




トランスフォーマーモデルの解読:そのアーキテクチャと基本原理の研究
Transformerモデルとは、シーケンスを処理するためのアーキテクチャの一種で、主に自然言語処理(NLP)で使用される。
シリーズ全体を読む
- Cross-Entropy Loss: Unraveling its Role in Machine Learning
- Batch vs. Layer Normalization - Unlocking Efficiency in Neural Networks
- Empowering AI and Machine Learning with Vector Databases
- Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
- Vector Databases: Redefining the Future of Search Technology
- Local Sensitivity Hashing (L.S.H.): A Comprehensive Guide
- Optimizing AI: A Guide to Stable Diffusion and Efficient Caching Strategies
- Nemo Guardrails: Elevating AI Safety and Reliability
- Data Modeling Techniques Optimized for Vector Databases
- Demystifying Color Histograms: A Guide to Image Processing and Analysis
- Exploring BGE-M3: The Future of Information Retrieval with Milvus
- Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
- TF-IDF - Understanding Term Frequency-Inverse Document Frequency in NLP
- Understanding Regularization in Neural Networks
- A Beginner's Guide to Understanding Vision Transformers (ViT)
- Understanding DETR: End-to-end Object Detection with Transformers
- Vector Database vs Graph Database
- What is Computer Vision?
- Deep Residual Learning for Image Recognition
- Decoding Transformer Models: A Study of Their Architecture and Underlying Principles
- What is Object Detection? A Comprehensive Guide
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Algorithmic)
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Methodological)
- Understanding CoCa: Advancing Image-Text Foundation Models with Contrastive Captioners
- Florence: An Advanced Foundation Model for Computer Vision by Microsoft
- The Potential Transformer Replacement: Mamba
- ALIGN Explained: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
トランスフォーマーモデルの導入は、自然言語処理(NLP)の進化を示すものであった。もともと機械翻訳のようなタスクのために概念化されたトランスフォーマーは、それ以来、さまざまな形に適応されてきた。これには、オリジナルのエンコーダー・デコーダー構造、エンコーダーのみ、デコーダーのみのバリエーションなどがあり、自然言語処理の課題のさまざまな側面に対応している。
このブログでは、Transformerモデルについて、そのオリジナルのエンコーダー・デコーダーの構成から説明し、そのメカニズムと能力の基礎的な理解を提供します。このモデルの複雑な設計と運用のダイナミクスを探ることで、Transformerが現代のNLPの進歩の礎石となった理由を明らかにすることを目指します。
トランスフォーマーの概要
Transformerモデルはその登場以来、自然言語処理(NLP)を大きく変えてきた。トランスフォーマーには3つの種類がある:エンコーダー・デコーダー、エンコーダー・オンリー、デコーダー・オンリーである。** オリジナルのモデルはエンコーダー・デコーダー型で、その基礎となる設計を包括的に見ることができる。
自己アテンション・メカニズムは、主に言語を翻訳するために開発されたTransformerアーキテクチャの中核をなすものである。その仕組みはこうだ:文はトークンと呼ばれる断片に分解される。これらのトークンはエンコーダーの複数のレイヤーを通して処理される。各レイヤーは他のトークンから情報を引き出すことによってトークンを洗練し、自己注意**によってより大きな文脈でトークンを豊かにします。このプロセスにより、より深く、より意味のあるトークン表現またはエンベッディングが得られます。
エンベッディングが強化されると、これらのエンベッディングはデコーダーに渡される。デコーダはエンコーダと同様の構造を持ち、自己注意と交差注意として知られる追加機能の両方を利用する。クロスアテンションにより、デコーダはエンコーダの出力から関連情報にアクセスし、それを取り込むことができる。
実際には、単語を翻訳するには、原文から関連する詳細情報、特にターゲット単語と密接に関連するトークンをピンポイントで特定する必要がある。その後、デコーダは、文の終わりを示す特別なトークンに到達するまで、構築文の文脈をガイドとして使用しながら、ターゲット言語の単語を一度に1つずつ生成する。このアテンション・ドリブン・アプローチにより、正確なだけでなく、文脈のニュアンスも考慮した翻訳が可能になる。
変換モデルのアーキテクチャ
下の図はTransformerモデルのアーキテクチャを表しています。
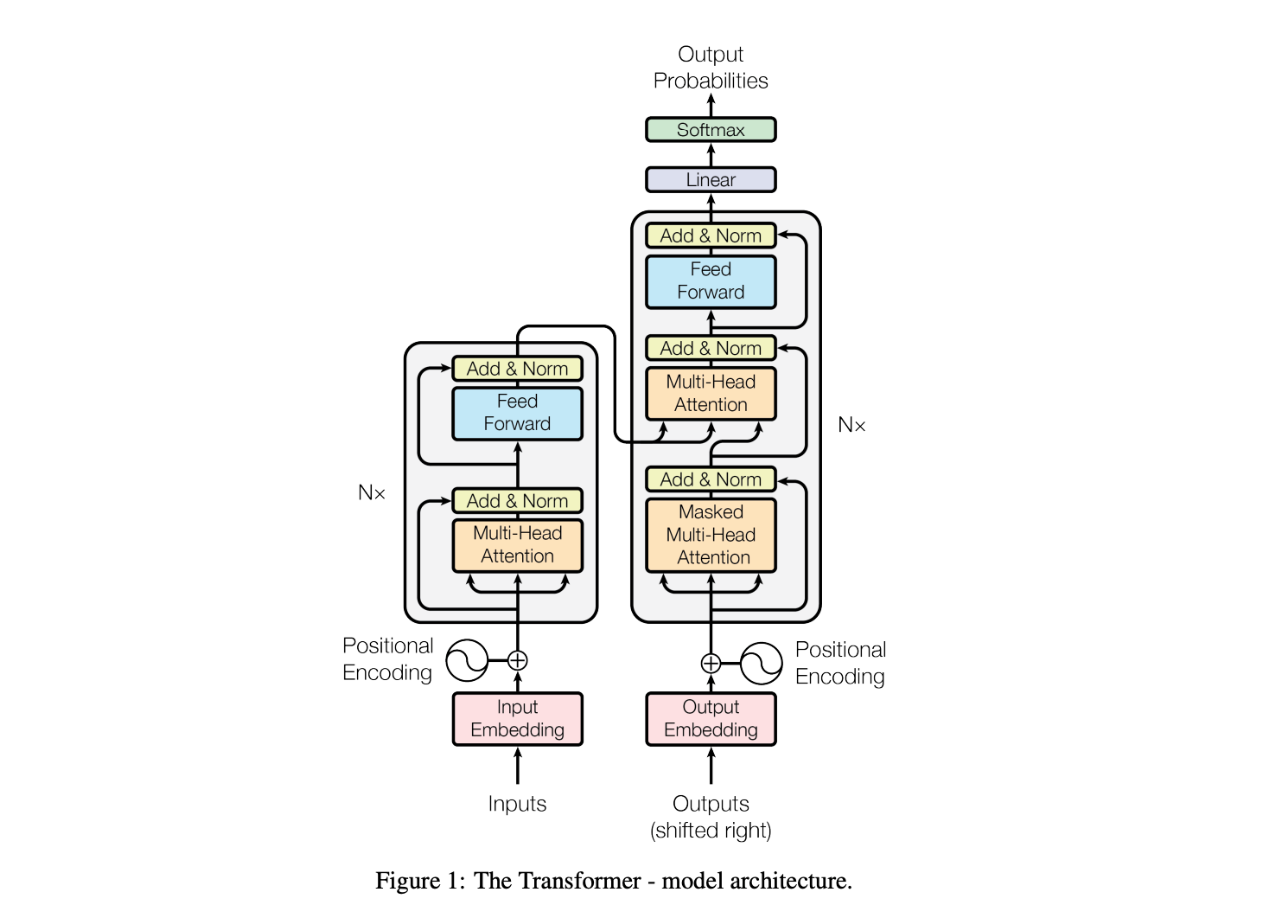 トランスフォーマーモデルのアーキテクチャ.png
トランスフォーマーモデルのアーキテクチャ.png
左下の入力はソーステキストを表し、埋め込み層を通して入力埋め込みに変換される。この埋め込み層は、各トークンに対応するベクトルを検索する辞書である。トークンの埋め込みを得た後、位置エンコーディングが追加される。この位置エンコーディングは、モデルがトークンの相対的な位置を理解するのに役立つ。この位置エンコーディングは、モデルがトークンの相対的な位置を理解するのを助ける。
次に、トークンの埋め込みと位置エンコーディングは、多頭注意モジュールに入る。このモジュールにより、モデルは入力シーケンスの異なる部分に同時に注意を向けることができる。注意メカニズムに続いて、残差接続とAdd & Norm層が適用される。残差接続とレイヤーの正規化を含むこれらの構造は、勾配の消滅を防ぎ、モデルがより効率的に収束するのを助けることによって、より深いネットワークの学習を可能にする経験的なテクニックです。これらの構造はモデルの他の部分にも一貫して現れることに気づくだろう。
Multi-Head Attentionの出力は、次にFeed-Forwardモジュールを通過します。このフィード・フォワード・ネットワークは、同じ変換と非線形性を各埋め込みに独立に適用し、埋め込みをより代表的で手元のタスクに適したものにします。エンコーダスタックの左にある "N×"の記号は、これが多層アーキテクチャであることを示しています。
画像の右側はデコーダーで、エンコーダーと同様のアーキテクチャを共有している。しかし、重要な違いがある。デコーダーにはマスクド・マルチヘッド・アテンション層があり、各埋め込みが以前の位置にしかアテンションできないようにして、将来のトークンからの情報が現在の位置に漏れるのを防いでいる。さらに、デコーダはクロス・アテンションを利用し、エンコーダの出力(エンコーダの出力からフローを見ることができる)エンベッディングにアテンションして、ソース言語の文脈とターゲット言語の生成を一致させます。
最後に、デコーダスタックを通過した後、出力エンベッディングはsoftmaxレイヤーを通して確率に変換され、ターゲットシーケンス内の次の単語を予測する。このプロセスは、通常文末を示す特別なトークンが生成されるまで繰り返される。
エンコーダーのコアコンセプトを理解する
エンコーダーにはいくつかのモジュールがあります。
スケールド・ドット・プロダクト・アテンション
マルチヘッドアテンション(MHA)の核となるのは、スケールドドットプロダクトアテンション(Scaled Dot-Product Attention)メカニズムである。MHAをよりよく理解するために、まずこの概念を説明しよう。
直感的には、注意とは、各埋め込みが文脈情報を収集するために、関連する埋め込みに注意する必要があることを意味します。アテンション計算には3つの役割がある:クエリー(Q)、キー(K)、バリュー(V)です。N個のクエリ埋め込みとM個のキーと値のペアがあるとします。アテンション・メカニズムの展開はこうだ:
関連性の計算:** メカニズムは、各クエリ埋め込みとM個のキー埋め込みとの関連性を計算します。これは多くの場合、クエリと各キーの間のドット積を使用して行われます。
正規化](https://zilliz.com/learn/layer-vs-batch-normalization-unlocking-efficiency-in-neural-networks):** これらの計算結果は正規化される。このステップにより、全ての関連性スコアの合計が1になることが保証され、各スコアがクエリとキーの関連性の度合いを反映する比例表現が容易になります。
文脈化:最後に、各クエリの埋め込みは文脈化された新しい形に組み直される。これは、正規化された関連性スコアで重み付けされた、各キーに対応する値の埋め込みを組み合わせることで実現される。
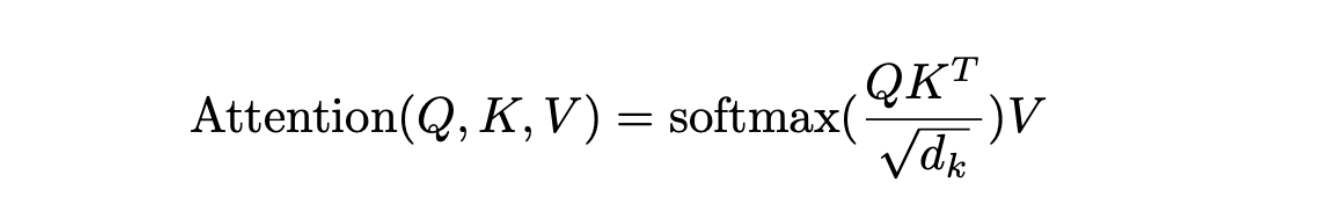 Scaled Dot-Product Attention formula.png
Scaled Dot-Product Attention formula.png
この式がScaled Dot-Product Attentionの定義である:同様に、KとVはそれぞれM個のkey embeddingsとvalue embeddingsを表す行列である。行列の乗算を用いると行列が得られ、各行はM個のキー埋め込みすべてに対するクエリ埋め込みの関連性に対応する。次にソフトマックス演算を適用して行を正規化し、各クエリの関連度スコアの和が1になるようにする。次に、この正規化されたスコア行列とV行列を掛け合わせ、コンテキスト化された表現を得る。
さらに、注目スコアはでスケーリングされることに注意することが重要である。原著者は、高次元は大きなドット積スコアをもたらし、これはソフトマックス関数が一つのキーに高いアテンションを不均衡に割り当てる原因になると説明している。この問題を軽減するために、ドット積をでスケーリン グすることで、よりバランスの取れた注目度重みとなる。
マルチヘッド注目
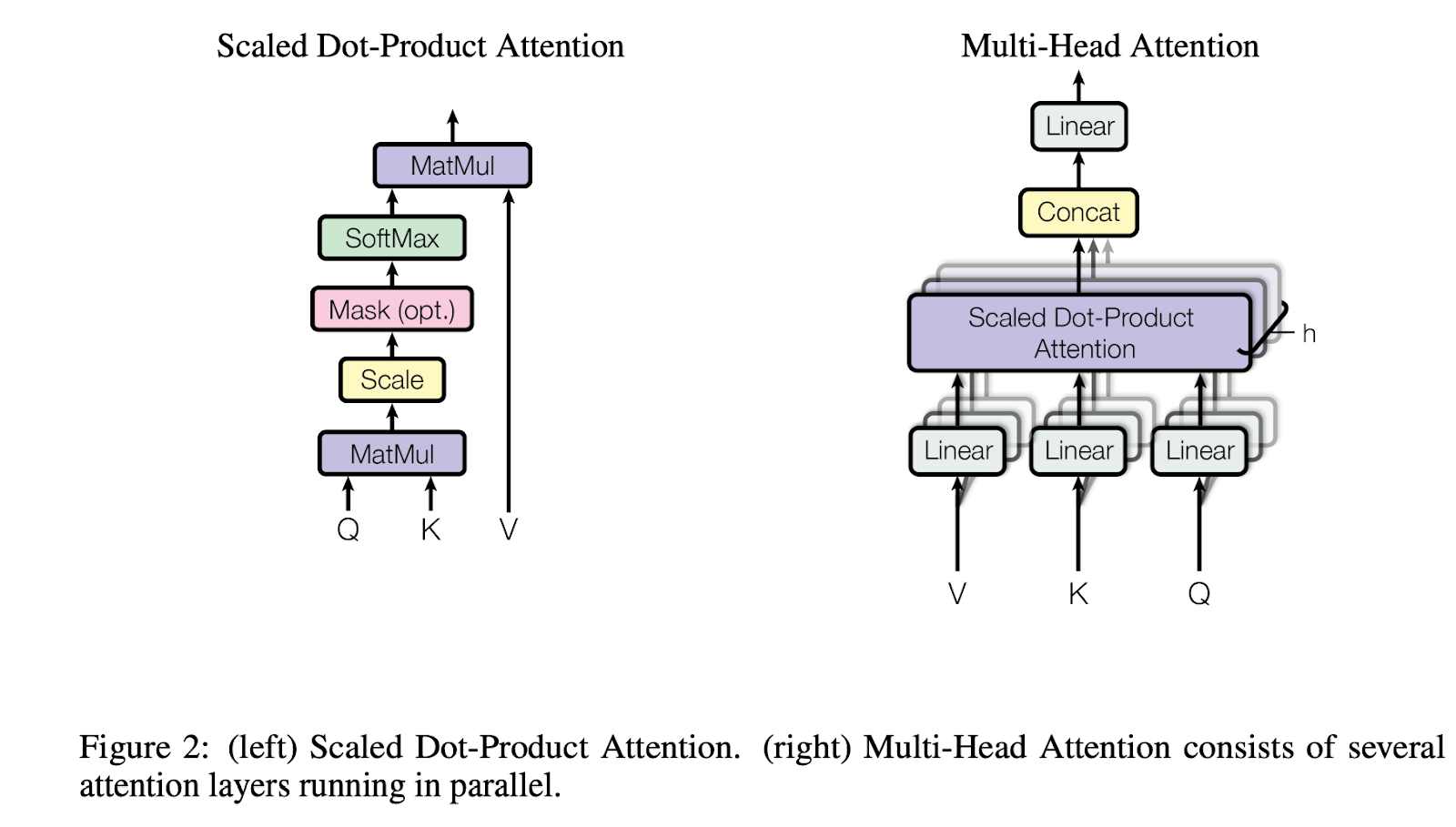 マルチヘッドアテンション.png
マルチヘッドアテンション.png
Transformerモデルは、その処理能力を高めるために、マルチヘッドアテンションとして知られるテクニックを採用している。このメカニズムでは、まずアテンションの構成要素であるクエリ(Q)、キー(K)、バリュー(V)を線形レイヤーを通して変換する。この変換によって追加のパラメータが導入され、より多くのデータから学習するモデルの能力が強化され、結果として全体的なパフォーマンスが向上する。
マルチヘッドアテンションメカニズムの中で、これらの変換されたQ、K、V要素は、スケールドドットプロダクトアテンションプロセスを受けます。オリジナルの設計では、これらのリニア層とアテンション層の複数(通常は8つ)の並列インスタンスが指定されている。この並列処理により、計算が高速化されるだけでなく、より多くのパラメータが導入され、エンベッディングがさらに洗練される。
各並列インスタンスは、"head "と呼ばれる各クエリから一意の変換された埋め込みを生成する。このようなヘッドが8つあり、各ヘッドがの次元を持つと仮定すると、全てのヘッドからの出力を合わせた総次元は8xとなります。これらの結果をモデルの主要なワークフローに戻すために、別の線形レイヤーは、投影行列を用いてこの連結出力を投影し、モデルの指定された次元にリサイズする。この構造化されたアプローチにより、Transformerは複数の視点を同時に活用することができ、複雑なデータパターンを識別し解釈する能力が大幅に向上する。
 多頭注目式.png
多頭注目式.png
Transformerのマルチヘッドアテンション機構では、、、(iは8つのインスタンスのうちの1つを表す)のレイヤーは、アテンション計算のためにクエリー(Q)、キー(K)、バリュー(V)を変換するための3つの線形レイヤーである。これらの層は埋め込みをそれぞれ, , の次元に投影する。
注意メカニズムの核となる考え方は、周囲の単語からの文脈情報を統合することで、各単語の埋め込みを強化することである。例えば、"Apple company designed a great smartphone. "という英文をフランス語に翻訳する場合、"Apple "という単語は、"company "のような隣接する単語から文脈を吸収する必要がある。これによって、モデルは "Apple "を果物としてではなく、ビジネスの実体として理解し、"pomme "を文字通りの果物の意味ではなく、ビジネスの文脈で翻訳するようになる。このプロセスは自己注意として知られている。
一方、トランスフォーマーのデコーダー部では、クロスアテンションと呼ばれる技術が使われている。これは、デコーダーがエンコーダーの出力からさまざまな情報に注意を向けることで、原文から多様で関連性のあるデータを翻訳出力に統合することを可能にする。このようにアテンションタイプを区別することで、Transformerモデルは適切な文脈に焦点を当てることで、さまざまな翻訳のニュアンスを効果的に処理することができる。
位置エンコーディング
Transformerモデルの注意メカニズムに慣れれば、位置エンコーディングをより直感的に理解できるようになります。多頭注意(MHA)の重要な課題は、文中の単語の順序を本質的に考慮しないことである。
簡単な文章を考えてみよう:「ティムはシェリーに本をあげる。MHAでは、"Sherry "に対するクエリ(Q)埋め込みは、文中の位置を意識することなく、対応するキー(K)およびバリュー(V)埋め込みと相互作用する。しかし、単語が出現する順序は、その意味を把握するために重要である。
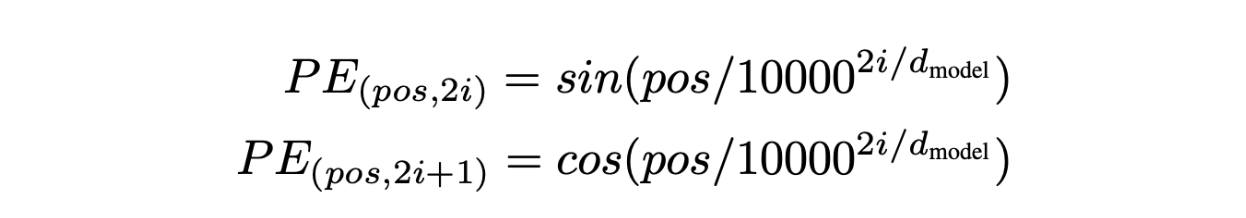 位置エンコーディング式.png
位置エンコーディング式.png
これに対処するために、注目度計算を位置情報を含むように修正する。例えば、ドット積計算のに位置を反映させ、とする。この調整により、文中の単語の配置をモデルが認識し、利用できるようになる。
位置エンコーディングは、各トークンの埋め込みに特別な埋め込みを追加することで実装される。この位置エンコーディングは同じ次元を持ち、文中の各位置にユニークなエンコーディングを割り当てる。コサイン関数とサイン関数は、それぞれ奇数インデックスと偶数インデックスに対してこれらのエンコーディングを生成する。この方法により、位置情報がベース埋め込みにシームレスに統合され、単語の順序に基づいてテキストを解釈・生成するモデルの能力が向上する。
フィードフォワードネットワーク
マルチヘッドアテンション(MHA)ステージでは、エンベッディングが相互作用によって洗練され、文脈に応じた表現が形成される。
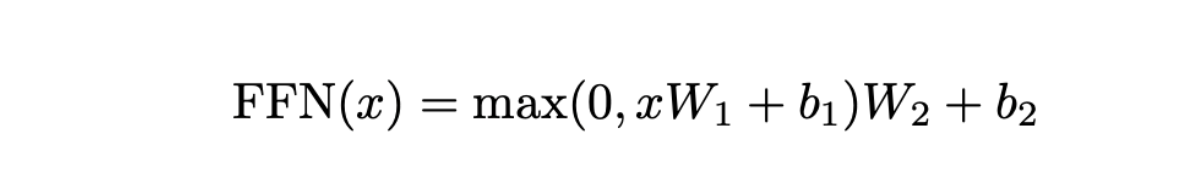 フィードフォワードネットワーク式.png
フィードフォワードネットワーク式.png
FFNは、通常512に設定される次元の埋め込みである、と表記される入力から始まります。FFNの最初の構成要素は、パラメータとで特徴づけられる線形層である。この層は埋め込みを512次元から2048次元の大きな空間に拡張する。この拡張に続いて、として定義されるReLU活性化関数が適用される。ReLUは非線形性を導入するための一般的な選択であり、データ中の複雑なパターンと相互作用を捉えるモデルの能力を強化するために重要である。
次に、パラメータとを持つもう一つの線形層が、埋め込みを元の512次元まで投影する。この非線形性を挿入した2段階のプロセスは不可欠である。これがないと、全体の操作が線形になり、前のMHA層に折りたたまれてしまう可能性があり、モデリングの柔軟性が損なわれてしまいます。
このフィードフォワードレイヤーを通過した後、エンベッディングは、高度な能力を持つ、文脈化されたバージョンに変換される。複数の(通常は6つの)Transformer層が積み重ねられ、各層がこのように埋め込みを強化すると、その結果、元のトークンの埋め込みを深く、豊かに抽象化した表現が得られます。これらのエンベッディングは、ニュアンスに富んだ包括的な言語情報を備え、ターゲット言語にデコードされます。
デコーダー
Transformerモデルのデコーダーもいくつかのレイヤーから構成され、主にマスクされたマルチヘッドアテンション(MHA)メカニズムを含むことでエンコーダーと区別される。エンコーダとは異なり、デコーダのこのMHAブロックは、エンコーダの出力と相互作用するクロスアテンションモジュールと対になっており、入力シーケンスをターゲット言語に翻訳するために重要である。
デコード処理は、ターゲット・シーケンスの翻訳開始を示す特別なトークン
デコーダーの最初のタスクは、
最初のトークン "L'entreprise "から、デコーダは後続のトークンを予測し続ける。例えば、"L'entreprise "の次に最も高い確率で予測されるトークンは "Apple "である。このステップ・バイ・ステップのトークン生成は、デコーダが翻訳完了を示す
デコーダはまた、次のトークンの確率を計算する最後のレイヤーを組み込み、シーケンスの各ステップで最も可能性の高い継続を効果的に決定する。このレイヤーは、出力が文法的に正しいだけでなく、エンコーダーによって提供された入力に基づいて文脈的にも適切であることを保証するために重要である。
マスクされた多頭注意
デコーディングとエンコーディングの最大の違いは、各埋め込みの文脈情報をどのように収集するかである。エンコードでは、各埋め込みは他のすべての埋め込みにアクセスできる(つまり、シーケンス全体から文脈情報を収集する)。しかしデコーディングでは、モデルは直前のテキストからしか情報を集めることができず、まだ生成されていない未来の情報を見ることはできない。これは言語モデルにおける因果性と呼ばれる。
| -------- | ---------------- | --------- | ------- | --------- | ------- | ------------- |
| L'entreprise(企業)|L'entreprise(企業)|L'entreprise(企業)|L'entreprise(企業)|L'entreprise(企業)
| | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | ?
| | | | | | | | | | | | | | | | エクセレント エクセレント エクセレント エクセレント エクセレント **エクセレント
....
マスクされたMHAプロセスでは、ハイライトされたトークンがクエリの埋め込みで、同じ行のトークンはその注目範囲を表す。"L'entreprise "は "Apple "からの情報を使ってはならない。そうでないと、デコード処理に矛盾が生じる。こうすることで、生成されたトークンが、受け取った情報に基づいて最も高い確率を持つことが保証される。さもなければ、生成されたトークンが後に中間トークンとなり、それ以降に生成されたトークンから情報を受け取ることができるようになった場合、最初に生成され、先行トークンからしか情報を受け取ることができなかったときとは異なる選択をすることになるかもしれない。これは復号プロセスにおいて混乱を引き起こす可能性がある。実用的な方法は、トークンごとにマスクを適用することである。例えば、マルチヘッドアテンションメカニズムにおいて、シーケンス"
クロスアテンション・マルチヘッドアテンション
デコーダが英語文の情報を首尾一貫したフランス語訳に正確に変換するために、クロスアテンション・マルチヘッ ドアテンションを使用します。これがないと、デコーダは元の英語の文脈を直接参照することなく、バラバラのフランス語のフレーズを生成することになります。クロスアテンション・マルチヘッドアテンションは、エンコーダーの出力、つまりエンコードされた英文の埋め込み情報をデコードプロセスに統合することで、この問題に対処する。
このセットアップでは、シーケンス内の各フランス語トークンが以前に生成されたフランス語トークンから文脈を構築する自己注意と同様に、クロスアテンションにより、これらのトークンはエンコードされた英語トークンの全範囲にもアクセスすることができます。ここでは、自己アテンションとは異なり、アテンション・メカニズムにおけるキーと値は、最終的にエンコードされた英語の埋め込みから導出され、英文全体が利用可能で関連性があるため、マスキングの必要はない。
このアーキテクチャにより、生成される各フランス語トークンは、対応する英語文の豊富な文脈から情報を得ていることが保証され、意味的整合性と論理的一貫性を維持した翻訳が可能になる。
さらに、このアプローチは、生成AIにおけるより広範な原則を示している。すなわち、指示、マスク、ラベルのような特定の条件を潜在埋め込みに埋め込み、これらを生成モデルのワークフローに統合するクロスアテンションを採用することである。この方法は、あらかじめ定義された条件に基づいてデータ生成プロセスを制御し、誘導する方法を提供する。異なるタイプのデータを埋め込みとして表現することができるため、クロスアテンションは、様々なデータタイプにまたがる情報を橋渡しし、合成するための効果的なツールであり、文脈に関連した制御された出力を生成するモデルの能力を向上させる。
最終予測ヘッド
Nxデコーダの処理の後、エンベッディングをデコードしてフランス語トークンに戻す必要がある。最終予測ヘッドは、デコーダによって生成されたシーケンスの最後のエンベッディングを受け取り、それをフランス語語彙上の確率分布に変換する。これは線形層とソフトマックス関数を用いて行われる。線形レイヤーは次に来る可能性のある各トークンをスコア化し、ソフトマックスはこれらのスコアを確率に変換し、モデルがシーケンス内で最も可能性の高い次の単語を予測できるようにする。
変換モデルを使った推論例
ここまでTransformerに関係するモジュールについて説明してきた。Transformerモデルがどのように機能するかを説明するために、"Apple company designed a great smartphone. "という英文をフランス語に翻訳するプロセスをデータフローの観点から見てみましょう:
1.トークン化と埋め込み:*。
文は単語やフレーズといった個別の要素にトークン化され、事前に定義された語彙からインデックスが作成される。
各トークンは埋め込みレイヤーを使ってベクトルに変換され、単語をモデルが処理できる形に変換する。
2.位置エンコーディング:。
- 位置エンコーディングは各トークンに対して生成され、文中の各単語の位置に関する情報をモデルに提供する。これらのエンコーディングはトークンの埋め込みに追加され、注意メカニズムが単語の順序を使用できるようにする。
3.エンコーダ処理:
複数の並列線形変換が入力をクエリー、キー、値のセットに変換する。これらはシーケンス全体で相互作用し、文全体からの情報で各トークンを豊かにします。
この相互作用の出力は次にフィードフォワードネットワーク(FFN)を通して処理され、非線形性と追加パラメータが導入され、埋め込みデータの表現能力がさらに強化される。
**4.レイヤースタッキング
- あるエンコーダ層からの出力は次のエンコーダ層に送られ、エンベッディングの文脈的な豊かさを段階的に向上させる。いくつかの層の後、エンコーダは、それぞれが入力文のトークンに対応する、非常に情報量の多い埋め込みセットを出力する。
5.デコーダの初期化:*。
翻訳は、デコーダが"
"トークンを受け取ることから始まる。このトークンは位置情報も埋め込まれ、エンコードされる。 デコーダはこの初期入力を、マスクされたMHAから始まるレイヤーを通して処理する。この初期段階では、"
"が唯一のトークンであるため、基本的にそれ自体に専念する。
6.逐次デコーディング:*。
- より多くのトークンが生成されるにつれて(たとえば "L'entreprise Apple a")、デコーダ内の各新しいトークンは、言語の論理的な順序を保持するために、以前に生成されたトークンにのみアテンションすることができます。
7.デコーダにおけるクロス・アテンション:。
- クロス・アテンションMHAレイヤーは、デコーダーの各新トークンがエンコーダーのすべての埋め込みにもアテンションすることを可能にする。このステップは、デコーダが元の英文の完全な文脈にアクセスすることを可能にし、翻訳が意味的にも構文的にも整合していることを保証するため、非常に重要である。
8.予測とトークン生成:*。
最後のデコーダー層は次のトークンの確率を出力する。この場合、最も確率の高いトークン "L'entreprise "が選択され、デコードされたシーケンスに追加される。
このプロセスは、直前のフランス語トークンと完全な英語入力に基づいて新しいトークンが生成され、「
」トークンが生成されるまで繰り返される。
この詳細なウォークスルーでは、Transformerがどのように自己注意や相互注意のような複雑なメカニズムを統合し、段階を追って効果的に言語を処理し、翻訳するかが示されている。
結論
Transformerの論文は、ディープラーニング研究におけるマイルストーンである。より重要なのは、以前のRNN手法と比較して、より多くのパラメータと効率的な学習を採用できるため、スケーリングが可能になり、最終的に今日の大規模言語モデル(LLMs)につながることである。また、エンコーダ・デコーダと自己アテンション、クロスアテンションの設計は、embeddingsのコレクションを使用することで、異なるモーダルデータを統一的な表現で表現し、マルチモーダル学習を自然に可能にします。この記事がこれらの概念の概要を提供することを願っています。加えて、さらに読むためのリソースのリストも提供します。
その他のリソース
論文注意力がすべて
長文のためのセンテンス・トランスフォーマー ](https://zilliz.com/learn/Sentence-Transformers-for-Long-Form-Text)
テキストを変換する:NLPにおけるセンテンス・トランスフォーマーの台頭](https://zilliz.com/learn/transforming-text-the-rise-of-sentence-transformers-in-nlp)
ヴィジョン・トランスフォーマー(ViT)とは](https://zilliz.com/learn/understanding-vision-transformers-vit)
検出トランスフォーマー(DETR)とは](https://zilliz.com/learn/detection-transformers-detr-end-to-end-object-detection-with-transformers)
BERT (Bidirectional Encoder Representations from Transformers)とは](https://zilliz.com/learn/what-is-bert)
ベクトルデータベースの話](https://zilliz.com/blog)
ベクトル・データベースとは何か、どのように機能するのか](https://zilliz.com/learn/what-is-vector-database)
RAGとは](https://zilliz.com/learn/Retrieval-Augmented-Generation)
 David Wang
David WangDavid Wang, Algorithm Engineer at Zilliz, brings extensive expertise in computer vision and natural language processing. His contributions to advanced embedding algorithm research, including projects like Towhee and GPTCache, reflect his commitment to advancing AI technologies. Before joining Zilliz, he worked at Alibaba Cloud for large-scale object recognition and classification projects. David holds a Master's degree from Dalian University of Technology.


