





Community
Chain-of-Retrieval Augmented Generation
Explore CoRAG, a novel retrieval-augmented generation method that refines queries iteratively to improve multi-hop reasoning and factual answers.
Community
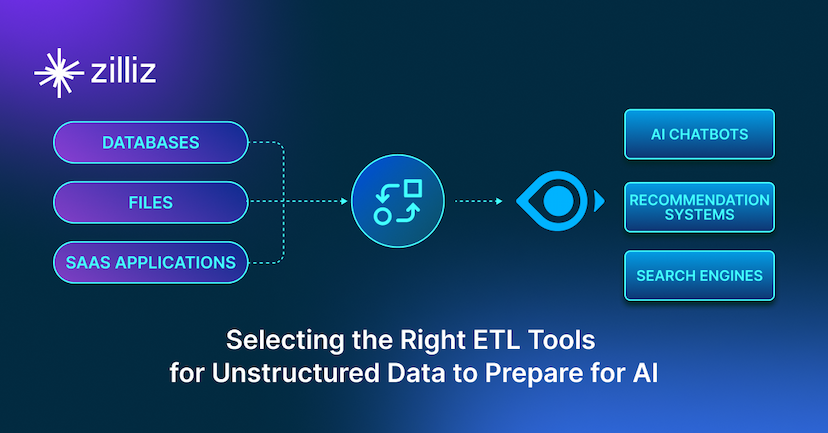
Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.

Community
Choosing the Right Audio Transformer: An In-depth Comparison
Discover how audio transformers enhance sound processing. Explore their principles, selection criteria, popular models, applications, and key challenges.

Community
Getting Started with Audio Data: Processing Techniques and Key Challenges
Discover audio data, its characteristics, processing techniques, and key challenges. Learn how to tackle them effectively in AI applications.

Community
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Explore DeepSeek-VL2, the open-source MoE vision-language model. Discover its architecture, efficient training pipeline, and top-tier performance.

Community
Knowledge Injection in LLMs: Fine-Tuning and RAG
Explore knowledge injection techniques like fine-tuning and RAG. Compare their effectiveness in improving accuracy, knowledge retention, and task performance.

Community
Multimodal Pipelines for AI Applications
Learn how to build scalable multimodal AI pipelines using DataVolo and Milvus. Discover best practices for handling unstructured data and implementing RAG systems.

Community
Insights into LLM Security from the World’s Largest Red Team
We will discuss how the Gandalf project revealed LLMs' vulnerabilities to adversarial attacks. Additionally, we will address the role of vector databases in AI security.
Community
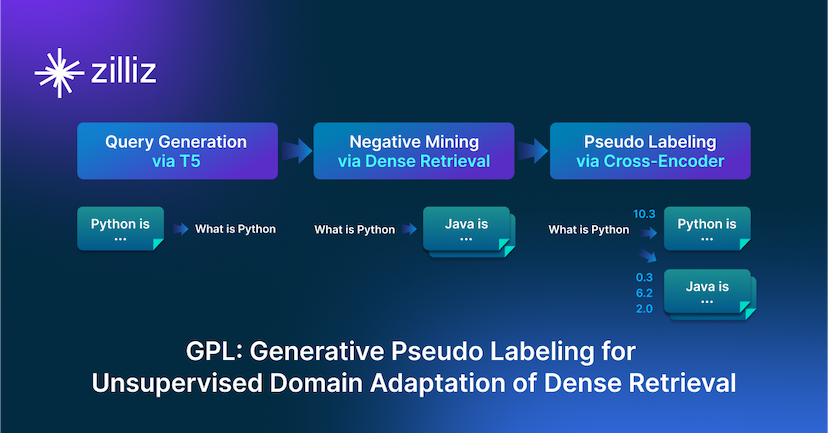
GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval
GPL is an unsupervised domain adaptation technique for dense retrieval models that combines a query generator with pseudo-labeling.