




CLIP Object Detection: Merging AI Vision with Language Understanding
CLIP Object Detection combines CLIP's text-image understanding with object detection tasks, allowing CLIP to locate and identify objects in images using texts.
Read the entire series
- Natural Language Processing Fundamentals: Tokens, N-Grams, and Bag-of-Words Models
- Primer on Neural Networks and Embeddings for Language Models
- Sparse and Dense Embeddings
- Sentence Transformers for Long-Form Text
- Training Your Own Text Embedding Model
- Evaluating Your Embedding Model
- Class Activation Mapping (CAM): Better Interpretability in Deep Learning Models
- CLIP Object Detection: Merging AI Vision with Language Understanding
- Discover SPLADE: Revolutionizing Sparse Data Processing
- Exploring BERTopic: A New Era of Neural Topic Modeling
- Streamlining Data: Effective Strategies for Reducing Dimensionality
- All-Mpnet-Base-V2: Enhancing Sentence Embedding with AI
- Time Series Embedding in Data Analysis
- Enhancing Information Retrieval with Learned Sparse Retrieval
- What is BERT (Bidirectional Encoder Representations from Transformers)?
- What is Mixture of Experts (MoE)?
OpenAI developed Contrastive Language-Image Pre-training (CLIP) in 2021 (Radford et al., 2021) as a major AI breakthrough that unites computer vision and natural language processing. Previously, computers were involved in image and video understanding, while humans concentrated on language processing and generation. CLIP is designed to relate images with corresponding textual descriptions using an extensive set of images and written online explanations without specifying the image data. This model leverages natural language understanding to align textual descriptions with image features, enabling precise identification of objects through contextual cues. The text-and-image-based design of its transformer sits entirely within a single embedding space, facilitating the interpretation of images through association with their textual descriptions. Machines can understand images in words and written texts through this AI revolution.
As shown in Figure 1 below, CLIP employs a dual-encoder framework to establish image-text correspondence by mapping them into a shared latent space. Two encoders are trained simultaneously within the system. The former is called Vision Transformer and is developed for images, whereas the latter is a Transformer-based language model designed for texts.
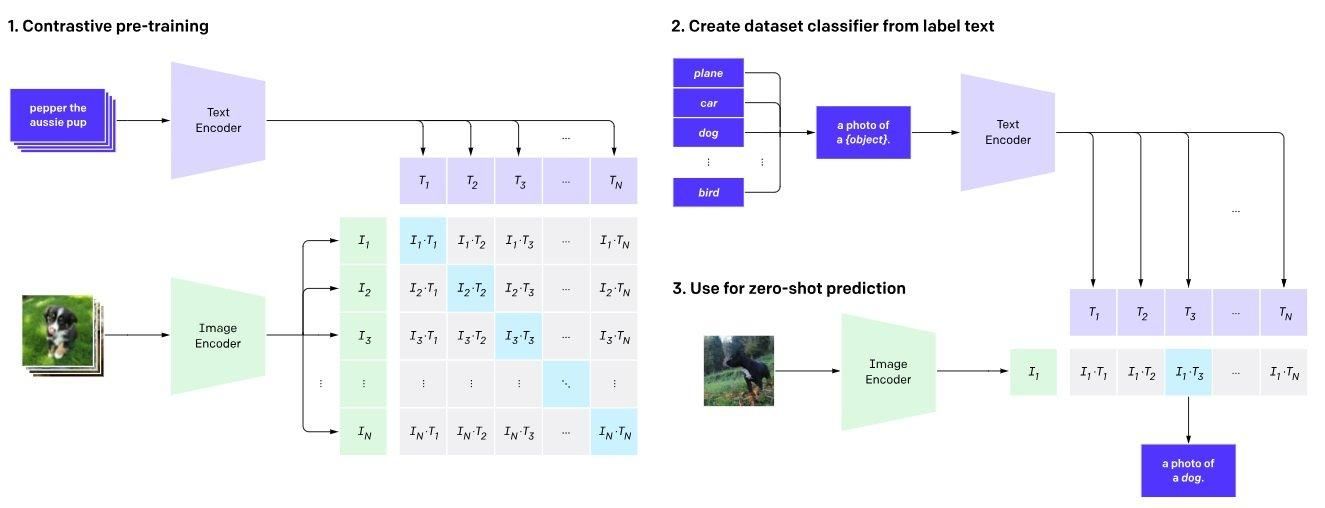
Figure 1. CLIP architecture (Radford et al., 2021)
Image Encoder: Visual inputs are analyzed in detail by an image encoder. It takes an ‘image’ as its input and produces a high-dimensional vector representation. Popular ways of doing this involve using convolutional neural network (CNN) architecture like ResNet to extract features from images.
Text Encoder: The text encoder encodes the semantic meaning of accompanying textual descriptions. Therefore, a “text caption/label” input would be converted into a corresponding high-dimensional vector representation. ****It frequently employs a transformer-based structure, such as a Transformer or BERT, to analyze text sequences.
Shared vector space: The two encoders generate embeddings inside the same vector space. CLIP utilizes common embedding spaces to facilitate the comparison of text and image representations and to get knowledge about their fundamental connections.
Step 1: The Contrastive Pre-training CLIP is trained using millions of image and text data pairs. The model is exposed to authentic matches and non-matching pairs during pre-training, generating shared latent space embeddings.
Step 2: The dataset classifiers are generated based on label text, with multiple text descriptions for each image. The Contrastive Loss Function penalizes the model for inaccurate image-text pairings but rewards accurate matchings in the latent space. This promotes the model's precise capture of similar visual and textual information.
Step 3: The trained text encoder is used as a zero-shot prediction, providing predictions without prior training using a fresh image. CLIP calculates cosine similarity between image and text descriptions and adjusts encoder settings to enhance similarity between correct pairings. It learns a multimodal embedding space that aligns semantically related images and words nearby, and the projected class is determined by selecting the class with the highest logit value.
The most common use case of CLIP’s framework is object detection, which allows the model to precisely identify objects in an image by analyzing natural language queries. This approach means there will no longer be a need for traditional datasets used in object detection or laborious annotation techniques. In the case of CLIP, it is enough to give them exact positions and differentiate them by just indicating “a blue bicycle on the right side of the signal.”
Additionally, CLIP can be used for things other than object identification. For example, it can carry out zero-shot learning, recognizing and classifying individuals or objects not part of its training dataset. The ability to make semantic inferences and interpretations based on the pre-trained weights’ conceptual knowledge acquired by the model demonstrates its generality.
CLIP bridges the gap between text and images, enabling a wide range of applications across different domains:
- Image Search and Retrieval: CLIP can be used to search for images using textual descriptions, significantly improving the accuracy and relevance of image retrieval systems. It understands the content of both text and images, making it possible to find images that match complex queries.
Augmented Reality (AR) and Virtual Reality (VR): In AR and VR environments, CLIP can be used to enhance the interaction between users and digital content, allowing for real-time image analysis and contextual understanding to provide relevant information or actions based on what the user sees and describes.
Art and Design Assistance: Artists and designers can use CLIP to generate or edit images based on textual descriptions, facilitating the creative process by translating words into visual elements.
Medical Assistance: In medical imaging, CLIP object detection can be used by practitioners to locate abnormalities present in different types of medical images, such as X-rays, MRIs, and CT scans. Moreover, textual descriptions can accurately identify specific organs, tumors, or malformations. In addition, patients from extensive health centers can now send images accompanied by explanations via telemedicine. This has empowered healthcare providers to make informed judgments without a deep understanding of analyzing medical images.
Self-driving Assistance: CLIP enhances the vision in self-driving cars by detecting many objects along the road. The system is competent and reads complex explanations of intricate scenarios; hence, it can decide correctly while driving. Furthermore, CLIP object detection improves safety by identifying pedestrians, bicycles, and road signs by self-driving cars. This technology assists in lowering accidents and improving road security.
Financial Services: With CLIP, traders can easily streamline stock management, reducing wastages such as overstocking and understocking. Additionally, textual descriptions are essential for effective product management within warehouses; they allow for easy identification, tracking, and monitoring of items during supply chain logistics while checking quality flaws and maintaining better communication among users
E-commerce recommendation: By way of its sophisticated image and language processing abilities, CLIP allows users to have individualized buying experiences. In specifying their preferred purchase, customers can be suggested what to buy by a system with such capability based on these characteristics.
Through its ability to perceive objects in various conditions, CLIP minimizes the need for extensive labeled data. This flexibility makes it ideal for situations where obtaining annotated data is difficult or time-consuming.
CLIP can seamlessly handle both zero-shot learning tasks, whether they involve new objects or not. CLIP effortlessly adapts its settings to accommodate various environmental conditions and objects without additional training.
CLIP was trained using various object recognition techniques, including large datasets containing images and corresponding descriptions. With this advancement, it has become possible to effortlessly identify information from text, allowing the AI system to operate more efficiently and save valuable time.
Extracting 3D geometric information in a visio-linguistic application is challenging, which results in poor performance in specialized fields like remote sensing. Therefore, it is essential to develop specific frameworks and methodologies for enhancing the effectiveness of CLIP in different domains, including remote sensing and vision-language blending tasks.
Decisions under uncertainty can be challenging, especially in sensitive areas such as health care or legal situations, where the interpretability of CLIP may be difficult, particularly concerning image recognition.
Further, it has a narrow understanding of fine-grained features, making it difficult for interpretability
The pretraining data could have biases affecting CLIP which might amplify social prejudices. These ethical concerns become crucial when AI applications control content or decision systems. Biased results could have severe consequences for reality.
On new data, zero-shot learning does not perform as well as trained tasks with CLIP.
Introduction to Object Detection
Object detection is a cornerstone of computer vision, involving the identification and localization of objects within images or videos. This technology has a myriad of applications, from healthcare diagnostics and autonomous vehicles to surveillance systems. Traditional object detection algorithms rely heavily on machine learning models trained on vast datasets of labeled images. However, acquiring such extensive labeled data is often time-consuming and costly. This is where zero-shot object detection comes into play. Zero-shot object detection enables models to detect objects without the need for fine-tuning on labeled datasets, making it a game-changer in the field of computer vision. By leveraging this approach, we can significantly reduce the dependency on large annotated datasets while still achieving accurate object detection.
Understanding the CLIP Model
The CLIP (Contrastive Language-Image Pre-training) model, developed by OpenAI in 2021, represents a significant leap forward in AI technology. By uniting computer vision and natural language processing, CLIP allows machines to interpret images through the lens of written text. The model employs a dual-encoder framework, which maps images and text into a shared latent space, establishing a robust image-text correspondence. This innovative approach enables CLIP to perform a variety of tasks, including object detection, zero-shot learning, and the recognition and classification of individuals or objects that were not part of its training dataset. The ability to understand and relate visual and textual data makes CLIP a versatile tool in the realm of AI.
How CLIP Works
CLIP operates by leveraging a contrastive loss function to train on millions of image and text data pairs. During training, the model learns to predict which text description corresponds to a given image and vice versa. This process results in a shared vector space where both images and text are represented, allowing for seamless comparison and understanding. For object detection tasks, CLIP can utilize textual descriptions to identify objects within images. Its proficiency in understanding natural language and image representations makes it particularly well-suited for zero-shot object detection, where the model can detect objects without prior exposure to labeled datasets. This capability opens up new possibilities for applications where labeled data is scarce or difficult to obtain.
Object Detection with CLIP
Object detection with CLIP is a straightforward yet powerful process. By providing a textual description of the object to be detected, the model can identify the corresponding object within an image. CLIP’s zero-shot object detection capabilities mean it can detect objects without the need for fine-tuning on labeled datasets, making it an ideal solution for scenarios where labeled data is limited or expensive to acquire. Additionally, CLIP’s ability to comprehend natural language allows it to detect objects based on detailed textual descriptions, enhancing its utility in various computer vision tasks. This makes CLIP a valuable tool for applications ranging from autonomous vehicles to medical imaging, where precise object detection is crucial.
Getting Started with CLIP
Setting Up Your Environment
To begin using CLIP, you’ll need to set up your environment with the necessary tools and resources. Start by installing the CLIP library and its dependencies. Ensure you have a compatible GPU for efficient training and inference. Next, prepare your image data and corresponding textual descriptions for object detection tasks. Once your environment is set up, you can explore CLIP’s capabilities and apply it to various object detection tasks. This setup will enable you to leverage CLIP’s advanced image and language processing abilities, allowing you to detect objects and gain insights from your image data with just a few lines of code.
Conclusion and Future Work in Zero Shot Object Detection
The continuous development of multimodal learning in CLIP highlights the excellent potential for its real-time. The search for advanced models that are more interpretable has been the main goal for machine learning engineers. CLIP also brings significant advancements in domains like image identification, natural language processing (NLP), medical diagnostics, and retail. Because of the impressive results obtained, there is room for further exploration into whether few-shot learning can enhance generalization capabilities in the model of CLIP. Explainable AI can be used to interpret the models and understand how they work. Also, transfer learning techniques can improve adaptability and consistent performance across multiple domains.
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., ... & Sutskever, I. (2021, July). Learning transferable visual models from natural language supervision. In International conference on machine learning (pp. 8748–8763). PMLR.

- Introduction to Object Detection
- Understanding the CLIP Model
- How CLIP Works
- Object Detection with CLIP
- Getting Started with CLIP
- Conclusion and Future Work in Zero Shot Object Detection
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Primer on Neural Networks and Embeddings for Language Models
Exploring neural network language models, specifically recurrent neural networks, and taking a sneak peek at how embeddings are generated.

Exploring BERTopic: A New Era of Neural Topic Modeling
BERTopic is a novel topic modeling technique that allows for easily interpretable topics while keeping important words in the topic descriptions.

Enhancing Information Retrieval with Learned Sparse Retrieval
Explore the inner workings, advantages, and practical applications of learned sparse embeddings with the Milvus vector database