




ベクトルデータベースとは?その仕組みとは?
ベクトルデータベースは、高速な情報検索と類似検索のために、機械学習モデルによって生成されたベクトル埋め込みを保存し、インデックス作成し、検索を行うものです。本記事では、ベクトルデータベースの仕組み、主な特徴とユースケース、およびエコシステムについて説明します。
シリーズ全体を読む
- 非構造化データ入門
- ベクトルデータベースとは?その仕組みとは?
- ベクトルデータベースについて: ベクトルデータベース、ベクトル検索ライブラリ、とベクトル検索プラグインの比較
- Milvusベクトルデータベース入門
- Milvus Quickstart:五分間だけでMilvus ベクトルデータベースをインストール
- ベクトル類似検索入門
- ベクター・インデックスの基本について知っておくべきすべてのこと
- スカラー量子化と積量子化
- 階層的航行可能小世界(HNSW)
- おおよその最近接者 ああ(迷惑)
- プロジェクトに適したベクトルインデックスの選択
- DiskANNとヴァマナアルゴリズム
- データの完全性を守る:ベクターデータベースにおけるバックアップとリカバリ
- AIにおける高密度ベクトル:機械学習におけるデータの可能性の最大化
- ベクターデータベースとクラウドコンピューティングの統合:現代のデータ課題に対する戦略的ソリューション
- 初心者のためのベクターデータベース導入ガイド
- ベクトル・データベースにおけるデータの完全性の維持
- 行と列からベクトルへ:データベース技術の進化の旅
- ソフトマックス活性化関数の解読
- ベクトル・データベースにおけるメモリ効率のための積量子化の利用
- ベクターデータベースにおける検索性能のボトルネックを発見する方法
- ベクターデータベースの高可用性の確保
- Locality Sensitive Hashingのマスター:包括的なチュートリアルと使用例
- ベクターライブラリ vs ベクターデータベース:どちらが適しているか?
- 微調整テクニックでGPT 4.xのポテンシャルを最大限に引き出す
- マルチクラウド環境におけるベクターデータベースの展開
- ベクトル埋め込み入門:ベクトル埋め込みとは何か?
ベクトルデータベース101へようこそ。
前回のチュートリアルでは、日々増加し続けるデータについて簡単に説明しました。また、これらのデータがどのようにして構造化/半構造化および非構造化データ種類に分類されるか、それらの違い、そして現代の機械学習がベクトル埋め込みを介して非構造化データを理解する方法について説明しました。最後に、このデータ処理がどのように近似最近傍探索(ANN)によって行われるかについて簡単に触れました。 これらの情報を踏まえると、増え続けるデータによって、新しいパラダイムシフトと新しいカテゴリのデータベースとデータ管理システムが必要となったことが明らかになりました。それがベクトルデータベースです。
ベクトルデータベースとは?
まず最初に、ベクトルデータベースとは何か?詳細を紹介する前に、この質問に簡単な答えを与え、ベクトルデータベースについてのいくつかの重要な事実をご紹介します。
- ベクトルデータベースは、新しいデータベースシステムであり、高次元のベクトル埋め込みを保存、インデックス作成、検索することで、高速なセマンティック情報検索とベクトルセマンティック検索を可能にします。
- ベクトルデータベースは、現代のAIスタックの主要なインフラストラクチャ・コンポーネントです。検索拡張生成(RAG)では、大規模言語モデル(LLM)の出力を拡張し、LLMに外部知識を提供することでAIのハルシネーションを解消します。ベクトルデータベースはこの外部知識を保存することによって、LLMがより正確な回答を生成するために文脈情報を見つけ・検索します。
- ベクトルデータベースは、チャットボット、推薦システム、画像/ビデオ/音声検索、セマンティック検索、およびRAGなどのユースケースやアプリケーションで広く使用されています。
- 主流の特化型ベクトルデータベースには、Milvus、Zilliz Cloud(完全管理型Milvus)、Qdrant、Weaviate、Pinecone、およびChromaがあります。
- 特化型ベクトルデータベースに加えて、多くの伝統的な関係データベースが小規模なベクトル検索を実行できるベクトルプラグインを追加しています。これにはCassandra、MongoDB、およびPgvectorなどのデータベースが含まれます。 さまざまなベクトルデータベースを比較するには、このベクトルデータベース比較ページを参照してください。 パフォーマンスを評価するには、このベクトルデータベースベンチマークページを参照してください。
ベクトルデータベースと伝統的なデータベースの違い
ベクトルデータベースと伝統的なデータベースの主な違いは何でしょうか?
伝統的なデータベース、特に関係データベースは、事前定義された形式を持った構造化データの管理と正確な検索操作に優れています。これに対して、ベクトルデータベースの強みは、データ対象の高次元数値表現、つまり、ベクトル埋め込みを通じて、画像、音声、動画、テキストコンテンツなどの非構造化データ種類の保存、インデックス作成、および検索にあります。従来の関係データベースの行と列とは異なり、ベクトルデータベースのデータポイントは類似性によってクラスター化された、固定の次元のベクトルとして表されます。 ベクトルデータベースは、近似最近傍検索(ANN)などの手法を使用して、ベクトル空間でのベクトル間の距離を計算することによってセマンティック類似検索(ベクトル検索とも呼ばれます)を行います。 ベクトルデータベースは、推薦システム、セマンティック検索、チャットボット、検索拡張生成(RAG)、異常検出、および類似画像・ビデオ。音声コンテンツの検索ツールなど、さまざまな分野のアプリケーション構築に幅広く採用されています。 人工知能(AI)とChatGPTのようなLLMの台頭により、ベクトルデータベースは、LLMのハルシネーションを解消するために使用される検索拡張生成(RAG)パイプラインの重要なインフラストラクチャ・コンポーネントとなっています。
ベクトルデータベースの仕組みとは?
MilvusやZilliz(完全管理型Milvus)のようなベクトルデータベースは、ベクトル埋め込みを保存、処理、インデックス作成、検索するために特別に構築されています。ほとんどのベクトルデータベースは、階層的ナビゲーション可能スモールワールド(HNSW)、局所性鋭敏型ハッシュ(LSH)、および直積量子化(PQ)などの主流のインデックスをサポートしています。言い換えれば、ベクトルデータベースは主にベクトル埋め込みを操作し、このデータをベクトル埋め込みに変換する機械学習モデルと密接に連携します。 以下の図は、ベクトルデータベースの仕組みを示しています。ここでは、例としてZillizを使用しています。
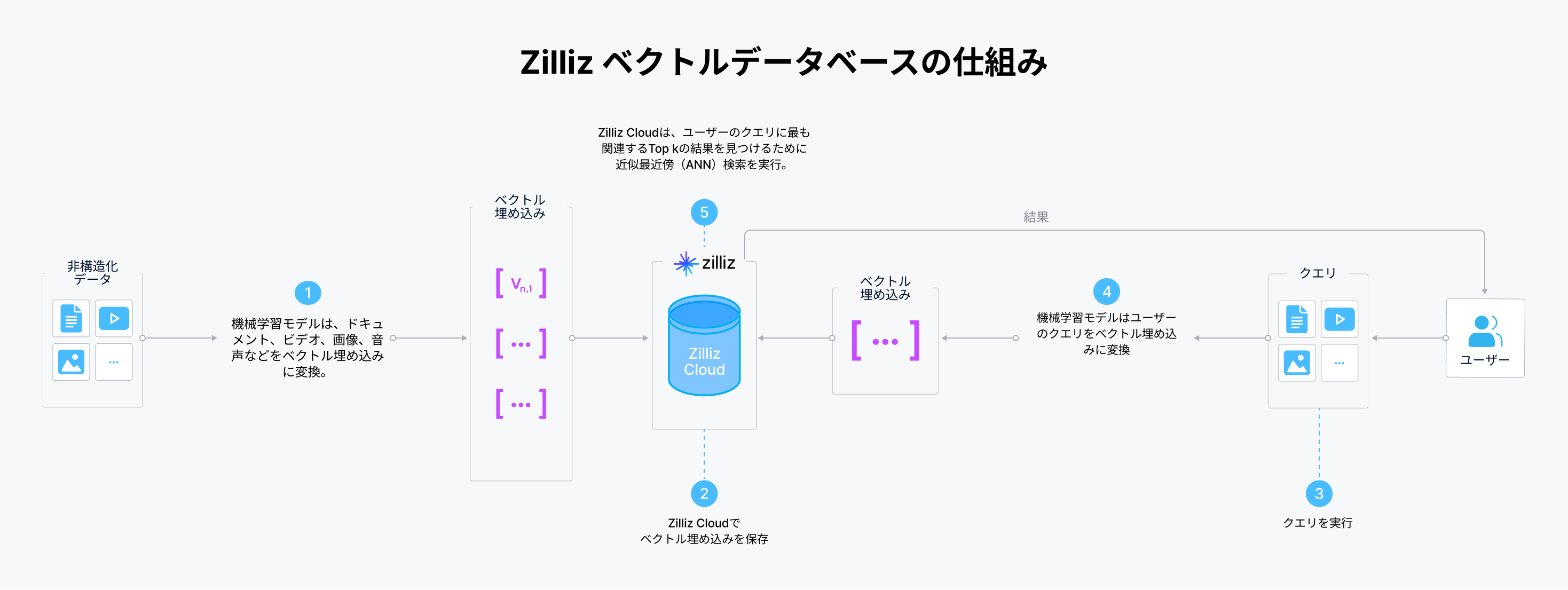 Zilliz ベクトルデータベースの仕組み
Zilliz ベクトルデータベースの仕組み
- 機械学習モデル(通常は埋め込みモデル)は、あらゆる種類の非構造化データをベクトル埋め込みに変換します。
- ベクトル埋め込みはZilliz Cloudに保存されます。
- ユーザーがクエリを実行します。
- 機械学習モデルがクエリをベクトル埋め込みに変換します。
- Zilliz Cloudは、近似最近傍(ANN)アルゴリズムを使用して、クエリベクトルとデータセット内のベクトルの距離を比較し、クエリに最も関連するTop-kの結果を見つけます。
- Zilliz Cloudは結果をユーザーに返します。
1000フィートから見たベクトルデータベース
今や有名になったImageNetデータセットにラベルを付けるために、どれだけのキュレーターが必要だったか予想できますか? 答えは…25,000人です(ものすごい人数ですね)。 画像、動画、ドキュメントの全文、音声などの非構造化データに、ラベルやタグを人手で付けるのではなく、その内容をもとに検索できるようにすることが、まさにベクトルデータベースの役割です。強力な埋め込みモデルと組み合わせることで、Milvusのようなベクトルデータベースは、eコマースのソリューション、推薦システム、セマンティック検索、コンピュータセキュリティ、製薬業界、その他多くの分野に革命をもたらす可能性を秘めています。 ユーザー視点で考えてみましょう。優れた使用性やユーザーAPIに欠けた技術は役に立ちません。基盤技術に加え、マルチテナンシーと使用性も非常に重要な属性です。ベクトルデータベースで重要視すべき特徴を挙げてみましょう(多くの特徴は構造化・半構造化データのベクトルデータベースにも共通していますが):
スケーラビリティとチューナビリティ
ベクトルデータベースに保存される要素が数億や数十億に増えるにつれ、複数ノードにまたがる水平スケーリングが極めて重要になります(3ヶ月ごとにサーバーラックに手動でRAMスティックを追加するのは面白くないですよね)。さらに、挿入レートやクエリレート、基盤ハードウェアの違いにより、アプリケーションのニーズが異なったりする可能性もあるため、最高のベクトルデータベースには、システム全体のチューナビリティも必要な条件です。
マルチテナンシーとデータ隔離
複数のユーザーをサポートすることは、すべてのデータベースシステムにとって当然の機能です。しかし、全ユーザーに新しいベクトルデータベースを作成するのは、必死すぎる所業となり、誰にとってもあまり良い結果を生みません。この耐障害性の概念と並行して必要なのがデータ隔離です:データベース内に一つのコレクションに対して行われた挿入、削除、またはクエリは、コレクション所有者が情報を共有することを望まない限り、システムの他の部分からは見えない状態であるべきです。
完全なAPIスイート
完全なAPIプログラミング言語やSDKを備えていないデータベースは、率直に言って、実際のデータベースではありません。例えば、MilvusはPython、Node、Go、JavaのSDKを提供しており、Milvusベクトルデータベースとの通信および管理を可能にしています。
直感的なユーザーインターフェース/管理コンソール
ユーザーインターフェースは、ベクトルデータベースに関連する学習曲線を大幅に削減できます。また、これらのインターフェースは通常にアクセスできない新機能やツールの提供を可能にしています。 ふう。かなりの情報量でしたね。ここでまとめましょう:ベクトルデータベースには次の機能が備わっているはずです。1) スケーラビリティとチューナビリティ、2) マルチテナンシーとデータ隔離、3) 完全なアクセス制御とAPIスイート、そして4) 直感的なユーザーインターフェース/管理コンソールです。次の2つのセクションでは、この概念を踏まえ、ベクトルデータベースとベクトル検索ライブラリおよびベクトル検索プラグインとの比較について、それぞれ説明します。
大規模言語モデル(LLM)と共にベクトルデータベースを使用する方法
ベクトルデータベースは、埋め込みモデルのベクトル埋め込み(特にはOpenAIのテキスト埋め込みモデルやResNet50の画像埋め込みモデル、その他多くのマルチモーダルモデル)の力を活用して、大規模な非構造データセットを管理、インデックス化、検索するための完全に管理された、簡素なソリューションです。 大規模言語モデル(LLM)は、事前に学習された知識に基づいて、さまざまな自然言語処理(NLP)タスクを実行できる生成AIモデルです。しかし、LLMは特定の領域に関する知識が不足しているため、ハルシネーション(誤った情報の生成)が生じやすいです。ベクトルデータベースは、このハルシネーションの問題を対処するために、LLMに対して、領域特定の最新で機密性のあるプライベートデータを提供する重要な技術です。
ベクトルデータベースをLLMと一緒に使用する方法
Zilliz Cloudベクトルデータベースを例として見てみましょう。Zilliz Cloudは、LLMの外部に、領域特定の最新で機密性のあるプライベートデータをベクトル埋め込みの形式で保存します。ユーザーが質問を与えると、Zilliz Cloudはその質問をベクトルに変換し、その後、クエリのベクトルとベクトルデータベースに格納されたベクトルとの空間的距離を比較して、最も関連性の高いTop-kの結果をANN検索で取得します。この測定は、内積、コサイン類似度、またはユークリッド距離(L2)などのさまざまな類似性メトリクスに基づいて行われます。さらに、データと共にメタデータを保存している場合、ハイブリッド検索で結果をファインチューニングできます。最後に、これらの結果を元の質問と組み合わせて、LLMにとって包括的なコンテキストを提供するプロンプトを作成します。
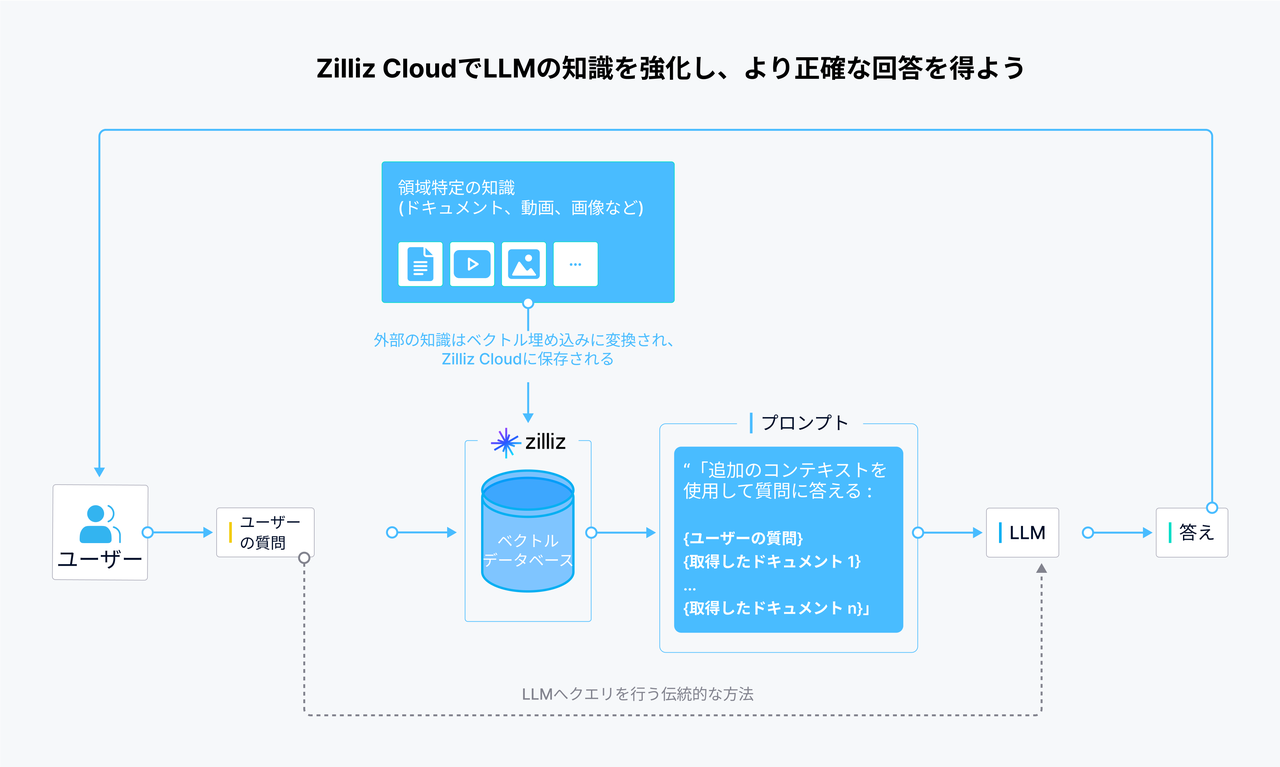 Zilliz CloudでLLM
Zilliz CloudでLLM
このフレームワークは、ベクターデータベース、LLM、およびコードとしてのプロンプトを含み、検索拡張生成(RAG)としても知られており、LLM駆動型アプリケーション開発の基盤となっています。
ベクトルデータベースの技術的課題
このチュートリアルの冒頭で、ベクトルデータベースが実装すべき機能についてリストアップしました。そのあとで、ベクトル検索ライブラリや検索プラグインと比較してその優位性を説明しました。ここでは、ベクトルデータベースが直面する複雑な技術的課題について簡単に説明します。将来のチュートリアルでは、Milvusがこれらの課題にどのように対処しているか、そして他のオープンソースベクトルデータベースと比べて、その技術的決定がどのようにMilvusのパフォーマンスを向上させたのかについても取り上げます。 飛行機をイメージしてください。飛行機自体は、機械システム、電気システム、そして組み込みシステムなど、互いに接続された多くのシステムで構成されており、それらが調和して動作することで快適な飛行体験を提供しています。同様に、ベクトルデータベース(VectorDB)は進化する複数のソフトウェアコンポーネントで構成されます。これらは大まかに、ストレージ、インデックス、サービスの3つの部分に分けられます。この3つの部分は密接に統合されていますが[1]、Snowflakeのような企業は、ストレージ業界全体に向けて、「共有ストレージ」モデルよりも「共有なし」アーキテクチャが優れていることを示しました。そのため、ベクトルデータベースが直面する最初の課題は、柔軟でスケーラブルなデータモデルの設計です。 では、もしデータモデルができたとして、その次は何でしょうか?すでにベクトルデータベースに保存されているデータ検索すること、つまりベクトルクエリおよびインデックス作成が次の重要な要素になります。機械学習や多層ニューラルネットワークの計算負荷の大きさにより、GPU、NPU/TPU、FPGAや、その他の汎用計算ハードウェアが普及しました。ベクトルインデックス作成やクエリも計算負荷が高く、アクセラレーター上で実行することで最大の速度と効率を発揮します。このように多様な計算リソースが存在することがもたらしたのは、次の課題である異種コンピューティングアーキテクチャの開発です。 データモデル、クエリエンジン、アーキテクチャが整ったら、最後に重要なのはアプリケーションがデータベースから読み取れるようにすることです。これは、最初のセクションで触れたAPIやユーザーインターフェースに密接に関係しています。新しいデータベースカテゴリには、最大のパフォーマンスを最低限のコストで引き出すための新しいアーキテクチャが必要ですが、多くのベクトルデータベースユーザーは依然として従来のCRUD操作(例: SQLのI挿入、選択、更新、削除)に慣れています。そのため、最後の課題は、既存のUI習慣を活用しつつ、基盤となるアーキテクチャとの適合性を維持できるAPIとGUIの開発です。 これらの3つのコンポーネントが、それぞれ主要な技術的課題に対応していることに注意してください。とはいえ、万能なベクトルデータベースアーキテクチャは存在しません。最適なベクトルデータベースは、これらの課題すべてを克服し、最初のセクションで述べた機能を提供することに重点を置きます。
ベクトルデータベースの利点
ベクトルデータベースは、ベクトル類似性検索、セマンティック検索、機械学習、生成AI(GenAI)アプリケーションなどのユースケースにおいて、主導の伝統的な関係データベースに対していくつかの利点が見られます。その主な利点は以下の通りです:
- 高次元検索: 画像認識、自然言語処理、推薦システムなど、機械学習や生成AIアプリケーションで一般的に使用される高次元ベクトルの効率的な類似性検索を実行します。与えたクエリに最も類似したデータポイントを迅速に見つけることが可能になることは、推薦エンジン、画像認識、自然言語処理などのアプリケーションに極めて重要です。
- スケーラビリティ: 水平スケールが可能で、大量の高次元ベクトルを効率的に保存および検索できます。リアルタイム検索と大規模データ検索を必要とするアプリケーションにとって重要です。
- ハイブリッド検索の柔軟性: スパース・デンスベクトルを含むさまざまなベクトルデータ型を処理できます。また、数値、テキスト、バイナリなどの複数のデータ型にも対応します。
- パフォーマンス: ベクトル類似性検索を効率的に実行し、伝統的なデータベースよりも高速な検索時間を可能にします。
- カスタマイズ可能なインデックス作成: 特定のユースケースやデータ種類に応じたカスタムインデックススキームを許可します。 これらの特性により、ベクトルデータベースは、効率的な類似検索やセマンティック検索、複雑データの処理、機械学習などのアプリケーションにおいて、ベクトル空間の中に迅速で効率的な検索と高次元ベクトルデータの取得を実現しました。
最速のベクトルデータベースはどれでしょうか?ベンチマークしましょう。
ANN-Benchmarksは、さまざまなベクトルデータベースおよび最近傍探索アルゴリズムの性能を評価するためのベンチマーク環境です。主な機能は以下の通りです:
- データセットとパラメータ指定: 異なるサイズと次元を持ったさまざまなデータセットと、検索対象の近傍数や使用する距離メトリックなど、各データセットに対するパラメータのセットを提供します。
- 検索再現率計算: ベンチマークは、検索再現率、すなわち、返されたk個の近傍内で実際の最近傍が見つかるクエリの割合を計算し、アルゴリズムの精度を評価します。検索再現率は最近傍探索アルゴリズムの正確度を評価するメトリックです。
- RPS計算: ベンチマークはまた、クエリ処理速度(RPS:秒間クエリ数)、すなわち、ベクトルデータベースまたは検索アルゴリズムがクエリを処理できる効率を測定し、システムの速度やスケーラビリティを評価します。 ANN-Benchmarksを使用することで、標準化された条件下でベクトルデータベースやアルゴリズムの性能を比較でき、特定のユースケースに最適な選択肢を特定するのに役立ちます。
ベクトルデータベースの比較
どのセマンティック検索ユースケースでも、大量のベクトル埋め込みを保存し、低遅延で最も関連性の高いベクトルを取得する機能が必要です。また、長期的に利用可能で、対象アプリケーションのコンプライアンス要件を満たすベクトルデータベースを選択する必要があります。 ベクトルデータベースを他の代替手段と比較する際には、アーキテクチャ、スケーラビリティ、パフォーマンス、ユースケース、コストを考慮することが重要です。各データベースの強みと弱みが異なるため、特定の要件と優先順位に基づいて評価する必要があります。以下は、適切なツールを選択する際に役立つリソースのリストです:
- オープンソースベクトルデータベースの比較
- ベクトルデータベースのベンチマーク
- Milvus vs Pinecone(およびZilliz vs Pinecone)
まとめ
このチュートリアルでは、ベクトルデータベースについて簡単に紹介しました。具体的には、以下を見てきました:
- 完全なベクトルデータベースに求められる機能
- ベクトル検索ライブラリとの違い
- 従来のデータベースや検索システムの検索プラグインとの違い
- ベクトルデータベース構築における主な技術的課題 このチュートリアルは詳細な解説や具体的なアプリケーション利用方法を示すものではありません。その目的は、概要を提供することにあります。しかし、これこそが、あなたのベクトルデータベースの旅の本当の始まりです! 次回のチュートリアルでは、世界で最も人気のあるオープンソースベクトルデータベースであるMilvusについて紹介します:
- Milvusの簡単な歴史と名前の由来
- Milvus 1.0と2.0の違い、およびMilvusの未来
- Google Vertex AIのMatching Engineなど、他のベクトルデータベースとの比較
- 一般的なベクトルデータベースのアプリケーション
 Frank Liu
Frank LiuFrank Liu is the Director of Operations & ML Architect at Zilliz, where he serves as a maintainer for the Towhee open-source project. Prior to Zilliz, Frank co-founded Orion Innovations, an ML-powered indoor positioning startup based in Shanghai and worked as an ML engineer at Yahoo in San Francisco. In his free time, Frank enjoys playing chess, swimming, and powerlifting. Frank holds MS and BS degrees in Electrical Engineering from Stanford University.


