




物体検出とは?総合ガイド
物体検出は、ニューラルネットワークを使用して、画像やビデオ内の人間、建物、車などの物体を分類し、位置を特定するコンピュータビジョン技術である。
シリーズ全体を読む
- Cross-Entropy Loss: Unraveling its Role in Machine Learning
- Batch vs. Layer Normalization - Unlocking Efficiency in Neural Networks
- Empowering AI and Machine Learning with Vector Databases
- Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
- Vector Databases: Redefining the Future of Search Technology
- Local Sensitivity Hashing (L.S.H.): A Comprehensive Guide
- Optimizing AI: A Guide to Stable Diffusion and Efficient Caching Strategies
- Nemo Guardrails: Elevating AI Safety and Reliability
- Data Modeling Techniques Optimized for Vector Databases
- Demystifying Color Histograms: A Guide to Image Processing and Analysis
- Exploring BGE-M3: The Future of Information Retrieval with Milvus
- Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
- TF-IDF - Understanding Term Frequency-Inverse Document Frequency in NLP
- Understanding Regularization in Neural Networks
- A Beginner's Guide to Understanding Vision Transformers (ViT)
- Understanding DETR: End-to-end Object Detection with Transformers
- Vector Database vs Graph Database
- What is Computer Vision?
- Deep Residual Learning for Image Recognition
- Decoding Transformer Models: A Study of Their Architecture and Underlying Principles
- What is Object Detection? A Comprehensive Guide
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Algorithmic)
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Methodological)
- Understanding CoCa: Advancing Image-Text Foundation Models with Contrastive Captioners
- Florence: An Advanced Foundation Model for Computer Vision by Microsoft
- The Potential Transformer Replacement: Mamba
- ALIGN Explained: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
画像やビデオ内のオブジェクトの位置を特定することが重要な、スポーツ分析システム用のコンピュータビジョン技術を開発しているとします。試合映像から選手を検出し追跡することで、特定のエリアにいる選手の数を数えたり、ゾーンをまたいだ選手の動きを監視したり、重要な場所にいる選手の滞在時間を分析したりすることができます。このような詳細なレベルを達成するためには、 オブジェクト検出 - 画像やビデオ内のオブジェクトを識別するだけでなく、その正確な位置を特定する コンピュータビジョン タスクが必要です。
画像全体にラベルを割り当てる単純な画像分類とは異なり、物体検出は物体のインスタンスを見つけ、バウンディングボックスを通してその位置をマークする。このカスタムオブジェクト検出モデルは、顔認識、セキュリティ監視、医療画像など、私たちが日常的に使用する多くの AIアプリケーションにおいて重要なコンポーネントです。
この記事では、物体検出の仕組み、よく使われるモデルやアルゴリズム、直面している課題、そしてこの技術の将来について理解するのに役立ちます。
物体検出とは何か?
物体検出は コンピュータビジョン技術の1つで、 ニューラルネットワークを使用して、画像やビデオ内の人間、建物、車などの物体を分類し、位置を特定する。物体検出モデルは画像を入力とし、検出された物体の輪郭を示すバウンディングボックスの座標を、それらの物体を識別するラベルとともに出力する。画像には複数のオブジェクトが存在し、それぞれにバウンディングボックスとラベルがあります。これらのオブジェクトは、画像の異なる場所にある複数の車のように、異なる場所にあることもあります。この概念は一般的にマルチオブジェクト検出として知られています。
オブジェクト検出をよりよく理解するために、類似のタスクと比較することが役立ちます:
画像分類:** このタスクは、画像内の特定のオブジェクトの存在を判断するだけです。例えば、画像に犬が写っているか?
オブジェクト検出: **オブジェクトのクラスを決定し、バウンディングボックスを使用して画像内の位置を特定します。例えば、画像内の犬はどこにいて、どんな種類の犬なのか?
画像セグメンテーション:** セグメンテーションはピクセルレベルの精度を提供します。オブジェクト検出のようにオブジェクトの周りにボックスを描くだけでなく、各ピクセルを特定のオブジェクトクラスに割り当てることで、正確な形状を定義します。例えば、どのピクセルが犬に属するのか、犬の正確な形状は?
 画像分類 vs. オブジェクト検出 vs. 画像セグメンテーション.png
画像分類 vs. オブジェクト検出 vs. 画像セグメンテーション.png
画像分類 vs. オブジェクト検出 vs. 画像セグメンテーション|出典
##物体検出の仕組み
物体検出システムには、物体を分類し、位置を特定するために連携するいくつかの重要なコンポーネントがあります。
特徴抽出
バウンディングボックス
物体の分類と位置特定
特徴抽出
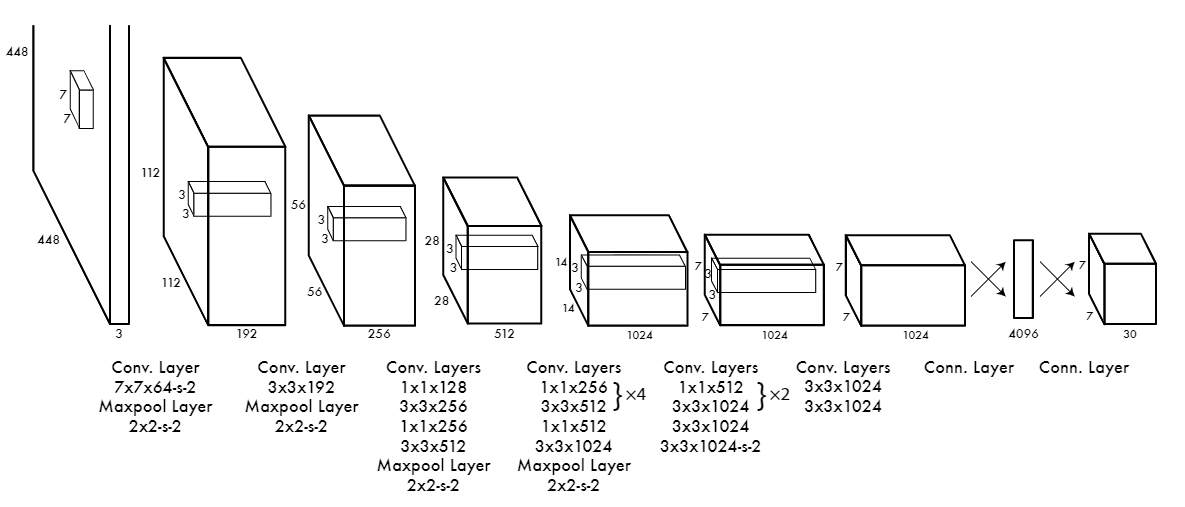
物体検出の最初のステップは、画像から重要な特徴を抽出することである。物体検出における特徴とは、エッジ、コーナー、テクスチャなど、物体を定義するのに役立つ特徴である。[畳み込みニューラルネットワーク] (CNNs)は、最新の深層学習ベースのアプローチにおいて、特徴抽出器として一般的に使用されている。CNNは、畳み込み層を通して画像にフィルターを適用することで、自動的に学習し、特徴を抽出する。しかし、この目的に使われるアルゴリズムはCNNだけではない。他の手法としては、RPN(Region Proposal Networks)、HOG(Histogram of Oriented Gradients)、SIFT(Scale-Invariant Feature Transform)などがある。
入力画像がCNNに入力されると、複数の畳み込み層を通過する。ネットワークは初期の層で、画像認識におけるエッジやコーナーのような基本的な特徴を識別する。画像がより深い層を通過するにつれて、ネットワークは物体の一部のような、より複雑な特徴を学習する。この階層的なプロセスは、ネットワークが異なる物体の本質的な特徴を理解し、より効果的に検出するのに役立つ。
畳み込みニューラルネットワーク(CNN)アーキテクチャ.png
畳み込みニューラルネットワーク(CNN)アーキテクチャ|出典
バウンディングボックス
バウンディング・ボックスとは、検出されたオブジェクトの周囲に描かれる矩形のことです。4つの値で定義されます:
(𝑥、幅 𝑦、高さ 𝑤)。モデルによって、座標(𝑥, ᵆ)はボックスの中心(YOLOのようなモデル)または左上隅(Faster R-CNNのようなモデル)を表し、ǔとǔはボックスの寸法を決定する。ディープラーニングモデルでは、バウンディングボックスの座標は回帰によって調整されます。これは、ニューラルネットワークが予測されたボックスの座標を、オブジェクトによりフィットするように改良するプロセスです。モデルはオフセット(Δ𝑥, Δ𝑦, Δ𝑮**)を予測し、バウンディングボックスの位置とサイズを調整します。
予測されたバウンディングボックスがグランドトゥルースとどの程度一致するかを評価するために、Intersection over Union (IOU)と呼ばれるメトリックが使用されます。これは、予測されたバウンディングボックスと実際のバウンディングボックスの重なりを測定します。数学的には次のように定義される:
IoU=AIntersectionAUnion
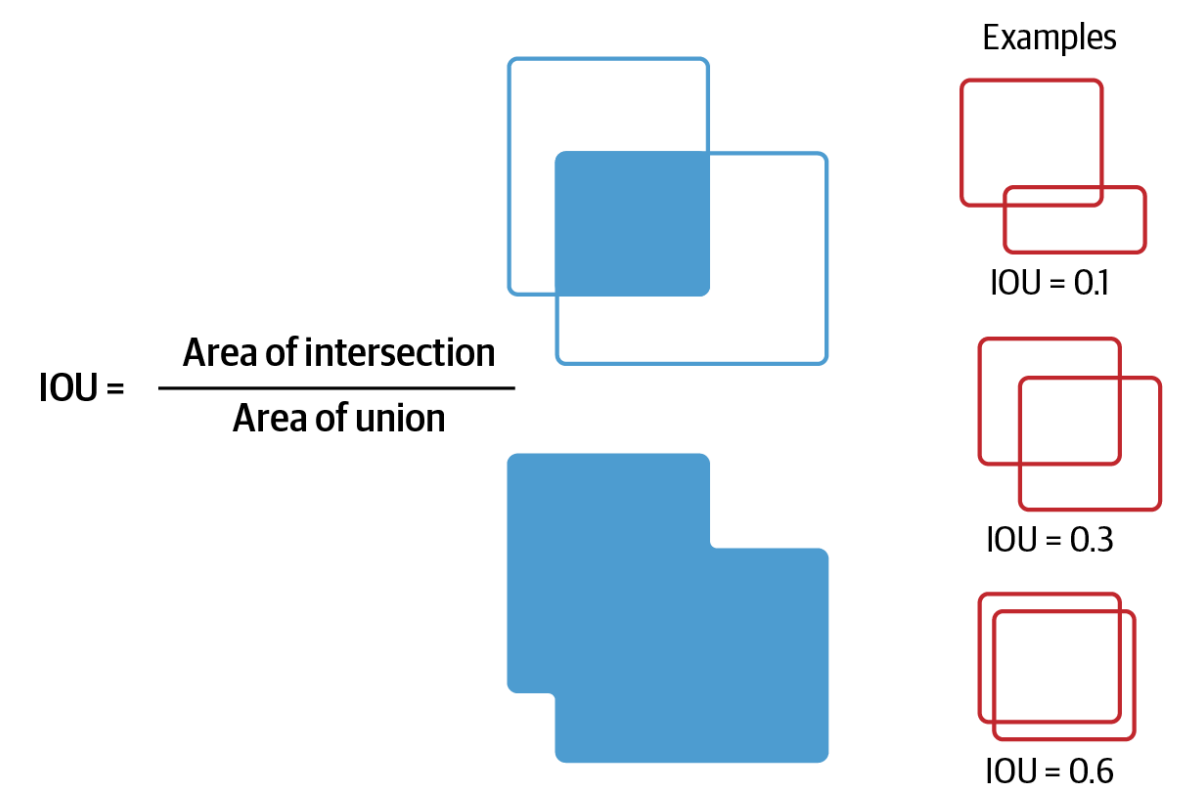 IOUメトリック.png
IOUメトリック.png
IOUメトリック|出典
IoUの値が高いほど、予測が実際の物体と密接に一致していることを意味し、値が低いほど、ローカライゼーションが不十分であることを示す。
分類
物体がローカライズされると、物体検出システムは検出された各物体に「車」や「人」などのラベルを割り当てる。分類は多くの場合、CNNの完全接続層を使用して実行され、抽出された特徴を入力とし、クラス確率を出力する。
ディープラーニングは現在、主要なアプローチであるが、伝統的な物体検出方法もまだ存在する。これらの手法は、ハリスコーナー検出器、SIFT(Scale-invariant feature transform)、SURF(Speeded-up robust features)、HOG(Histogram of Oriented gradients)など、手作業で設計された特徴やアルゴリズムを使用することが多い。
これらの伝統的な物体検出方法を比較し、最新のディープラーニングベースの方法との違いを理解しよう。
| :-----------------------:| :-----------------------------------------------------------------------------------------------:| :------------------------------------------------------------------------------------: | 特徴抽出** | ディープラーニングに基づく手法 | 伝統的な手法 | 特徴抽出 | 特徴抽出(Feature Extraction)|多層レイヤーを用いてデータから自動的に特徴を学習する。 | コーナー、エッジ、グラデーションのような手作業の特徴に頼る。 | | スケーラビリティ|大規模なデータセットや複雑な実環境にも対応可能。 | 複雑な実世界のシナリオや大規模なデータセットに苦戦する。 | | スピード|YOLOやSSDのような最新のモデルは、リアルタイムのパフォーマンスのために設計されている。 | 手作業による抽出と反復アルゴリズムへの依存のため遅い。 | | 精度|深い特徴学習と異なるタスクにうまく汎化する能力により、精度が高い。| 特に視点、スケール、照明の変化に敏感。| | 手法|CNN、YOLO、R-CNN、SSD、EfficientDet.、ハリスコーナー検出器、SIFT、SURF、HOG。 | | リソース要件**|多くの場合、トレーニングのために大きな計算能力(GPU)と大規模なデータセットを必要とする。 | 計算集約度は低いが、専門家が設計した特徴を必要とする。 |
よく使われる物体検出モデルの説明
物体検出では、いくつかの有力なディープラーニング・モデルが台頭しており、それぞれに独自の利点がある。人気のあるディープラーニングの異常検知モデルには、以下のようなものがある:
YOLO
R-CNNファミリー
SSD(シングルショット・マルチボックス検出器)
EfficientDet
YOLO
 YOLO建築.png
YOLO建築.png
YOLO建築|ソース
YOLO(You Only Look Once)は、シンプルでありながら非常に効率的なオブジェクト検出アーキテクチャです。予測時間に関しては最速の部類に入る。そのため、防犯カメラのような多くのリアルタイムシステムで使用されている。物体検出を2段階のアプローチで深く学習する他のモデル(最初に領域を提案し、次に物体を分類する)とは異なり、YOLOは一度にすべてを行う。入力画像をグリッドに分割し、同時に各グリッドセルのバウンディングボックスとオブジェクトクラスを予測する。このグリッドベースの構造により、YOLOはネットワークを1回通過するだけで高速な予測を行うことができ、処理時間を大幅に短縮することができる。
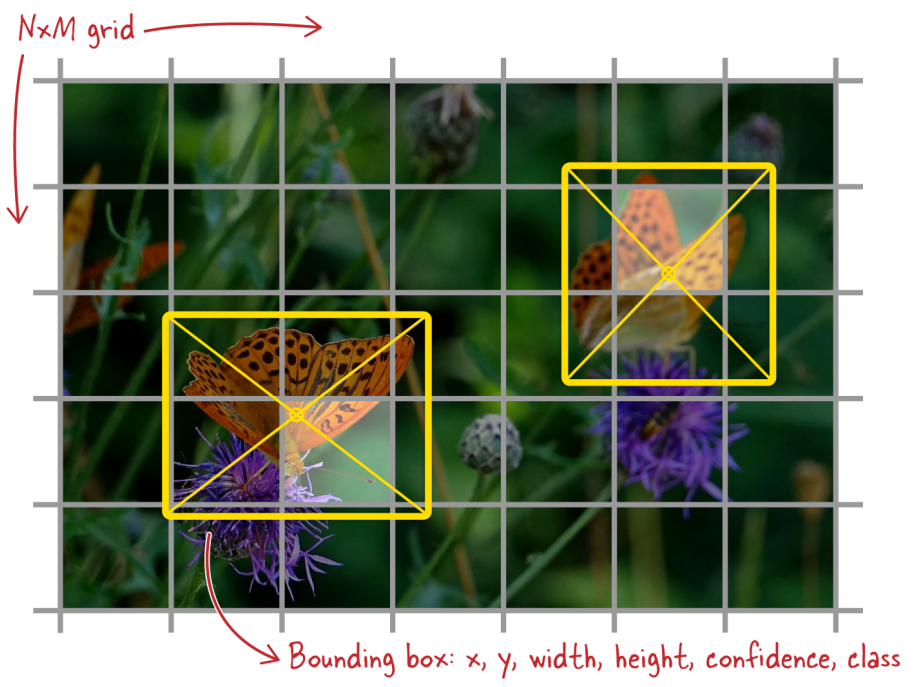 YOLOグリッド.png
YOLOグリッド.png
YOLOグリッド|出典
x, y:** グリッドセルに対するバウンディングボックスの中心の座標。
w, h: バウンディングボックスの幅と高さは、画像全体にスケーリングされます。
Confidence: 箱がオブジェクトを含む確率。
Class: 特定のクラスに属するオブジェクト。
しかし、YOLOはスピードに優れている反面、特に小さな物体を検出する場合、精度が犠牲になる可能性がある。これは、YOLOが入力画像をグリッドに分割し、各グリッドセルが1つのオブジェクトしか予測できないためである。小さな物体が1つのグリッドセル内に収まったり、複数のグリッドセルの境界に重なったりすると、YOLOはその物体の位置を正確に特定したり、周囲の物体から区別したりするのに苦労することがある。その結果、小さな物体は見逃されたり、不正確に分類されたりする。
R-CNNファミリー
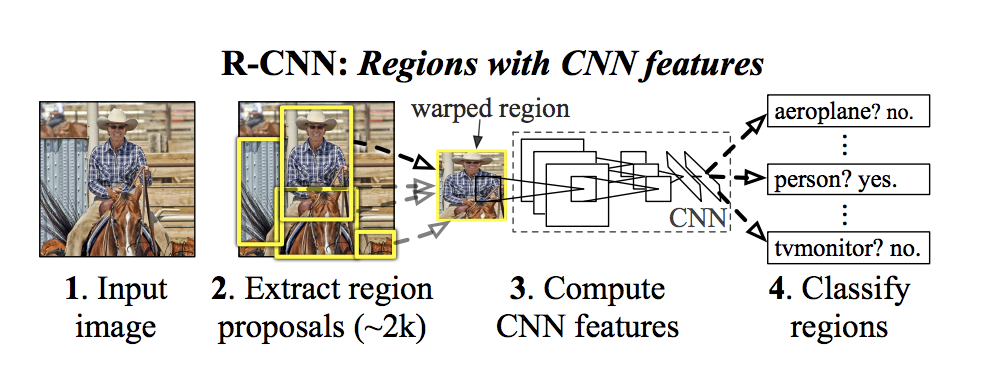 R-CNNアーキテクチャ.png
R-CNNアーキテクチャ.png
R-CNNアーキテクチャ|ソース
Fast R-CNN](https://arxiv.org/pdf/1504.08083)やFaster R-CNNを含むR-CNN(Regions with Convolutional Neural Networks)モデルは、物体検出技術の向上において重要な役割を担っている。オリジナルのR-CNNは、まず(領域提案法を用いて)物体が入っていそうな領域を画像から見つける。次に、SVM技術を活用して、それらの領域から特徴を抽出し分類するためにCNNを使用する。Fast R-CNNは、モデルが提案されたすべての領域に対して同じ計算を再利用し、一度に複数のタスクを処理する方法を追加することで、このプロセスを高速化した。
最後に、Faster R-CNNはRegion Proposal Network (RPN)を導入することで、さらに高速化した。
SSD (シングルショット・マルチボックス検出器)
 SSD(シングルショット・マルチボックス・ディテクタ)アーキテクチャ.png
SSD(シングルショット・マルチボックス・ディテクタ)アーキテクチャ.png
SSD(シングルショット・マルチボックス・ディテクタ)アーキテクチャ|出典
YOLOと同様に、 Single Shot Multibox Detector (SSD) は画像をシングルパスで処理しますが、異なるスケールで複数の feature maps を使用することで、より洗練されたアプローチをとります。これによりSSDは様々な大きさの物体、特に小さな物体を検出することができます。SSDはFaster R-CNNよりも高速ですが、一般的にYOLOよりも精度が高く、速度と精度のバランスが保たれています。
このバランスにより、SSDは効率性と信頼性の高い検出の両方を必要とするアプリケーションに適しています。
EfficientDet
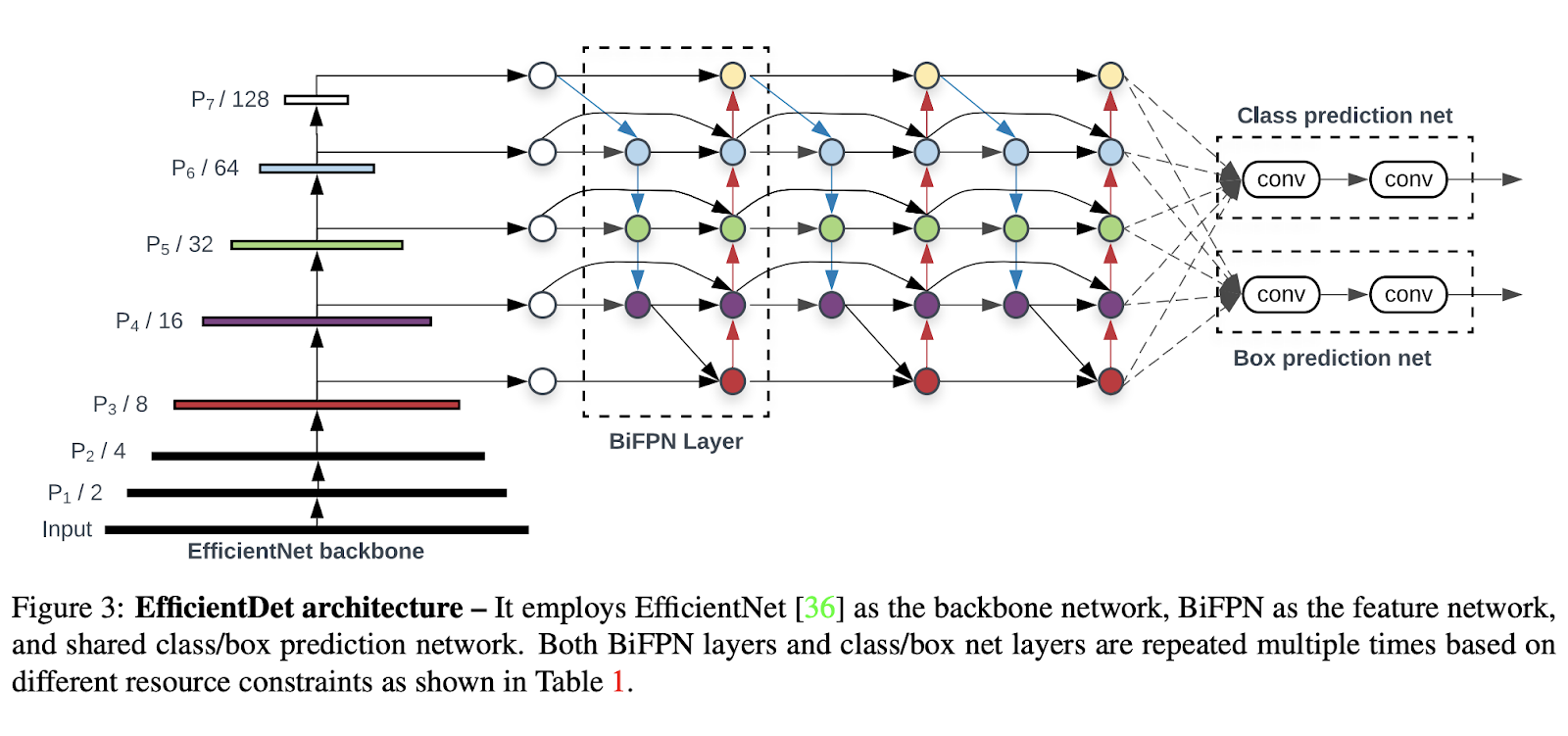 EfficientDetアーキテクチャ.png
EfficientDetアーキテクチャ.png
EfficientDetアーキテクチャ|ソース
EfficientDetは、少ない計算資源で高い精度を達成することを目指し、効率性を念頭に設計されています。双方向特徴ピラミッドネットワーク(BiFPN)を使用しており、異なるスケールの物体を検出するモデルの能力を向上させるのに役立ちます。さらに、EfficientDetは、ネットワークの深さ、幅、解像度を同時に調整する複合スケーリング手法を使用しています。
つまり、特徴抽出、分類、箱型予測ネットワークをバランスよくスケーリングし、過度の計算負荷をかけることなく高い性能を確保します。
物体検出の応用
物体検出は、機械が視覚データを解釈し理解するのに役立つ重要な技術です。様々な産業において、自動化、安全性、効率性を向上させる上で非常に重要です。以下は、実世界のシナリオにおける物体認識・検出の最も重要な応用例です:
自律走行車:*** 自律走行車システムは、車両の周囲にあるさまざまな物体を認識・識別するために、物体検出に大きく依存しています。これには、歩行者、他の車、自転車、交通標識の検出が含まれます。リアルタイム検出は、人間が関与することなく車が複雑な環境をナビゲートするのに役立つため、これらの車両の安全運転にとって重要です。
ヘルスケア:**ヘルスケア](https://zilliz.com/learn/the-role-of-vector-databases-in-patient-care)では、X線、CTスキャン、MRIなどの様々な種類のスキャンにおいて、医師や放射線技師が腫瘍、骨折、その他の状態などの異常を特定するのを支援するために、物体検出が医療用画像処理に応用されている。この技術は診断のスピードと精度を向上させるのに役立ち、がんや内蔵損傷など生命を脅かすような状況では非常に重要なものとなる。
セキュリティと監視の領域では、物体検出は、顔認識、不審な行動の検出、制限区域での不正アクセスの識別など、さまざまな目的に使用される。例えば、物体検出アルゴリズムを搭載したカメラは、自動的に個人を識別して追跡したり、公共スペースに放置された物体を検出して、潜在的なセキュリティ脅威に対するアラームを作動させることができます。
小売業と電子商取引:** 現代の店舗では、小売業や[電子商取引]の分野において、在庫の追跡やチェックアウトプロセスの自動化に物体検出が利用されている。その代表的な例がAmazon Goの店舗で、顧客は従来のレジに並ぶことなく商品を受け取り、その場を離れることができる。このシステムでは、カメラと物体検出アルゴリズムを使用して、顧客がどの商品を選んだかを自動的に追跡し、合計金額は顧客のアカウントに直接請求される。
オブジェクト検出の課題
様々なアプリケーションにおいて多くの利点があるにもかかわらず、物体検出はいくつかの技術的課題に直面している:
リアルタイム性能:***物体検出における主な課題の1つは、特に時間に敏感なアプリケーションにおいて、速度と精度のバランスをとることである。自律走行や監視カメラで使用されるようなリアルタイム・システムでは、わずか数ミリ秒での判断が求められます。自動運転車の歩行者検出のようなクリティカルなシナリオでは、検出のわずかな遅れが重大な結果につながる可能性があります。
オクルージョン:**画像内で、ある物体が他の物体を部分的に、あるいは完全に覆い隠してしまうこと。物体検出モデルは、物体を正しく識別するために物体の完全な可視性に依存しているため、これは物体検出モデルにとって大きな課題となります。
画像中の物体の大きさが大きく異なって見えることがあり、これは検出モデルにとって課題となります。物体は、カメラからの距離や実際の大きさによって、ある画像では小さく見え、別の画像では大きく見えることがあります。モデルは、このようなばらつきを処理し、異なるスケールの物体を正確に検出するのに十分頑健でなければなりません。
悪条件の照明:** 照明が悪かったり、一定していなかったりすると、特に屋外では、物体検出モデルの精度に大きな影響を与える可能性があります。
将来の傾向と進歩
物体検出技術は、技術の進歩や様々な業界への応用需要の高まりにより、常に変化しています。ここでは、エキサイティングな将来のトレンドをいくつかご紹介します:
エッジコンピューティング:*** ドローンやスマートフォンのような多くのデバイスは、デバイス上で直接物体検出のようなタスクを実行するためにAIを使用しています。これにより、処理のためにクラウドサーバーにデータを送信する必要性が減少する。例えば、Google PixelのようなAI搭載カメラを搭載した最新のスマートフォンは、リアルタイムの物体検出にエッジ・コンピューティングを使用している。
3次元物体検出:*** ロボット工学、拡張現実(AR)、仮想現実(VR)などの分野が拡大するにつれ、3次元空間の物体を検出する必要性がますます高まっている。従来の2次元検出を超える3次元物体検出は、より正確な空間モデリングを可能にします。例えば、TeslaやWaymoが開発するような自律走行車は、3D物体検出を使用して、歩行者、他の車両、環境内の障害物を識別します。
ハイブリッド・モデル:***物体検出を追跡や推論などの他のAI分野と組み合わせることで、複雑なシーンの理解や物体の行動予測など、より高度な応用が可能になる。例えば、監視システムでは、ハイブリッド・モデルは物体(人や車両など)を検出するだけでなく、時間の経過とともにその動きを追跡し、行動を予測します。
要約
物体検出は、コンピュータが視覚世界を正確に知覚・解釈できるようにする、革新的な技術として登場した。交通量の多い道路をナビゲートする自動運転車から、微妙な異常を検出する医療用画像システムまで、その応用範囲は広く、拡大し続けている。
本講演では、物体検出モデルの基本原理と、特徴抽出、バウンディングボックス、分類などの主要な構成要素について解説する。また、伝統的な手法から今日この分野で主流となっているディープラーニングベースのアーキテクチャまで、物体検出モデルの進化についても検証した。
複雑な環境下でのリアルタイム性能の達成や、オクルージョンやスケール変化への対応など、課題は残るものの、物体検出の未来は明るい。エッジコンピューティング、3D物体検出、ハイブリッドモデルの進歩は、その能力をさらに高め、新たな可能性を追求することを約束する。
関連リソース
コンピュータ・ビジョンとは](https://zilliz.com/learn/what-is-computer-vision)
ビジョントランスフォーマー(ViT)理解ガイド](https://zilliz.com/learn/understanding-vision-transformers-vit)
画像認識のための深層残差学習](https://zilliz.com/learn/deep-residual-learning-for-image-recognition)
ニューラルネットワークにおける正則化の理解](https://zilliz.com/learn/understanding-regularization-in-nueral-networks)
DETRを理解する:変換器を用いたエンドツーエンドの物体検出](https://zilliz.com/learn/detection-transformers-detr-end-to-end-object-detection-with-transformers)
画像検索のための画像埋め込み](https://zilliz.com/learn/image-embeddings-for-enhanced-image-search)
生成AIリソースハブ|Zilliz](https://zilliz.com/learn/generative-ai)
ベクターデータベースとは何か](https://zilliz.com/learn/what-is-vector-database)
Milvusベクトルデータベース入門](https://zilliz.com/learn/introduction-to-milvus-vector-database)
Zillizクラウド入門](https://zilliz.com/cloud)
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS


{kind=link}