




**What is a Convolutional Neural Network? An Engineer's Guide**

What is a Convolutional Neural Network? An Engineer's Guide
A Convolutional Neural Network (CNN) is a deep-learning model tailored for visual data like images, videos, and sometimes even audio files.
CNNs have transformed fields such as computer vision, and image analysis and processing, object detection, and even natural language processing (NLP).
Traditional neural networks like MLP (Multi-Layer Perceptron) or Fully Connected Networks treat image data as flat vectors, which can be limiting when dealing with the spatial information present in visual data. This can lead to poor accuracy due to wrong assumptions (inductive bias).
CNNs address these issues by preserving image structure, such as local connectivity and content of the pixels of the image data, making them efficient at pattern recognition.
This post highlights CNN advantages, explains its architecture, and gives a simple example of designing a CNN model.
Key reasons for using a CNN
CNNs excel at extracting meaningful features from raw visual data, outperforming traditional neural networks. Reasons for using a CNN include:
Parameter sharing—A CNN shares the same set of parameters across different regions of input, which is helpful in efficiently identifying the hidden patterns in high-dimensional data.
Reduced number of parameters—CNNs use the technique of pooling and convolution, which significantly reduces the number of parameters compared with fully connected networks.
Hierarchical feature learning—A CNN mimics the hierarchical structure of the human visual system.
State-of-the-art performance—CNNs consistently outperform traditional neural networks in tasks like object detection, image processing, speech recognition, and image segmentation. Note that recent advances in computer vision have introduced convolutional and non-convolutional Transformers as well.
Convolutional Neural Network Advantages and Disadvantages
While CNNs have changed the game for computer vision, we need to know both the pros and cons. Let’s dive into the advantages and disadvantages of CNNs:
Convolutional Neural Network Advantages:
- Pattern and Feature Detection: CNNs are great at detecting patterns and features in images, videos and audio signals. Their hierarchical structure allows them to learn complex features from raw data.
- Invariance to Transformations: CNNs are translation, rotation and scaling invariant. Meaning they can recognize objects even if they are in different positions, orientations or sizes in an image.
- Automatic Feature Extraction: CNNs allow end to end training, no need for manual feature extraction. The network learns to find relevant features directly from the raw input data.
- Scalability and Accuracy: CNNs can handle large amounts of data and are accurate on complex tasks. As more data is given, their performance usually improves.
Convolutional Neural Network Disadvantages:
Computational Cost: Training CNNs is computationally expensive and requires lot of memory. This can be a challenge to implement without specialized hardware like GPUs.
Overfitting: If not given enough data or proper regularization techniques, CNNs can overfit. Meaning they will perform well on training data but fail to generalize to new unseen data.
Data Requirements: CNNs require large amounts of labeled data for training. In domains where labeled data is scarce or expensive to obtain, this can be a big limitation.
Interpretability: It’s hard to interpret what a CNN has learned. The “black box” nature of deep learning models makes it difficult to understand the reasoning behind their predictions which can be a problem in sensitive applications.
Understanding these advantages and disadvantages is crucial when deciding whether to use CNNs for a particular task and when designing and implementing CNN-based solutions.
Common Regularization Techniques in CNNs
As we mentioned in the disadvantages, CNNs can be prone to overfitting especially when working with limited data. Regularization techniques are used to prevent CNNs from overfitting the training data, so the model can generalize better to unseen data. Here are some common regularization techniques used in CNNs:
Dropout: This technique randomly "drops out" (i.e., sets to zero) some output features of the layer during training. Dropout forces the network to learn more robust features that are not dependent on any single neuron. By doing this, the network becomes less sensitive to the specific weights of neurons and in turn results in better generalization. During testing all neurons are used but their outputs are scaled down to compensate for the missing neurons during training.
L1 Regularization: Also known as Lasso Regularization, L1 regularization adds a penalty term to the loss function that is proportional to the absolute value of the weights. This technique encourages sparsity in the model by pushing some weights to zero. L1 regularization is useful when you want to create a simpler model by removing less important features.
L2 Regularization: Also known as Ridge Regularization, L2 regularization adds a penalty term to the loss function that is proportional to the square of the weights. This technique discourages large weights and spreads the weight values more evenly. L2 regularization doesn't result in sparse models like L1 but can help in reducing the impact of less relevant features.
Both L1 and L2 can reduce the number of weights and make the network more efficient. The choice between L1 and L2 (or a combination of both, known as Elastic Net regularization) depends on the problem and dataset.
These regularization techniques work when used properly, solves one of the biggest problems in deep and machine learning now.
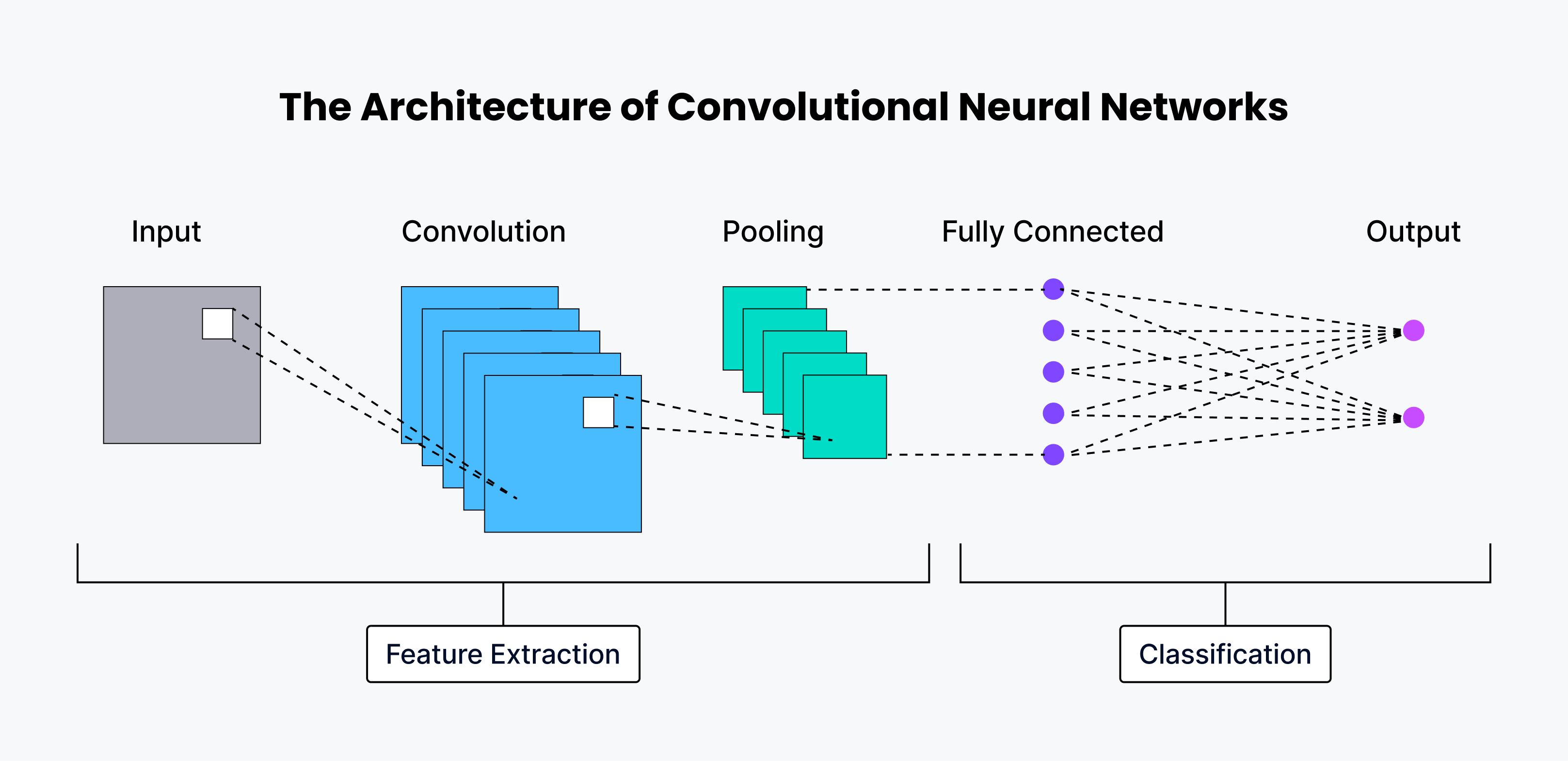
CNN architecture and how it works
A CNN has great capabilities, thus empowering these networks to find hidden patterns and decipher visual data with exceptional accuracy.
The human neural system has several layers, and each one is responsible for performing a unique function. CNNs have a similar architecture, with each layer extracting different features from the input image. Below is a detailed explanation of all the layers involved in CNN architecture.
The first few layers are convolution layers, which are responsible for extracting the basic features of the image such as edges and shape.
The next few layers are pooling layers, which are the output layer responsible for reducing the size of feature maps.
Finally, the last layer is the fully connected (FC) layer, which is responsible for classifying the image into one of the given categories.
Nearly all modern, pure convolutional architectures have just one global pooling layer at the end followed by one fully connected layer.
Convolution layer
The convolution layer is the core of a CNN, designed to find distinctive patterns in the input data. It takes the input image and applies a set of filters to produce an output called a feature map. The filters are small matrices of weights that scan the input image to identify different patterns. As the filter moves across the image, it does so in steps defined by the stride - the number of pixels the filter moves in each step. Sometimes, padding is used to control the output size by adding extra pixels around the input. There are different types of padding, including valid, zero padding (no padding), same padding (output size equals input size), and full padding (which increases output size). After the convolution operation, a non-linear activation function, typically ReLU (Rectified Linear Unit), is applied to introduce non-linearity into the model.
More convolutional layers
As we mentioned earlier, another convolutional layer can come after the first convolutional layer. When this happens, the CNN becomes hierarchical as the later layers can see the pixels within the receptive fields of the previous layers. This hierarchical structure allows hidden layer in the network to learn more complex features as data flows through the layers.
Let’s say we want to recognize a human face in an image. You can think of a face as a composition of various features. It’s eyes, nose, mouth, eyebrows and so on. Each individual feature of the face is a lower level pattern in the neural net and the combination of these features is a higher level pattern, a feature hierarchy in visual cortex of the CNN.
In the first convolutional layer, the network might learn to detect simple features like edges, curves and basic shapes. These could be the outline of facial features or the contrast between different parts of the face.
The second layer image classification might combine these basic features to recognize more complex shapes. For example it might detect circular shapes (possibly eyes) or curved lines (maybe the outline of the mouth or eyebrows).
In subsequent layers the network could start to recognize entire facial features by combining the patterns from previous layers. One neuron might fire when it detects an eye-like structure, another when it detects a nose-like pattern.
In the final layers the CNN would combine all these facial features to recognize a full face. At this stage the network isn’t just detecting individual features but understanding how these features relate to each other in the context of a face.
Finally the convolutional layers would convert the image into numerical values so the neural network can interpret input images and extract patterns at various levels of abstraction. This hierarchical feature learning is one of the key strengths of CNNs in image recognition tasks, to understand complex multi-component objects like faces.
Pooling layer
Following the convolution layer, we often find a pooling layer. The purpose of this pooling layer downsamples) is to reduce the size of feature maps while preserving the most important features. This helps to reduce computational complexity and control overfitting. There are two common pooling techniques: max pooling, which takes the maximum value from a small region of the feature map, and average pooling, which takes the average value from a small region.
Fully connected (FC) layer
The final layer of a CNN is typically a fully connected layer that classifies the CNN's output. This layer is similar to a traditional neural network layer, connecting to all neurons from the previous layer. It uses the high-level features learned by the convolutional layers to perform the final classification or regression task.
 The-Architecture-of-Convolutional-Neural-Networks.png
The-Architecture-of-Convolutional-Neural-Networks.png
Essential terminology
When working with CNNs, it's important to understand some essential terminology. An epoch refers to one complete pass through the entire training dataset. Dropout is a technique used to prevent overfitting by randomly dropping neurons during the training process. Stochastic Depth is another method that shortens the network during training by randomly dropping residual blocks.
Strides—This is known as a step size that the filter takes during convolution operation.
Padding—Padding in CNN is adding zeros around the borders of the image to preserve its spatial dimension after convolution. It's done to prevent the image from shrinking and to prevent the loss of information after each convolution operation.
Epoch—One complete pass through the entire training dataset.
Dropout (regularization)—Technique to prevent overfitting by randomly dropping neurons during training, which forces the network to learn rather than rely on more neurons.
Stochastic Depth—Shortens the network during training by dropping the residual blocks randomly and bypassing their transformations through skip connections. Meanwhile, at the testing time, the whole network is used to make predictions. This results in improved test error and significantly reduced training time.
Types of convolutional neural networks
The history and development of convolutional neural networks go back several decades and many researchers have contributed to it. Understanding this history will help you understand the current state of CNNs.
Historical basis
Kunihiko Fukushima laid the foundation for CNNs in 1980 with his work on the "Neocognitron", a hierarchical, multi layered artificial neural network. This early model could learn robust visual pattern recognition.
Yann LeCun made another important contribution in 1989 with his paper "Backpropagation Applied to Handwritten Zip Code Recognition". LeCun applied backpropagation to train neural networks to recognize patterns in handwritten zip codes. This was a big step towards practical applications of neural networks.
LeNet-5: The original CNN architecture
LeCun and his team continued to work on it through the 1990s and finally came up with LeNet-5 in 1998. LeNet-5 applied the principles of earlier work to document recognition. It is considered the original CNN architecture and the foundation for all future work.
Evolution of CNN architectures
Since LeNet-5, many variant CNN architectures have been developed. New datasets like MNIST and CIFAR-10 and competitions like ImageNet Large Scale Visual Recognition Challenge (ILSVRC) have driven most of this innovation. Some of the notable CNN architectures that have been developed are:
AlexNet: Developed by Alex Krizhevsky, Ilya Sutskever and Geoffrey Hinton, AlexNet won ILSVRC 2012. It was deeper and wider than previous CNNs, used ReLU activations and dropout for regularization.
VGGNet: Developed by the Visual Geometry Group at Oxford, VGGNet is known for its simplicity and depth. It uses small 3x3 convolutional filters throughout the network.
GoogLeNet (Inception): Developed by Google, it introduced the "Inception" module which allows for more efficient computation and deeper networks.
ResNet: Developed by Microsoft Research, ResNet introduced skip connections and allowed training of much deeper networks (up to 152 layers in the original paper).
ZFNet: An improvement over AlexNet, ZFNet (named after its creators Zeiler and Fergus) won ILSVRC 2013 by tuning the architecture hyperparameters.
Each of these architectures brought innovations that pushed the boundaries of what was possible with CNNs, improving performance on various computer vision tasks.
How to design a Convolution Neural Network
When designing a CNN, there are several key decisions to make. These include choosing the input size, determining the number of convolution layers, selecting the size and number of filters per input layer, choosing the pooling method, deciding on the number of fully connected layers, and selecting the activation functions. Each of these choices can significantly impact the network's performance and efficiency.
Choose the input size—Input size represents the size of an image on which the CNN will be trained. The input size should be large enough so the network is capable of extracting the features of an object that it aims to classify.
Choose the number of convolution layers—This determines how many features the network will be able to learn. More convolution layers allow it to learn more complex features, but the computation time increases.
Choose the size of the filter—The size of the filter, along with the stride of the convolution, determines the size of the features that will be extracted from images. A larger dimension filter will extract a higher number of features.
Choose the number of filters per layer—This determines the number of different features that can be extracted from an image.
Choose the pooling method—The two common pooling techniques are max pooling and average pooling. Max pooling takes the maximum value from a small region of the feature map, while average pooling takes the average value from a small region of the feature map.
Choose the number of fully connected layers—This determines the number of classes the network can classify.
Choose the activation function—The activation function enables the learning of more complex patterns from the image dataset. For binary classification, it's normal to use the sigmoid function. In a multi-class classification problem statement, the FC layer uses the softmax activation function. To introduce the nonlinearity in data, people mostly use the GeLU or Swish activation functions these days.
Below is a simple example of CNN implementation with Python that classifies traffic signs. Find the dataset on the Kaggle website.
Simple CNN implementation with PyTorch
To implement a CNN model in Python, use frameworks such as PyTorch, TensorFlow, Keras, etc. These frameworks provide the implementation of all the layers required for a CNN.
The process starts with importing the necessary modules as follows:
# dependencies for computation
import pandas as pd
import numpy as np
# dependencies for reading and displaying images
from cv2 import resize
from skimage.io import imread
import matplotlib.pyplot as plt
%matplotlib inline
# dependency to create validation set
from sklearn.model_selection import train_test_split
# dependency to evaluate the model
from sklearn.metrics import accuracy_score
from tqdm import tqdm
# PyTorch libraries and modules
import torch
from torch.autograd import Variable
from torch.nn import (Linear, ReLU, CrossEntropyLoss,
Sequential, Conv2d, MaxPool2d, Module,
Softmax, BatchNorm2d, Dropout)
from torch.optim import Adam, SGD
Once that's done, load the dataset and the images with the following code:
# loading dataset
train = pd.read_csv('Data/train.csv')
# loading training images
train_img = []
for img_name in tqdm(train['Path']):
# defining the image path
image_path = 'Data/' + str(img_name)
# reading the image
img = imread(image_path, as_gray=True)
# resize image
img = resize(img, (28, 28))
# normalizing the pixel values
img /= 255.0
# converting the type of pixel to float 32
img = img.astype('float32')
# feed the image into the list
train_img.append(img)
# converting the list to numpy array
train_x = np.array(train_img)
# defining the target
train_y = train['ClassId'].values
train_x.shape
Once the training data is loaded, you’ll need to create a training and validation dataset using the train_test_split() method from sklearn.
# create validation set
train_x, val_x, train_y, val_y = train_test_split(train_x, train_y, test_size = 0.1)
# Check the shapes of the training and validation sets
(train_x.shape, train_y.shape), (val_x.shape, val_y.shape)
You’ll also need to reshape the data for the Torch model as follows:
# converting training images into torch format
train_x = train_x.reshape(-1, 1, 28, 28)
train_x = torch.from_numpy(train_x)
# converting the target into torch format
train_y = train_y.astype(int);
train_y = torch.from_numpy(train_y)
# converting validation images into torch format
val_x = val_x.reshape(-1, 1, 28, 28)
val_x = torch.from_numpy(val_x)
# converting the target into torch format
val_y = val_y.astype(int);
val_y = torch.from_numpy(val_y)
Then define different layers of a CNN as follows:
class Net(Module):
def __init__(self):
super(Net, self).__init__()
self.cnn_layers = Sequential(
# Defining a 2D convolution layer
Conv2d(1, 4, kernel_size=3, stride=1, padding=1),
BatchNorm2d(4),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2),
# Defining another 2D convolution layer
Conv2d(4, 4, kernel_size=3, stride=1, padding=1),
BatchNorm2d(4),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2),
)
# final dense layer for prediction
self.linear_layers = Sequential(
Linear(4 * 7 * 7, 43)
)
# Defining the forward pass
def forward(self, x):
x = self.cnn_layers(x)
x = x.view(x.size(0), -1)
x = self.linear_layers(x)
return x
The CNN network above has two convolution layers followed by a maximum pooling layer with spatial dimensions of 2-by-2.
A flattening layer can help classify hidden layers in the image of the sign into respective classes.
Next, let’s decide on the optimizer and the loss function and define the training procedure.
# defining the model
model = Net()
# defining the optimizer
optimizer = Adam(model.parameters(), lr=0.07)
# defining the loss function
criterion = CrossEntropyLoss()
# checking if GPU is available
if torch.cuda.is_available():
model = model.cuda()
criterion = criterion.cuda()
print(model)
def train(epoch):
model.train()
tr_loss = 0
# getting the training set
x_train, y_train = Variable(train_x), Variable(train_y)
# getting the validation set
x_val, y_val = Variable(val_x), Variable(val_y)
# converting the data into GPU format
if torch.cuda.is_available():
x_train = x_train.cuda()
y_train = y_train.cuda()
x_val = x_val.cuda()
y_val = y_val.cuda()
# clear Gradients of the model parameters
optimizer.zero_grad()
# prediction for train and validation set
output_train = model(x_train)
output_val = model(x_val)
# compute train and validation loss
loss_train = criterion(output_train, y_train)
loss_val = criterion(output_val, y_val)
train_losses.append(loss_train)
val_losses.append(loss_val)
# backpropagation and update model parameters
loss_train.backward()
optimizer.step()
tr_loss = loss_train.item()
if epoch%2 == 0:
# printing the validation loss
print('Epoch : ',epoch+1, '\t', 'loss :', loss_val)
Finally, train the model for 25 epochs on the training data as follows:
# defining the number of epochs
n_epochs = 25
# empty list to store training losses
train_losses = []
# empty list to store validation losses
val_losses = []
# training the model
for epoch in range(n_epochs):
train(epoch)
In the end, each model will be there to make predictions on the testing data. To learn more details, refer to this blog for how to write CNNs from Scratch in PyTorch.
FAQs
What is the difference between CNN and Deep Neural Networks?
A CNN is a type of neural network that can process visual data like images, speech, video, etc., while deep neural networks (DNNs) are a type of artificial neural network that can learn complex patterns from data.
Below are the key differences between CNNs and DNNs.
A CNN has a specific architecture for processing images. On the other hand, a DNN doesn't have any specific architecture and can work for a variety of tasks.
A CNN learns features from images by using convolution layers, while a DNN learns features with the help of different types of layers.
A CNN is more difficult to train, requires more data, and is computationally expensive compared with a DNN.
What are the three layers of a CNN?
The three layers of a CNN are the activation layer, convolution layer, pooling layer, and fully connected layer.
Convolution layer—This layer is responsible for extracting features from images. It works by scanning images with a filter, which is a small matrix of weights. The filter moves across the image, and weights are multiplied by the values of pixels in the image. Finally, it produces a feature map that contains the extracted features.
Pooling layer—The pooling layer reduces the size of feature maps. To do this, two common pooling techniques are max pooling and average pooling.
Fully connected layer—This is the same as traditional neural networks that classify the output of CNN. The neurons in the fully connected layers then classify the image into a set of classes.
What is a Convolutional Neural Network in deep learning?
A convolutional neural network is a type of deep neural network that processes images, speeches, and videos so that you can use them to make real-world predictions on structured/unstructured data in the growing digital world.
A CNN helps predict human emotion, behavior, interests, likes, dislikes, etc., easily and efficiently.
- **Key reasons for using a CNN**
- Convolutional Neural Network Advantages and Disadvantages
- Common Regularization Techniques in CNNs
- **CNN architecture and how it works**
- Types of convolutional neural networks
- **How to design a Convolution Neural Network**
- **Simple CNN implementation with PyTorch**
- **FAQs**
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free