マルチエージェントシステムの進化:初期のニューラルネットワークから現代の分散学習まで(アルゴリズム編)
この記事では、アルゴリズムの観点から、MASの黎明期から最新の開発までの進化について説明する。
シリーズ全体を読む
- 交差エントロピー損失:機械学習におけるその役割を解明する
- バッチとレイヤーの正規化 - ニューラルネットワークの効率性を引き出す
- ベクトル・データベースによるAIと機械学習の強化
- ラングチェーンツール先進のツールセットでAI開発に革命を起こす
- ベクターデータベース検索テクノロジーの未来を再定義する
- ローカル感度ハッシング (L.S.H.):包括的ガイド
- AIの最適化:安定した普及と効率的なキャッシュ戦略への手引き
- ネモ・ガードレールAIの安全性と信頼性を高める
- ベクトル・データベースに最適化されたデータ・モデリング技法
- カラーヒストグラムの謎を解く:画像処理と解析の手引き
- BGE-M3を探る:Milvusによる情報検索の未来
- BM25を使いこなす:Milvusにおけるアルゴリズムとその応用を深く掘り下げる
- TF-IDF - NLPにおける項頻度-逆文書頻度の理解
- ニューラルネットワークにおける正則化を理解する
- 初心者のためのヴィジョン・トランスフォーマー(ViT)理解ガイド
- DETRを理解する:トランスフォーマーによるエンドツーエンドのオブジェクト検出
- ベクトル・データベース vs グラフ・データベース
- コンピュータ・ビジョンとは?
- 画像認識のための深層残差学習
- トランスフォーマーモデルの解読:そのアーキテクチャと基本原理の研究
- 物体検出とは?総合ガイド
- マルチエージェントシステムの進化:初期のニューラルネットワークから現代の分散学習まで(アルゴリズム編)
- マルチエージェントシステムの進化:初期のニューラルネットワークから現代の分散学習まで(方法論編)
- CoCaを理解する:コントラスト・キャプションによる画像テキスト・ファウンデーション・モデルの進歩
- フローレンスマイクロソフトによるコンピュータビジョンの高度な基礎モデル
- トランスフォーマーの後継者候補マンバ
- ALIGNの説明ノイジー・テキスト教師による視覚・視覚言語表現学習のスケールアップ
この記事は2部構成の第1部です。第2回目の記事はこちら(https://zilliz.com/learn/evolution-of-multi-agent-systems-from-early-neural-networks-to-modern-distributed-learning-methodological-part-2)をご覧ください。
マルチ・エージェント・システム(MAS)**の進化は長い道のりを歩んできた。MASが誕生する以前は、システムは通常、特定のタスクを解決するために単独で動作していた。例えば、物体検出モデルは、画像内の可能性のある物体をすべて検出するだろう。より詳細な物体を検出する必要があれば、同じモデルをより小さな、より関連性の高いデータセットで微調整する。このアイデアは、タスクを解決するために単一のモデルを使用することでした。
しかし、もし複数の物体検出モデルがあり、それぞれが特定の物体の検出に特化していたらどうだろう?複数のモデルが協力して、困難な物体検出タスクを解決し、すべての物体検出タスクに単一のモデルを使用するよりも優れた結果を達成することができる。複数のモデルが協調してタスクを解決するこのシステムは、MASの実用的な実装である。
この記事では、アルゴリズムの観点から、MASの黎明期から最新の開発までの進化について説明する。それでは早速、初期の手法の1つであるSMFFNNフレームワークから始めましょう。
SMFFNN フレームワーク
ニューラル・ネットワークは、トレーニング・データと同様のテスト・データを予測する場合には、高い信頼性が証明されている。しかし、テストデータがトレーニングデータから大きく乖離している場合には苦戦を強いられる。
例えば、犬と猫の画像の大規模なデータセットを使って、犬と猫の画像を分類するニューラルネットワークを訓練したとしよう。テストデータに猫の写真が含まれていれば、モデルは良い結果を出す可能性が高い。しかし、データにキリンの写真が含まれていれば、このモデルは誤った予測をするでしょう。言い換えれば、ニューラルネットワークはしばしば、学習分布から外れた実世界のデータの複雑さに対処するのに苦労する。
ニューラルネットワークのこの欠点に対処する最も初期の方法の1つは、教師あり多層フィードフォワードニューラルネットワーク(SMFFNN)とポテンシャル重み線形分析(PWLA)の組み合わせです。
図- PWLAとSMFFNNのワークフロー.png](https://assets.zilliz.com/Figure_Workflow_of_PWLA_and_SMFFNN_85c07cefe1.png)
図:PWLAとSMFFNNのワークフロー。
名前が示すように、SMFFNNは多層ニューラルネットワークで構成されている。各層の意思決定を「イエス」か「ノー」かに単純化するバイナリーステップ関数を用いて、1エポックのみ訓練される。SMFFNNの訓練プロセスの前に、データはPWLAによって前処理されなければならない。
一言で言えば、PWLAはデータの前処理技術であり、ベクトル・トルクのような物理学の概念を用いて、データのどの部分が重要かを最初に推測することができる。まず入力データを "min and max "法で正規化し、データのどの部分が重要かを判断し、次にデータの最も関連性の高い部分に焦点を絞って次元削減を実行する。
処理されたデータは、SMFFNNによって学習され、正確な予測を行うために使用される。このアプローチの利点は、新しいデータが利用可能になったときに、それを直接PWLAに統合できることである。PWLAとSMFFNNが連携して異なるソースからのデータを分類していることから、MASの初期の応用例を見ることができる。
例えば、どの都市が最も病院を必要としているかを分類するMASが欲しいとしよう。そのためにはまず、人口、首都からの距離、現地スタッフの数、医療保険加入者数、既存の病院の数などを収集する。次に、PWLAはこれらのデータをすべて収集し、データの正規化を行い、どの特徴がユースケースにとって重要かを分析し、最も重要な特徴に焦点を当てるために次元削減を行う。最後に、これらの特徴をSMFFNNに送り、学習と予測を行う。
図-ユースケース例-病院建設ゾーンのインテリジェント分類](https://assets.zilliz.com/Figure_Example_Use_Case_Illustration_Intelligent_classification_of_zones_for_building_a_hospital_Source_e2d3cd36ff.png)
図-ユースケース例ユースケース例:病院建設のためのゾーンのインテリジェントな分類 | 出典._.
しかし、この方法にはいくつかの制限がある。
設計上、SMFFNNとPWLAは情報の一方向の流れに従うため、インテリジェントなマルチエージェントシステムを構築するのに必要なフィードバックメカニズムの概念に苦戦する。現実のマルチエージェントシステムでは、エージェントはフィードバックや新しいデータに基づいて行動を進化させることができなければならない。しかし、SMFFNNシステムには、エージェントが時間をかけて学習し、適応することを可能にするフィードバックメカニズムが欠けている。
また、このシステムでは単一エージェントによる相互作用のみが可能です。システムにSMFFNN(またはエージェント)を増やすと、各エージェントは知識を効率的に共有したり、他のエージェントとの相互作用に基づいて適応したりすることができなくなり、より自律的に行動するようになる。エージェントの数が増えるにつれて、多層ネットワークをトレーニングし、すべてのエージェントに対して前処理を行うという計算の複雑さにより、この方法は効率的なスケールに苦戦する可能性がある。
強化学習の出現
強化学習(RL)**の概念は、SMFFNNの教師あり手法とは異なり、解決したいタスクのダイナミクスを定義することなく実装できるため、その登場以来大きな注目を集めている。さらに、RLはSMFFNNに欠けていたフィードバック機構の概念を導入している。
RLシステムは、タスクを遂行するために環境と相互作用するエージェントから構成される。エージェントが行動を起こすごとに、一定の報酬を受け取る。エージェントの行動がタスクのゴールに到達すればするほど、より高い報酬を得ることができる。したがって、RLシステムの目標は、報酬を最大化するためにエージェントの将来の行動(ポリシー)を改善するよう導くことである。
図- RLシステムにおける反復ごとのエージェントと環境の相互作用](https://assets.zilliz.com/Figure_Agent_Environment_interaction_per_iteration_in_an_RL_system_932583f803.png)
図:RLシステムにおける反復ごとのエージェントと環境の相互作用_。
報酬を最大化するために、Q値と呼ばれる指標が導入される。Q値は、エージェントが将来受け取るであろう報酬に基づいて、与えられた状態で特定の行動を取ることがエージェントにとってどの程度良いかを評価する。エージェントはこの情報を使って、長期的な累積報酬を最大化するために取るべき行動を決定する。
ディープQ学習(DQN)とディープ決定性政策勾配(DDPG)は、エージェントのQ値を最大化するための最もよく知られたRLアルゴリズムの2つである。
DQNは、離散的な行動(右、左、前進、後退など)のQ値関数を最適化することに重点を置いている。Q値は、環境から受け取る報酬と将来の期待報酬に基づいて、ベルマン方程式を使用して各反復で更新され、最適なQ値、したがって、最適なポリシーを導きます。
一方、DDPGは2つの要素からなるアルゴリズムである:
アクター:アクターの役割は、各状態に対して最適な行動を直接出力することである。
クリティック:批評家はQ-LearningにおけるQ値の学習方法と同様に、Q値を推定します。ただし、DDPGにおけるクリティックは、連続的なアクション空間(例えば、連続的なステアリング角度と速度値を持つ車の制御など)において、アクターが選択するアクションの品質を評価します。
図- DQNとDDPGの図](https://assets.zilliz.com/Figure_Diagram_of_DQN_and_DDPG_Source_dd4a50c223.png)
図:DQNとDDPGのダイアグラム Source._.
DDPGの目標は行為者(政策)と批判者(Q値関数)の両方を最適化することです。それでもなお、批判者のQ値関数は行為者の政策を評価し改善する上で重要な役割を果たします。
しかし、SMFFNNと同様に、DQNもDDPGも単一エージェント間の相互作用のために設計されています。つまり、単一のエージェントのポリシーのみを最適化することになる。一つの簡単な解決策は、複数の単一エージェントを作成することである。残念ながら、複数のRLシングルエージェントを実装することは最適化が難しい。というのも、各エージェントの視点から見ると、環境はもはや静止しておらず、あるエージェントがとった行動が、他のエージェントの行動によって異なる報酬につながる可能性があるからです。
複数のシングルエージェントの最適化の難しさを解決する方法として、非定常性をより効果的に扱えるMulti-Agent Deep Deterministic Policy Gradient (MADDPG)と呼ばれる方法が導入されました。
MADDPGの主な特徴は、中央集権的な批評家であることで、批評家は学習中の全エージェントの観測と行動にアクセスできる。したがって、Q値関数は各エージェントのポリシーを他のエージェントのポリシーに条件付けることで最適化される。このアプローチは、各エージェントを静的な環境の一部として扱うのではなく、他のエージェントの現在の戦略に対する最適な応答を学習させるので有用である。
図- 25000エピソード後の協調コミュニケーションにおけるエージェント報酬(左)とポリシー学習成功率(右)](https://assets.zilliz.com/Figure_Agent_reward_left_and_policy_learning_success_rate_right_on_cooperative_communication_after_25000_episodes_Source_ab710b0953.png)
図:25000エピソード後の協調コミュニケーションにおけるエージェント報酬(左)と政策学習成功率(右) Source._.
上の図からわかるように、MADDPGにおけるエージェントの性能は、数回の実験におけるエージェントの報酬と政策学習の成功率において、DDPGのような他のシングルエージェントアルゴリズムよりも優れています。
しかし、MADDPGアプローチには1つの問題がある:スケーラビリティの問題である。 上述したように、中央集権的な批判者アプローチでは、すべてのエージェントの観察と行動が考慮される。より多くのエージェントを訓練したい場合、スケーラビリティの問題が発生する可能性があり、訓練プロセスには時間と計算コストがかかる。
この課題を解決する1つの方法は、グラフ・ニューラル・ネットワーク(GNN)である。
MASにおけるグラフ・ニューラル・ネットワーク
GNNがマルチエージェントシステムでどのように使用できるかを探る前に、グラフを理解することが重要である。グラフは、ノードとエッジという2つの基本要素を持つデータ構造である。ノードは、単語、エージェント、トークンなど、ユースケースに応じて様々なエンティティを表すことができる。一方、エッジは2つのノード間のつながりを表す。
図- グラフのデータ構造](https://assets.zilliz.com/Figure_Graph_data_structure_368d6ea352.png)
図:グラフのデータ構造。
各ノードは通常、固有の特徴や属性を持ち、通常は特定の次元を持つベクトルとして表現される。ノードほど一般的ではないが、エッジも特徴を持つことができる。どの2つのノードがエッジによって接続されているかを決定するために、グラフ構造は隣接行列として表現されます。ここで、A[i,j]はノードiとjの間に接続があれば1、そうでなければ0となります。
ノード、ノードの特徴、隣接行列があれば、グラフベースのニューラルネットワーク(GNN)を実装することができる。GNNトレーニングのゴールはノード、エッジ、あるいはグラフレベルで設定できる。つまり、例えばノード、エッジ、グラフの分類を行うことができる。
以上の概念から、マルチエージェント環境をグラフとしてモデル化できることが理解できた。これはまた、グラフ畳み込み強化学習(略してDGN)と呼ばれる方法によって実装されている。
図- DGNアーキテクチャ- エンコーダー、畳み込み層、Qネットワーク。すべてのエージェントは重みを共有し、重みを更新するために勾配が蓄積される](https://assets.zilliz.com/Figure_DGN_architectures_encoder_convolutional_layer_and_Q_network_All_agents_share_weights_and_gradients_are_accumulated_to_update_the_weights_Source_d00669558f.png)
図:DGNアーキテクチャ:エンコーダ、畳み込み層、Qネットワーク。すべてのエージェントは重みを共有し、重みを更新するために勾配が蓄積される。 Source._.
DGNでは、環境内の各エージェントはグラフ内のノードで表される。エッジは隣接するエージェント間で形成され、隣接するエージェントは通常、特定の環境に応じて、距離または他の測定基準によって決定される。近傍のエージェントは、互いに影響し合う可能性が高いため、通信を行うことができる。グラフ構造は静的なものではなく、エージェントが移動したり、環境に出入りしたりすることで、時間とともに変化する。
DGNは、すべてのエージェント間で重みを共有するため、パラメータ共有機能により拡張が容易です。これは、全てのエージェントが同じニューラルネットワークパラメータを使用することを意味し、エージェントの数に関係なく学習する必要があるパラメータの数を減らすことができる。また、前述したように、DGNの背後にある考え方は、近くのエージェントは相互作用しやすく、互いに影響を与えやすいということです。したがって、各エージェントは、環境内のエージェント総数に関係なく、隣接するエージェントからの特徴のみを必要とする。
DGNのスケーラビリティの特徴を示すために、DGNは訓練されたエージェント数よりも多くのエージェントが存在するシナリオにうまく汎化することができる。例えば、ルーティングの実験では、20のエージェントと20のルーターで訓練されたDGNは、再学習することなく、最大140のエージェントがいる環境でも良い結果を出すことができた。DGNを使えば、性能を大幅に低下させることなく、エージェント数を多数に拡張することができる。
MASにおけるトランスフォーマー
グラフ以外に、有名なトランスフォーマーアーキテクチャもマルチエージェントシナリオに適用されている。既にご存知かもしれないが、トランスフォーマーアーキテクチャはエンコーダーとデコーダーで構成されている。エンコーダは入力シーケンスを潜在空間にマッピングし、デコーダは出力を自己回帰的または逐次的に生成する。
トランスフォーマー・アーキテクチャーの特徴は、各エンコーダーとデコーダーのブロックにアテンション層があることだ。このレイヤーは、入力シーケンスに関する文脈情報を提供する上で極めて重要である。例えば、「私はガレージに車を停める」と「私は公園で外を歩く」の「公園」という単語は、このアテンション・レイヤーによってTransformerによって異なるものとして認識される。
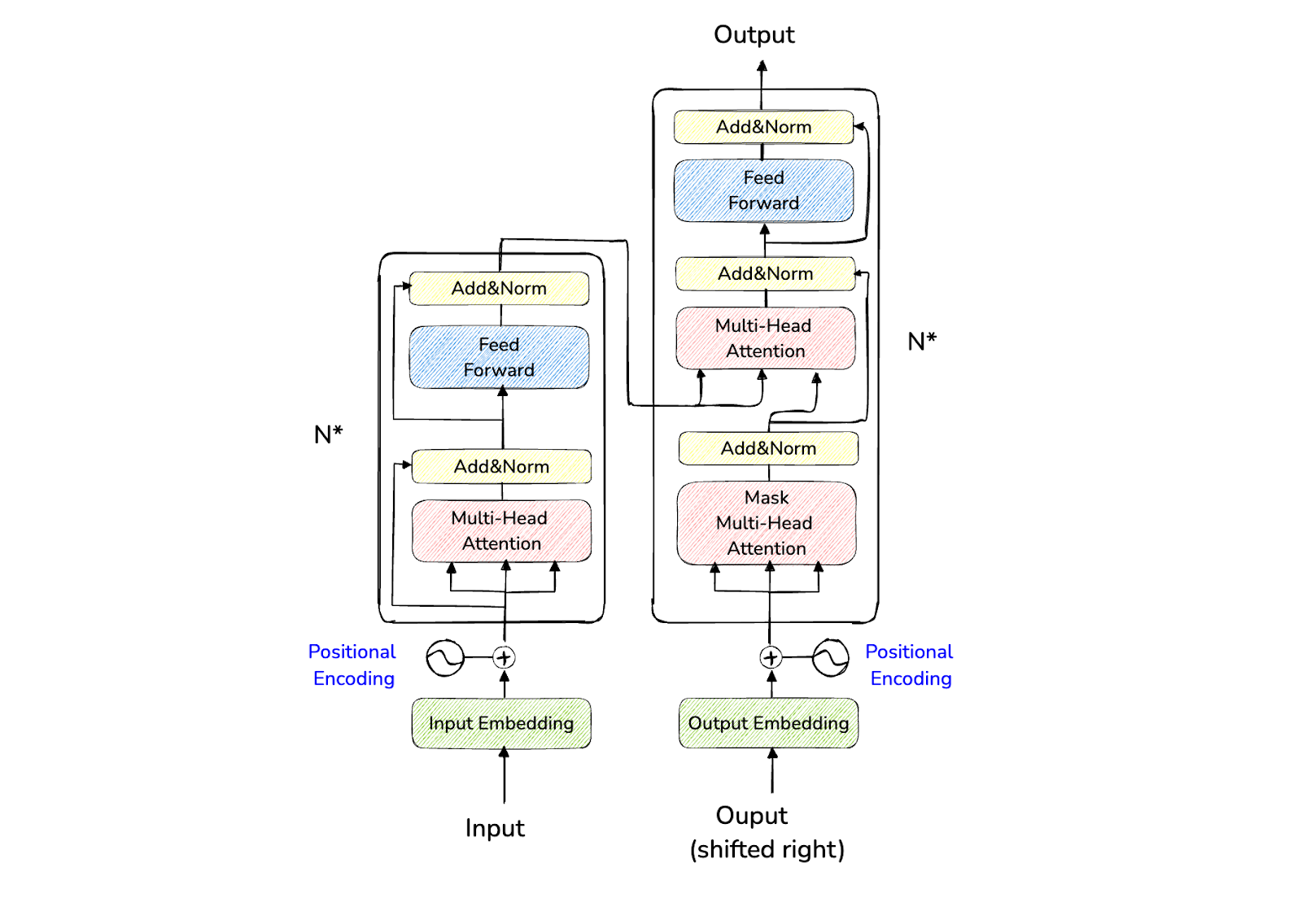 図-トランスフォーマーのアーキテクチャ.png
図-トランスフォーマーのアーキテクチャ.png
図-トランスフォーマーの建築.png]()トランスフォーマーのアーキテクチャ。
Transformerアーキテクチャは、当初、テキスト分類、名前付きエンティティ認識、テキスト生成、質問応答など、テキストのユースケースのみを想定していた。しかし、Transformerは汎用性があり、画像や音声など、異なるモダリティに使用できることが判明した。したがって、マルチエージェントシステムを含む多くのユースケースでTransformersを使用できることは驚くことではない。
前のセクションで述べたように、マルチエージェントシステムでは、複数のエージェントが協力して共有報酬を最大化する必要がある。課題は、各エージェントの行動が他のエージェントの行動とどのように相互作用するかを考慮しながら、各エージェントに最適なポリシーを見つけることである。我々は、非定常性がマルチエージェントシステムにおける大きな課題の一つであることを知っている。
マルチエージェントシステムに関する1つの視点として、マルチエージェントの意思決定は一連の行動として考えることができるという考え方がある。これは、翻訳のような言語タスクにおいて、文中の単語がどのように配置されるかに似ている。これによって、Transformersのようなシーケンスモデル(SM)を使う道が開ける。
マルチエージェント環境でTransformersを実装するアルゴリズムの1つに、Multi-Agent Transformers(MAT)というものがある。MATはエージェントの意思決定プロセスを、文中の単語が互いにどのように続いていくかに似たシーケンスとして扱う。
図-すべてのエージェントが同時に行動を起こす従来のマルチエージェント学習パラダイム(左)と、エージェントが順序に従って行動を起こすマルチエージェント逐次決定パラダイム(右)](https://assets.zilliz.com/Figure_Conventional_multi_agent_learning_paradigm_left_wherein_all_agents_take_actions_simultaneously_vs_the_multi_agent_sequential_decision_paradigm_right_where_agents_take_actions_by_following_a_sequential_order_060ac41b91.png)
図:すべてのエージェントが同時に行動を起こす従来のマルチエージェント学習パラダイム(左)と、エージェントが順序に従って行動を起こすマルチエージェント逐次決定パラダイム(右) Source._.
MATアプローチでは、各エージェントは、文に単語が追加されるように、逐次的に決定を下します。つまり、最初のエージェントは観察に基づいて行動を決定する。次に、次のエージェントは最初のエージェントが何をしたかを見て、その観察を考慮し、決定する。このプロセスは続き、各エージェントは自分自身の決定を下す前に、前のエージェントが行ったことを考慮する。こうすることで、MATはエージェントが一緒に意思決定を行う複雑さを軽減する。MATは、問題を扱いやすいステップ・バイ・ステップのプロセスに変えるのだ。
MATはTransformerモデルを使用しているため、マルチエージェントの実装ではエンコーダとデコーダに依存している:
エンコーダー:エンコーダー:エンコーダーは、すべてのエージェントからのオブザベーション(彼らが環境で見たもの)を受け取り、有用な情報に変換する。
デコーダー:デコーダーはこの情報を受け取り、前のエージェントが何をしたかを考慮しながら、各エージェントにとって最適な行動を次々に予測する。行動を決定する際に、情報の最も重要な部分に焦点を当てるために、通常のテキスト生成プロセスと同様のアテンションメカニズムを使用する。
下の視覚化でわかるように、MATはMAPPOやHAPPOのような強力なベースラインと比較して、ベンチマーク課題において優れた性能を発揮します。MATは、管理可能なステップに分解することで、複数のエージェントを調整する問題を大幅に簡素化します。
MATは、複数のエージェントを調整する問題を管理可能なステップに分解することで、大幅に簡素化します。ソース..png](https://assets.zilliz.com/Figure_Performance_on_the_Half_Cheetah_task_with_different_disabled_joints_Source_303323eb53.png)
図:さまざまな関節が無効化されたHalfCheetahタスクのパフォーマンス. Source._.
結論
本稿では、人工知能におけるマルチエージェントシステムの進化について、初期のニューラルネットワークから現代の学習アルゴリズムまで、アルゴリズムの観点から考察した。MASを実装する初期のアルゴリズムは、SMFFNNとPWLAと呼ばれる単一のニューラルネットワークとデータ前処理技術から構成されている。しかし、SMFFNNはフィードバック機構を欠いており、マルチエージェント相互作用に苦戦していた。
この問題に取り組むため、DQNやDDPGのようなRLアルゴリズムなど、より高度なアプローチが導入された。これらのRLアルゴリズムは、フィードバック機構と連続行動空間を導入した。しかし、初期のRLアルゴリズムの主な課題は、シングルエージェントRLをマルチエージェントシナリオに拡張することであり、MADDPGの開発につながった。MADDPGに関連するスケーラビリティの問題を解決するために、グラフ、およびトランスフォーマベースのアルゴリズムをMASで使用することができ、ベースラインモデルと比較して有望な結果を示している。
次回](https://zilliz.com/learn/evolution-of-multi-agent-systems-from-early-neural-networks-to-modern-distributed-learning-methodological-part-2)では、MASの進化を方法論やアプローチ・ベースの観点から論じたい。ご期待ください。
続きを読む
半導体製造業がドメイン固有モデルとエージェント型AIを使って問題解決する方法 ](https://zilliz.com/blog/industrial-problem-solving-through-domain-specific-models-and-agentic-ai-in-semiconductor-manufacturing)
Mistral Large、Nemo、Llamaエージェントによるマルチエージェントシステムの最適化](https://zilliz.com/blog/optimize-multi-agent-system-with-mistral-large-mistral-nemo-and-llama-agents)
専門家の混合(MoE)とは何か? その仕組みとユースケース】(https://zilliz.com/learn/what-is-mixture-of-experts)
PagedAttentionによる大規模言語モデルサービングの効率的なメモリ管理](https://zilliz.com/learn/efficient-memory-management-for-llm-serving-pagedattention)
深層残差学習とは何か ](https://zilliz.com/learn/deep-residual-learning-for-image-recognition)
RAGとは ](https://zilliz.com/learn/Retrieval-Augmented-Generation)
ベクトル・データベースとは何か、どのように機能するのか ](https://zilliz.com/learn/what-is-vector-database)
あなたのGenAIアプリのためのトップパフォーマンスAIモデル|Zilliz](https://zilliz.com/ai-models)
ジェネレーティブAIリソースハブ|Zilliz](https://zilliz.com/learn/generative-ai)