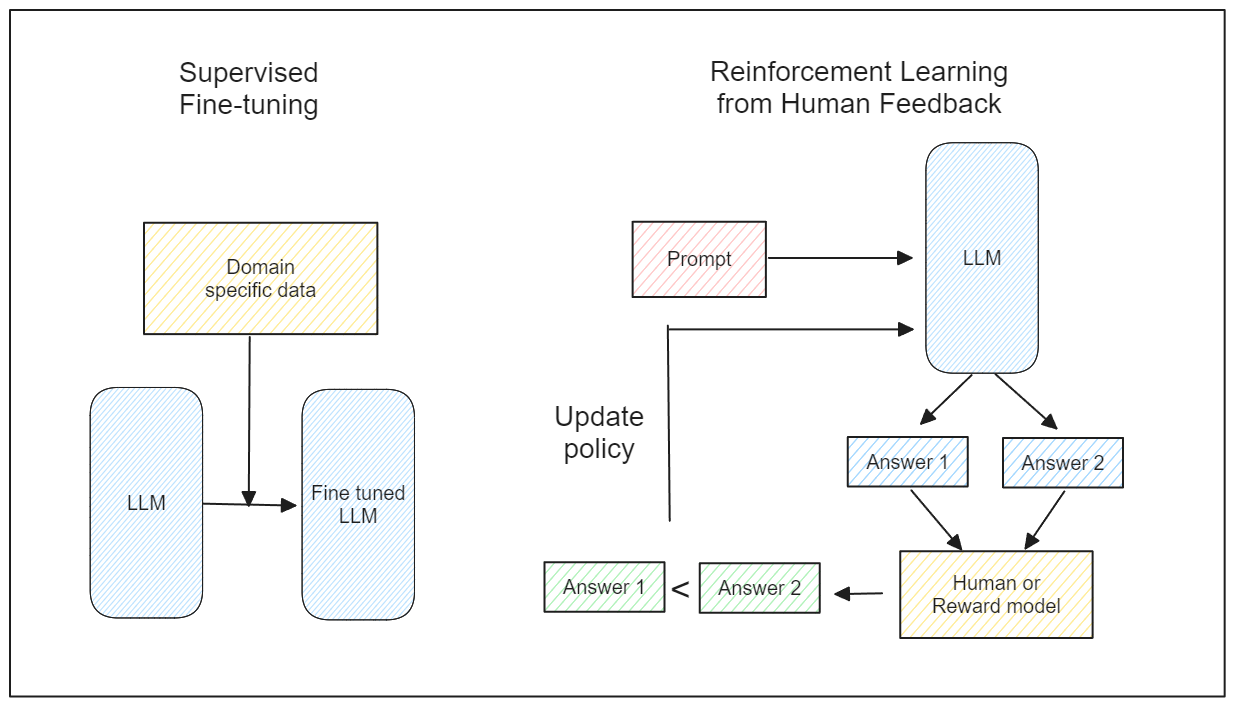 Supervised fine-tuning vs. Reinforcement Learning from Human Feedback
Supervised fine-tuning vs. Reinforcement Learning from Human Feedback
Since supervised fine-tuning is straightforward, let's discuss RLHF in more detail. One drawback of native RLHF is the need for humans to evaluate the quality of responses generated by the LLMs. This approach is expensive and time-consuming.
Data scientists introduced Proximal Policy Optimization (PPO) to alleviate this issue.PPO introduces a reward model to replace human evaluation. However, this reward model needs to be trained separately, making the PPO application cumbersome. Additionally, the reward model needs to be retrained every time new data is added.
To address these issues, Direct Preference Optimization (DPO) was introduced. DPO optimizes the LLM's policy using the negative log-likelihood loss function on human preference data. The dataset for fine-tuning with DPO consists of prompts, preferred responses, and dispreferred responses:
 Example of the data format used to fine-tune LLMs with DPO
Example of the data format used to fine-tune LLMs with DPO
However, DPO tends to overfit the preference dataset quickly. To mitigate this issue, Identity Preference Optimization (IPO) was developed.
IPO introduces a regularization term in the DPO loss function to avoid overfitting. It also uses a log odds ratio term appended to the negative log-likelihood (NLL) loss function, allowing the LLM to be fine-tuned to the desired style while penalizing dispreferred responses.
Conclusion
Yujian Tang discussed various ways to customize LLMs for optimal use in our specific use cases in his talk. The presentation began by providing a brief history of AI advancements that led to the development of LLMs. This topic was followed by an explanation of two methods to customize LLMs: RAG and fine-tuning.
RAG enhances the response quality generated by LLMs by injecting relevant contexts alongside the query as inputs. Vector databases like Milvus store context embeddings and perform vector searches to implement RAG. LLMs then use these contexts to generate appropriate answers.
The second approach is fine-tuning, and there are two methods of fine-tuning:
Supervised Fine-Tuning: This method involves providing our LLMs with our own training data and corresponding labels and then training them like any supervised machine learning model.
Reinforcement Learning from Human Feedback (RLHF): This method incorporates reinforcement learning theory, where we collect various responses from the LLM based on a query and evaluate each response's quality. Over time, our LLMs produce responses that align with our preferences.
For more details about LLM customization, Watch the replay of Yujian’s talk.
Keep Reading

Zilliz Cloud BYOC Now Available Across AWS, GCP, and Azure
Zilliz Cloud BYOC is now generally available on all three major clouds. Deploy fully managed vector search in your own AWS, GCP, or Azure account — your data never leaves your VPC.

Democratizing AI: Making Vector Search Powerful and Affordable
Zilliz democratizes AI vector search with Milvus 2.6 and Zilliz Cloud for powerful, affordable scalability, cutting costs in infrastructure, operations, and development.

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.