




トランスフォーマーの後継者候補マンバ
Mambaはシーケンスモデリングのための新しいアーキテクチャで、機械学習でよく使われるTransformerモデルに代わるものを提供するように設計されている。
シリーズ全体を読む
- 交差エントロピー損失:機械学習におけるその役割を解明する
- バッチとレイヤーの正規化 - ニューラルネットワークの効率性を引き出す
- ベクトル・データベースによるAIと機械学習の強化
- ラングチェーンツール先進のツールセットでAI開発に革命を起こす
- ベクターデータベース検索テクノロジーの未来を再定義する
- ローカル感度ハッシング (L.S.H.):包括的ガイド
- AIの最適化:安定した普及と効率的なキャッシュ戦略への手引き
- ネモ・ガードレールAIの安全性と信頼性を高める
- ベクトル・データベースに最適化されたデータ・モデリング技法
- カラーヒストグラムの謎を解く:画像処理と解析の手引き
- BGE-M3を探る:Milvusによる情報検索の未来
- BM25を使いこなす:Milvusにおけるアルゴリズムとその応用を深く掘り下げる
- TF-IDF - NLPにおける項頻度-逆文書頻度の理解
- ニューラルネットワークにおける正則化を理解する
- 初心者のためのヴィジョン・トランスフォーマー(ViT)理解ガイド
- DETRを理解する:トランスフォーマーによるエンドツーエンドのオブジェクト検出
- ベクトル・データベース vs グラフ・データベース
- コンピュータ・ビジョンとは?
- 画像認識のための深層残差学習
- トランスフォーマーモデルの解読:そのアーキテクチャと基本原理の研究
- 物体検出とは?総合ガイド
- マルチエージェントシステムの進化:初期のニューラルネットワークから現代の分散学習まで(アルゴリズム編)
- マルチエージェントシステムの進化:初期のニューラルネットワークから現代の分散学習まで(方法論編)
- CoCaを理解する:コントラスト・キャプションによる画像テキスト・ファウンデーション・モデルの進歩
- フローレンスマイクロソフトによるコンピュータビジョンの高度な基礎モデル
- トランスフォーマーの後継者候補マンバ
- ALIGNの説明ノイジー・テキスト教師による視覚・視覚言語表現学習のスケールアップ
トランスフォーマーモデルとそのコンポーネントは、多くの人工知能(AI)のブレークスルーを支えている。これらのモデルが主流である一方で、その2次的な複雑さにより、長いシーケンスに対する効率は制限されている。この問題に取り組むために、線形注意、ゲート畳み込み、構造化状態空間モデル(SSM)など、様々な2次関数以下の時間モデルが登場してきた。しかし、これらのモデルは、テキストのような離散的で内容の豊富なデータに対しては、しばしば苦戦を強いられる。
昨年、このような問題に対処するために、Mambaと呼ばれる新しいアーキテクチャが登場した。このアーキテクチャは、Transformerの性能に匹敵する一方、シーケンス長をリニアにスケーリングし、大規模データを効率的に処理するための強力な選択肢を提供する。
この記事では、Mambaについて説明する:
Mambaを理解するために必要な主要概念
Mambaの基本的なアーキテクチャ
Mambaがどのように動作するかの詳細な概要。
トランスフォーマーとの比較で、従来のモデルに対するマンバのパフォーマンスを検証。
もっと詳しく知りたい方は、マンバ論文をどうぞ。
トランスフォーマーの問題点
トランスフォーマーアーキテクチャは、特に自己注意メカニズムのおかげで、ゲームチェンジャーとなった。これによって、トランスフォームベースのモデルは、シーケンス内のすべてのトークンを同時に考慮することができるようになり、長距離の依存関係を必要とするタスクに実用的になった。これが、長いエッセイを首尾一貫して生成するのに効果的な理由である。では、なぜMambaのような新しいアーキテクチャが必要なのだろうか?
その理由を理解するために、トランスフォーマーアーキテクチャーの核となる要素を簡単に見直してみよう。トランスフォーマーは、テキストのような入力データをトークンの列として扱う。重要な利点は、各トークンがシーケンス内の他のどのトークンに対しても「アタッチ」できることだ。これは、各トークンとシーケンス内の他のすべてのトークンとの関連性を比較する行列を作成する、自己アテンションによって実現される。学習中、このプロセスは並列に実行されるため、高速な学習と効率的な表現学習が可能となる。
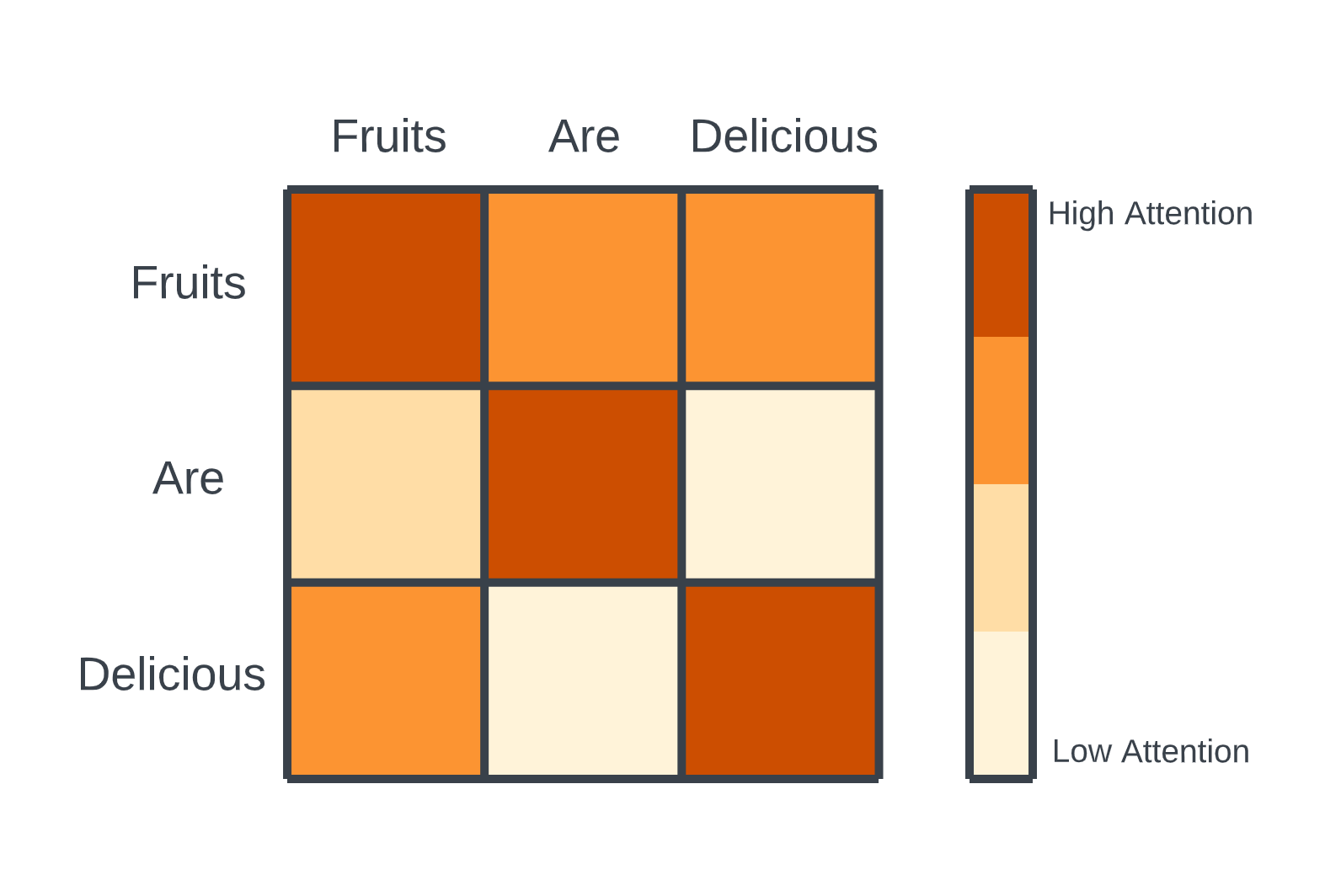 トランスフォーマーにおける注意のメカニズム.png
トランスフォーマーにおける注意のメカニズム.png
トランスフォーマーの注意メカニズム|出典
しかし、この自己注意メカニズムには、推論(新しいテキストやトークンの生成)中に重大な欠点がある。各ステップにおいて、モデルは、以前に生成されたトークンであっても、シーケンス全体の注意行列を再計算しなければならない。この結果、2次関数的な時間複雑性が生じ、長さのシーケンスに対してトークンを生成するには計算が必要になる。シーケンスの長さが長くなるにつれて、計算とメモリーの需要は維持できなくなり、大きなボトルネックになる。
リカレント・ニューラル・ネットワーク
RNNs (Recurrent Neural Networks)**は、過去に部分的な解決策を提供した。Transformerとは異なり、RNNは状態(潜在情報)を保持するため、トークンごとにシーケンス全体を再計算することなく、シーケンスを段階的に処理することができる。しかし、RNNは長距離の依存関係を効果的に捉えるのに苦労し、最終的にはTransformersに負けてしまった。
RNNのセルは2つの入力を受け取る.jpg](https://assets.zilliz.com/RNN_s_cell_takes_two_inputs_531293e980.jpg)
RNNのセルは2つの入力を受け取る:現在の入力と以前の隠れ状態|出典
TransformerとRNNの長所を組み合わせたMambaは、長距離の依存関係を捕捉しながら、管理可能な複雑な時間を維持する。しかし、Mambaはこの基礎の上に構築されているため、まずは状態空間モデルを探求してみよう。
Mambaを構築するキーコンセプト
Mambaの階層構造を学ぶためには、キーとなる概念をしっかりと理解する必要がある。
状態空間モデル
状態空間モデル(SSM)**は、システムが時間とともにどのように変化するかを表し、理解する。SSMは、動いている物体や信号のような動的なシステムを、その現在の状態と入力にどのように反応するかに焦点を当てて記述します。
SSMの中核概念:
状態空間:状態空間:状態空間とは、システムがとりうるすべての位置のマップだと考えてください。例えば、迷路の中をナビゲートする場合、地図上の各ポイントは特定の場所を表します。
状態ベクトル**:これは座標のようなもので、地図上のどこにいるかを表します。現在位置や出口からの距離などの詳細を含むことができます。言語モデルでは、同様のベクトルが入力シーケンスの「状態」を説明するのに役立ちます。これらはembeddingsと考えることができる。
SSMの仕組み:
任意の時間において、SSMは次のように働く:
入力系列 :x(t)$:この情報は、迷路の中で左に移動する命令のように、あなたがモデルに提供するものです。
潜在状態表現 **:これはシステムの現在の状態に関する更新された「知識」である。あなたの位置や出口への行き方など、重要な情報をとらえます。
予測出力系列 :y(t)$:これは、システムが次に何をするかを示すもので、より早く出口に到達するために再び左に移動することを示唆する。
SSMは2つの方程式を使って変化を追跡する:
1.状態方程式:この方程式は、入力に基づいて現在の状態がどのように変化するかを示す:
h'(t)=Ah(t)+Bx(t)$。
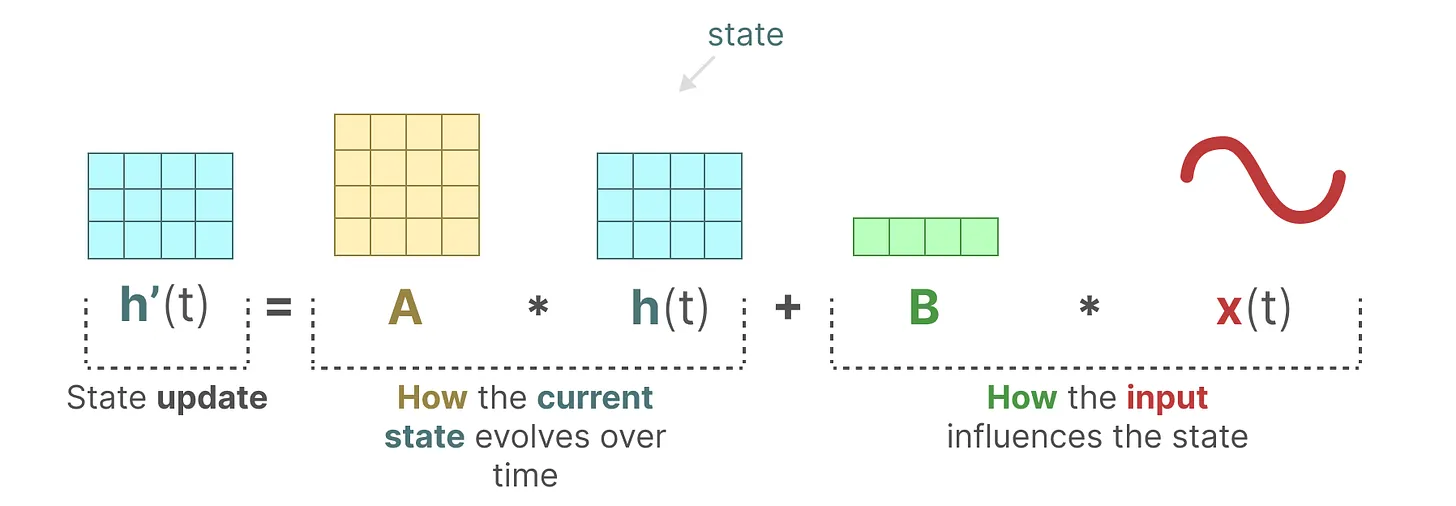 状態空間モデルの状態方程式.png
状態空間モデルの状態方程式.png
状態空間モデルの状態方程式|出典
行列 :この行列はシステムの異なる部分がどのようにつながっているかを示す。SSMにおける行列は、過去の情報を保持し、どれだけの履歴が隠れた状態に取り込まれるかを決定するために重要である。HiPPO(高次多項式射影演算子)を用いると、行列は入力信号を圧縮し、古いトークンを減衰させながら最近のトークンを効果的に捕捉する。
行列 **:これは入力が現在の状態にどのように影響するかを示す。
2.出力方程式:この方程式は、状態がどのように出力につながるかを説明する:
y(t)=Ch(t)+Dx(t)$である。
 状態空間モデルの出力式.png
状態空間モデルの出力式.png
状態空間モデルの出力式|出典
行列**:これは状態を出力に変換する。
行列***:入力から出力への直接の経路を提供する。そのため、スキップ接続とも呼ばれる。
行列 、、、 は、モデルの学習可能な要素であるため、しばしばパラメータと呼ばれる。
これらの方程式は、SSMが入力から学習したことに基づいて、次に何が起こるかを予測するのに役立つ。このアプローチは、動きや信号を追跡するような、時間とともに連続的に変化するシステムをモデル化するのに役立つ。
アーキテクチャはこんな感じだ:
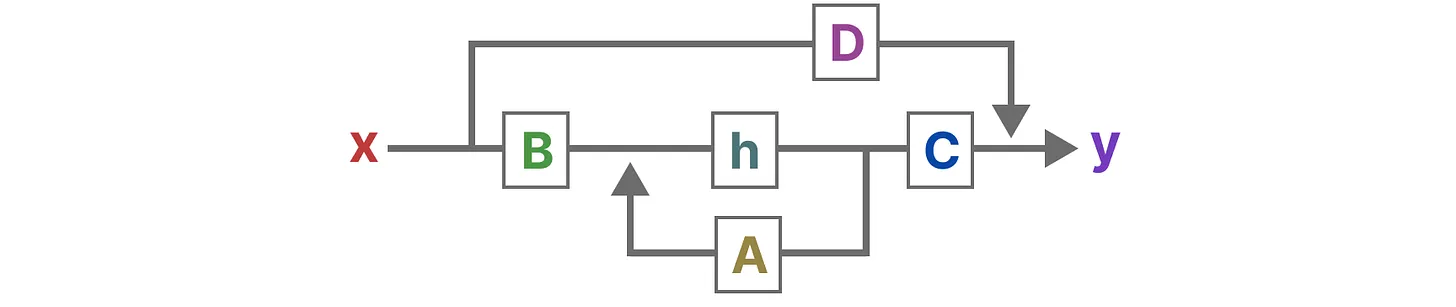 SSMの完全なアーキテクチャ.png
SSMの完全なアーキテクチャ.png
SSMの完全なアーキテクチャ|ソース
大規模言語モデル](https://zilliz.com/glossary/large-language-models-(llms))が入力を離散テキストとして処理するのに対して、方程式は時間に依存するので連続的である。連続信号を離散信号に変換する方法を探ってみよう。
離散化
テキストシーケンスのように、我々が遭遇するほとんどの入力は離散的であるため、連続モデルを離散モデルに変換する方法が必要です。連続信号を離散信号に変換するために、ゼロ次ホールド法を使います。その方法は以下の通りである:
ホールド値**:離散入力を受け取るたびに、次の入力を受け取るまでその値を保持する。このプロセスは、SSMが利用できる連続信号を効果的に作り出します。
ステップサイズ** :値を保持する時間は、ステップサイズと呼ばれる学習可能なパラメータによって制御される。このパラメータは入力の分解能を表し、連続信号をどれだけ細かくサンプリングするかを決定する。
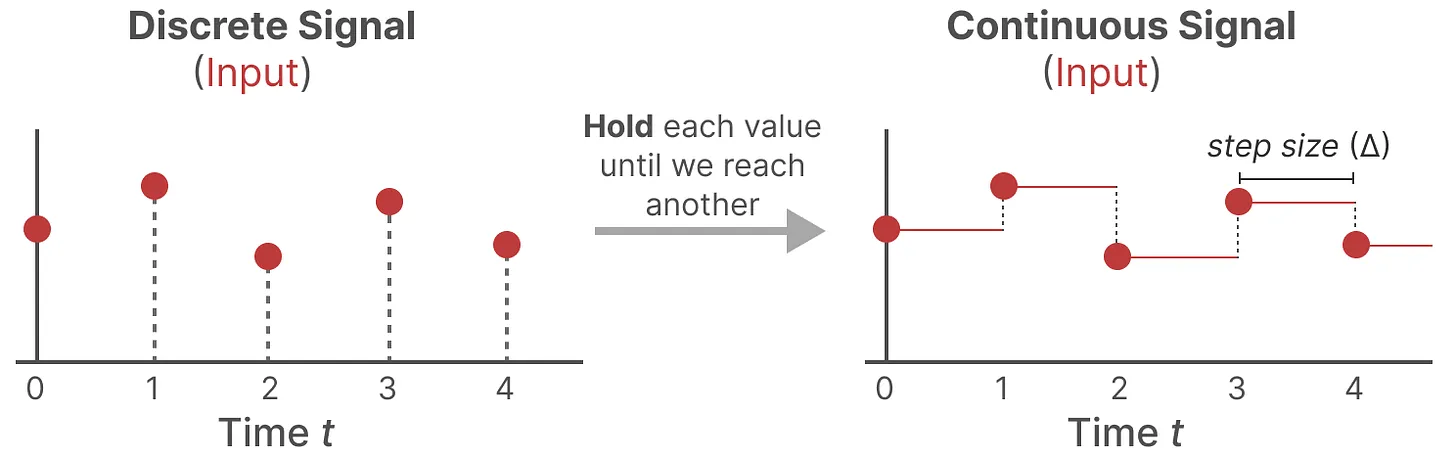 離散化のためのゼロ次ホールドテクニック.png
離散化のためのゼロ次ホールドテクニック.png
離散化のためのゼロ次ホールドテクニック|出典
入力をこのように連続的に表現したら、同じような定数形式で出力を生成し、入力の時間ステップに従ってこれらの値をサンプリングすることができます。サンプリングされた値が離散化された出力になります。
これによって、行列の表現が変わります:
これらの行列は言語タスクに適している。状態方程式と出力方程式は次のようになります:
状態方程式 。
出力方程式
離散化された時間ステップを表すためにの代わりにを使います。これにより連続SSMと離散SSMの違いがより明確になります。
状態空間モデル(SSM)におけるリカレント表現と畳み込み表現
状態空間モデル(SSM)を扱うとき、タスクと入力データの形式に応じて、複数の方法で表現することができる。SSMの計算に役立つ2つの一般的な表現は、リカレント表現とコンボリューション 表現である。
リカレント表現
このアプローチは、リカレントニューラルネットワーク(RNN)がシーケンスを扱う方法と一致している。連続的な信号を離散的なタイムステップに分割することで、各入力がシステムにどのように影響するかを一歩一歩計算することができる。各タイムステップで、現在の入力が前の状態とどのように相互作用するかを決定し、状態を更新して、次の出力を予測できるようにする。
この方法はRNNと似ており、シーケンスを繰り返し処理し、ステップごとに前の状態を使用します。時間の経過に伴うシーケンスのアンローリングは、過去の情報が現在の予測に影響を与えるRNNのプロセスを反映しています。これは、逐次データ処理のための構造化されたステップバイステップの方法を提供する。
コンボリューション表現
SSMを表現するもう一つの方法は、コンボリューションアプローチ である。タイムス テップごとに各入力を個別に処理する代わりに、トークンのシーケンスに対してフィル ター、つまりカーネルを適用し、1次元空間の入力全体の特徴を集約する。
この方法は畳み込みニューラルネットワーク (CNN)に似ており、カーネルは入力シーケンスを横切って移動し、各位置で計算を実行する。この方法は、CNNが画像データを扱うのと同様に並列に学習することができ、学習時の計算効率が高い。しかし、推論時にはカーネルのサイズが固定されるため、リカレント法に比べて柔軟性が制限される。
組み合わせ
リカレント表現と畳み込み表現にはユニークな利点がある。リカレントSSMは効率的な推論を可能にし、畳み込みSSMは並列化された学習をサポートする。これらを組み合わせることで、より高速な学習にはコンボリューション表現を使用し、より効率的な推論にはリカレント表現**を使用することができる。
しかし、これらのモデルの重要な限界は線形時間不変性(LTI)であり、行列、、は全てのタイムステップで固定されたままであるため、静的で内容にとらわれない表現になってしまう。そこでMambaは、システムをより動的で適応的なものにするための改良を加える。
Mambaとは何か?
Mambaはシーケンスモデリングのための新しいアーキテクチャであり、機械学習でよく使われるTransformerモデルの代替を提供するように設計されている。選択的状態空間モデル(Selective State Space Model: SSM)を導入しており、関連性のあるデータに焦点を当て、関連性のない部分を捨てることで、より効率的に情報を処理することができる。
Mambaは、状態空間モデル(SSM)に存在する以下の問題に対処することができる:
線形時間不変性**:SSMは、行列(A、B、C)が静的ですべてのトークンに対して同じであるため、シーケンス内の各トークンを平等に扱う。
貧弱な内容認識**:これらの行列の固定された性質のために、SSMは内容に基づいて特定の入力に焦点を当てたり無視したりすることができない。
パターンを想起できない**:パターンを再現するタスクにおいて、SSMはその時間的不変性のため、履歴から特定のトークンを呼び出すのに苦労する。マトリックスBは入力から独立したままであるため、モデルが特定の入力に適応し、シーケンス内のパターンを認識することを妨げる。
マンバがそれを解決する方法は以下の通りである:
選択的スキャンアルゴリズム
動的行列(BとC)**:行列が静的である従来の状態空間モデルとは異なり、Mambaは行列BとCを動的で入力に依存するものにする。これにより、モデルはシーケンス内の関連情報に焦点を当て、無関係な部分を無視することができる。このアプローチにより、S4のような先行モデルが抱える内容認識の問題に対処し、選択的注意を必要とするタスクでMambaが優れた性能を発揮することを可能にしている。
入力適応型ステップサイズ**:調整可能なステップサイズ(⊿)を組み込むことで、マンバは選択的に入力を圧縮することができる。重要なステップでは入力に重点を置き、小さなステップでは事前のコンテクストを重視し、即時の入力と長期的な依存関係のバランスをとる。
ハードウェア対応アルゴリズム
並列スキャン・アルゴリズム**:状態空間モデルにおける再帰性は、各状態が前の状態に依存するため、一般的に並列化を制限する。しかし、Mambaはこの制限を打ち破る並列スキャンメカニズムを導入し、効率的なハードウェアアクセラレーションによる並列計算を可能にします。このため、性能劣化を起こすことなく、より長いシーケンスにもスケーラブルに対応できる。
カーネル・フュージョン**:複数の演算をカーネルに統合することで、Mambaはメモリレベル(GPUのDRAMやSRAMなど)間の中間結果の保存と転送の必要性を低減します。これにより、メモリ・アクセス・パターンが最適化され、特にGPUのような最新のハードウェアでは、速度とエネルギー効率の両方が向上します。
再計算**:バックプロパゲーションの中間状態を保存する代わりに、Mambaはバックワードパス中にそれらを再計算し、メモリ負荷を軽減します。これは計算コストが高いように見えますが、メモリアクセス時間の節約により、特に長いシーケンスでは効率的です。
強化されたモデル構造
上記の機能強化に基づき、Mambaモデルの構造は以下のようになる:
リカレントSSMと長距離依存関係**:Mambaは行列AのHiPPO(Highly Parallelizable Ordinary Differential Equation)初期化を活用し、言語生成のようなタスクに重要な長距離依存性を効率的に取り込みます。
Mambaブロックのスタック**:マンバブロックは、トランスフォーマーデコーダーブロックと同様に積み重ねることができる。そうすることで、あるMambaブロックの出力を別のMambaブロックに渡すことで、より深くシーケンスを処理することができる。
正規化**](https://zilliz.com/learn/layer-vs-batch-normalization-unlocking-efficiency-in-neural-networks) および ソフトマックス レイヤー:これらのレイヤーは、スムーズで安定した学習を保証し、適切な出力トークンを選択するためにアーキテクチャに追加される。
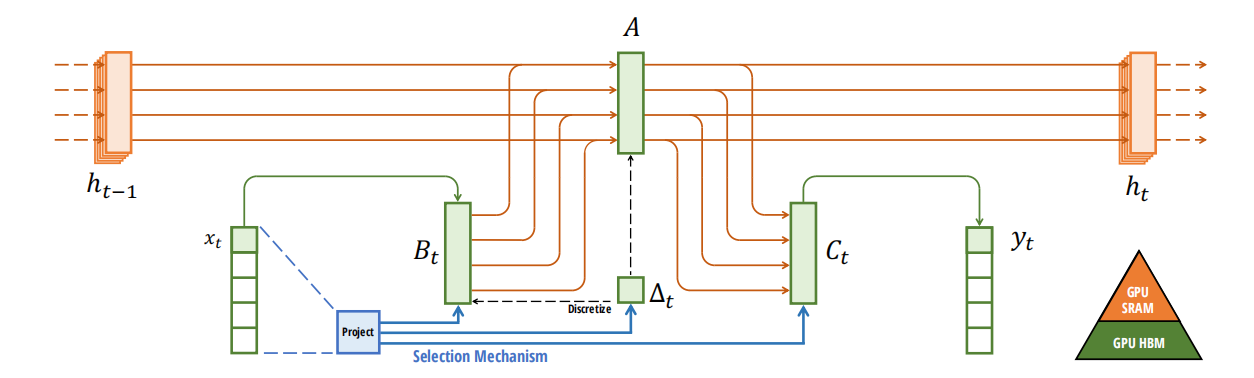 選択的SSMまたはマンバアーキテクチャ.png
選択的SSMまたはマンバアーキテクチャ.png
選択的SSMまたはマンバ・アーキテクチャー|ソース
それでは、トランスフォーマーモデルとの比較を見てみよう。
マンバ対トランスフォーマー
Mambaアーキテクチャは、標準的なTransformerモデル、特にGPT-3アーキテクチャ、およびTransformer++と呼ばれるより強力なバリアントに対して評価されました。この評価では、様々な下流タスクにおけるプレプレキシティやゼロショット性能といったプレトレーニングメトリクスに焦点を当てた。
**1.事前学習性能
MambaのプレトレーニングはPileデータセットを使って行われ、モデルサイズはGPT-3のものと同じに設定された。スケーリング則](https://arxiv.org/abs/2001.08361)をチンチラプロトコル下で分析した結果、Mambaは標準的なTransformerモデルよりも、特に長いシーケンスに関するシナリオで優れていることが明らかになった。Mambaは、約1億2,500万から13億パラメータまでのモデルサイズにおいて、高度なTransformerレシピ(Transformer++)の性能に匹敵する最初のアテンションフリーモデルである。その結果、Mambaは、より少ないパラメータで、Transformerモデルと同等以上の性能を発揮できることが示されました。
**2.ゼロショット評価
Mambaは、様々なダウンストリームタスクにおいて、PythiaやRWKVを含む 様々なオープンソースモデルを一貫して凌駕しました。Mambaは、ゼロショット評価において、すべてのタスクでクラス最高の性能を発揮し、同程度のモデルサイズでPythiaやRWKVを大きく上回りました。
**3.モデル効率
Mambaアーキテクチャは、学習と推論の両方で優れた効率を示した。ベンチマークにおいて、Mambaは同規模のTransformerよりも4~5倍高い推論スループットを達成した。キーバリュー(KV)キャッシュがないため、Mambaはより大きなバッチサイズを利用でき、全体的なスループットを向上させることができた。
**4.ダウンストリームタスクのパフォーマンス
言語モデリングやゲノム配列分類などの下流タスクにおいて、Mambaはより長いコンテキストの活用において顕著な優位性を示した。Mambaの選択的状態空間モデル(SSM)メカニズムは、Transformerベースのモデルがコンテキストの長さが長くなるにつれてリターンが減少するのに対し、非常に長いシーケンスでもパフォーマンスを維持した。
**5.スケーラビリティと適応性
Mambaのアーキテクチャは有望なスケーラビリティを示している。Mambaの性能は、モデルサイズが大きくなるにつれて一貫して向上し、HyenaDNAとTransformer++の両モデルを大幅に少ないパラメータで凌駕しています。また、Mambaの選択的なSSM機能により、コンテキストの長さが変化しても効果的に適応することができます。
結論
この記事では、MambaがTransformerモデルとどのように競合するかについて議論した。要約すると
Transformer**は長距離の依存関係を効果的に管理するが、推論時の時間の複雑さに課題がある。
状態空間モデル(SSM)**は、動的システムを表現し、状態変化を追跡するための数学的枠組みを提供します。SSMは2つの主要な方程式を使用する。1つは状態を更新するための方程式、もう1つは出力を生成するための方程式である。
離散化は連続入力をSSMで処理するための離散表現に変換する。Recurrentとconvolutional**アプローチは、一方は推論に、もう一方は学習に使われ、SSMを計算する。
Mamba**は選択的スキャンとハードウェアを考慮したアルゴリズムを用いて欠点に対処し、Transformerモデルとよく比較している。
Mambaは、Transformerのような従来のモデルが直面する課題に対する説得力のあるソリューションを提供します。状態空間モデルの原理を活用し、効率と性能のバランスを取っている。
その他のリソース
以下は、さらなる探索のためのリソースである:
ニューラル言語モデルのスケーリング法則](https://arxiv.org/abs/2001.08361)
Mamba: 選択的状態空間による線形時系列モデリング](https://arxiv.org/abs/2312.00752)
HiPPO: 最適多項式射影によるリカレントメモリ](https://arxiv.org/abs/2008.07669)
長距離アリーナ:効率的な変圧器のためのベンチマーク](https://arxiv.org/abs/2011.04006)
構造化状態空間による長いシーケンスの効率的モデリング](https://arxiv.org/abs/2111.00396)
レジェンドルメモリユニット:連続時間表現](https://proceedings.neurips.cc/paper_files/paper/2019/file/952285b9b7e7a1be5aa7849f32ffff05-Paper.pdf)
PagedAttentionによる大規模言語モデルサービングの効率的なメモリ管理](https://zilliz.com/learn/efficient-memory-management-for-llm-serving-pagedattention)
RoBERTaとは](https://zilliz.com/blog/roberta-optimized-method-for-pretraining-self-supervised-nlp-systems)
ベクトルデータベースとは](https://zilliz.com/learn/what-is-vector-database)
RAGとは](https://zilliz.com/learn/Retrieval-Augmented-Generation)
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
読み続けて

ベクターデータベース検索テクノロジーの未来を再定義する
ベクターデータベースを使った検索の未来は有望で、AIの統合とコンテキストを意識した体験が先導する。

ベクトル・データベースに最適化されたデータ・モデリング技法
この記事では、ベクター・データベースのパフォーマンスを最適化するためのさまざまなデータ・モデリング・テクニックを紹介する。

BM25を使いこなす:Milvusにおけるアルゴリズムとその応用を深く掘り下げる
Milvusを使えば、文書とクエリをスパースベクトルに変換するBM25アルゴリズムを簡単に実装できる。そして、これらのスパースベクトルは、特定のクエリに従って最も関連性の高い文書を見つけるためのベクトル検索に使用することができる。