




ALIGNの説明ノイジー・テキスト教師による視覚・視覚言語表現学習のスケールアップ
ALIGN (A Large-scale ImaGe and Noisy-text embedding)モデルは、ノイズの多い画像-alt-textペアから視覚表現と言語表現を学習するように設計されている。
シリーズ全体を読む
- Cross-Entropy Loss: Unraveling its Role in Machine Learning
- Batch vs. Layer Normalization - Unlocking Efficiency in Neural Networks
- Empowering AI and Machine Learning with Vector Databases
- Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
- Vector Databases: Redefining the Future of Search Technology
- Local Sensitivity Hashing (L.S.H.): A Comprehensive Guide
- Optimizing AI: A Guide to Stable Diffusion and Efficient Caching Strategies
- Nemo Guardrails: Elevating AI Safety and Reliability
- Data Modeling Techniques Optimized for Vector Databases
- Demystifying Color Histograms: A Guide to Image Processing and Analysis
- Exploring BGE-M3: The Future of Information Retrieval with Milvus
- Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
- TF-IDF - Understanding Term Frequency-Inverse Document Frequency in NLP
- Understanding Regularization in Neural Networks
- A Beginner's Guide to Understanding Vision Transformers (ViT)
- Understanding DETR: End-to-end Object Detection with Transformers
- Vector Database vs Graph Database
- What is Computer Vision?
- Deep Residual Learning for Image Recognition
- Decoding Transformer Models: A Study of Their Architecture and Underlying Principles
- What is Object Detection? A Comprehensive Guide
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Algorithmic)
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Methodological)
- Understanding CoCa: Advancing Image-Text Foundation Models with Contrastive Captioners
- Florence: An Advanced Foundation Model for Computer Vision by Microsoft
- The Potential Transformer Replacement: Mamba
- ALIGN Explained: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
近年、自然言語処理(NLP)やコンピュータビジョンを発展させる上で、事前に学習された視覚・視覚言語表現が不可欠となっている。これらの密接に関連する分野は、様々な視覚的・言語的理解タスクをサポートするために、画像や画像とテキストのペアの表現を学習することに焦点を当てている。
視覚表現学習は伝統的に、何百万もの手作業でラベル付けされた画像を含むImageNetのような、大規模でラベル付けされたデータセットに依存してきた。一方、視覚言語表現学習では、MSCOCOのような、画像とキャプションのペアからなるデータセットを使用し、キャプションを生成したり、テキストに基づいて画像を検索したりするモデルを学習する。
これらのデータ駆動型アプローチは、この分野を発展させてきた一方で、大規模データセットの作成、人間の労力、専門知識を必要とするスケーラビリティに関する課題も抱えている。もう一つの課題は、膨大なデータセットに含まれるノイズや不整合であり、これはモデルのパフォーマンスや汎化を低下させる可能性がある。
これらの課題から、研究者たちは、高価なラベル付きデータセットに頼ることなく、視覚・視覚言語モデルを訓練するための新しいアプローチを開発することになりました。ALIGN](https://arxiv.org/pdf/2102.05918)モデルは、時間のかかるデータクリーニングをスキップし、ノイズを処理し、より柔軟でスケーラブルなモデル性能をサポートするために巨大なデータセットを使用することで、この変化を表しています。
さらに詳しく知りたい方は、ALIGN論文をご覧ください。
ALIGNとは?
ALIGN (A Large-scale ImaGe and Noisy-text embedding)モデルは、ノイズの多い画像とテキストのペアから視覚と言語の表現を学習するように設計されています。画像エンコーダとテキスト・エンコーダからなる単純なデュアル・エンコーダ・アーキテクチャを使用します。 これらのエンコーダは、マッチした画像とテキストのペアの埋め込みが類似し、マッチしていないペアの埋め込みが非類似になるように強制する対比的損失を用いて学習される。 このアプローチにより、ALIGNは画像分類、画像-テキスト検索、ゼロショット画像分類を含むタスクにおいて、最先端の(SOTA)結果を達成することができる。
図- ALIGN法の概要.png](https://assets.zilliz.com/Figure_A_summary_of_the_ALIGN_method_60b5e30d3c.png)
図:ALIGN法の概要|出典
方法論
ALIGNモデルの方法論には、以下の重要な段階が含まれる:
1.データセットの構築
2.モデルの学習と最適化
3.モデルの評価
 図- モデル開発と評価パイプライン.png
図- モデル開発と評価パイプライン.png
図モデル開発と評価のパイプライン
データセットの構築
ALIGNは18億以上の画像alt-textペアの大規模データセットを使用します。大規模なフィルタリングが行われるConceptual Captionsのような従来のデータセットとは異なり、ALIGNはノイズを許容しながらスケーラビリティを可能にするために最小限のフィルタリングを使用します。
- 最小限のフィルタリング:** ALIGNは広範なキュレーションの代わりに、基本的な周波数ベースのフィルタリングだけを適用します。例えば、データセットは、無関係または一般的なコンテンツを避けるために、10枚以上の画像で共有されるオルトテキストを除外し、事前に定義されたサイズとアスペクト比のしきい値を持つ画像を保持し、冗長性を減らすために関連するオルトテキストが1,000枚を超える画像を破棄します。また、意味のあるテキストコンテンツを維持するため、短すぎたり長すぎたりするオルトテキスト(3語未満や20語以上など)も削除されます。
 図- 画像とテキストのペアのサンプル.png
図- 画像とテキストのペアのサンプル.png
図:イメージテキスト対のサンプル|出典
学習と最適化
ALIGNモデルは、EfficientNet画像エンコーダと、大規模なデータセットのスケールとノイズを処理するために最適化されたBERTテキストエンコーダからなるデュアルエンコーダアーキテクチャを使用しています。具体的な学習コンポーネントは以下に詳述する。
EfficientNetエンコーダとBERTエンコーダ
EfficientNet:**この 畳み込みニューラルネットワーク(CNN)は計算効率のために最適化され、精度を最大化するために深さ、幅、解像度を調整します。 ALIGNでは、EfficientNetは入力画像を処理し、意味のある埋め込みに変換する画像エンコーダです。
BERT:双方向学習で知られるBERTは単語の文脈を理解するので、ALIGNのテキスト・エンコーダとして適しています。画像-alt-テキストのペアのテキスト成分を処理し、効果的なテキスト埋め込みを生成します。
2つのエンコーダ間の互換性を確保するために、線形活性化を持つ完全連結層がBERTエンコーダに追加される。この層はBERT出力の次元性をEfficientNet出力の次元性と一致するように調整し、ALIGNフレームワーク内での2つのエンコーダのシームレスな統合を可能にする。両方のエンコーダはゼロから訓練され、クロスモーダルなタスクの一貫性を維持するように最適化されています。
正規化ソフトマックス損失による対照学習
ALIGNモデルでは、マッチした画像とテキストのペア間の距離を最小化し、バッチ内のマッチしていないペア間の距離を最大化することで、対比的損失がアライメントを促します。損失関数](https://zilliz.com/learn/Cross-Entropy-Loss-Unraveling-its-Role-in-Machine-Learning)は2つの要素を組み合わせています:画像からテキストへの損失とテキストから画像への損失です。これらの損失は正規化されたsoftmax関数を用いて計算され、画像とテキストの埋め込み間の類似度を測定する。
図-式.png](https://assets.zilliz.com/Figure_Equations_6c1c08d345.png)
図方程式
トレーニングテクニック
温度スケーリング:** ソフトマックスの温度は埋め込み距離のバランスをとるのに役立ち、ALIGNがデータセットに内在するノイズを効果的に管理することを可能にする。
バッチ内ネガティブ:** ネガティブ・サンプルはバッチ内から抽出され、ランダムなペアリングをシミュレートし、広範囲なデータ変動に対するALIGNのロバスト性を強化します。
モデル評価
訓練後、ALIGNモデルは様々な視覚タスクと視覚言語タスクにわたってその能力を評価するために評価を受けました。
検索タスク:** ALIGNの性能は、Flickr30KやMSCOCOのようなベンチマーク・データセットを使って、画像からテキスト、テキストから画像への検索でテストされます。これらのテストは、ALIGNの適応性を測定するために、微調整の有無にかかわらず行われます。また、ALIGNはCrisscrossed Captions (CxC)データセットで評価され、これはMSCOCO注釈を拡張して、モーダル内検索とモーダル間検索をサポートします。
視覚分類:** ImageNet ILSVRC-2012 ベンチマークとその変種における視覚分類タスクに対して、ALIGNモデルのゼロショット転送が行われました。性能は様々な細かい分類データセットに画像エンコーダを適用することで評価され、複数の視覚分類タスクにまたがるVisual Task Adaptation Benchmark (VTAB)での頑健性を測定しました。
結果
画像とテキストのマッチングと検索、ゼロショット視覚分類、画像エンコーダのみによる視覚分類など、ALIGNの能力を評価するために様々な画像テキスト検索と分類タスクが実施されました。
画像テキストのマッチングと検索
ゼロショット設定では、ALIGNは従来のSOTAであるCLIPと比較して、その画像検索能力を7%以上向上させます。さらに、微調整により、ALIGNは、OSCARのような、より複雑なクロスモーダル注意層を利用するものを含む、すべての既存手法を大幅に凌駕します。

図:Flickr30KとMSCOCOデータセットでの画像-テキスト検索結果| 出典
ALIGNはすべてのメトリクスでSOTAの結果を達成しており、特に画像からテキスト(+22.2% R@1)とテキストから画像(20.1% R@1)のタスクで大きなマージンをとっています。R@1はRecall@1の略で、情報検索タスク、特に結果のランキングの文脈で使われる指標である。

図:Crisscrossed Captions (CxC)データセットにおけるマルチモーダル検索性能| 出典
ALIGNはまた、SITSタスクにおいて、DEI2Tのような以前のSOTAを凌駕し、[5.7%]改善した(https://arxiv.org/pdf/2102.05918)。
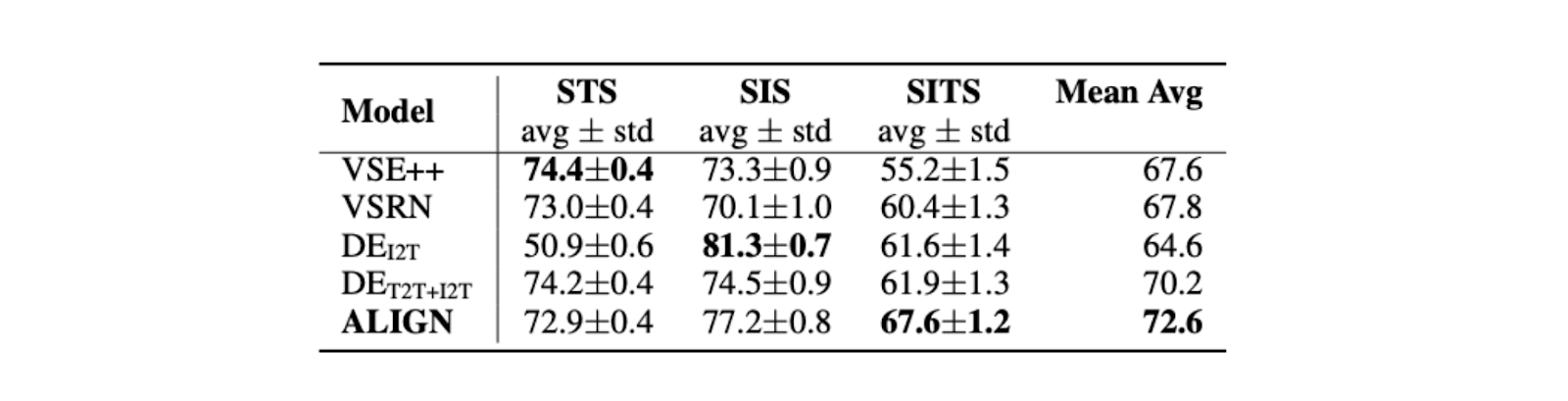 図- Crisscrossed Captions (CxC)データセットにおけるスピアマンのRブートストラップ相関(100).png
図- Crisscrossed Captions (CxC)データセットにおけるスピアマンのRブートストラップ相関(100).png
図Spearman's R Bootstrap Correlation (100) on Crisscrossed Captions (CxC) dataset | Source
ゼロショット視覚分類
ALIGNは、異なる画像分布を持つ分類タスクにおいて、大きな頑健性を示します。公平な比較を行うために、CLIPと同じ迅速なアンサンブル手法が使われる。このようなアンサンブルはImageNetのトップ1の精度を2.9%向上させる。
図- ImageNetとその変種における画像分類へのALIGNのゼロショット転送のトップ1精度](https://assets.zilliz.com/Figure_Top_1_Accuracy_of_zero_shot_transfer_of_ALIGN_to_image_classification_on_Image_Net_and_its_variants_f92bca608b.png)
図ImageNetとその変種におけるALIGNの画像分類へのゼロショット転送のトップ1精度|出典
画像エンコーダのみによる視覚分類
固定パラメータで、ALIGNはCLIPをわずかに上回り、85.5%のトップ1精度のSOTA結果を達成しました。微調整後、ALIGNはBiTとViTモデルの精度を上回り、Meta Pseudo Labelsのすぐ下にランクされ、ImageNetトレーニングと大規模なラベルなしデータとの間のより深い相互作用が必要となります。
図- ImageNet分類結果](https://assets.zilliz.com/Figure_Image_Net_classification_results_94da00a090.png)
図-ImageNet分類結果ImageNet分類結果|出典
ALIGN モデルの応用
ベンチマークタスクでの性能を超えて、ALIGNは実世界のアプリケーション、特に画像検索において、その実用的な有用性を証明しています。ALIGNは2つの異なるタスクに適用しました:テキストプロンプトによる画像検索と、マルチモーダルなクエリ、すなわち画像+テキスト入力に基づく画像検索です。
テキスト画像検索
ALIGNは、CC-BYライセンス画像の膨大なコレクション(学習セットとは異なる)から、テキストクエリのみに基づいて画像を検索します。クエリには、詳細なシーンや、インスタンスレベルの細かい概念を含む説明が含まれます。
図- ALIGNの埋め込みを用いたきめ細かなテキストクエリによる画像検索](https://assets.zilliz.com/Figure_Image_retrieval_with_fine_grained_text_queries_using_ALIGN_s_embeddings_926b6e4795.png)
図ALIGNの埋め込みを用いたきめ細かなテキストクエリによる画像検索|出典
マルチモーダル(画像+テキスト)画像検索
ALIGNは画像とテキストの埋め込みを組み合わせて、マルチモーダル画像検索のために関連画像を検索します。具体的には、クエリ画像とテキスト文字列が与えられると、画像埋め込みとテキスト埋め込みが一緒に追加され、検索のための新しいクエリ埋め込みを形成する。
図- 画像+テキストクエリによる画像検索](https://assets.zilliz.com/Figure_Image_retrieval_with_image_text_queries_1bdd68bf69.png)
図画像+テキストクエリによる画像検索|出典
ハグ顔を用いたALIGNの実装
ALIGNはHugging Face変換ライブラリを使って実装できます。以下にALIGNを実装する手順を示します。以下のコードはHuggingFaceのものです。
ステップ1:必要なライブラリのインストール
pip install transformers
ステップ 2: 必要なライブラリのロード
インポートリクエスト
インポートトーチ
from PIL import Image
from transformers import AlignProcessor, AlignModel
ステップ 3: ALIGN モデルの読み込み
processor = AlignProcessor.from_pretrained("kakaobrain/align-base")
model = AlignModel.from_pretrained("kakaobrain/align-base")
ステップ4:画像と候補テキストラベルの準備
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
candidate_labels = ["猫の画像", "犬の画像"].
ステップ5:画像とテキストの前処理
inputs = processor(images=image ,text=candidate_labels, return_tensors="pt")
ステップ6:モデルへの入力
with torch.no_grad():
outputs = model(**inputs)
ステップ 7: 類似性スコアの抽出
# 画像とテキストの類似度スコア
logits_per_image = outputs.logits_per_image
ステップ8:確率への変換
# ラベル確率を得るためにソフトマックスを取ることができる
probs = logits_per_image.softmax(dim=1)
print(probs)
画像とテキストの類似度を計算した後、画像とテキストの特徴量embeddings(画像はEfficientNetから、テキストはBERTから)をMilvusやZilliz Cloud(Milvusが提供するマネージドサービス)のようなベクトルデータベースに保存し、大規模なデータセット間の効率的な類似度検索を行う必要があるかもしれません。Milvusは、ALIGNによって生成された潜在空間における類似性に基づいて画像やテキストを検索する、効率的なベクトルベースの検索を可能にします。Milvusの詳細については、そのドキュメントをご覧ください。
結論
ALIGNはクロスモーダルおよびマルチモーダルタスクのための堅牢で効率的なソリューションです。そのシンプルで効果的なデータ収集と学習アプローチにより、ALIGNは類似したセマンティクスを持つ画像とテキストを整列させ、視覚情報とテキスト情報を組み合わせた複雑なクエリを処理することを可能にします。この能力は、単一のモダリティ(画像またはテキスト)だけでは達成困難な、より高度な検索機能への扉を開きます。
しかしながら、ALIGNのアプローチは、将来の研究分野も浮き彫りにしています。
多様なノイジーデータの使用を探求する:**視覚・視覚言語モデルのトレーニングのために、画像・アルト・テキストのペアだけでなく、異なるタイプのノイジーデータの有効性を調査する。
将来的には、ノイズの多いデータからの学習に特化した、より高度なモデルアーキテクチャの設計に焦点を当てることで、より高い効率性と性能を実現できる可能性がある。
関連リソース
ALIGN: ソースコード](https://paperswithcode.com/paper/scaling-up-visual-and-vision-language)
コンピュータ・ビジョンとは](https://zilliz.com/learn/what-is-computer-vision)
ベクトル探索によるコンピュータビジョンデータの理解](https://zilliz.com/blog/use-vector-search-to-better-understand-computer-vision-data)
CLIP物体検出:AIビジョンと言語理解の融合](https://zilliz.com/learn/CLIP-object-detection-merge-AI-vision-with-language-understanding)
ベクトルデータベースとは何か、どのように機能するのか](https://zilliz.com/learn/what-is-vector-database)
RAGとは - Zillizブログ](https://zilliz.com/learn/Retrieval-Augmented-Generation)
ジェネレーティブAIリソースハブ|Zilliz](https://zilliz.com/learn/generative-ai)
あなたのGenAIアプリのためのトップパフォーマンスAIモデル|Zilliz](https://zilliz.com/ai-models)
MilvusでAIアプリを作る:チュートリアル&ノートブック](https://zilliz.com/learn/milvus-notebooks)
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS


