




AIの最適化:安定した普及と効率的なキャッシュ戦略への手引き
このブログでは、Stable Diffusionモデルを最適化するための様々なキャッシング戦略について説明します。
シリーズ全体を読む
- 交差エントロピー損失:機械学習におけるその役割を解明する
- バッチとレイヤーの正規化 - ニューラルネットワークの効率性を引き出す
- ベクトル・データベースによるAIと機械学習の強化
- ラングチェーンツール先進のツールセットでAI開発に革命を起こす
- ベクターデータベース検索テクノロジーの未来を再定義する
- ローカル感度ハッシング (L.S.H.):包括的ガイド
- AIの最適化:安定した普及と効率的なキャッシュ戦略への手引き
- ネモ・ガードレールAIの安全性と信頼性を高める
- ベクトル・データベースに最適化されたデータ・モデリング技法
- カラーヒストグラムの謎を解く:画像処理と解析の手引き
- BGE-M3を探る:Milvusによる情報検索の未来
- BM25を使いこなす:Milvusにおけるアルゴリズムとその応用を深く掘り下げる
- TF-IDF - NLPにおける項頻度-逆文書頻度の理解
- ニューラルネットワークにおける正則化を理解する
- 初心者のためのヴィジョン・トランスフォーマー(ViT)理解ガイド
- DETRを理解する:トランスフォーマーによるエンドツーエンドのオブジェクト検出
- ベクトル・データベース vs グラフ・データベース
- コンピュータ・ビジョンとは?
- 画像認識のための深層残差学習
- トランスフォーマーモデルの解読:そのアーキテクチャと基本原理の研究
- 物体検出とは?総合ガイド
- マルチエージェントシステムの進化:初期のニューラルネットワークから現代の分散学習まで(アルゴリズム編)
- マルチエージェントシステムの進化:初期のニューラルネットワークから現代の分散学習まで(方法論編)
- CoCaを理解する:コントラスト・キャプションによる画像テキスト・ファウンデーション・モデルの進歩
- フローレンスマイクロソフトによるコンピュータビジョンの高度な基礎モデル
- トランスフォーマーの後継者候補マンバ
- ALIGNの説明ノイジー・テキスト教師による視覚・視覚言語表現学習のスケールアップ
#AIの最適化:安定した普及と効率的なキャッシング戦略の手引き
イントロダクション
AI業界は電光石火のスピードで動いている。モデルやアプリケーションはますます複雑になり、常に可能性の限界を押し広げている。OpenAIのDALLE-2、Stable Diffusion、Midjourneyのようなテキストから画像への生成モデルは、非常にリアルで多様な画像を数秒で作成することを可能にしました。
拡散モデル](https://zilliz.com/glossary/diffusion-models)のインパクトは、単に視覚的に魅力的な画像を生成するだけにとどまらない。パーソナライズされた魅力的なビジュアルコンテンツの作成を可能にすることで、様々な業界に革命をもたらす可能性を秘めている。例えば、拡散モデルは、カスタム製品の生成、没入感のあるバーチャル体験の作成、あるいはビデオゲームやアニメーションの開発を支援することもできる。
しかし、これらのモデルが複雑化し、性能が向上するにつれて、効率的に実行するための計算能力も要求されるようになります。AIモデルにとって最適化が非常に重要なのはこのためです。
このブログ記事では、Stable Diffusionモデルを最適化するための様々なキャッシュ戦略について説明します。
安定拡散を理解する
Stable Diffusionは、テキスト記述から高品質の画像を生成するオープンソースのディープラーニングモデルだ。必要なのはまともなGPUか、1時間数セントでレンタルできるGPUサーバーだけだ。
このモデルは、画像とテキストのペアの大規模なデータセットで学習され、与えられたテキスト記述に一致する画像を生成するように学習する。テキストだけを使って画像を変更することができるため、さまざまな用途に使える非常に汎用性の高いツールとなっている。
どのように機能するのか?Stable Diffusionは、拡散モデルと潜在表現学習の概念を組み合わせ、与えられたテキスト入力と密接に一致する、視覚的に首尾一貫した詳細な画像を作成します。
一般的に、拡散モデルの学習プロセスでは、入力画像を様々なスケールのガウスノイズで破損させ、各ステップで除去する必要のあるノイズを予測することで、このプロセスを逆転させる学習を行います。モデルは画像を繰り返しノイズ除去することで、徐々に与えられたプロンプトにマッチするクリーンで高品質な画像を生成する。
##安定拡散アーキテクチャ
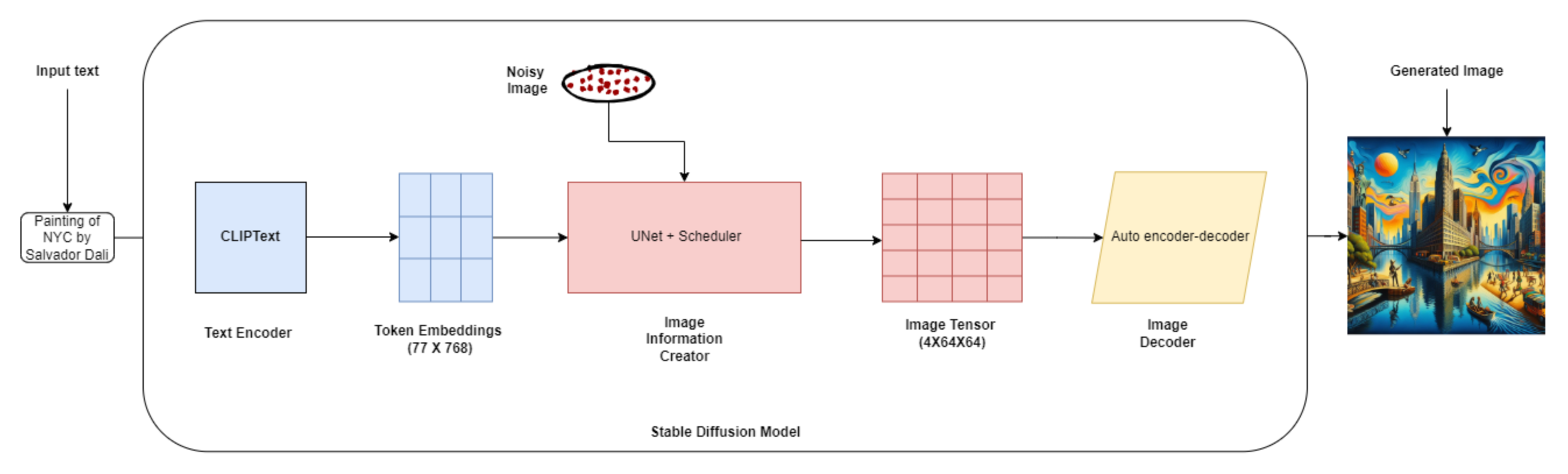 安定拡散アーキテクチャ.png
安定拡散アーキテクチャ.png
Stable Diffusionのアーキテクチャは、3つの主要コンポーネントで構成されています:
- テキストエンコーダ(OpenAIのCLIP)***:テキストエンコーダは、入力されたテキスト記述を、画像生成時にU-Netの条件付けに使用できる潜在空間にマッピングします。
- Variational Autoencoder (VAE)**:VAEは画像を潜在表現に符号化し、元の画像空間に復号化する役割を担う。
- ノイズ推定ネットワーク(U-Net)**:U-Netは畳み込みニューラルネットワークであり、各ノイズ除去ステップで除去すべきノイズを予測し、生成プロセスを望ましい出力画像へと導く。
以下は、プロセス全体の簡略化された内訳です:
1.テキストエンコーディング:例えば、"庭で遊んでいるかわいい子犬 "の画像を生成したいとします。テキストエンコーダーはこのプロンプトを受け取り、数値表現に変換する。 2.潜在空間の初期化:256x256ピクセルの画像を生成したいとします。潜在空間初期化では、(1, 256, 256, 3)の形状のランダムノイズテンソルを開始点として作成する。 3.拡散プロセス拡散プロセスは潜在表現を反復的に改良する。各ステップにおいて、U-Netはノイズの多い潜在表現と符号化されたテキストプロンプトを入力とし、除去すべきノイズを予測する。 4.反復的洗練:拡散過程が1000のタイムステップからなるとする。各タイムステップで、U-Netは潜在表現をよりノイズの少ない、より一貫性のあるものに改良する。 5.画像デコーディング拡散処理の後、最終的な潜在表現はデコーダー・ネットワークに渡され、出力画像が生成される。デコーダは潜在表現をピクセル値に変換する。
なぜ最適化が必要なのか?
- APIのコスト**:安定拡散モデルを最適化することで、推論速度の向上、メモリ消費量の削減、リソースの効率的な利用が可能になり、APIコストが削減されます。
- スピードの必要性インタラクティブな画像編集ツールやリアルタイム画像生成システムなど、多くの実世界のアプリケーションでは、シームレスなユーザー・エクスペリエンスを提供するために、高速な推論速度が非常に重要です。最適化は推論時間を大幅に短縮します。
- スケーラビリティ**:最適化されたモデルは、より大量のリクエストを処理し、増大する需要に対応するために効率的に拡張することができます。
- リソース効率**:AI最適化技術により、メモリフットプリントと計算要件が削減され、費用対効果の高い導入が可能になります。
- 展開の柔軟性:**最適化されたモデルは、リソースに制約のあるデバイスを含むさまざまなハードウェア・プラットフォームに展開できるため、適用範囲が広がります。
では、キャッシュがこのプロセスをどのように改善できるかを見てみましょう。
AIモデルにおけるキャッシュの役割
キャッシングとは、頻繁に使用されるデータ、つまり生成AIモデルの場合は以前に計算された結果を、再利用できるように高速にアクセスできるメモリロケーションに保存する基本的なテクニックである。
**コンセプトは単純だ:ユーザーがモデルにプロンプトを出すと、そのリクエストをデータベースに保存することができ、次にユーザーが同じようなプロンプトを出したときに、モデルは保存されたデータの一部を使用して応答することができます。
逐次的なノイズ除去処理と相当なモデルサイズを考えると、安定拡散はかなりの計算コストにつながる可能性がある。しかし、このようなリソースを大量に消費するモデルにとって、推論プロセス中に生成された中間的な活性化と埋め込みを効率的に保存し、検索するキャッシングは、ゲームチェンジャーとなり得る。
様々なキャッシュ戦略によって計算効率を向上させることができる:
- ベクターデータベース](https://zilliz.com/learn/what-is-vector-database):ベクトル・データベース](): 高次元データをベクトルとして格納することができるこれらの専用データベースは、様々なMLモデルから生成された潜在表現とベクトル埋め込みを迅速に取り出すことができる。最も一般的なクエリのためにベクトルデータベースをセットアップすることで、再計算の必要性を減らし、モデルの推論速度を向上させることができます。
- メモ化**:メモ化は、高価な関数の呼び出しの結果を保存し、同じ入力が再び遭遇したときにキャッシュされた結果を取り出す効果的なキャッシュ技法です。この戦略は、再帰的アルゴリズムや繰り返し計算を行う関数を最適化し、冗長な計算を排除して実行速度を向上させます。
- 潜在的なキャッシュ:** モデルは、以前に処理された入力の潜在的な表現をキャッシュします。類似の入力に遭遇した場合、再計算の必要性を回避して、キャッシュされた潜在的な表現を取り出すことができます。
- 時間ベースのキャッシュ:**時間ベースのキャッシュは、キャッシュ内の各アイテムに有効期限またはTTL(time-to-live)値を割り当てる。指定された有効期限に達すると、そのアイテムは削除されるか、無効とマークされ、データの関連性と有効性を確保するために元のソースから新たに検索する必要があります。
- キャッシュ消去ポリシー**:キャッシュ削除ポリシーは、キャッシュがその容量に達したときに、どのアイテムをキャッシュから削除するかを決定します。一般的な退去ポリシーには、FIFO(先入れ先出し)、LIFO(後入れ先出し)、LRU(最近使用頻度が最も低い)、LFU(最近使用頻度が最も低い)、ランダム置換があり、それぞれ異なる基準で削除する項目を選択します。
**安定拡散のような拡散モデルのために特別に開発された新しいキャッシュ戦略もある。
- DeepCache](https://github.com/horseee/DeepCache):DeepCacheは、追加のトレーニングを必要とせずに拡散モデルを高速化します。DeepCacheは、冗長な計算を省き、ノイズ除去の段階をまたいで特徴をキャッシュし、検索することで魔法をかける。高レベルの特徴量を巧みに再利用し、低レベルの特徴量を効率的に更新することで、DeepCacheは一流の画質を維持しながら、驚異的なスピードアップを実現します。
- 近似キャッシング:](https://arxiv.org/abs/2312.04429) 近似キャッシングは、新しいプロンプトに必要なノイズ除去ステップの数を減らすために、以前の画像世代からの中間ノイズ状態を巧みに再利用します。このテクニックは、プロンプト間の類似性を活用することで初期ステップをスキップし、貴重な計算時間を節約することができます。LCBFUと呼ばれるスマートなキャッシュ管理ポリシーと組み合わせることで、最適なモデル効率を実現します。
- ブロック・キャッシング](https://fwmb.github.io/blockcaching/):ブロック・キャッシングは、レイヤーの出力が時間とともに滑らかに変化することを利用し、ネットワーク内の位置に基づいて明確なパターンを認識します。前のステップからの出力を再利用することで、冗長な計算を回避します。気の利いたスケールシフトアライメントのトリックと自動スケジューリングにより、ブロックキャッシュはアーチファクトを抑え、パフォーマンスを最高に保つ。
安定拡散におけるキャッシュの実装
Stable Diffusionのキャッシュは、中間計算を保存して再利用することで、冗長な計算を避け、画像生成プロセスを高速化することを目的としています。
重要なアイデアは、モデルのフォワードパスの間に、潜在表現やアテンションマップのような、頻繁に使用される、または計算集約的な中間結果を特定し、キャッシュすることである。
ここでは、Stable Diffusionでキャッシュ戦略を実装するためにベクトルデータベースを使用する方法を説明します:
1.1.自己アテンションレイヤーやU-netプロセスのバイパスなど、キャッシングによってパフォーマンスが大幅に向上するレイヤーやモジュールを特定する。 2.フォワードパス中に、これらのレイヤーの中間結果を保存するキャッシュメカニズムを実装する。安定拡散モードのフォワードパスの間、中間潜在表現と埋め込みをベクトルデータベースに格納する。 3.後続のフォワード・パスの間に、キャッシュされた結果がベクトル・データベースで利用可能(かつ現在の入力に対して有効)かどうかをチェックする。 近い一致が見つかった場合、再計算する代わりにキャッシュされた結果を取得し(これは必要なノイズ除去ステップ数を減らす)、拡散プロセスの開始点として使用する。 4.入力やモデルのパラメータが変更された場合など、必要に応じてベクトルデータベースのキャッシュを更新または無効にする。
擬似コードによる処理の例:
インポート faiss
class StableDiffusion:
def __init__(self, autoencoder, unet, conditioning_model):
self.autoencoder = autoencoder
self.unet = unet
self.conditioning_model = conditioning_model
self.vector_db = faiss.IndexFlatL2(latent_dim) # ベクトルデータベースの初期化
def generate_image(self, conditioning_input, timesteps):
latent = self.autoencoder.encode(conditioning_input)
# 類似した潜在表現をベクトルデータベースに問い合わせる
距離、インデックス = self.vector_db.search(latent, k=1)
if distances[0] < threshold:
# キャッシュされた潜在表現を取得する
latent = self.vector_db.reconstruct(indices[0])
else:
for t in timesteps:
latent = self.diffusion_step(latent, t, conditioning_input)
# 新しい潜在表現をベクトルデータベースに追加
self.vector_db.add(latent)
image = self.autoencoder.decode(latent)
画像を返す
使用例と利点
効率的なキャッシュ戦略で安定した拡散モデルを最適化することは、実世界で数多くの応用例と利点があります。いくつかのユースケースを見てみましょう:
- アーティストやデザイナーは、最適化されたStable Diffusionモデルを活用して、高品質のデジタルアートを効率的に生成することができます。このモデルは、頻繁に使用されるスタイルやパターンをキャッシュすることで、バリエーションや反復を素早く生成し、クリエイティブなプロセスを効率化します。
- コンテンツ生成**:メディアやエンターテインメント企業は、最適化されたStable Diffusionモデルを利用して、多様で魅力的なビジュアルコンテンツを大規模に生成することができます。効率的なキャッシングにより、このモデルは類似したテキスト入力に基づいて画像を迅速に生成することができ、迅速なコンテンツ作成とパーソナライズを可能にします。
- 商品ビジュアライゼーション:** Eコマース・プラットフォームは、最適化された安定拡散モデルを採用することで、さまざまなカテゴリーやスタイルのリアルな商品画像を生成することができます。頻繁にアクセスされる商品属性やスタイルをキャッシュすることで、画像生成プロセスを大幅に高速化し、ユーザーエクスペリエンスを向上させ、計算コストを削減することができます。
課題と考察
Stable Diffusionにキャッシングを実装することは、大きなメリットをもたらしますが、同時に課題や考慮すべき点もあります:
- メモリ管理: メモリ管理:キャッシュのサイズと利用可能なメモリのバランスをとることが重要です。メモリ管理**:キャッシュのサイズと利用可能なメモリのバランスをとることが重要である。キャッシュの立ち退きポリシーや圧縮技術のような戦略は、メモリを効率的に管理するのに役立つ。
- インデックス作成と検索効率**:ベクトル・データベースのサイズが大きくなると、類似検索の効率がボトルネックになることがあります。検索性能とスケーラビリティを向上させるために、HNSW(Hierarchical Navigable Small World)グラフのような適切なベクトルインデックス戦略を選択します。 *** キャッシュの無効化モデルが進化したり新しいデータが導入されたりすると、キャッシュされた表現が古くなったり無効になったりすることがあります。時間ベースの期限切れやバージョニングなどのキャッシュ無効化ストラテジーを実装することは、キャッシュされたデータの新鮮さと正確さを保証するために非常に重要です。
- スケーラビリティスケーラビリティ**:大規模なアプリケーションやデータセットを扱う場合、キャッシュのサイズが大きくなる可能性があります。分散キャッシングやクラウドベースのストレージソリューションの使用など、効率的に拡張できるキャッシング戦略の設計が不可欠です。
- キャッシュの一貫性**:分散環境や複数ノードのセットアップでは、モデルの異なるインスタンス間でキャッシュの一貫性を維持することは困難です。同期メカニズムを実装するか、分散キャッシュフレームワークを使用することで、データの一貫性を確保することができます。
- レイテンシとスループット**:似たような入力に対してベクターデータベースをクエリすることは、画像生成プロセスにさらなるレイテンシをもたらします。高速なパフォーマンスを維持するためには、キャッシュヒットレートとレイテンシのトレードオフのバランスを取る必要があります。バッチ処理や非同期更新のようなテクニックは、スループットの向上に役立ちます。
これらの課題を解決するには、キャッシュシステムを定期的に監視して、ボトルネックを特定し、パフォーマンスを最適化します。
結論
ベクトル・データベースと、レイテント・キャッシング、ブロック・キャッシング、近似キャッシングなどのキャッシング技術を活用することで、AIアプリケーションのパフォーマンス、スケーラビリティ、費用対効果を大幅に向上させることができます。
これらのキャッシング戦略を実装するには、課題が伴います。キャッシング戦略を活用することで、これらの課題に正面から取り組み、特定のプロジェクトに有効なソリューションを見つけることができます。
最適化されたStable Diffusionモデルがユーザーの手元にあれば、可能性は無限に広がります。かつては想像もできなかったような素晴らしい作品を生み出す可能性があります。



