




初心者のためのヴィジョン・トランスフォーマー(ViT)理解ガイド
ヴィジョン・トランスフォーマー(ViT)は、物体検出や画像分類などのコンピュータ・ビジョン・タスクを実行するためにトランスフォーマーを使用するニューラルネットワーク・モデルである。
シリーズ全体を読む
- Cross-Entropy Loss: Unraveling its Role in Machine Learning
- Batch vs. Layer Normalization - Unlocking Efficiency in Neural Networks
- Empowering AI and Machine Learning with Vector Databases
- Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
- Vector Databases: Redefining the Future of Search Technology
- Local Sensitivity Hashing (L.S.H.): A Comprehensive Guide
- Optimizing AI: A Guide to Stable Diffusion and Efficient Caching Strategies
- Nemo Guardrails: Elevating AI Safety and Reliability
- Data Modeling Techniques Optimized for Vector Databases
- Demystifying Color Histograms: A Guide to Image Processing and Analysis
- Exploring BGE-M3: The Future of Information Retrieval with Milvus
- Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
- TF-IDF - Understanding Term Frequency-Inverse Document Frequency in NLP
- Understanding Regularization in Neural Networks
- A Beginner's Guide to Understanding Vision Transformers (ViT)
- Understanding DETR: End-to-end Object Detection with Transformers
- Vector Database vs Graph Database
- What is Computer Vision?
- Deep Residual Learning for Image Recognition
- Decoding Transformer Models: A Study of Their Architecture and Underlying Principles
- What is Object Detection? A Comprehensive Guide
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Algorithmic)
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Methodological)
- Understanding CoCa: Advancing Image-Text Foundation Models with Contrastive Captioners
- Florence: An Advanced Foundation Model for Computer Vision by Microsoft
- The Potential Transformer Replacement: Mamba
- ALIGN Explained: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
ヴィジョン・トランスフォーマー(ViT)は、トランスフォーマーアーキテクチャに基づくニューラルネットワークモデルであり、画像データを処理することを目的として構築されている。トランスフォーマーにおける注意とは、モデルが入力データの関連する部分に焦点を当て、よりよく理解し、予測を生成するのを助けるメカニズムであり、より文脈を意識した柔軟な情報処理を可能にする。ビジョン・トランスフォーマーは、アテンションの概念を画像に適用し、広大なキャンバスの中から重要な要素を区別する。アテンションはまた、ViTがグローバルな関係を捉え、既存の視覚モデルを凌駕することを可能にする。
グローバルな注意は、トランスフォーマーモデルを従来の畳み込みニューラルネットワーク(CNN)から分離する。CNNは隣接する画素の情報を取り込んで集約し、局所的な関係のみを捉える。ViTはより広いキャンバスで動作し、各画像セグメントが全体的に比較される。このアプローチは計算の複雑さを増大させるが、ViTは性能を大幅に向上させる。
ヴィジョン・トランスフォーマーは、物体検出、画像分類、セマンティック・セグメンテーションのタスクで目覚ましい性能を発揮している。このブログでは、ViTアーキテクチャを詳しく説明し、ハギング顔モデルを使った実装を簡単に説明します。
トランスフォーマーとは?
Vaswaniらは論文「Attention is All You Need」(2017年)で、トランスフォーマーアーキテクチャを紹介した。トランスフォーマーモデルは自己注意メカニズムを導入し、入力データの異なる部分の間に関係コンテキストを構築できるようにした。
トランスフォーマーは、特に自然言語処理(NLP)において、データに対する深い理解と印象的な結果によって、大きな人気を博した。トランスフォーマーは、アテンション・メカニズムを利用して、文中の単語間の関係を導き出す。このアプローチにより、テキストの意味理解を収集し、文脈を意識した情報量の多いベクトル埋め込みを生成することができ、AIモデリングにおいて正確な結果を得ることができる。
トランスフォーマーの仕組み
意味的関係を構築するには、データ点を共有された意味的n次元空間にマッピングする必要がある。各データ点は空間内の特定の位置にあり、各点間の距離がそれらの関係を決定する。
自然言語処理では、まず自然言語テキストをトークンに分解する。次にこれらのトークンは、意味空間における位置を表す埋め込みに変換される。埋め込みは、類似したトークンが近接したままとなるように作成される。
例えば、'car'、motorcycle'、airplane'のような単語は、すべて乗り物のカテゴリーに入るため、互いに近い位置にマッピングされる。近いデータポイントはまた、より高いアライメントスコアを持つと言われています。
図1- ベクトル埋め込みができるまで](https://assets.zilliz.com/Figure_1_How_vector_embeddings_are_created_a49508b17d.png)
図1: ベクトル埋め込みはどのように作成されるか?
しかし、言語というのは厄介なもので、文脈によって用語の意味が変わってしまうことがよくあります。変換器は、テキストの文脈に応じて、潜在空間内で単語埋め込みを移動させます。BERT](https://arxiv.org/abs/1810.04805)のような一般的なモデルは、複数のエンコーダ層で構成され、それぞれが埋め込み値を修正するために注目メカニズムを適用する。テキスト文がエンコーダを通過するとき、各単語は残りのトークンと比較され、その埋め込みは提供されたコンテキストに応じて修正される。
エンベッディングが生成されると、最終的なヘッド層に渡され、ヘッド層はタスクに応じて予測を行う。例えば、分類タスクではクラス確率を出力し、seq-2-seqモデリングタスクでは別のシーケンスを出力する。
ビジョン・トランスフォーマーとは?
トランスフォーマーは主に言語タスクに利用されるが、ヴィジョン・トランスフォーマー(ViT)と呼ばれるバリエーションは画像データのモデリングに利用される。変換器の背後にある一般的な直観は、データ点はデータセット内の位置と文脈に応じて一定の重要度を保持するというものである。例えば、ある単語は他の単語よりも文章全体に意味を与えるので、モデリング時に優先されるべきである。大きな画像内のピクセルやパッチについても同じことが言える。
画像には複数のオブジェクトが異なる位置に含まれることがあり、それぞれがタスクに応じて異なる値を保持する。視覚変換は、画像パッチ間の関係を捉えるために注意メカニズムを使用する。
図2-画像への注意の適用 - 出典](https://assets.zilliz.com/Figure_2_Applying_attention_to_images_Source_22146a1919.png)
図2:画像への注意の適用 -_ ソース
アプローチは言語データの場合と変わらないが、トークンの代わりに画像パッチを変換アーキテクチャに渡す。このアプローチは従来のCNNよりも多くの情報を捉え、画像データをモデル化するためのより良い方法を提供する。
ビジョン変換器の課題
画像データは個々の文章に比べてサイズがはるかに大きいため、画像データに変換器を採用すると、計算上の課題が増える。サイズ255×255の小さな画像は65,025ピクセルから構成される。自己アテンション機構は各ピクセルをデータセット全体と比較するので、CPUの計算はおよそ65,025 x 65,025 = 4.2x109の比較演算を実行しなければならず、これは計算上の悪夢である。この問題を解決するために、オリジナルのViT論文の著者は、画像をパッチに分割し、各パッチを変換器への入力として扱うことを提案している。この方法ははるかに効率的で、効果的なトレーニングに十分な情報を取り込むことができる。
ヴィジョン・トランスフォーマー(ViT)アーキテクチャ
ViTエンコーディングの最初のステップは、画像パッチの平坦化された配列を生成することである。パッチは最初のフィードフォワード線形射影層に渡される。この層は、平坦化されたパッチを埋め込み空間に投影し、後で変換器が処理できるようにする。
図3- ViTアーキテクチャ - 出典](https://assets.zilliz.com/Figure_3_Vi_T_Architecture_Source_5f8b46cff2.png)
図3:ViTアーキテクチャ -_ ソース
一般的な画像埋め込みが作成されると、さらに2つのステップが必要になる。まず、埋め込み画像にクラス・トークン(CLS)を付加します。このアプローチはBERTネットワークから採用されたもので、BERTネットワークは学習可能な埋め込みにこの追加トークンを用いている。最初は、このトークンは白紙であり、何の情報も含んでいない。しかし、変換層を通過するにつれて、すべてのパッチからの情報が集約され、最終的な出力は元の画像全体を表す。このトークンは分類タスクに使用され、最終予測のために分類器に供給される。
第2段階はパッチ埋め込みに位置エンコーディングを適用することである。変換器はデータ中のシーケンスを識別するデフォルトのメカニズムを持っていないからである。ごちゃごちゃしたパッチは元の画像を誤認させ、学習精度を低下させるため、シーケンスを強調することは重要である。位置埋め込みは事前学習中に学習され、パッチ埋め込みと同じサイズで、パッチ埋め込みに直接追加される。
変換エンコーダ
エンコーダは、トランスフォーマ・モデル全体を支える主要な動力源です。3つの主要コンポーネントで構成されています:
ノームレイヤー:*** レイヤーの正規化は、他の主要なレイヤーからのアクティベーションをスケーリン グし、トレーニングに安定性を与えます。また、アクティベーションをスケーリングすることで、ウェイトの更新を容易にし、トレーニングを高速化します。
この層は異なる画像パッチ間の関係を計算します。マルチヘッドであることは、複数の注意の計算が並行して行われることを意味する。各ヘッドはパラメータを持ち、わずかに異なる入力を処理する。直感的には、各ヘッドは入力から異なる情報を取り込み、値ベクトルの重みとなる注目スコアを計算する。各ヘッドからの出力は連結され、最終的にリッチな表現となる。
多層パーセプトロン(MLP):** この基本的なフィードフォワード・ニューラルネットワークは非線形性を導入し、トランスフォーマーブロックの出力となる。ソフトマックス層と組み合わせることで、分類ラベルを出力することができます。
ヴィジョン・トランスフォーマー(ViT)の実装
さて、視覚変換器がどのように動作するかを説明したので、Hugging Faceディレクトリからモデルを実装することができる。このウォークスルーでは、'Painting Style Classification'データセットを使ってViTモデルの微調整を試みます。この実装の全コードはGoogle Colab notebookからアクセスできます。
まず、関連ライブラリのインストールとインポートから始めます。
pip install datasets transformers[torch]
from datasets import load_dataset, load_metric
from transformers import ViTImageProcessor, ViTForImageClassification, TrainingArguments, Trainer
インポートトーチ
インポート numpy as np
次に、HuggingFace datasets ライブラリからデータセットを読み込みます。
# config = 'mini' の代わりに 'full' を渡す。
ds = load_dataset('keremberke/painting-style-classification', 'full')
ds` オブジェクトを表示することで、データセットの構成を理解することができる。
ds
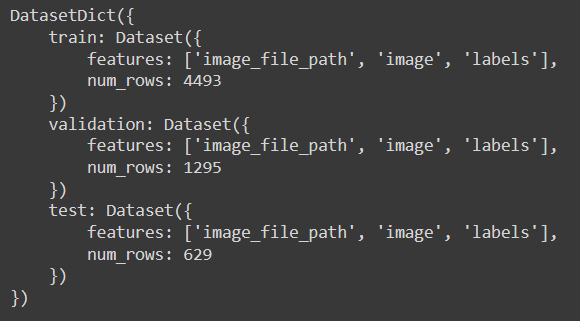
出力された結果は、データセットに画像とラベルが含まれていることを示している。さらに、トレーニングセットには4493枚、検証セットには1295枚、テストセットには629枚の画像が含まれている。適切なトレーニングのためには、データセットに数万枚の画像が含まれているのが理想的だが、今回のデモではこれで十分だろう。
画像とそのラベルの例を見てみよう。
data_index = 4000
example = ds['train'][data_index]['image'].
labels = ds['train'].features['labels'].
example # 画像を表示
# 上の画像のラベルを表示
labels.int2str(ds['train'][data_index]['labels'])
 図4-画像とそのラベルの例 Label- 'Romanticism'
図4-画像とそのラベルの例 Label- 'Romanticism'
図4:画像とそのラベルの例。ラベル: 'Romanticism'_
データセットがロードされたら、モデルをロードできる。モデルには2つの目的がある。第一に、入力画像を変換し、モデルの要求に合わせるための正しい設定を持つプリプロセッサが含まれています。2つ目は、事前学習で得られた重みを含むモデル・アーキテクチャが含まれていることです。まずプリプロセッサを初期化し、処理パイプラインを作成する。
# HuggingFaceからプリトレーニングされたViTモデルをロードする。
model_name_or_path = 'google/vit-base-patch16-224-in21k'
processor = ViTImageProcessor.from_pretrained(model_name_or_path)
次のコードは、Hugging Faceの組み込み機能を使用し、リアルタイムパイプラインを作成します。これは、画像がアクセスされたときだけ処理が適用されることを意味します。これにより、メモリと不要な処理を節約できます。
def transform(data_batch):
'''
画像のバッチを一括処理する関数
'''
# PIL画像のリストを受け取り、ピクセル値に変換する
inputs = processor([x for x in data_batch['image']], return_tensors='pt')
inputs['labels'] = data_batch['labels'].
return inputs
# with_transform関数はリアルタイムで画像に変換をかける
prepared_ds = ds.with_transform(transform)
最後に、処理した画像をトーチテンソルとしてスタックする関数が必要です。
def collate_fn(batch):
'''
バッチ画像を積み上げる関数
'''
# バッチはディクテのリスト
return {
'pixel_values': torch.stack([x['pixel_values'] for x in batch])、
'labels': torch.tensor([x['labels'] for x in batch]).
}
データ処理がセットアップされたので、評価メトリクスやモデルの初期化などの学習パラメータを定義します。 これは分類問題なので、評価のためにaccuracy、precision、recallを計算します。
# 精度、精度、リコールの評価指標をロードする
accuracy_metric = load_metric('accuracy')
precision_metric = load_metric('precision')
recall_metric = load_metric('recall')
def compute_metrics(p):
# 予測値と参照値を抽出する
predictions = np.argmax(p.predictions, axis=1)
references = p.label_ids
# 精度を計算する
精度 = accuracy_metric.compute(predictions=predictions, references=references)
# 精度を計算する(簡単にするために2値分類を仮定する)
精度 = precision_metric.compute(predictions=predictions, references=references, average='macro')
# リコールを計算する(単純化のために2値分類を仮定する)
リコール = recall_metric.compute(predictions=predictions, references=references, average='macro')
# すべてのメトリクスを1つの辞書にまとめる
return {
'accuracy': accuracy['accuracy']、
'precision': precision['precision']、
'recall': recall['recall'].
}
ここでモデルを初期化します。モデル名とデータセットのクラス数を渡して、分類ヘッドを開始できるようにします。
labels = ds['train'].features['labels'].names
model = ViTForImageClassification.from_pretrained(
model_name_or_path、
num_labels=len(labels)、
id2label={str(i): c for i, c in enumerate(labels)}、
label2id={c: str(i) for i, c in enumerate(labels)}, label2id={c: str(i) for i, c in enumerate(labels)}.
)
最後に、学習パラメータを初期化し、先ほど初期化したデータ処理関数を指定するTrainerオブジェクトを作成します。
training_args = TrainingArguments(
output_dir="./vit-base-art"、
per_device_train_batch_size=32、
evaluation_strategy="steps"、
num_train_epochs=4、
fp16=True、
save_steps=100、
eval_steps=100、
logging_steps=10、
learning_rate=2e-4、
save_total_limit=2、
remove_unused_columns=False、
push_to_hub=False、
report_to='tensorboard'、
load_best_model_at_end=True、
)
trainer = Trainer(
model=model、
args=training_args、
data_collator=collate_fn、
compute_metrics=compute_metrics、
train_dataset=prepared_ds["train"]、
eval_dataset=prepared_ds["validation"]、
tokenizer=processor、
)
すべて整ったので、トレーニングを実行できる。
train_results = trainer.train()
trainer.save_model()
trainer.log_metrics("train", train_results.metrics)
trainer.save_metrics("train", train_results.metrics)
trainer.save_state()
結果を表示](https://assets.zilliz.com/printed_result_2_5d4ab54df0.png)
4エポック後の検証精度は50.7%に達した。この数字はあまり印象的ではないかもしれないが、より長くトレーニングすることで改善されるだろう。また、我々のデータセットには限りがあることも覚えておいてほしい。
スケーラブルで効率的な画像検索のためのビジョン変換器(ViT)とベクトルデータベースの組み合わせ
ヴィジョン・トランスフォーマー(ViTs)は、視覚データをどのように理解し処理するかを変換する。ViTsは画像をパッチに分割し、それぞれをトークンとして扱い、画像内の複雑で大域的な関係を捉えるために自己注意メカニズムを使用する。このアプローチにより、ViTsは画像の視覚的内容を包括的に表現するリッチで高次元の特徴埋め込みを生成することができる。
MilvusやZilliz Cloud(フルマネージドMilvus)のようなベクトルデータベースは、ViTsのような機械学習モデルによって生成されることが多い高次元ベクトルを効率的に保存、管理、照会するために設計された特別なシステムです。これらのデータベースはベクトル類似性検索に最適化されており、与えられたクエリベクトルに類似したベクトル(ひいてはデータ)を見つけることを目的としている。
ViTsとベクトルデータベースを組み合わせることで、大きなメリットが得られる。第一に、ViTsは、詳細な視覚情報を捉えた画像のリッチな高次元埋め込みを生成する。これらの埋め込みは、Milvusのようなベクトルデータベースにインデックス化され保存され、画像の類似性を高速に検索することができる。この組み合わせにより、ユーザがサンプルをアップロードして画像を検索し、視覚的に類似したアイテムを迅速かつ正確に見つけることができる、強力な画像検索システムを構築する機能が強化される。
この統合は、幅広いアプリケーションを生み出すことができる。電子商取引では、ベクターデータベースとViTの組み合わせにより、アップロードされた画像に類似した商品を見つけることができる画像ベースの検索機能を実現し、ユーザーエクスペリエンスとエンゲージメントを向上させることができる。コンテンツ管理では、視覚的特徴に基づく画像の自動タグ付けと分類をサポートし、手作業を減らして効率を高める。さらに、この相乗効果はレコメンデーションシステムにも有効で、ユーザーの嗜好の埋め込みに基づいて、視覚的に類似したアイテムが提案される。
結論
トランスフォーマーアーキテクチャは、人工知能(AI)の領域において画期的な発明であった。これにより、モデルは個々のデータポイントの重要性を理解し、驚くべき結果を得ることができるようになった。ヴィジョン・トランスフォーマー(ViT)も同じアーキテクチャを使用しているが、画像データを処理するために構築されている。
ViTは画像パッチを個々のデータポイントとして扱う。パッチは平坦化され、逐次エンコードと追加クラス埋め込みのために処理される。変換器はマルチヘッドアテンションモジュールを使い、各パッチ間のアラインメントスコアを計算する。画像パッチを比較することで、画像全体に対する各セグメントの重要性を理解することができる。最後に、分類ヘッドが注意出力に非線形性を付加し、モジュールの最終出力となる。
注意メカニズムは計算量の多い手順であるため、ゼロからのモデル事前学習は難しい。しかし、HuggingFaceハブは様々な事前訓練されたViTモデルをホストしており、下流のタスクのために微調整することができる。
その他のリソース
機械学習、ジェネレーティブAI、ベクトル・データベース、その他の人工知能技術についてもっと学びたい場合は、以下のリソースが良い出発点となる。
論文注意がすべて
ブログOpenAI Whisper: Transforming Speech-to-Text with Advanced AI
生成AIリソースハブ|Zilliz](https://zilliz.com/learn/generative-ai)
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS


