




A hassle-free vector database for GenAl
Free yourself from database setup, maintenance, and scaling concerns. Give your GenAl apps a powerful, serverless database that grows with your needs.
Up to 50x cost savings with automatic scaling
Start small, and compute resources dynamically adjust to match your app’s demands. Perfect for fluctuating workloads. Our serverless service ensures you only pay for what you use-never for idle servers.

Data portability for evolving needs
Transfer your data to Zilliz dedicated clusters or open-source Milvus as your needs change. Retain control over your data and infrastructure choices with one-click migration options.
Why is our serverless so cost-efficient?
Zilliz Cloud Serverless is 50x more cost-efficient than in-memory vector databases. It uses a tiered storage system with DRAM, SSD, and object storage to automatically optimize data placement. This approach ensures fast access for active data while reducing costs for less frequently used information, all without manual management.
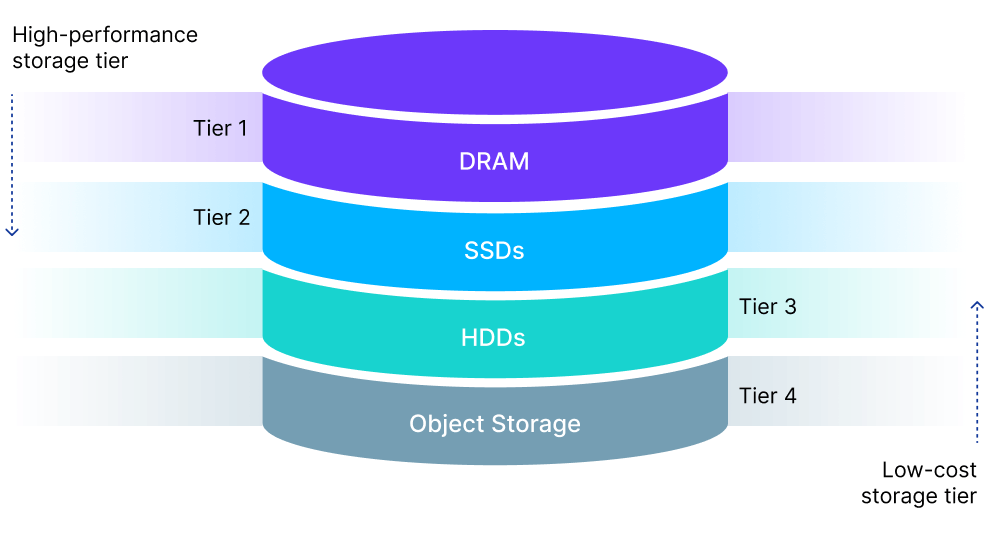
Tiered Storage
Implement tiered storage to reduce costs by storing infrequently accessed data on less expensive hardware.
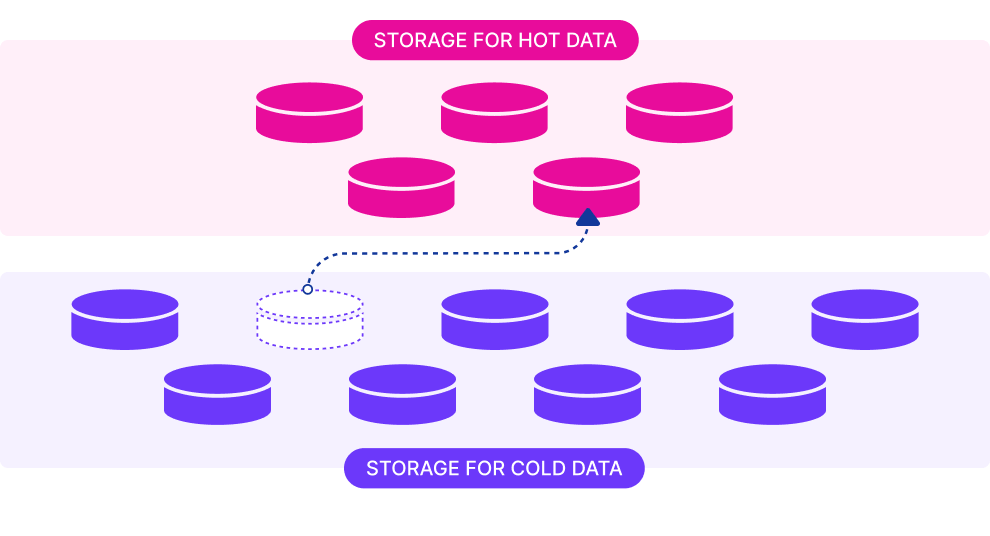
Hot Cold Data Separation
Maintain high performance by storing frequently accessed data on high-speed local disks.
Benchmarks
Recall
Dataset / Size
8.8 M
1536 dim
10 M
768 dim
138 M
1536 dim
Recall
ベクトルデータベース機能を完全装備で、より速い構築へ

高性能ベクトル検索
ディープニューラルネットワークやその他の機械学習(ML)モデルが生成する膨大な埋め込みベクトルを効率的に保存、インデックス作成、管理することができます。

低遅延かつ高リ再現率
低遅延と高再現率でデータに対する信頼性を高め、より確実で正確なリアルタイムの意思決定。
- もっと詳しく

ハイブリッド検索
複数のベクターフィールドでのクエリを可能にし、より正確な検索結果のために、マルチモーダルやスパース・デンス、高密度テキストの組み合わせをサポート。
- もっと詳しく

多様な類似性指標
コサイン、ユークリッド、内積などの類似性指標を正しく選択して、分類やクラスタリングのパフォーマンスを向上させましょう。
- もっと詳しく

調整可能な一貫性
複数の一貫性レベルでデータの精度とパフォーマンスを柔軟に調整できるようになり、あなたのアプリケーションの独特なニーズに基づいて、それらを整理することができます。

必要に応じたスケーリング
コンポーネントベースのアーキテクチャにより、横方向のスケーリングは容易で、ワークロードの変動にかかわらず、高いパフォーマンスと効率を確保できます。