




LLMの局限
領域特定の知識の欠如
LLMは公開されているデータのみでトレーニングされているため、一般にアクセスできない領域特定の情報、専用情報、または機密情報を欠いている可能性があります。
ハルシネーションの発生傾向
LLMは、所有している情報に基づいてのみ回答を行います。参照するデータが不足している場合、不正確または架空の情報を提供する可能性があります。
高くて遅い
LLMはクエリ内のトークンごとに課金されるため、特に繰り返しの質問は高額なコストが要ります。さらに、ピーク時の応答遅延により、迅速な回答を求めるユーザーを失望させることもあります。
最新情報へのアクセス不可
LLMはしばしば古いデータでトレーニングされており、高額なトレーニングコストのため、知識ベースを定期的に更新するのは難しいです。たとえば、GPT-3のトレーニングには最大140万ドルかかると言われています。
トークンの制限
LLMはクエリプロンプトに追加できるトークン数に制限を設けています。たとえば、ChatGPT-3は4,096トークン、GPT-4(8K)は8,192トークンの制限があります。
不変の事前トレーニングデータ
LLMの事前トレーニングデータには古い情報や誤った情報が含まれている可能性がありますが、それらのデータを変更、修正、または削除することはできません。
Zilliz CloudがLLMアプリケーションを拡張する方法
LLMのためのRAG: LLMの知識ベースを更新・拡張し、より正確な回答を提供
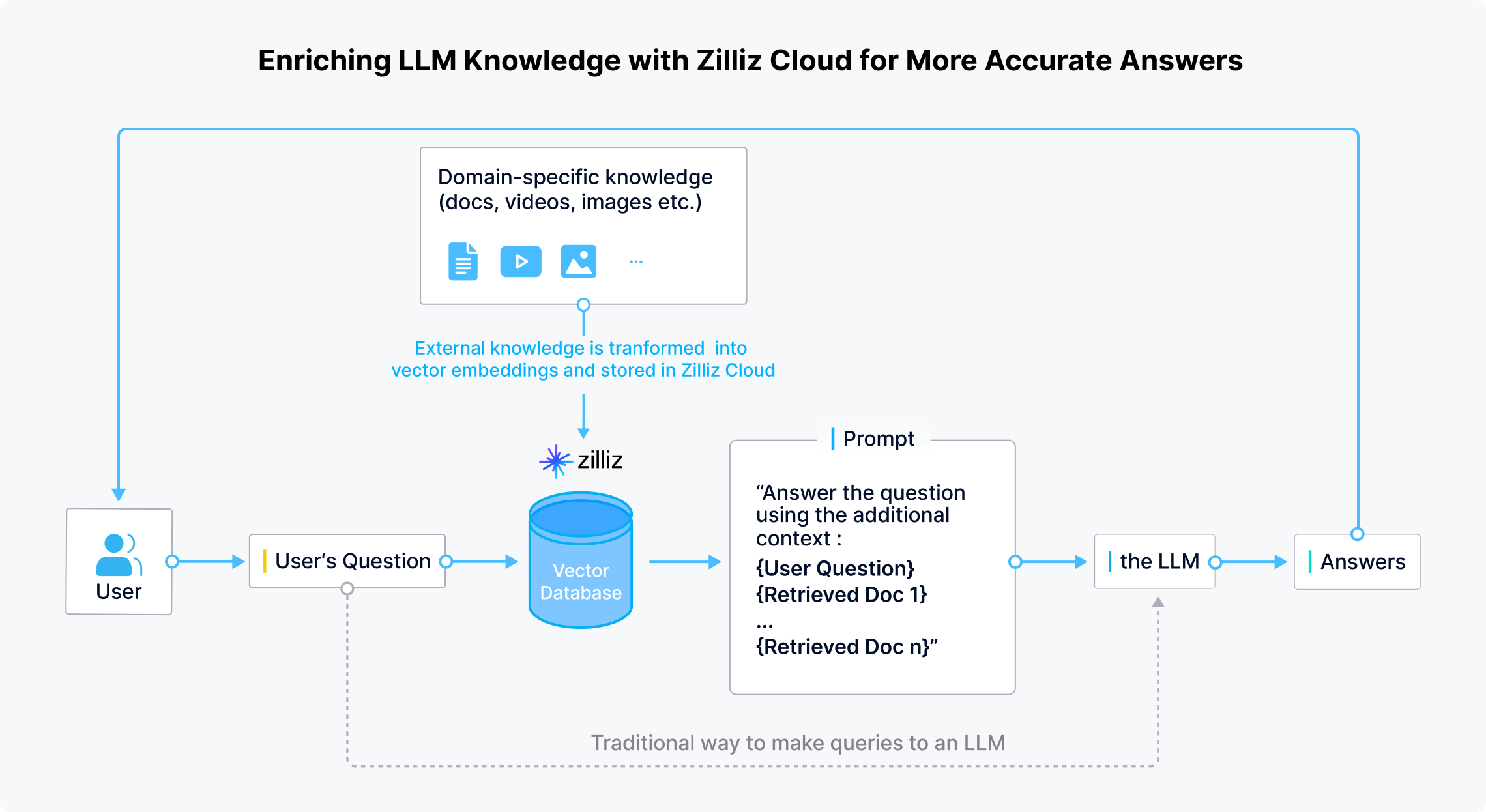
Zilliz Cloudは、開発者や企業が領域特定の最新情報や機密性の高いデータをLLMの外部に安全に保存できるようにします。 ユーザーが質問を与えると、LLMアプリケーションは埋め込みモデルを使用して質問をベクトルに変換します。 その後、Zilliz Cloudが類似性検索を実行し、質問に関連するTop-kの結果を提供します。最後に、これらの結果は元の質問と組み合わせられてプロンプトを生成し、LLMにより正確な回答を生成するための包括的なコンテキストを提供します。
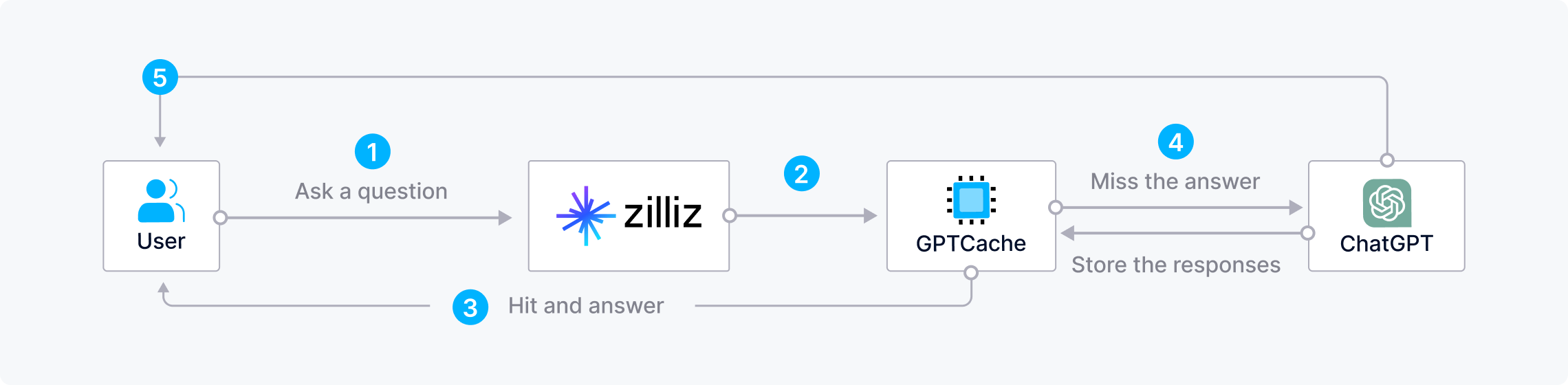
Zilliz CloudとGPTCacheを組み合わせて時間とコストを節約
LLMに対して繰り返しや類似した質問をすると、コストやリソースを浪費し、特にピーク時には長い時間がかかる可能性があります。 AIアプリケーションを構築する際に時間とコストを節約するため、開発者はZilliz CloudをGPTCache(LLMの応答を保存するオープンソースのセマンティックキャッシュ)と組み合わせて利用できます。このアーキテクチャでは、ユーザーが質問した際に、ZillizはまずGPTCacheで回答を求めます。 回答が見つかれば、Zilliz Cloudが即座にそれを返します。回答が見つからない場合、Zilliz CloudはLLMにクエリを送り、その回答をGPTCacheに保存して将来の使用に備えます。
CVPスタック
ChatGPT/LLMs + ベクトルデータベース + Prompt-as-Code
CVPスタック (ChatGPT/LLMs + a vector database + prompt-as-code) は、ベクトルデータベースが備えたLLMを強化する価値を示す人気のAIスタックです。OSS Chatを例として、CVPスタックの仕組みを説明できます。
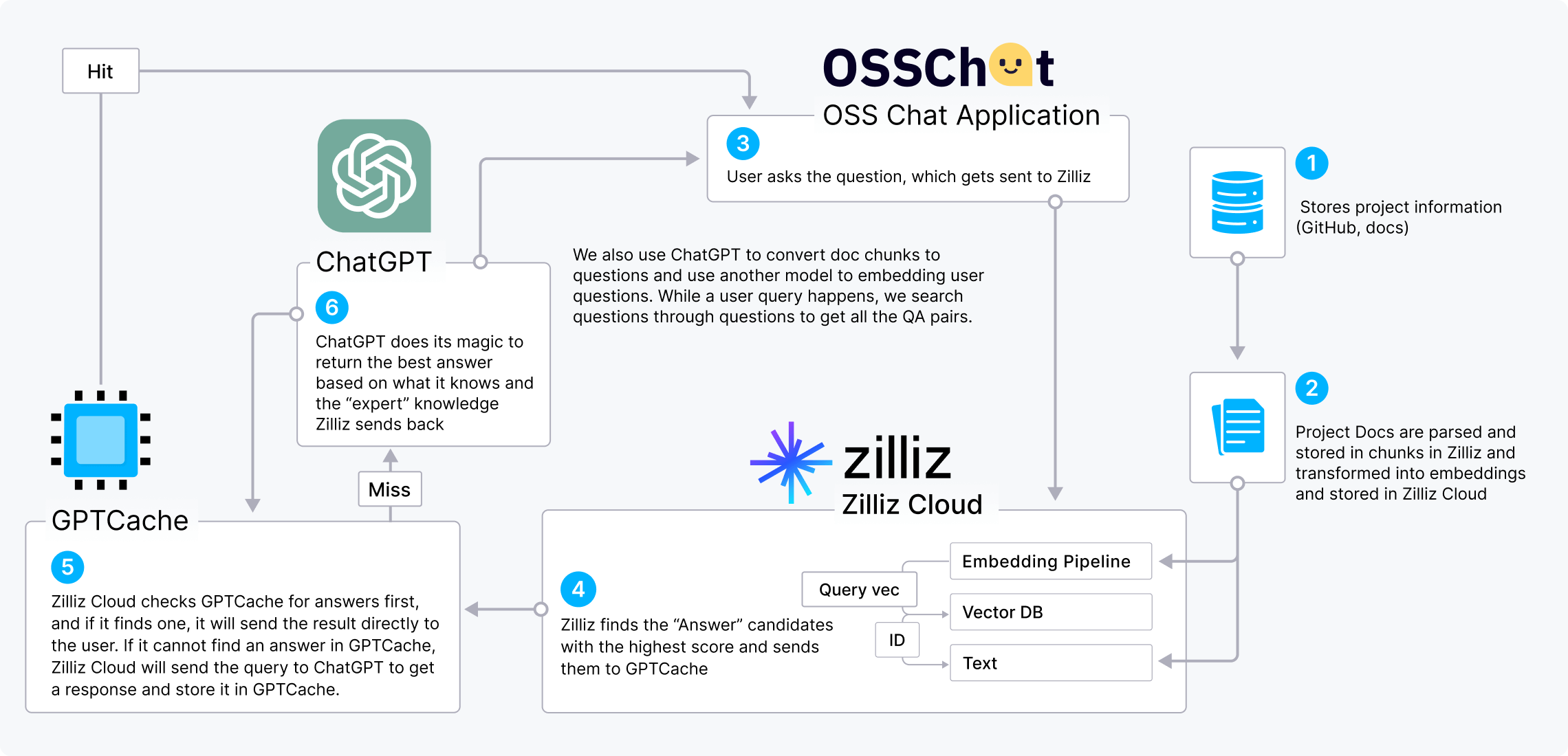
OSS ChatはGitHubプロジェクトに関する質問に答えるチャットボットです。さまざまなGitHubリポジトリやそのドキュメントページから情報を収集し、それを埋め込みの形式でZilliz Cloudに保存します。 ユーザーがOSS Chatにオープンソースプロジェクトについて質問すると、Zilliz Cloudが類似性検索を実行して最も関連性の高いTop-kの結果を探します。 そして、 これらの結果は元の質問と組み合わせられてプロンプトを生成し、ChatGptにより正確な回答を生成するためのより広範なコンテキストを提供します。
また、GPTCacheをCVPスタックに組み込むことで、コストを削減し、応答を高速化できます。
MilvusとZilliz Cloudを活用したLLMプロジェクト
開発者がどのようにしてMilvusとZilliz Cloudを利用し、生成AIアプリケーションを強化しているのかについてもっと詳しく。
- OSS Chat
- PaperGPT
- NoticeAI
- Search.anything.io
- IkuStudies
- AssistLink AI
人気AIプロジェクトとMilvusとの統合
OpenAI, LangChain, LlamaIndexなど、多くの他のAIの先駆者たちが、検索機能を強化するためにZilliz Cloudと統合しています。



