フローレンスマイクロソフトによるコンピュータビジョンの高度な基礎モデル
Florenceはマイクロソフトによって開発された大規模な視覚言語モデルで、マルチモーダル機能を必要とするアプリケーションに特に有効です。
シリーズ全体を読む
- 交差エントロピー損失:機械学習におけるその役割を解明する
- バッチとレイヤーの正規化 - ニューラルネットワークの効率性を引き出す
- ベクトル・データベースによるAIと機械学習の強化
- ラングチェーンツール先進のツールセットでAI開発に革命を起こす
- ベクターデータベース検索テクノロジーの未来を再定義する
- ローカル感度ハッシング (L.S.H.):包括的ガイド
- AIの最適化:安定した普及と効率的なキャッシュ戦略への手引き
- ネモ・ガードレールAIの安全性と信頼性を高める
- ベクトル・データベースに最適化されたデータ・モデリング技法
- カラーヒストグラムの謎を解く:画像処理と解析の手引き
- BGE-M3を探る:Milvusによる情報検索の未来
- BM25を使いこなす:Milvusにおけるアルゴリズムとその応用を深く掘り下げる
- TF-IDF - NLPにおける項頻度-逆文書頻度の理解
- ニューラルネットワークにおける正則化を理解する
- 初心者のためのヴィジョン・トランスフォーマー(ViT)理解ガイド
- DETRを理解する:トランスフォーマーによるエンドツーエンドのオブジェクト検出
- ベクトル・データベース vs グラフ・データベース
- コンピュータ・ビジョンとは?
- 画像認識のための深層残差学習
- トランスフォーマーモデルの解読:そのアーキテクチャと基本原理の研究
- 物体検出とは?総合ガイド
- マルチエージェントシステムの進化:初期のニューラルネットワークから現代の分散学習まで(アルゴリズム編)
- マルチエージェントシステムの進化:初期のニューラルネットワークから現代の分散学習まで(方法論編)
- CoCaを理解する:コントラスト・キャプションによる画像テキスト・ファウンデーション・モデルの進歩
- フローレンスマイクロソフトによるコンピュータビジョンの高度な基礎モデル
- トランスフォーマーの後継者候補マンバ
- ALIGNの説明ノイジー・テキスト教師による視覚・視覚言語表現学習のスケールアップ
人工知能の研究は、人間の適応性と同様に、複数のタスクに対応できるシステムを作る方向にシフトしている。この変化は、個々の問題に特化したモデルを設計することが、人間のようなAIを実現する最も効果的な方法ではないという事実に由来する。研究者たちは現在、人間の入力を最小限に抑えながら、現実世界のさまざまなタスクを解決できる包括的なシステムを開発している。このアプローチは、OpenAIのGPTシリーズのような基盤モデルの作成につながっている。大規模なデータセットで訓練されたこれらのモデルは、fine-tuningを通して様々なタスクに適応し、強力なパフォーマンスと汎化を示している。
このシフトは、特にコンピュータビジョンにおいて極めて重要であり、従来の手法では様々なタスクに適応するのに苦労している。コンピュータ・ビジョンは、異なるタスクに特化したモデルを使用するという従来のアプローチでは、非効率的で適応性が制限されるという課題に直面している。このような課題に対処するため、マイクロソフトの研究者はFlorence, a new foundation model for computer visionを開発した。Florenceは、画像の分類、物体検出、視覚的質問応答、ビデオ解析など、様々な視覚AIタスクに適応可能な単一のアーキテクチャを提供することを目的としている。このモデルは、タスクに特化した最小限のトレーニングで様々なアプリケーションに適応できる汎用視覚システムへの一歩である。
Florenceの初期結果は、コンピュータ・ビジョンを進歩させる可能性を示している。このモデルは様々なタスクで優れた性能を発揮し、しばしば特殊化されたモデルを凌駕します。これらの結果は、Florenceと同様の基礎モデルが、より効率的で有能な視覚AIシステムにつながる可能性を示唆している。Florenceの構造、トレーニング方法、能力、AIとコンピュータビジョンの未来への潜在的影響について探ってみよう。
コンピュータ・ビジョンの世界
コンピュータビジョンには、3つの主要な次元に沿って分類できる多様なタスクが含まれる:
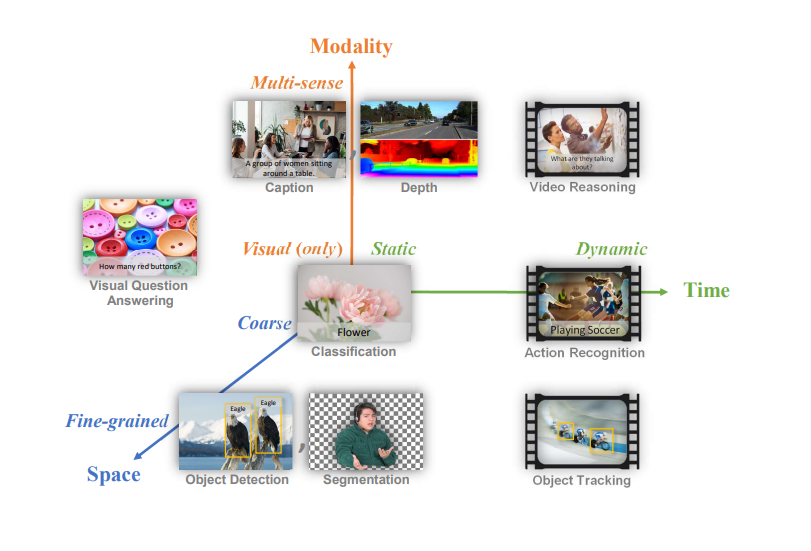 時空間モダリティ空間にマッピングされた一般的なコンピュータビジョンのタスク.png
時空間モダリティ空間にマッピングされた一般的なコンピュータビジョンのタスク.png
図1:時空間モダリティ空間にマッピングされた一般的なコンピュータビジョンタスク
Florenceは、空間、時間、モダリティという3つの重要な次元において、コンピュータビジョンの幅広い課題に取り組むことができます。
1.**空間この次元は、粗いシーンの理解から、細かいオブジェクトの検出やセグメンテーションまで幅広い。粗いレベルでは、画像の主な主題やテーマを特定することを目的とした画像分類のようなタスクがある。きめ細かい分析に向かうと、画像内の複数の物体を識別して位置を特定する物体検出や、物体の境界を正確に画定する必要があるセグメンテーションなどのタスクに遭遇する。
2.時間:コンピュータビジョンのタスクは静的な画像と動的なビデオコンテンツの両方を扱う。静的タスクには、画像分類、物体検出、視覚的質問応答が含まれる。動的タスクには、ビデオ内のアクション認識やオブジェクト追跡など、時間の経過に伴う画像シーケンスの分析が含まれる。
3.モダリティ:視覚情報のみに焦点を当てるタスクもあれば、その他のモダリティを組み込んだタスクもある。純粋な視覚タスクには、画像分類や物体検出が含まれる。マルチモーダルなタスクは、視覚データと他のタイプの情報、例えばテキスト(画像キャプションや視覚的な質問に対する回答)、深度情報、あるいは一部のビデオ解析タスクでは音声などを組み合わせます。
課題普遍的な視覚AIの創造
従来、このような多様なタスクには、それぞれが特定のタイプの問題用に設計され最適化された、特殊なモデルが必要だった。このアプローチは効果的ではあるが、いくつかの限界がある:
1.開発と展開における非効率性:開発・展開の非効率性**:タスクごとに個別のモデルを作成・維持することは、リソース集約的で時間がかかります。
2.**知識の伝達が難しい:1つのタスクに最適化されたモデルは、学習した知識を関連タスクに適用するのに苦労することが多い。
3.新奇な状況に対応する限られた能力:専門化されたモデルは、学習データと大きく異なるシナリオに直面したとき、パフォーマンスが低下する可能性がある。
Florenceは、これらの限界に対処することを目的としている。目標は、最小限の修正で様々な下流のタスクに適応可能な、汎用ビジョンシステムとして機能する基礎モデルを開発することです。この目標を達成するため、フローレンスのアーキテクチャは複数のコンポーネントを統合しており、それぞれが視覚理解の異なる側面に取り組むように設計されている。
フローレンスのアーキテクチャ複数のアプローチの統合
前述の通り、Florenceはマイクロソフトによって開発された大規模な視覚言語モデルである。複数のコンピュータ・ビジョンと言語処理タスクを単一のフレームワークで統合するように設計されている。これによってフローレンスは、画像認識、物体検出、そして視覚的な質問に対する回答や画像キャプションといった、より複雑な機能を含むさまざまなタスクを実行できるようになる。このモデルは、視覚と言語理解の組み合わせを活用して、テキストデータと視覚データを処理・解釈するため、マルチモーダルな機能を必要とするアプリケーションに特に効果的です。
それでは、Florenceのアーキテクチャーとその仕組みについて説明しよう。
Florenceの多用途性は、既存のいくつかのモデルタイプの要素を組み合わせた統一されたアーキテクチャに由来する。
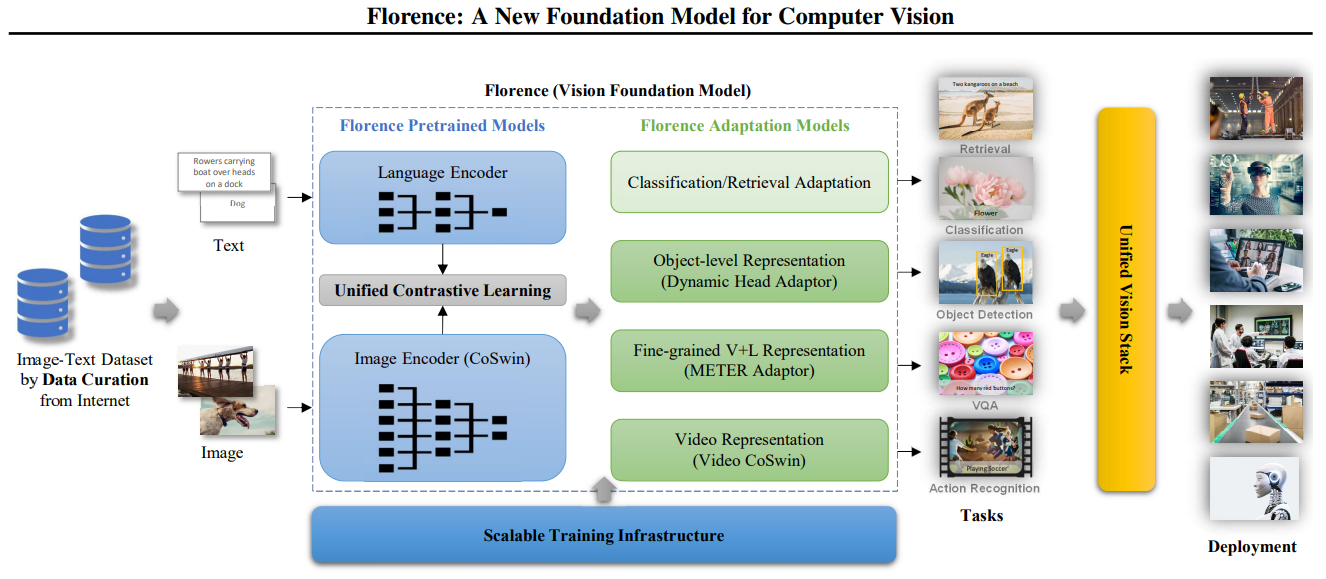 データキュレーションからデプロイまでのワークフローを示すフローレンス構築の概要.png
データキュレーションからデプロイまでのワークフローを示すフローレンス構築の概要.png
図2:フローレンス構築の概要、データキュレーションからデプロイメントまでのワークフローを示す_。
アーキテクチャには2つの主要コンポーネントがある:Florence事前学習モデルとFlorence適応モデル。
フローレンス事前学習モデル
Florenceの事前学習済みモデルはいくつかの主要なコンポーネントで構成され、それぞれが視覚データとテキストデータを効果的に処理し、整合するように設計されています。
1.**言語エンコーダーこのコンポーネントはテキスト入力を処理し、モデルが視覚コンテンツに関連する言語を理解し生成することを可能にする。これは、BERTやGPTのようなモデルに似ていますが、視覚情報と並行して動作するように特別に設計されています。
2.画像エンコーダー(CoSwin):CoSwinと呼ばれる階層的なVision Transformerに基づき、このエンコーダは視覚情報を処理し、生のピクセルデータを意味のある表現に変換します。自然言語処理におけるトランスフォーマ・アーキテクチャの成功に基づき、それらを画像処理に適応させている。
3.統合対照学習:このモジュールは、視覚的表現とテキスト表現を整列させ、モデルが画像とその説明の関係を理解できるようにする。どのテキストがどの画像に対応し、またその逆も同様であるかをモデルが学習するのを助ける。
フローレンス適応モデル:
これらのモデルは、事前に訓練されたモデルから表現を取り出し、特定のタスクに適応させる:
1.分類/検索適応:このコンポーネントにより、Florenceは画像の分類とクロスモーダル検索タスクを実行することができます。例えば、画像を事前に定義されたカテゴリに分類したり、与えられたテキスト記述にマッチする画像を検索したりすることができます。
2.オブジェクトレベル表現(Dynamic Head Adaptor)*:このアダプターは、きめ細かなオブジェクト検出とセグメンテーションタスクを可能にする。これにより、画像に何が写っているかを分類し、特定の物体の位置を特定して輪郭を描くことができる。
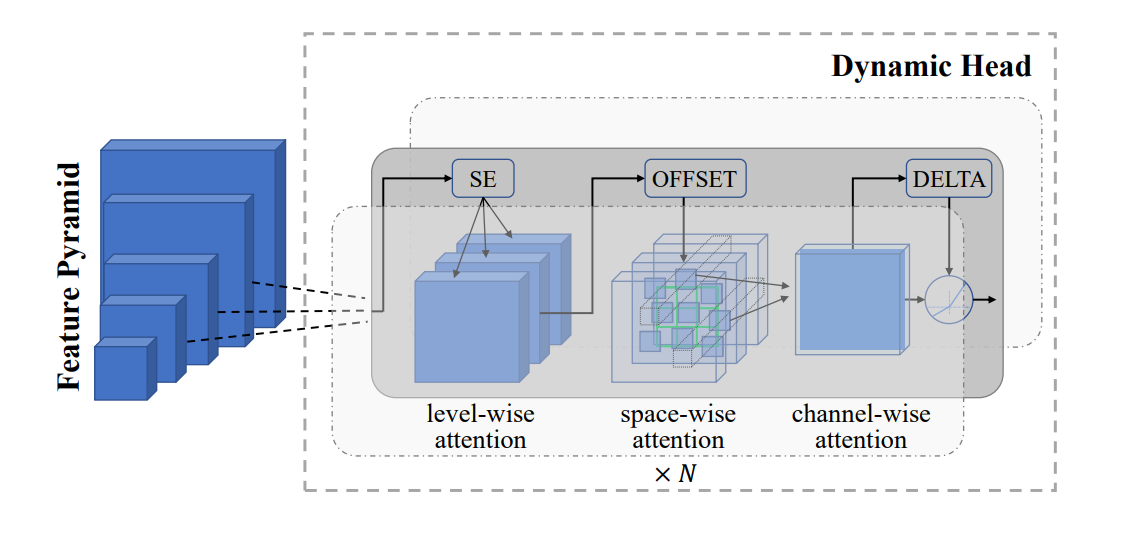 物体レベルの視覚表現学習に使われるダイナミックヘッドアダプター.png
物体レベルの視覚表現学習に使われるダイナミックヘッドアダプター.png
図3: オブジェクトレベルの視覚表現学習に使用されるダイナミックヘッドアダプター Figure 3: Dynamic Head adapter used for object-level visual representation learning
上の画像に示したダイナミック・ヘッド・アダプターは、一連の注意メカニズムを通して視覚情報を処理する:
入力は、異なるスケールの視覚情報を含む特徴ピラミッドである。例えば、人通りの多い街角の画像:
最も大きなブロックは、建物や道路の全体的な配置を表しているかもしれない。
中間のブロックは、個々の車や歩行者をとらえるかもしれない。
最小のブロックは、ナンバープレートや顔の特徴などの細かいディテールに焦点を当てることができる。
アダプターは3種類の注意を適用する:
レベルワイズアテンション(SE)**:これはピラミッドの異なるレベルにまたがる重要な特徴に焦点を当てる。この街路シーンでは、SEは、車両検出タスクでは車のレベルを、人物認識タスクでは顔の特徴レベルを強調するかもしれない。
空間的注意**:これは、3Dグリッドで表される各レベル内の関連する空間的位置に注意を向ける。例えば、歩行者を探す場合は歩道部分に注目し、車両を検出する場合は道路部分に注目する。
チャネル単位の注意**:これは重要な特徴チャンネルを強調します。あるチャンネルは形状の検出に、他のチャンネルは色情報に適しているかもしれません。
OFFSETとDELTA成分は空間予測を微調整します。これらは、街頭のシーンで車や人の輪郭を正確に示すなど、オブジェクトの境界を正確に特定するのに役立ちます。
この多段階の注意プロセスにより、モデルは、異なるスケールと空間的位置で最も関連性の高い情報に集中することで、物体を検出し分割することができる。例えば、バスのような大型の物体、車のような中型の物体、道路標識のような小型の物体を同時に検出することができる。
3.きめ細かいV+L表現(METER Adaptor)*:このモジュールは、視覚的質問応答や画像キャプション付けなどの視覚言語タスクをサポートする。これにより、視覚情報とテキスト情報の間の複雑な関係を理解することができる。
フローレンスV+L適応モデルとして使用されるMETERアダプター.png](https://assets.zilliz.com/METER_adapter_used_as_Florence_V_L_adaptation_model_c2b1959fd3.png)
図4:フローレンスV+L適応モデルとして使用されたMETERアダプター
上の図に示したMETERアダプターは、視覚情報と文字情報を融合させるためにコ・アテンション・メカニズムを使用している。その仕組みを見てみよう:
言語エンコーダー(RoBERTa)はテキスト入力を処理する。例えば、次のような質問を処理する:「消火栓の隣に停まっている車は何色ですか?
ビジュアル・エンコーダ(Florence-CoSwin)は視覚入力を処理する。これは、街頭シーンの画像を分析する。
両方の入力は別々の自己注意レイヤーを通り、それぞれのモダリティが独立して情報を処理できるようにする。テキスト自己アテンションは、色、車、消火栓のようなキーワードに焦点を当て、視覚自己アテンションは、車や消火栓を含む画像の領域を強調するかもしれない。
これらのセルフアテンションレイヤーの出力は、次にクロスアテンションレイヤーに送られる。ここで視覚情報とテキスト情報が組み合わされる:
テキストの特徴は、画像の関連する部分に注目する(Vl、Kl、Qlの矢印が下を向いている)。この例では、carとfire hydrantという単語を、画像内の視覚的表現に結びつける。
画像の特徴は、テキストの関連する部分(Vv, Kv, Qv矢印が上を向いている)に関連付けます。これには、車の視覚的特徴と問題文中の色の単語を関連付けることが含まれる。
最後に、両方のストリームはフィードフォワード層を通過し、この組み合わされた情報をさらに処理する。
このプロセスはMco回繰り返され、何度も改良を加えることができる。
このアーキテクチャーにより、モデルは、最初はテキストと画像を別々に処理し、徐々に情報を結合して、視覚とテキストのコンテンツ間の複雑な関係を理解できるようになる。この例では、消火栓の近くにある車から正しい車を特定し、その色を判断し、次のような答えを導き出す:消火栓の隣に停まっている車は青い。
4.ビデオ表現(Video CoSwin):このアダプターは、Florenceのビデオデータを扱う機能を拡張し、行動認識のようなタスクを可能にする。このアダプターは、画像処理機能をベースに、時間の経過に伴う画像のシーケンスを理解します。
この統一された構造により、Florenceは1つの基本モデルとタスクに特化したアダプターで、画像分類からビデオ認識まで、幅広いタスクを扱うことができます。
フローレンスの能力多才なビジュアルAI
フローレンスの適応力は、以下のタスクをこなす能力に表れている。
ゼロショット画像分類
Florenceは、12のデータセットにおいて、CLIPやFLIPのようなモデルをほとんどのケースで上回り、強力なゼロショット分類を示しています。また、ImageNetのような大規模なデータセットでも83.7%の精度を達成しています。この性能は、Florenceが言語と視覚的特徴の理解を用いて、未知のカテゴリを認識するために汎化できることを示している。
線形プローブ分類
フローズン特徴量の上に線形分類器を使用した場合、FlorenceはほとんどのデータセットでSimCLRv2、ViT、EfficientNetのようなモデルを上回ります。多様できめ細かい分類タスクにおけるこの汎用性は、Florenceの学習された表現が豊かで、新しいタスクに適応可能であることを示唆している。
物体検出
Florenceの物体検出性能は複数のデータセットで評価され、COCOで62.4mAP、Object365で39.3mAP、Visual Genomeで16.2AP50を記録した。これらの結果は、複雑なシーンの中で複数の物体を分類し、位置を特定し、識別する能力を強調しています。
ビジュアル質問応答(VQA)
FlorenceはVQA v2データセットで80.36%の精度を達成し、画像コンテンツと質問を組み合わせる能力を示しました。これは、視覚情報とテキスト情報を統合する能力を反映している。
画像-テキスト検索
Flickr30Kデータセットでは、画像対テキストで97.2%、テキスト対画像で87.9%のR@1、MSCOCOデータセットでは、画像対テキストで81.8%、テキスト対画像で63.2%のR@1を示しています。視覚表現とテキスト表現を整合させるこの能力は、強固なクロスモーダル検索能力をサポートする。
ビデオアクション認識
Florenceは静止画像で学習したにもかかわらず、動画タスクによく適応し、Kinetics-400で86.5%、Kinetics-600で87.8%のトップ1精度を達成しました。この性能は、Florenceが動画データに関する特別な訓練なしに、動画中の時間情報を捕捉し、動きやシーケンスを扱いながらアクションを認識できることを示している。
より詳しい評価と実験結果については、Florenceの論文をご覧ください。
Florence とベクトルデータベースはどのようにマルチモーダル検索を強化するか?
Florenceの能力、特に画像-テキスト検索とゼロショット分類は、ベクトルデータベースの強みとよく一致している。この2つを組み合わせることで、その可能性を最大限に引き出し、ロバストなマルチメディア検索・分析システムを構築することができる。
ベクターデータベースを理解する
ベクトルデータベースは、高次元ベクトルを格納、索引付け、照会するために設計された特殊なシステムであり、画像、テキスト、音声などの複雑なデータを表現する。これらのベクトルは、Florenceのようなモデルによって生成されることが多く、膨大なデータセットを類似性に基づいて効率的に検索することができる。この機能により、ベクトルデータベースは、意味的または内容的な類似性に基づく高速で正確なデータマッチングを必要とするアプリケーションで重要な役割を果たします。
Milvus: スケールのために構築されたオープンソースのベクトルデータベース
Milvusは、本稿執筆時点でGitHub上で30,000以上のスターを持つ最も人気のあるオープンソースのベクトルデータベースであり、AIを活用したアプリケーションに特に適している。Florenceのようなモデルが生成する大規模で複雑なデータセットを管理するために、スケーラビリティ、パフォーマンス、柔軟なインデックスを兼ね備えている。以下のような幅広い機能を提供している:
ハイブリッド検索とマルチモーダル検索**](https://zilliz.com/blog/a-review-of-hybrid-search-in-milvus):Milvusは、ハイブリッドスパース検索と密検索をサポートし、ベクトル類似性検索とスカラーフィルタを組み合わせ、マルチモーダル検索を可能にします。
スケーラビリティ**](https://zilliz.com/learn/scaling-vector-databases-to-meet-enterprise-demands):Milvusは数十億のベクトルを管理することができ、Florenceの膨大なデータセットを処理する能力に対応しています。
多様なインデックスタイプ**](https://zilliz.com/learn/vector-index):Milvusには15種類のインデックスタイプがあり、様々なアプリケーションのニーズに合わせて、クエリのスピード、精度、メモリを最適化する柔軟性を提供します。
GPUアクセラレーション**](https://zilliz.com/blog/milvus-on-gpu-with-nvidia-rapids-cuvs):Milvusはインデックス作成と検索にGPUアクセラレーションを活用しており、FlorenceのGPUベースの推論とうまく連携し、エンドツーエンドのシステム効率を最大化します。
リアルタイム更新Milvusはリアルタイムのデータ挿入と更新をサポートしており、Florenceベースのシステムは大きな混乱なしに新しいデータをシームレスに取り込むことができます。
このFlorenceとMilvusの組み合わせは多くの応用が可能です。そのいくつかは以下の通りです:
マルチモーダルRAG**](https://zilliz.com/blog/multimodal-rag-expanding-beyond-text-for-smarter-ai):従来のRAGシステムは、LLMの生成プロセスを強化し、より正確でパーソナライズされた応答を生成するために、関連するテキストを検索することに焦点を当てている。マルチモーダルRAGは、FlorenceやMilvusのようなマルチモーダルAIモデルを使用して、埋め込み、検索、生成プロセスに画像、音声、ビデオなどの追加データタイプを統合することにより、テキストを超えて拡張します。
大規模ビジュアル検索エンジン**:ユーザーは、詳細なテキスト説明に基づいて画像を検索したり、画像をアップロードして膨大なデータセットから類似画像を検索したりできる。
コンテンツ推薦システム**:様々なコンテンツアイテム(画像、動画、記事)のフローレンス埋め込みを保存することで、Milvusはユーザーの嗜好や行動に基づいてパーソナライズされた推薦を行うことができる。
自動タグ付けと分類**:フローレンスのゼロショット機能は、Milvusの高速検索と組み合わされ、データベース内の類似した、既にタグ付けされたアイテムを見つけることにより、新しい画像の自動タグ付けを可能にする。
スケール**での視覚的な質問応答:Milvusに画像-質問-答えのトリプレットの埋め込みを保存することで、画像に関する新しい質問に対する関連情報の迅速な検索を可能にする。
FlorenceとMilvusのようなベクトルデータベースは共に、スケーラブルなマルチモーダルAIシステムの強力な基盤を提供する。両技術の継続的な進歩により、Florenceの視覚的理解とMilvusの高性能検索機能を活用したアプリケーションの幅が広がることが期待される。
結論
Florenceは、コンピュータビジョンにおける注目すべき進歩であり、複数の手法を1つの堅牢で適応性の高いモデルに統合した。Milvusのようなベクトルデータベースと統合することで、FlorenceはマルチモーダルRAGから大規模視覚検索やパーソナライズされた推薦システムまで、様々なアプリケーションを可能にする。
この技術が進化するにつれ、人間とコンピュータのインタラクションを強化し、AI主導のアシスタントを合理化する、より高度なビジュアルAIシステムの登場が期待される。また、このような開発は、様々な産業におけるより良い自動化につながり、創造性とコンテンツ制作のための新しいツールを導入するかもしれない。
参考資料
 Denis Kuria
Denis KuriaDenis is a machine learning engineer who enjoys writing guides to help other developers. He has a bachelor's in computer science and loves hiking and exploring the world.