CoCaを理解する:コントラスト・キャプションによる画像テキスト・ファウンデーション・モデルの進歩
Contrastive Captioners(CoCa)は、マイクロソフトが開発したAIモデルで、言語モデルと視覚モデルの機能を橋渡しするように設計されている。
シリーズ全体を読む
- Cross-Entropy Loss: Unraveling its Role in Machine Learning
- Batch vs. Layer Normalization - Unlocking Efficiency in Neural Networks
- Empowering AI and Machine Learning with Vector Databases
- Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
- Vector Databases: Redefining the Future of Search Technology
- Local Sensitivity Hashing (L.S.H.): A Comprehensive Guide
- Optimizing AI: A Guide to Stable Diffusion and Efficient Caching Strategies
- Nemo Guardrails: Elevating AI Safety and Reliability
- Data Modeling Techniques Optimized for Vector Databases
- Demystifying Color Histograms: A Guide to Image Processing and Analysis
- Exploring BGE-M3: The Future of Information Retrieval with Milvus
- Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
- TF-IDF - Understanding Term Frequency-Inverse Document Frequency in NLP
- Understanding Regularization in Neural Networks
- A Beginner's Guide to Understanding Vision Transformers (ViT)
- Understanding DETR: End-to-end Object Detection with Transformers
- Vector Database vs Graph Database
- What is Computer Vision?
- Deep Residual Learning for Image Recognition
- Decoding Transformer Models: A Study of Their Architecture and Underlying Principles
- What is Object Detection? A Comprehensive Guide
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Algorithmic)
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Methodological)
- Understanding CoCa: Advancing Image-Text Foundation Models with Contrastive Captioners
- Florence: An Advanced Foundation Model for Computer Vision by Microsoft
- The Potential Transformer Replacement: Mamba
- ALIGN Explained: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
人工知能は基礎モデルの台頭を目の当たりにしてきた。基礎モデルは、ゼロショット、少数ショット、または転移学習によって複数のタスクに取り組むことができる、膨大なデータセットで事前に訓練された大規模なシステムである。言語処理におけるBERT、T5、GPT-3のようなモデルの成功は、研究者が視覚と視覚言語タスクのための同様のアプローチを開発するように触発しました。この探求は、それぞれ長所と限界のあるいくつかの戦略につながっている。
画像分類で事前に訓練されたシングルエンコーダーモデルは、強力な視覚表現を提供するが、言語関連タスクでは苦戦する。デュアル・エンコーダ・モデルは、画像とテキストのペアでコントラスト損失を学習させたもので、クロスモーダル検索を扱うことができるが、視覚的質問応答のようなタスクでは視覚と言語の共同理解に欠ける。生成的な事前学習を用いたエンコーダ・デコーダモデルは、画像のキャプション付けやマルチモーダル理解では良い性能を発揮するが、クロスモーダルなアライメントタスクでは不十分である。このような様々なタスクにおける性能のバランスという課題から、これらの戦略の最良のものを統合することを目的としたモデルであるCoCaが開発された。
CoCa: Contrastive Captioners are Image-Text Foundation Models paper](https://arxiv.org/abs/2205.01917)で紹介されたContrastive Captioners (CoCa)は、これらのアプローチを統合することを目指しています。コントラスト学習と生成キャプションを単一のアーキテクチャで組み合わせることで、CoCaはこれまでの方法の限界に対処しています。
CoCaは、様々なベンチマークテストで印象的な結果を示しており、しばしば特化したモデルを凌駕しています。ゼロショット画像分類](https://zilliz.com/learn/what-is-zero-shot-learning)、画像-テキスト検索、画像キャプション付けに優れています。また、CoCaの性能はモデルサイズに応じてうまくスケールするため、さらなる改善の可能性を示唆している。ここでは、CoCaのアーキテクチャ、学習プロセス、結果について説明し、CoCaが画像テキスト基盤モデルと人工知能への応用をどのように前進させるかを示す。
対照的キャプションア(CoCa):統一されたアプローチ
コントラスト・キャプション(CoCa)は、マイクロソフトが開発したAIモデルで、言語モデルと視覚モデルの能力を橋渡しするように設計されている。このモデルは、コンピュータ・ビジョンで広く使用されている、肯定的なペアと否定的なペアを対比することで効果的な表現を学習する手法である対比学習の要素と、強力な言語モデリング機能を組み合わせたものである。
CoCaは、シングル・エンコーダ、デュアル・エンコーダ、エンコーダ・デコーダの長所を組み合わせた新しいエンコーダ・デコーダ・アーキテクチャを導入している。CoCaのアーキテクチャの主要コンポーネントは、視覚情報とテキスト情報を効果的に処理するために協働します。
CoCaアーキテクチャの概要
CoCaアーキテクチャは、下図のように3つの主要コンポーネントから構成されている:**イメージ・エンコーダ、ユニモーダル・テキスト・デコーダ、マルチモーダル・テキスト・デコーダである。
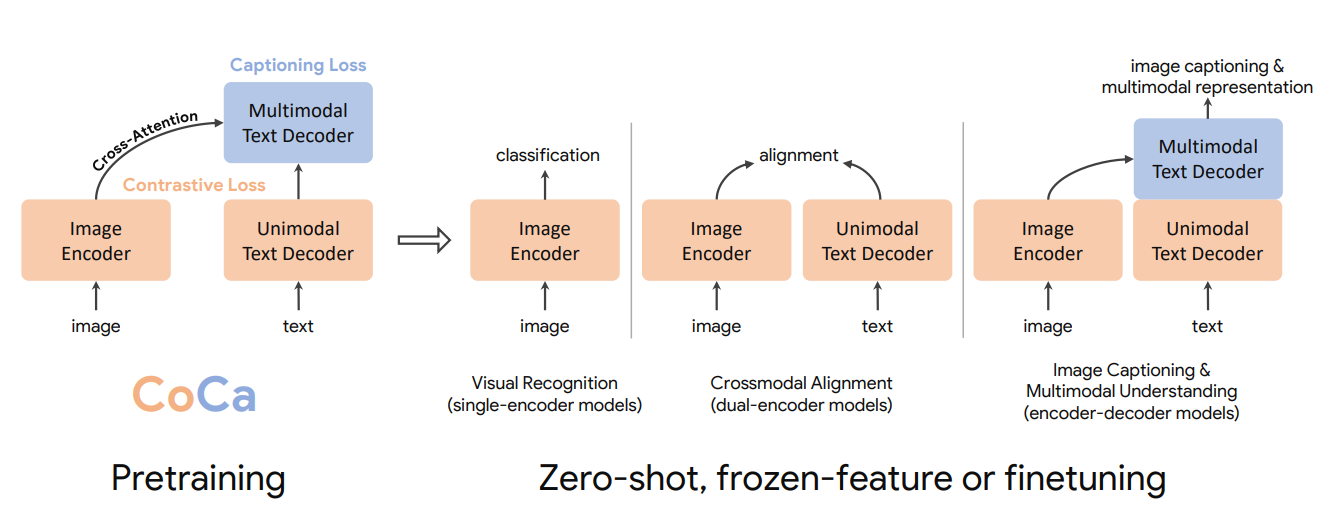 図1- 画像-テキスト理解のための基礎モデルとしてのコントラストキャプション(CoCa)の事前学習プロセスの概要.png
図1- 画像-テキスト理解のための基礎モデルとしてのコントラストキャプション(CoCa)の事前学習プロセスの概要.png
図1: 画像-テキスト理解のための基礎モデルとしての対照キャプション作成(CoCa)のためのプリトレーニングプロセスの概要._.
各要素を見てみましょう:
1.画像エンコーダー:このコンポーネントは、シングルエンコーダーモデルと同様に、入力画像を処理します。未加工のピクセルデータを、画像の視覚的内容を捉えるembeddingsに変換します。
2.ユニモーダルテキストデコーダ:デコーダーの最初の部分は、画像の特徴を見ずにテキストを処理する。これはデュアル・エンコーダ・モデルのテキスト・エンコーダに似ており、CoCaは純粋なテキスト表現を作成することができる。
3.マルチモーダルテキストデコーダー:テキストデコーダーの2番目の部分は、テキストと画像情報を組み合わせる。エンコーダー・デコーダーモデルと同様に、視覚と言語の共同理解を可能にする。
この統一されたアーキテクチャにより、CoCaは最小限の適応で様々な下流タスクに使用することができる。例えば、CoCaモデルは以下のようなケースに最適です:
視覚認識**:画像エンコーダーを使用するだけで、CoCaは画像分類や物体検出のようなタスクを実行することができます。
クロスモーダルアライメント**:画像エンコーダとユニモーダルテキストデコーダを使用することで、CoCaは画像-テキスト検索やゼロショット分類のようなタスクを実行することができます。
画像キャプションとマルチモーダル理解**:エンコーダーとデコーダーの完全な構造を使用して、CoCaは画像のキャプションを生成し、ビジュアルコンテンツに関する質問に答えることができます。
詳細なアーキテクチャとトレーニング目標
なぜCoCaが多様なタスクに優れているのかを理解するために、CoCaのアーキテクチャ・コンポーネントと、学習プロセスを導くトレーニング目標を探ってみましょう。まず、CoCaのアーキテクチャを図解で見てみよう:
図2- CoCaアーキテクチャの詳細とトレーニング目標.png](https://assets.zilliz.com/Figure_2_In_depth_depiction_of_the_Co_Ca_architecture_along_with_its_training_goals_57eccd149a.png)
図2:トレーニング目標に沿ったCoCaアーキテクチャの詳細な描写_図2-トレーニング目標に沿ったCoCaアーキテクチャの詳細な描写.png
画像エンコーダは、入力画像を埋め込みの集合にエンコードする。これらの埋め込みは2つの方法で使用される:
1.1.注意プーリング層に渡され、対照学習のために画像の単一のベクトル表現が作成される。
2.キャプション生成のためにマルチモーダルテキストデコーダーの入力として使われる。
ユニモーダルテキストデコーダはまずテキスト入力を処理し、画像の影響を受けない純粋なテキスト表現を作成する。この表現はコントラスト損失に使われる。次にテキストはマルチモーダルテキストデコーダを通過し、クロスアテンションメカニズムによってテキスト表現と画像特徴を組み合わせる。
CoCaは3つの訓練目標を採用している:シングル・エンコーダ分類、デュアル・エンコーダ対照学習、エンコーダ・デコーダ・キャプション*。これらの目的はそれぞれ、画像分類とテキスト生成タスクを効果的に処理するCoCaの能力に貢献しています。
シングルエンコーダ分類
古典的なシングルエンコーダ分類タスクでは、CoCaは学習プロセスをガイドするためにクロスエントロピー損失を使用します:
図3- クロスエントロピー損失式.png](https://assets.zilliz.com/Figure_3_Cross_entropy_loss_formula_4947e3d467.png)
図3:クロスエントロピーの損失公式_Figure 3- Cross-entropy loss formula.png
ここで
p(y)`は真のラベル分布であり、ワンホット、マルチホット、スムースなラベル分布である。
q_θ(x)` はモデルから予測される確率分布である。
上記の真のラベル分布が何を意味するか見てみよう:
ワンホット分布**は、各画像に対する1つの正しいカテゴリを表します。例えば、3つのカテゴリがあるとすると、ある画像に対する真実のラベルは、その画像が最初のカテゴリに属する場合、
[1, 0, 0]のようになります。マルチホット分布**は複数の正しいカテゴリを許容します。これは画像が複数のカテゴリに属する可能性がある場合に使用されます。例えば、画像が1つ目と2つ目のカテゴリに当てはまる場合、グランドトゥルースラベルは
[1, 1, 0]となるかもしれません。平滑化ラベル分布**は、不確実性を考慮したり、過信を防ぐために、非対象ラベルに確率質量を割り当てます。これは3つのカテゴリーに対して、一発値ではなく、[0.9, 0.05, 0.05]`のようなものになるかもしれません。
この損失関数は真のラベル分布p(y)とモデルの予測値q_θ(x)の間の不一致を測定する。この損失を最小化することで、CoCaは画像を事前に定義されたカテゴリに正確に分類することを学習する。このアプローチは視覚認識タスクには有効であるが、自由形式のテキスト記述を組み込んでいないため、2番目の目的につながる。
デュアルエンコーダ対照学習
CoCaは対比的損失を用いて、画像とテキスト表現を共有埋め込み空間で整列させる。対比的損失関数は以下のように定義される:
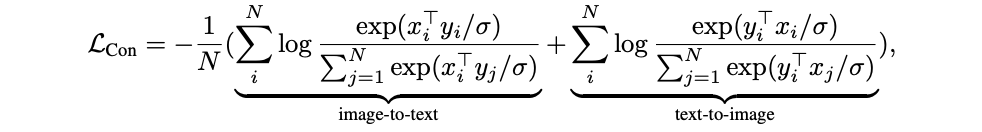 図4-対照的損失関数式.png
図4-対照的損失関数式.png
図4:対照的損失関数の式
ここで
x_i
とy_j`は、それぞれi番目とj番目のペアの正規化画像とテキスト埋め込みである。N`はバッチサイズである。
σ`は分布の濃度を制御する温度パラメータである。
この損失関数は、画像とテキストの埋め込みを整列するようモデルに促す。これは2つの要素を持つ:
画像とテキストのマッチング:この項は画像 x_i とそれに対応するテキスト y_i の類似度を最大化し、バッチ内の他のテキスト y_j との類似度を最小化する。
log( exp(x_i^T * y_i / σ) / Σ_j^N exp(x_i^T * y_j / σ) )`.
テキストと画像のマッチング:この項は、テキスト y_i とそれに対応する画像 x_i との類似度を最大化し、他の画像 x_j との類似度を最小化する。
log( exp(y_i^T * x_i / σ) / Σ_j^N exp(y_i^T * x_j / σ) ).
この損失を最小化することで、モデルは画像とテキストが一致するペアには高い類似度スコアを割り当て、一致しないペアには低いスコアを割り当てるようになる。温度パラメータ σ はモデルがその予測についてどの程度確信を持っているかを制御し、値が低いほど確信度が高くなる。
エンコーダ・デコーダ・キャプショニング
キャプション付け**の目的に対して、CoCaは標準的な言語モデリング損失を使用する。キャプション損失は次のように定義される:
図5- キャプション損失式.png](https://assets.zilliz.com/Figure_5_Captioning_loss_formula_b8a48e64d8.png)
図5:キャプション損失式
ここで
y_t`はキャプションのt番目のトークンである。
y_<t` は直前のトークンである。
x` は画像を表す。
T` はキャプション内のトークンの総数である。
画像と以前に生成されたトークンが与えられたとき、この損失はキャプション内の各トークンを生成する負の対数尤度を計算する。この損失を最小化することで、CoCaは入力画像を説明する正確で首尾一貫したキャプションを生成することを学習する。
損失を組み合わせる:CoCaの学習目標
CoCaの最後の目標は、コントラストとキャプションの損失を1つの統一された目標に統合することである:
 図6-損失の統合-CoCaトレーニング目標.png
図6-損失の統合-CoCaトレーニング目標.png
図6:損失を組み合わせる:CoCaのトレーニング目標_[Figure 6: Combining Losses: The CoCa Training Objective
ここで
- λ_Con
とλ_Capは、コントラスト損失とキャプション損失の寄与のバランスをとるハイパーパラメータである。
この結合損失により、CoCaは(対比学習による)整列表現と(キャプションによる)生成能力の両方を学習することができる。このモデルは、ローカリゼーションと分類のタスクがモデルのデコーダ内で分離されている分離デコーダアーキテクチャのおかげで、1回のフォワードパスで両方の損失を計算することができる。ユニモーダルデコーダーの出力は対比学習に使用され、マルチモーダルデコーダーの出力はキャプション付けに使用される。このアーキテクチャにより、CoCaは別々のフォワードパスを必要とすることなく、複数の目的を効率的に扱うことができる。
これらの学習目的を組み合わせることで、CoCaは画像分類、キャプション生成、画像とテキストのペアの整列などのタスクを効率的に実行することができ、マルチモーダルAIタスクのための多用途モデルとなる。
CoCaの学習プロセス
明確なアーキテクチャー基盤を持つCoCaの学習プロセスは、多様なデータソースから表現を学習することを保証します。モデルは2つの大規模データセットを組み合わせて学習される:
1.JFT-3Bデータセット:JFT-3Bデータセット**:これは、関連するラベルを持つ画像の大規模なコレクションである。ラベルは短いテキスト記述として扱われるため、CoCaは多様な画像とテキストのペアから学習することができる。
2.ALIGNデータセット:このデータセットは、関連するaltテキスト説明を持つ画像を提供し、より自然な言語監視を提供する。
学習プロセスでは、65,536の画像-テキストペアのバッチサイズを使用し、その半分はJFTから、半分はALIGNから得られる。この大きなバッチサイズは効果的な対比学習を可能にし、各肯定的な画像-テキストペアに対して豊富な否定的な例を提供する。
CoCaは50万ステップ学習され、これはJFTでは約5エポック、ALIGNでは約10エポックに相当する。この大規模な学習により、モデルは頑健で汎化可能な表現を学習することができる。
最適化処理にはAdafactor optimizerを使用。このオプティマイザは大規模な学習に対してメモリ効率が良いように設計されている。オプティマイザのパラメータはβ1 = 0.9、β2 = 0.999、重み減衰0.01に設定されている。これらの設定は学習を安定させ、overfittingを防ぐのに役立つ。
学習率のスケジュールには、学習ステップの最初の2%にウォームアップ期間があり、その後線形減衰が続く。このスケジュールはモデルを効果的に収束させるのに役立ち、小さな更新から始めて徐々に学習率を上げ、最終的な表現を微調整するために学習率を下げる。
事前学習では、画像は288x288ピクセルの解像度で処理される。メイン学習段階の後、モデルはさらに576x576の高解像度で1エポック学習される。この最終的な高解像度トレーニングは、モデルがきめ細かい視覚的ディテールを捉えるのに役立つ。
ビデオ認識のためのCoCa
静止画像だけでなく、CoCaの学習された視覚表現は動的なデータにも適応するため、アーキテクチャを変更することなくビデオ認識タスクに取り組むことができます。下図は、CoCaがどのようにビデオ認識に適応しているかを示している。
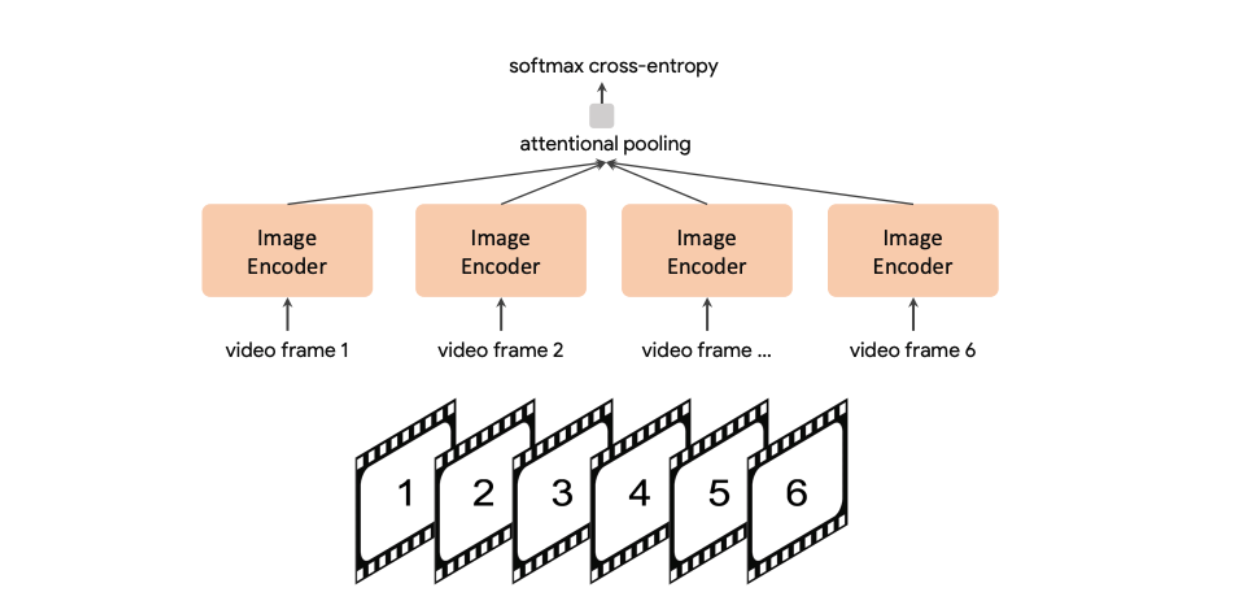 図7- ビデオ認識のためのCoCaプロセス.png
図7- ビデオ認識のためのCoCaプロセス.png
図7:動画認識のためのCoCaのプロセス動画認識のためのCoCaのプロセス(英語
映像認識のプロセスは以下の通りである:
1.ビデオからの個々のフレームは、画像エンコーダーによって処理される。これにより、CoCaは各フレームのビジュアルコンテンツを独立してキャプチャすることができます。
2.複数のフレーム(図では6つのフレーム)からの出力は、注意プーリングを使用して結合される。このプーリング機構により、モデルはビデオの時間的次元にわたって情報を集約することができる。
3.ソフトマックス・クロスエントロピー](https://zilliz.com/learn/decoding-softmax-understanding-functions-and-impact-in-ai)損失が、分類のためにプールされた表現に適用される。これにより、集約されたフレーム表現に基づいて、ビデオのアクションやコンテンツを予測するようにモデルを訓練する。
ビデオ認識へのこのアプローチはシンプルでありながら効果的である。CoCaの学習された表現は、コアモデルのアーキテクチャを変更することなく、時間データを扱うために簡単に適応させることができるため、CoCaの柔軟性を実証している。
このアプローチの有効性は、CoCaによって学習された視覚表現が、静的な視覚入力と動的な視覚入力の両方に関連する基本的な視覚特徴を捉えていることを示している。この汎化能力は、CoCaモデルの重要な強みである。
ベンチマーク結果
CoCaの設計の多用途性は、ベンチマークデータセットにおける性能によってさらに証明されている。ここでは、CoCaと他の画像テキスト基盤やタスクに特化したモデルとの包括的な比較を行う。
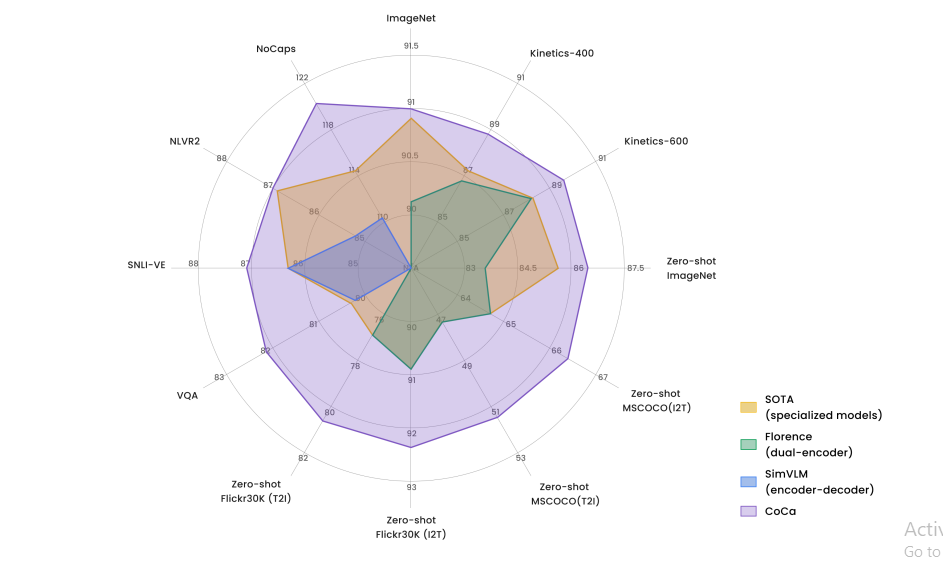 図8- CoCaと他の画像テキスト基盤モデルの比較.png
図8- CoCaと他の画像テキスト基盤モデルの比較.png
図8:CoCaと他の画像テキスト基盤モデルとの比較_」(英語)
主要な結果をいくつか見てみよう:
ImageNet分類:CoCaは、画像認識モデルの標準的なベンチマークであるImageNet classificationタスクで印象的な結果を達成しました。モデルが明示的に訓練されていないカテゴリに画像を分類しなければならないゼロショット分類において、CoCaは86.3%のトップ1精度を達成しました。これは、追加トレーニングなしで、学習した表現を新しいタスクに移行するモデルの能力を実証している。
フリーズしたエンコーダーと学習された分類ヘッドにより、CoCaは90.6%のトップ1精度を達成した。これは、モデル全体を微調整しなくても、事前学習で学習された表現が画像分類に非常に有効であることを示している。
ImageNetデータセットで微調整を行った場合、CoCaは91.0%のトップ1精度を達成する。この結果は画像分類に特化したモデルを凌駕しており、CoCaの統一的な学習アプローチの威力を浮き彫りにしている。
ビデオアクション認識:CoCaは静止画像に対してのみトレーニングされているにも関わらず、ビデオアクション認識タスクにおいて顕著な性能を発揮します。Kinetics-400データセットにおいて、CoCaは微調整により88.9%のトップ1精度を達成。Kinetics-600では89.4%のトップ1精度を達成。難易度の高いMoments-in-Timeデータセットでは、CoCaは49.0%のトップ1精度を達成した。これらの結果は、CoCaが動的な視覚入力に対して学習した表現を汎化する能力を実証している。
画像テキスト検索:CoCaは、視覚表現とテキスト表現の整合を必要とする、クロスモーダル検索タスクにおいて優れた性能を発揮する。Flickr30Kデータセット(1Kテストセット)において、CoCaは画像からテキストへの検索で92.5%のリコール@1、テキストから画像への検索で80.4%のリコール@1を達成した。より大きなMSCOCOデータセット(5Kテストセット)では、CoCaは画像からテキストへの検索で66.3%のrecall@1、テキストから画像への検索で51.2%のrecall@1を達成した。これらの結果は、CoCaがモダリティを超えて整列した表現を作成する能力を実証している。
視覚的質問応答:VQA v2データセットでは、画像に関する質問に回答するために、視覚とテキストの両方の入力を理解する必要がありますが、CoCaは、テスト-stdスプリットで82.3%の精度を達成し、新たな最先端を打ち立てました。この結果は、CoCaの画像とテキストの関係を推論する能力を示しています。
視覚的関与と推論:CoCaは、視覚入力とテキスト入力について、より複雑な推論を必要とするタスクで高いパフォーマンスを発揮する。SNLI-VEの視覚的含意タスクにおいて、CoCaはテストセットで87.1%の精度を達成した。NLVR2視覚推論タスクでは、CoCaはテストP分割で87.0%の精度を達成した。これらの結果は、CoCaが視覚情報とテキスト情報の関係を微妙に理解する能力を持つことを示している。
**画像キャプションCoCaは、難易度の高いNoCaps画像キャプション・ベンチマークで新たな基準を打ち立て、CIDErスコア120.6を達成しました。この結果は、CoCaの生成能力と、トレーニング中に見られなかった新しいオブジェクトやシーンを記述する能力を浮き彫りにしています。
これらのベンチマーク結果は、CoCaが視覚と言語の幅広いタスクにおいて汎用性があり、有効であることを示しています。このモデルは、特定のアプリケーションのために設計された特殊なアーキテクチャを凌駕することが多く、統一されたトレーニングアプローチの威力を示しています。
スケーリング性能
CoCaの統一されたアプローチにより、モデルのサイズが大きくなるにつれてパフォーマンスが向上します。
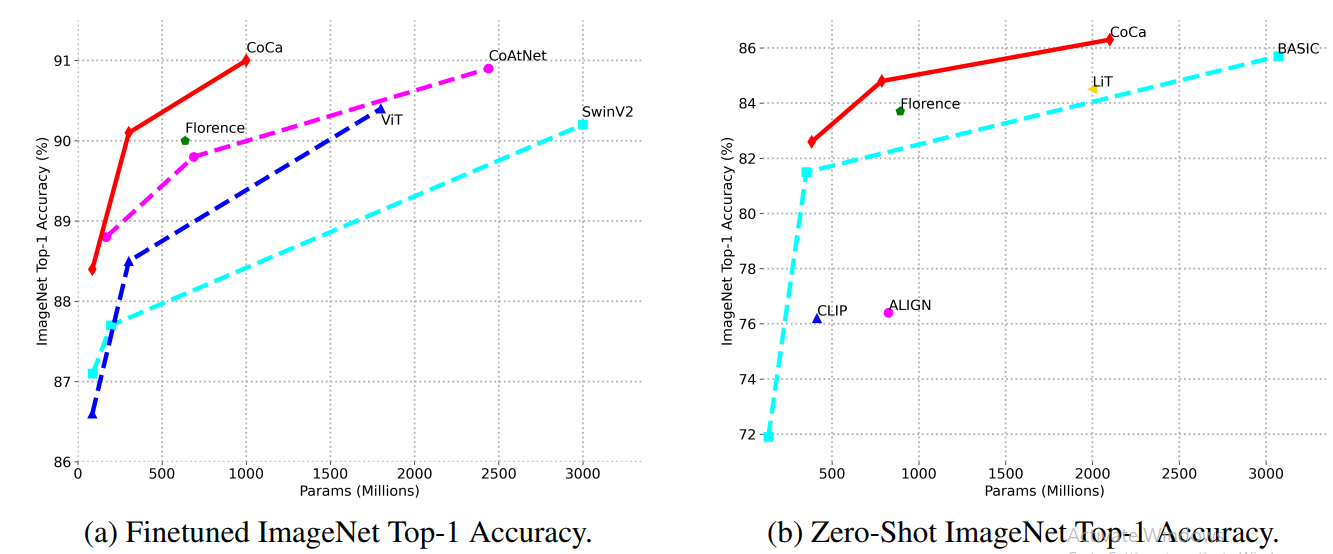 図9- モデルサイズの画像分類スケーリング性能.png
図9- モデルサイズの画像分類スケーリング性能.png
図9:モデルサイズの画像分類スケーリングパフォーマンス
上の画像は、ファインチューニングとゼロショットの両方のImageNet分類について、他のモデルと比較したCoCaのスケーリング挙動を示しています。
微調整されたImageNetのパフォーマンスにおいて、CoCaはCoAtNetやViTのような他のモデルと比較して、より少ないパラメータでより高い精度を達成しています。この効率性はCoCaの統一された学習アプローチによるもので、同じ量のデータからより効果的な表現を学習することができます。
ゼロショットImageNetの性能は、さらに素晴らしいスケーリングを示しています。CoCaのゼロショット精度はモデルサイズと共に急速に向上し、 CLIP やALIGNといった他のモデルを凌駕しています。このことは、CoCaが追加のトレーニングなしで未知のタスクに適用できる、より一般化可能な表現を学習することを示唆しています。
これらのスケーリング結果は、より大きなCoCaモデルであっても、様々なタスクにおいてより良い性能を発揮できることを示している。このスケーラビリティはCoCaアプローチの重要な利点であり、モデルサイズと訓練データを増やすことによる将来の改善のための明確な道筋を示唆している。
なぜCoCaは機能するのか?主なイノベーション
CoCaの素晴らしいベンチマーク結果とスケーラビリティは、以前のモデルとは異なるいくつかの重要な設計革新に起因している:
統一アーキテクチャ:シングルエンコーダ、デュアルエンコーダ、エンコーダデコーダモデルの要素を組み合わせることで、CoCaは単一のアーキテクチャで幅広いタスクを処理することができます。この統一されたアプローチにより、このモデルは複数の視覚タスクや言語タスクに有用な表現を学習することができる。
デカップルド・テキスト・デコーダー:テキストデコーダをユニモーダル部分とマルチモーダル部分に分離したことは、極めて重要な革新である。ユニモーダル部分は、CoCaがクロスモーダル検索のようなタスクに不可欠な純粋なテキスト表現を作成することを可能にする。マルチモーダル部分は、共同推論を必要とするタスクのために、画像とテキスト情報を融合することを可能にする。
**共同トレーニングの目的コントラスト損失とキャプション損失の両方を使用することで、CoCaは整列表現と生成能力を同時に学習することができる。コントラスト損失は、関連する画像とテキストのペアに対して類似した表現を作成するようモデルを促し、キャプション損失は、画像に対して説明的なテキストを生成するようモデルを訓練する。
**効率的なトレーニングCoCaの設計により、1回のフォワードパスで両方の損失を計算することができる。この効率性は、異なる目的のために別々のパスを必要とするアプローチに比べ、トレーニングの高速化と計算リソースの有効活用を可能にし、大きな利点となります。
大規模な事前学習:JFT-3Bの画像-ラベルペアとALIGNの画像-テキストペアの組み合わせで学習することで、CoCaは豊富で一般化可能な表現を学習します。この多様な学習データにより、CoCaは幅広い視覚概念とそのテキスト説明を理解することができます。
マルチモーダルAIを強化するためのCoCaとベクトルデータベースの統合
実世界のアプリケーションでCoCaの強力な表現をさらに活用するために、MilvusやZilliz Cloudのようなベクトルデータベースと統合することで、マルチモーダル埋め込みデータの効率的な保存と検索が可能になり、大規模なマルチメディア検索と分析のための強力なシステムを構築することができます。ベクトルデータベースは、高次元のベクトルを効率的に保存し、検索するように設計されており、CoCaのようなモデルによって生成されたembeddingsを管理するのに理想的です。
CoCaは、画像とテキストの両方について、共有された埋め込み空間に整列された表現を生成する。これらの埋め込みはベクトルデータベースに保存することができ、画像とテキストの大規模なデータセットにわたる高速で効率的な類似検索を可能にする。この組み合わせは、いくつかの強力なアプリケーションを可能にする:
1.マルチモーダル検索**:ユーザーは、テキストクエリを使用して画像を検索したり、画像入力に基づいて関連するテキストを検索したりすることができる。ベクトル・データベースは、埋め込み画像の余弦類似度に基づいて、最も類似したアイテムを素早く検索することができる。
2.スケーラブルなゼロショット分類:CoCaのゼロショット分類機能は、クラス埋め込みをベクトルデータベースに格納し、最近傍探索を実行することで、膨大な画像コレクションに拡張することができます。
3.コンテンツベースの推薦:CoCaの埋め込みを推薦システムに格納することで、ベクトルデータベースはモダリティを超えたコンテンツベースの推薦を可能にする。
4.効率的な微調整:ドメインに特化したアプリケーションの場合、ベクトル類似性検索を使うことで、関連するデータのサブセットを素早く特定することができ、CoCaモデルをより効率的に微調整することができる。
Milvus:CoCaおよびマルチモーダルAIアプリケーションのための強力なベクトルデータベース
Milvusは、CoCaとの統合に特に適したオープンソースの高性能ベクトルデータベースです。MilvusがCoCaベースのアプリケーションをどのように強化できるかをご紹介します:
1.ハイブリッドおよびマルチモーダル検索**:Milvusはベクトル類似性検索と従来のフィルタリングを組み合わせることができ、意味的類似性とメタデータの両方を考慮した複雑なクエリを可能にします。
2.高次元インデックス**:Milvusは高次元ベクトルの効率的なインデックス作成とクエリをサポートしており、これはCoCaの埋め込み(数百から数千の次元を持つことがある)を管理する上で非常に重要です。
3.スケーラビリティ**:Milvusは水平方向に拡張できるように設計されており、数十億のベクトルを扱うことができます。このスケーラビリティはCoCaの大規模データセットの処理能力にマッチしている。
4.複数のインデックスタイプ**:Milvusは様々なシナリオに最適化された15のインデックスタイプを提供しており、ユーザは特定のニーズに基づいてクエリの速度と精度のバランスを取ることができる。
5.GPU アクセラレーション**:Milvusは、インデックス作成と検索操作の両方にGPUアクセラレーションを活用することができ、CoCaのGPUベースの推論を補完し、エンドツーエンドのパフォーマンス最適化を実現します。
6.リアルタイム更新: Milvusはリアルタイムの挿入と更新をサポートし、CoCaベースのシステムが大きなダウンタイムなしに継続的に新しいデータを取り込むことを可能にします。
CoCaとMilvusのようなベクターデータベースの相乗効果は、スケーラブルで効率的かつ強力なマルチモーダルAIシステムを構築するための新たな可能性を開きます。両技術の進歩が進むにつれ、基礎モデルとベクターデータベースの両方の長所を活用した、ますます洗練されたアプリケーションが登場することが期待される。
コカの意味と今後の方向性
CoCaが進歩し続けるにつれて、将来的にマルチモーダルモデルがどのように開発され、展開されるかを再定義する可能性を秘めている。まず、AIの分野に対する将来の重要な影響から見てみよう:
モデル開発の簡素化:異なるタスクに特化したモデルを作成する代わりに、研究者や開発者は、幅広いアプリケーションに単一のCoCaモデルを使用できる可能性がある。これにより、開発プロセスが合理化され、タスクに特化したアーキテクチャの必要性が減少する可能性がある。
転移学習の向上:CoCaの強力なゼロショットと少数ショットの性能は、ラベル付けされたデータが限られているタスクに特に有用である可能性を示唆している。これにより、大規模なラベル付きデータセットが利用できない領域への高度なAI技術の適用が可能になる。
マルチモーダルAIシステム:CoCaの視覚と言語の両方のタスクを処理する能力は、モダリティを超えてコンテンツを理解し生成できる、より洗練されたAIシステムにつながる可能性がある。これにより、より自然で多様な人間とAIの相互作用が可能になる。
AI開発の効率化:CoCaの統一的なアプローチは、AIの研究開発における計算資源の効率的な利用につながる可能性がある。複数のタスクに対して単一のモデルをトレーニングすることで、研究者はAIシステム開発の全体的な計算コストを削減できる可能性がある。
**今後の研究の方向性は以下の通りである。
より大規模なモデルやデータセットへの拡張:CoCaの印象的なスケーリング挙動を考えると、さらに大きなモデルサイズを探求し、より大きく多様なデータセットでトレーニングすることで、パフォーマンスをさらに向上させることができるだろう。
新たなモダリティを取り入れる:CoCaのアプローチを拡張し、音声や動画など他のモダリティを含めることで、さらに汎用性の高いAIモデルを実現できる可能性があります。
少数ショット学習能力の探求:CoCaは強力なゼロショット性能を示すが、その数ショット学習能力を調査することで、最小限の追加訓練で特定のタスクにモデルを適応させる新しい方法が明らかになるかもしれない。
ドメイン特異的な適応を探る:CoCaを特定のドメインや産業に効率的に適応させる方法を調査することで、ヘルスケア、金融、科学研究などの新しいアプリケーションを解き明かすことができる。
結論
CoCaは、異なる学習アプローチを単一の効率的なモデルに統合することで、画像-テキスト基盤モデルの重要な進歩を示している。その汎用的な学習アプローチのおかげで、画像分類、ビデオ認識、視覚的質問応答、画像キャプション付けなど、様々なタスクに優れている。ゼロショットや少数ショットのシナリオにおけるその強力な性能により、多くのAIアプリケーションにとって価値ある基礎となります。
CoCaをMilvusのようなベクトルデータベースと統合することで、大量のマルチメディアデータを扱うスケーラブルで効率的なマルチモーダルシステムが可能になる。AIの研究が進むにつれ、CoCaのようなモデルは、多様なデータタイプを理解できる、より統合されたシステムへの道を開く。
その他のリソース
論文
CoCa: Contrastive Captioners are Image-Text Foundation Models (arxiv.org)](https://arxiv.org/abs/2205.01917)
[ [2108.07258] On the Opportunities and Risks of Foundation Models (arxiv.org)](https://arxiv.org/abs/2108.07258)
୧[2103.00020↩] Learning Transferable Visual Models From Natural Language Supervision (arxiv.org)](https://arxiv.org/abs/2103.00020)
Microsoft COCO Captions:Data Collection and Evaluation Server (arxiv.org)](https://arxiv.org/abs/1504.00325)
ベクトルデータベースとは何か、どのように機能するのか](https://zilliz.com/learn/what-is-vector-database)
Milvusでマルチモーダル検索システムを構築する ](https://zilliz.com/blog/how-vector-dbs-are-revolutionizing-unstructured-data-search-ai-applications)
RAGとは ](https://zilliz.com/learn/Retrieval-Augmented-Generation)
コントラストキャプションによる画像-テキスト事前学習 (research.google)](https://research.google/blog/image-text-pre-training-with-contrastive-captioners/#:~:text=We%20propose%20CoCa%2C%20a%20unified,encoder%20and%20encoder%2Ddecoder%20paradigms)
 Denis Kuria
Denis KuriaDenis is a machine learning engineer who enjoys writing guides to help other developers. He has a bachelor's in computer science and loves hiking and exploring the world.