




Combining Images and Text Together: How Multimodal Retrieval Transforms Search
The Rise of Multimodal Models
As we look back at the rapid progress of large language models (LLMs) in 2024, it's clear that AI continues to advance through increased innovation and investment. While abundant textual data is available, researchers have recognized that humans understand the world through multiple senses, prompting a shift toward leveraging other data types like images, audio, and videos. This shift has driven the rise of multimodal AI models, which can process and understand data from multiple sources, allowing for richer, more complex interpretations of information.
In the first half of 2024, we saw significant multimodal model releases, such as OpenAI's GPT-4o, Anthropic's Claude 3, Google's Gemini 1.5 Pro, and Apple's Ferret-UI. These models extend AI's capabilities beyond text, opening up new applications in creative industries, productivity tools, and more interactive systems. What was once a niche academic concept has now become mainstream, with developers utilizing these APIs to build applications that integrate AI with diverse media, unlocking new possibilities for innovation.
 OpenAI scientists showing the multimodal capabilities of their newly released GPT-40.png
OpenAI scientists showing the multimodal capabilities of their newly released GPT-40.png
Figure: OpenAI scientists showing the multimodal capabilities of their newly released GPT-40
Multimodal Retrieval and Composed Image Retrieval (CIR)
As multimodal models develop, multimodal retrieval—which combines inputs from multiple modalities, typically text and images—is becoming increasingly popular. This approach allows for a more nuanced and precise way to capture users’ search intents, leveraging the strengths of both modalities.
One of the most common tasks within multimodal retrieval is Composed Image Retrieval (CIR), where users provide a query that includes a reference image along with a descriptive caption. This dual-input approach enables the retrieval of specific images by combining visual content with textual instructions, creating a more detailed and accurate query.
Traditional image searches primarily rely on visual similarity metrics, which are effective for many general-purpose queries. However, in cases where a single reference image doesn't fully express the user's intent, text input becomes an essential complement. The text adds context and precision that an image alone may lack, allowing users to fine-tune their search queries. This fusion of modalities enables developers to create more robust and flexible search systems, allowing users to express complex queries naturally and with higher precision.
In the following sections, we will explore the leading models and techniques in composed image retrieval, their methodologies, and their performance across various domains, evaluated using popular datasets like FashionIQ, CIRR, and CIRCO. These evaluations will highlight the strengths and limitations of different CIR approaches in real-world applications.
An Overview of Popular Composed Image Retrieval Methods
In recent years, multimodal retrieval techniques have advanced towards zero-shot universality, especially with models like CLIP, which enables powerful text-to-image retrieval using a shared embedding space for both modalities. These techniques leverage either pre-trained embeddings or fine-tuned, annotated datasets depending on the available resources, leading to significant improvements in search performance and data quality.
The following table provides an overview of popular composed image retrieval (CIR) techniques, their core methodologies, and the types of embeddings they generate and use for search:
| Technique | Description | Generated Embedding | Search Embedding |
| Pic2Word | Converts an image into a token embedded within text, enabling flexible image-to-text searches. | CLIP Text Embedding | CLIP Visual Embedding |
| CompoDiff | Applies noise to a CLIP visual embedding, then uses text during the denoising process to reconstruct a conditional CLIP visual embedding. | CLIP Visual Embedding | CLIP Visual Embedding |
| CIReVL | Transforms an image into descriptive text, modifies the description to match the target, and generates a new representation. | CLIP Text Embedding | CLIP Visual Embedding |
| MagicLens | Uses a Transformer model that simultaneously processes image and text data, generating a unified vector embedding. | MagicLens Embedding | MagicLens Embedding |
Pic2Word: Mapping Pictures to Words for Zero-shot Composed Image Retrieval
Pic2Word is a method for zero-shot composed image retrieval (ZS-CIR), aimed at retrieving images using image and text as input queries without requiring large, labeled datasets. Using the pre-trained CLIP model, Pic2Word maps visual embeddings from images into pseudo-word tokens representing the image in the textual space. This allows the model to combine the image features with text descriptions to retrieve target images based on modifications specified in the text (e.g., changing attributes of an image, like the color of an object).
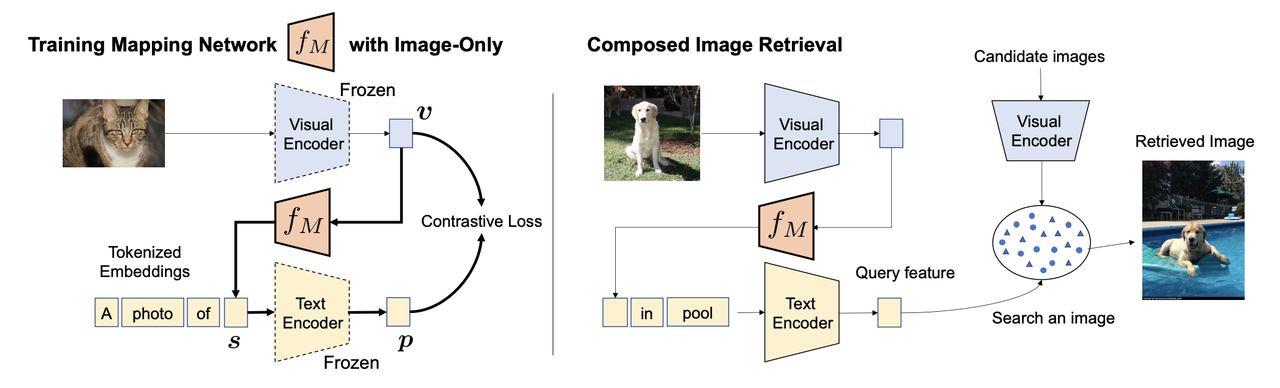 Left-the process of training the Pic2word mapping network; Right-the process of composed image retrieval..png
Left-the process of training the Pic2word mapping network; Right-the process of composed image retrieval..png
Figure: Left: the process of training the Pic2word mapping network; Right: the process of composed image retrieval.
How Pic2Word Works
The image above shows the training of the Pic2Word mapping network and the process of composed image retrieval. During the training process, an image (e.g., a picture of a cat) is passed through a frozen Visual Encoder, which generates a visual embedding . Simultaneously, a tokenized text prompt like "A photo of" is passed through a Text Encoder that produces a corresponding text embedding . The goal of the mapping network is to map the image embedding to a pseudo-token that can be incorporated into the text prompt, forming the phrase "A photo of [s]."
This mapped token, when passed through the frozen Text Encoder, should generate a textual embedding that aligns closely with the original image embedding . The network is trained using a contrastive loss function, which minimizes the distance between the visual embedding and the text embedding , ensuring that the image is accurately represented as a word-like token.
Once the mapping network is trained, it can be used for composed image retrieval tasks. In this stage, the user inputs an image (e.g., a dog) and a text query (e.g., "in a pool"). The image is processed through the Visual Encoder, while the text is processed through the Text Encoder. The learned pseudo-token enhances the query, allowing the system to understand image and text composition.
The query feature, combining image and text representations, is compared against a database of candidate images. The system then retrieves the best-matching image (e.g., a dog swimming in a pool), effectively modifying the input image based on the text description provided.
CompoDiff: Versatile Composed Image Retrieval With Latent Diffusion
CompoDiff is a diffusion-based model designed for zero-shot composed image retrieval (ZS-CIR). It employs diffusion models, a technique in text-to-image generation, to significantly improve the flexibility and precision of image editing and retrieval. These models go beyond simply referencing text; they ensure the generated images align with patterns observed during training. By using diffusion models, CompoDiff creates embeddings that merge input text, reference images, and masks, generating vectors that align with the CLIP visual embedding distribution.
Then, how do we understand the mechanics of diffusion models? Consider a photograph that becomes increasingly noisy over time. Imagine you start with a clear, sharp picture and then gradually add random noise to it, similar to static on an old TV. The image becomes more and more obscured until it's almost unrecognizable, turning into what looks like pure noise. This is the forward diffusion process.
The more fascinating part, though, is the reverse process. In diffusion models, the goal is to start with that noisy image and slowly "denoise" it step by step. As the model removes noise, it reconstructs the original image (or creates new images based on text prompts). This process allows the model to generate high-quality images that adhere to certain conditions—like a specific text description or a reference image.
It works the same way when embedding text. CompoDiff gradually denoises a Gaussian noise embedding, enhancing its signal-to-noise ratio until it matches that of a CLIP visual embedding. Text and images control this transformation, with masks providing extra guidance on which image areas to modify.
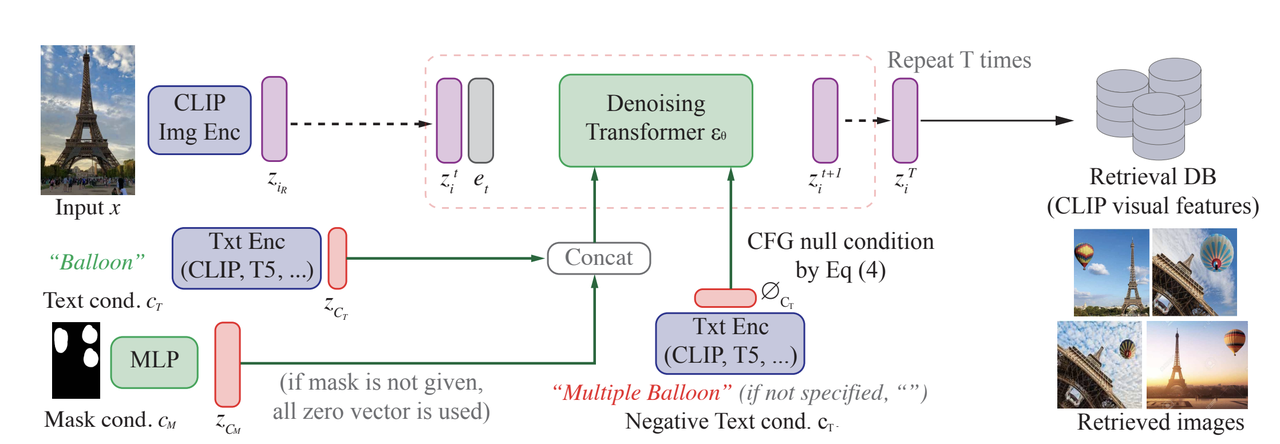 How CompoDiff Works.png
How CompoDiff Works.png
Figure: How CompoDiff Works
CompoDiff’s Inference Process
In the inference phase of CompoDiff, as illustrated in the diagram, the process begins with an input image (e.g., the Eiffel Tower) that is encoded into a latent space through the CLIP Image Encoder, producing the initial visual embedding . This embedding undergoes a forward diffusion process, adding noise to it and transforming it into a noisier version , representing a degraded version of the original image.
Next, the Denoising Transformer is applied, which progressively removes the noise in multiple steps (repeated times) to recover a cleaner image embedding. The denoising process is guided by conditions that influence how the image should be reconstructed. These conditions include:
Text Condition : In this case, the text prompt "Balloon" is encoded through a Text Encoder (CLIP or other text models like T5), producing a text embedding . This embedding adds a contextual guide to the denoising process, ensuring that the final image aligns with the description of a "Balloon."
Mask Condition : If a mask is provided, it is processed through a Multi-Layer Perceptron (MLP) to generate a mask embedding , which guides the denoising to focus on specific areas of the image, such as modifying or adding elements like a balloon in certain regions.
The text and mask conditions are concatenated with the noisy visual embedding and passed through the denoising transformer, which uses Classifier-Free Guidance (CFG) to adjust the strength of these conditions. If no mask or condition is provided, default zero vectors are used to ensure smooth operation.
Notably, negative text conditions are also introduced during this process to refine the output. For example, a negative condition like "multiple balloons" could be applied to avoid generating more than one balloon, ensuring that the final image reflects a single balloon near the Eiffel Tower.
After several iterations of denoising, the resulting image embedding aligns with the CLIP visual features and is then compared against a retrieval database to find or generate the best-matching image, which in this case would be the Eiffel Tower with a balloon in the sky.
CompoDiff’s Training Process
The training is staged in two phases:
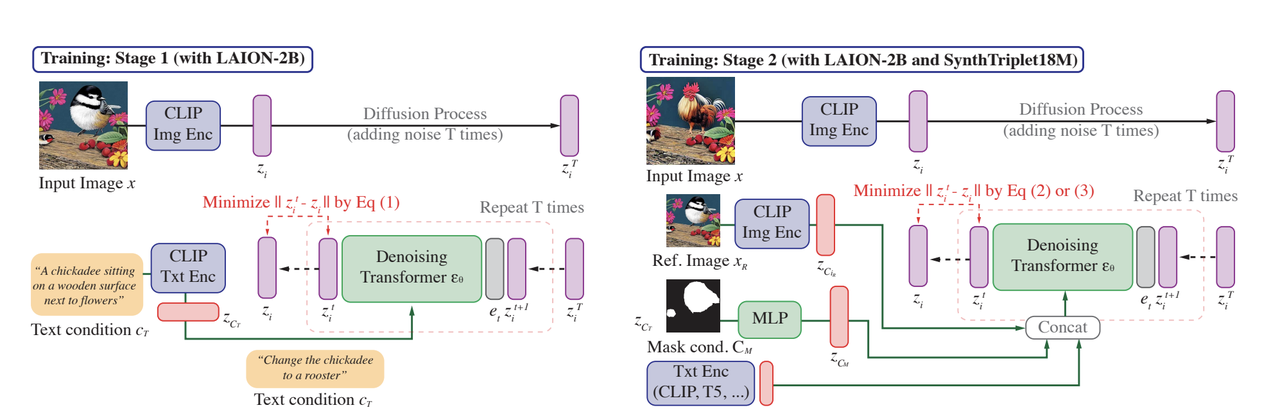 CompoDiff’s Training Process.png
CompoDiff’s Training Process.png
Figure: CompoDiff’s Training Process
****
Stage 1: Training with LAION-2B
In the first stage, the model is trained on the LAION-2B dataset, which contains a large collection of image-text pairs. The primary goal of this stage is to learn how to generate CLIP visual embeddings from noisy inputs using textual descriptions as guidance.
The process begins by encoding an image (e.g., a bird) into a CLIP visual embedding . This embedding undergoes a diffusion process, where noise is progressively added over several steps, resulting in a highly noisy version that contains little to no identifiable information. Simultaneously, the corresponding text description, such as "A chickadee sitting on a wooden surface next to flowers," is encoded into a CLIP text embedding . The noisy visual embedding and the text embedding are then fed into a Denoising Transformer, which removes the noise in stages, guided by the text. The transformer aims to gradually reconstruct the clean visual embedding of the image. The objective in this stage is to minimize the difference between the noisy visual embedding and the reconstructed embedding using the text as the guiding reference. This teaches the model to align visual and textual information, ensuring that the generated image features match the textual description.
Stage 2: Fine-Tuning on SynthTriplets18M Dataset
In Stage 2, the model is fine-tuned on both the LAION-2B and the synthetic SynthTriplet18M datasets, enhancing its ability to handle more complex scenarios.
In this phase, the model learns to generate specific images not only from text descriptions but also by incorporating reference images and mask conditions that indicate areas to modify. The training starts by encoding an input image, just like in Stage 1, but now a reference image is also provided and encoded into its own visual embedding. The reference image guides the model in modifying the input image. A mask condition is also introduced, highlighting specific regions in the image needing modification. The mask is processed into an embedding using an MLP (multi-layer perceptron), and it works in conjunction with the text embedding (e.g., "Change the chickadee to a rooster") to guide the denoising process.
The model alternates between two objectives: one where it learns to obscure specific areas of the target image based on the text and mask conditions, and another where it refines its ability to transform the input image into the target image based on the provided reference, mask, and text. Through this alternating training process, the model learns how to blend visual and textual information to modify images accurately and flexibly. By the end of these two stages, CompoDiff is equipped to handle complex composed image retrieval tasks, offering fine control over how images are generated and modified based on multiple conditions. This allows the model to generate images that align with detailed text instructions, incorporate features from reference images, and selectively modify specific regions.
CIReVL: Vision-by-Language for Training-Free Compositional Image Retrieval
Most compositional image retrieval (CIR) models rely on annotated datasets and task-specific model training, which are expensive and prone to overfitting. This means that the models tend to perform poorly when presented with images that differ from their training distribution. This issue becomes especially problematic in real-world applications where the variety of inputs can be vast and unpredictable. With the development of large-scale models like large language models (LLMs) and vision-language models (VLMs), the zero-shot learning paradigm—where models perform tasks they haven't been explicitly trained on—has gained significant attention. CIReVL is a prominent example of a zero-shot CIR model that requires no additional training but still achieves robust performance.
 How CIReVL works.png
How CIReVL works.png
Figure: How CIReVL works
More specifically, CIReVL (Compositional Image Retrieval through Vision-by-Language) is a training-free approach to compositional image retrieval that leverages existing, pre-trained models such as VLMs and LLMs. Its goal is to retrieve target images from a database by combining a query image and a textual modifier (for example, "Eiffel Tower without people and at night"). What makes CIReVL stand out is its ability to bypass the need for supervised training altogether, offering a more flexible and efficient solution for CIR tasks.
The method is built on three key components, each with strong generalization capabilities. First, a vision-language model (such as BLIP2) generates a descriptive caption for the input image. Second, a large language model (such as GPT-3.5 or GPT-4) modifies the caption based on the provided text instructions (e.g., "remove people, change the time to night"). Lastly, the modified caption is transformed into a text embedding using a text-image encoder like CLIP, which then performs the actual image retrieval from the database. This process is highly modular and operates purely in the language domain, allowing for more intuitive control and user intervention. This straightforward pipeline also makes CIReVL both scalable and adaptable.
MagicLens: Self-Supervised Image Retrieval with Open-Ended Instructions
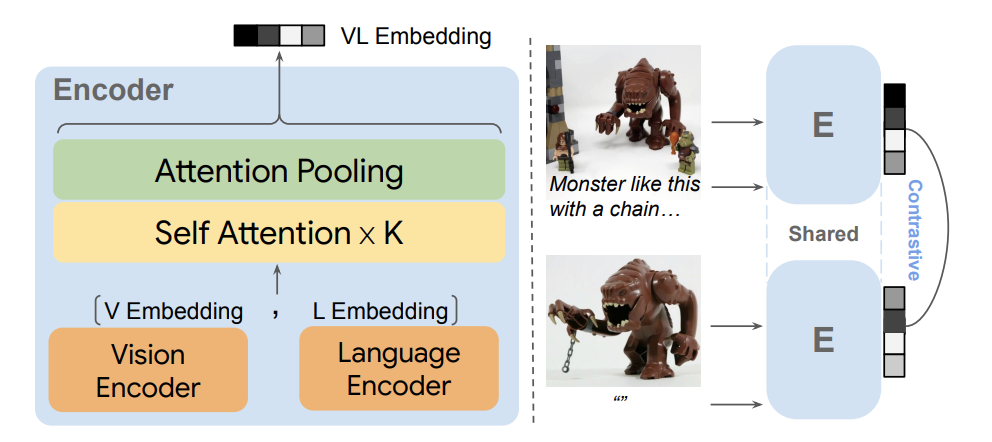
Looking back to previous methods, we can find that one of the biggest challenges in Composed Image Retrieval (CIR) is collecting and annotating high-quality, real-world data to train models that generalize well across various contexts. Models need to understand complex image relationships, but the data required for this kind of training is often expensive and difficult to obtain. To tackle this issue, DeepMind and Ohio State University researchers introduced MagicLens, a self-supervised image retrieval model with open-ended instructions. Its core innovation lies in its ability to go beyond traditional visual similarity and retrieve images based on more nuanced semantic relationships.
MagicLens builds on pre-trained vision-language models (VLMs) like CLIP or CoCa, alongside large language models (LLMs) such as PaLM2. This combination enables MagicLens to handle complex search queries, allowing users to input an image and a flexible text prompt (e.g., "from a different angle" or "the interior view") to retrieve images that align with both the visual content and the semantic relationships.
The model capitalizes on the insight that images from the same web pages often share implicit relationships, such as different views of an object or interactions between objects. MagicLens mines these image pairs from web pages and uses them to generate a vast dataset of training triplets—each consisting of a query image, a textual instruction, and a target image. These triplets provide the foundation for MagicLens’s self-supervised learning process, where the model learns to link images based on the instructions provided.
 How Magiclends works.png
How Magiclends works.png
Figure: How Magiclends works
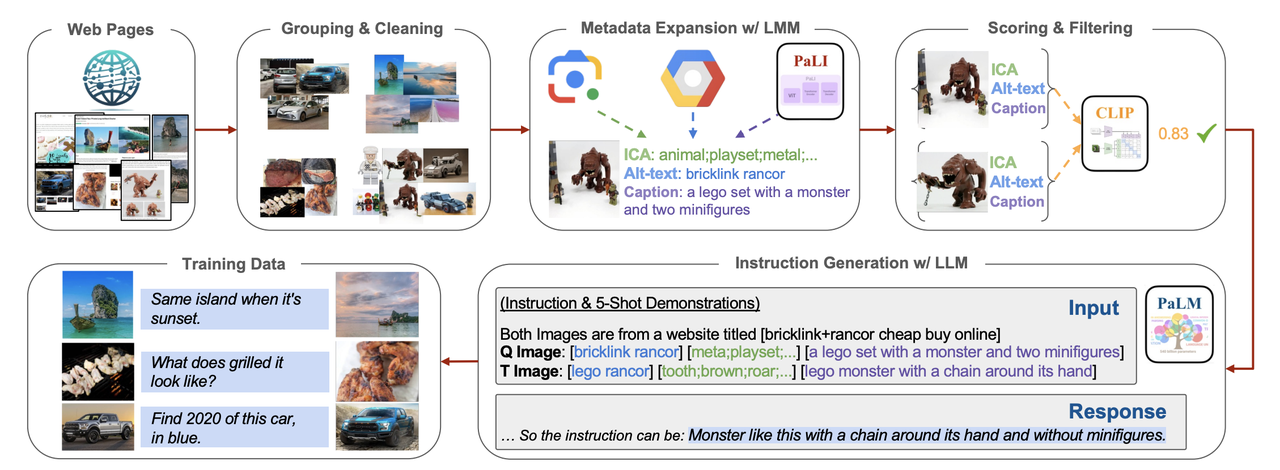
To collect and curate these triplets, MagicLens employs a sophisticated data pipeline:
Web Pages: Images are collected from the same URL, with the assumption that they are likely related. This enables the model to gather a vast amount of data from Common Crawl.
Grouping & Cleaning: The collected images are grouped by URL, then filtered to remove low-resolution, duplicate, or irrelevant (e.g., advertisement) images.
Metadata Expansion: To enhance understanding, metadata is generated for each image. This metadata includes:
ICA labels (generated via Google Vision API) for basic object identification.
Alt-text (alternative text descriptions from web pages).
Captions generated using Google’s PaLI model.
Scoring & Filtering: Using CLIP's image-to-image and text-to-text scoring, MagicLens further filters out weakly related image pairs, ensuring that only high-quality pairs remain.
Instruction Generation: Based on the metadata of paired images, Google’s PaLM2 generates open-ended textual instructions that explain the relationship between the query and target images.
 data pipeline.png
data pipeline.png
Figure: data pipeline
Through this pipeline, MagicLens generates a dataset of 36.7 million triplets (reference image, text instruction, and target image), which provides the foundation for model training. This massive dataset allows MagicLens to train effectively without the need for manual annotations, leading to a robust model across various retrieval tasks.
Evaluation of Composed Image Retrieval (CIR) Models
Several benchmark datasets are commonly used to assess the performance of Composed Image Retrieval (CIR) models, including FashionIQ, CIRR, and CIRCO. These datasets cover a variety of retrieval tasks, from fashion image search to natural image retrieval, making them ideal for evaluating different models across various domains.
FashionIQ focuses on fine-grained fashion image retrieval, with tasks involving specific clothing items (e.g., dresses, shirts etc). It includes 2005 queries and 5179 index images.
CIRR emphasizes real-world images and covers a wide range of image relationships (e.g., spatial or compositional changes). It has 4148 queries and 2316 index images.
CIRCO is a large-scale dataset with over 120,000 natural images, where each query can have multiple correct target images.
Model Performance on CIR Benchmarks
The following table highlights the performance of several leading CIR models on these datasets. The models are evaluated using different metrics, such as Recall@10 (R@10) for FashionIQ and CIRR, and Mean Average Precision at 5 (mAP@5) for CIRCO. These metrics assess how well the models can retrieve relevant images based on a combination of visual input and textual instructions.
| Publication | Params | Fashion IQ R@10 | CIRR R@1 | CIRCO mAP@5 | |
| Pic2Word | CVPR 2023 | 429M | 24.7 | 23.9 | 8.7 |
| CompoDiff | CVPRW 2024 | 568M | 36.0 | 18.2 | 12.6 |
| CIReVL | ICLR 2024 | 12.5B | 28.6 | 24.6 | 18.6 |
| MagicLens-L | ICML 2024 | 613M | 38.0 | 33.3 | 34.1 |
Key Insights:
FashionIQ Performance: MagicLens-L outperforms other models with a Recall@10 of 38.0, showcasing its effectiveness in fashion retrieval tasks. CompoDiff follows closely with 36.0, showing its strength in fashion-related CIR.
CIRR Performance: MagicLens-L also leads in CIRR, achieving a Recall@1 of 33.3, significantly higher than other models. CIReVL performs solidly with 24.6, demonstrating its capability in real-world image retrieval.
CIRCO Performance: MagicLens-L shines in large-scale natural image retrieval tasks as well, with a mean Average Precision at 5 (mAP@5) of 34.1, far ahead of other models. This demonstrates its strength in handling complex, large datasets with multiple correct targets.
Overall, MagicLens-L shows the best general performance across all datasets, particularly excelling in both fashion and large-scale natural image retrieval tasks, despite having fewer parameters compared to CIReVL.
Summary
In this article, we explored the increasing adoption of multimodal retrieval methods, which combine the retrieval of text, images, and many other data types to provide more flexible and precise ways to capture search intent. A common task in this domain is composed image retrieval (CIR), where users refine image searches using text descriptions in combination with reference images.
We covered key models and techniques driving CIR, including Pic2Word, CompoDiff, CIReVL, and MagicLens. Each of these builds on the foundational capabilities of CLIP while adopting different approaches to improve retrieval:
Pic2Word transforms images into text tokens embedded in a text-based search, leveraging CLIP text embeddings for highly versatile, text-driven image retrieval.
CompoDiff employs text-guided denoising, refining noisy visual embeddings with text input to conditionally reconstruct image embeddings, improving search precision.
CIReVL modifies text descriptions to better match the target image and regenerates new visual embeddings, providing more accurate search results by aligning textual modifications with the reference image.
MagicLens uses Transformer models to process text and images in parallel, generating a unified embedding that captures both modalities and enhances retrieval performance.
Explore Our Multimodal Search Demo!
We’ve developed an online demo for multimodal search powered by the Milvus vector database. In this demo, you can upload an image and input text instructions, which are processed by a composed image retrieval model to find matching images based on both visual and textual input.
At the heart of this demo is the MagicLens embedding model, which works alongside a GPT-4o-based re-ranking system to refine search results according to user intent. This combination highlights how multimodal models can transform modern retrieval systems, delivering more accurate and intuitive search experiences.
We invite you to explore and experience the future of multimodal search firsthand!
 Searching results from the multimodal search model.png
Searching results from the multimodal search model.png
Figure: Searching results from the multimodal search model
Play with the demo: Multimodal Image Search
Check the source code: Multimodal RAG with Milvus | Milvus Documentation
Further Resources
MagicLens GitHub page: https://open-vision-language.github.io/MagicLens/
CIReVL GitHub page: https://github.com/ExplainableML/Vision_by_Language
CompoDiff GitHub page: https://github.com/navervision/CompoDiff
Milvus demo: https://milvus.io/milvus-demos

Keep Reading

My Wife Wanted Dior. I Spent $600 on Claude Code to Vibe-Code a 2M-Line Database Instead.
Write tests, not code reviews. How a test-first workflow with 6 parallel Claude Code sessions turns a 2M-line C++ codebase into a daily shipping pipeline.

A Developer's Guide to Exploring Milvus 2.6 Features on Zilliz Cloud
Milvus 2.6 marks a shift from “vector search + glue code” to a more advanced retrieval engine, and it is now Generally Available (GA) on Zilliz Cloud (a managed Milvus service).

What Exactly Are AI Agents? Why OpenAI and LangChain Are Fighting Over Their Definition?
AI agents are software programs powered by AI that can perceive their environment, make decisions, and take actions to achieve a goal—often autonomously.