ベクトル・データベースに最適化されたデータ・モデリング技法
この記事では、ベクター・データベースのパフォーマンスを最適化するためのさまざまなデータ・モデリング・テクニックを紹介する。
シリーズ全体を読む
- Cross-Entropy Loss: Unraveling its Role in Machine Learning
- Batch vs. Layer Normalization - Unlocking Efficiency in Neural Networks
- Empowering AI and Machine Learning with Vector Databases
- Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
- Vector Databases: Redefining the Future of Search Technology
- Local Sensitivity Hashing (L.S.H.): A Comprehensive Guide
- Optimizing AI: A Guide to Stable Diffusion and Efficient Caching Strategies
- Nemo Guardrails: Elevating AI Safety and Reliability
- Data Modeling Techniques Optimized for Vector Databases
- Demystifying Color Histograms: A Guide to Image Processing and Analysis
- Exploring BGE-M3: The Future of Information Retrieval with Milvus
- Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
- TF-IDF - Understanding Term Frequency-Inverse Document Frequency in NLP
- Understanding Regularization in Neural Networks
- A Beginner's Guide to Understanding Vision Transformers (ViT)
- Understanding DETR: End-to-end Object Detection with Transformers
- Vector Database vs Graph Database
- What is Computer Vision?
- Deep Residual Learning for Image Recognition
- Decoding Transformer Models: A Study of Their Architecture and Underlying Principles
- What is Object Detection? A Comprehensive Guide
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Algorithmic)
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Methodological)
- Understanding CoCa: Advancing Image-Text Foundation Models with Contrastive Captioners
- Florence: An Advanced Foundation Model for Computer Vision by Microsoft
- The Potential Transformer Replacement: Mamba
- ALIGN Explained: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
データモデリングプロセスは、組織のデータアーキテクチャを単純化し、形式化する。新しいデータベースを作成するための設計図として、データと情報を表現する。これにより、関係者の理解と協力が強化され、データ品質と開発効率が向上します。
ベクターデータベースは、構造化されたデータではなく、高次元の非構造化データに焦点を当てているため、従来のデータベースと比較してユニークである。このことは、ベクトル・データベースのデータ・モデリングに独特の課題と機会をもたらし、最適化されたテクニックを議論する根拠となる。
ベクターデータベースの説明
ベクトルデータベースは、ベクトル埋め込みという形でデータを保存します。ベクトル内の各値はデータの特徴を表し、集合的にデータの包括的な表現を形成します。これらのベクトルは、テキストや画像のような高次元の非構造化データを格納・管理します。ベクトル化された構造により、効率的なデータ検索や類似性のような高度な検索メカニズムが可能になります。
ベクトル・データベースはまた、膨大なベクトル埋め込みコレクションへのアクセスを提供することで、AIモデルにデータポイント間の関係を理解する力を与える。
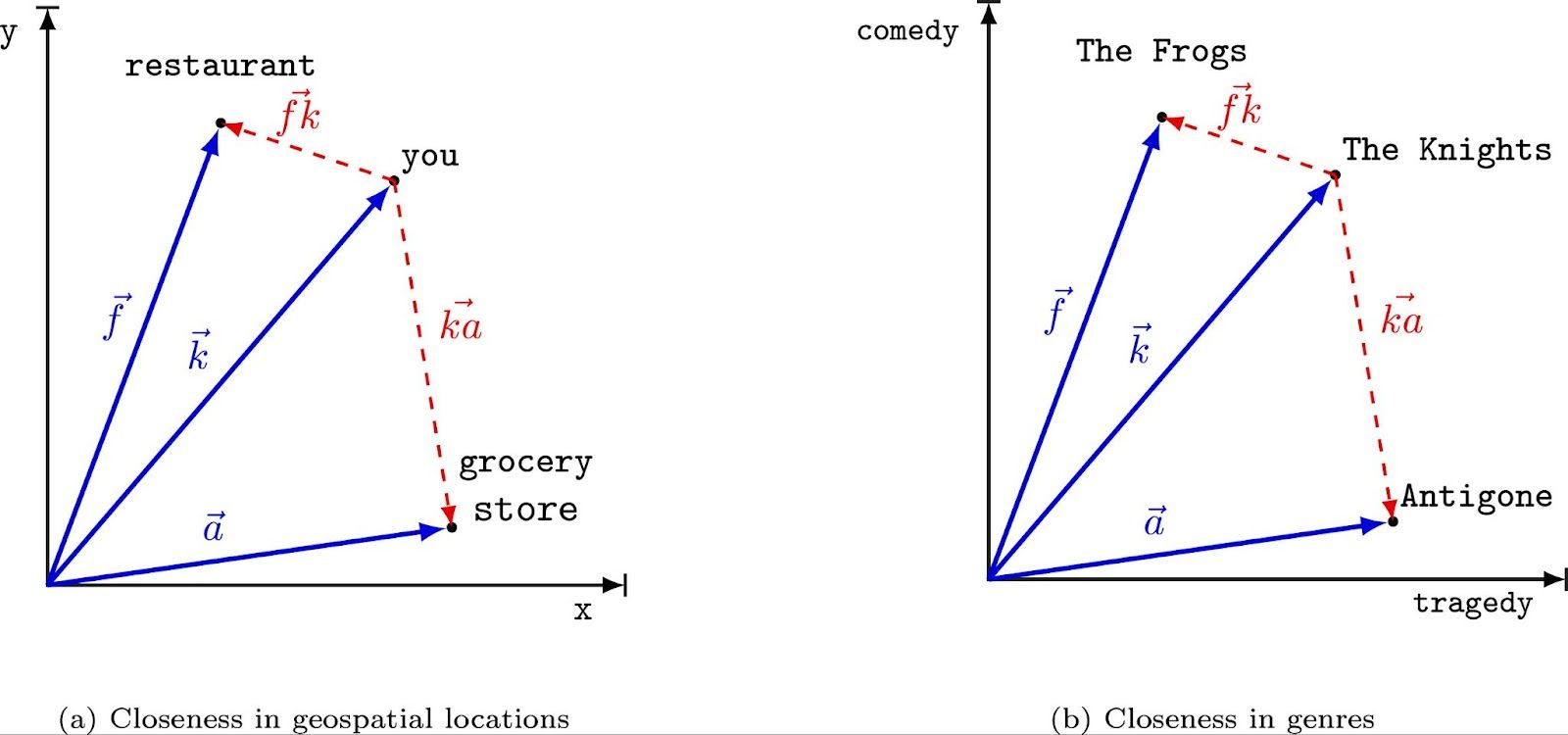
ベクトルのグラフィカルな表現 出典
しかし、その中核となる機能は、データモデリングに特別な注意を払う必要がある。エンジニアは、検索効率を維持するためにインデックスのような技術を実装し、埋め込みを生成するために適切なアルゴリズムを選択しなければなりません。
ベクターデータベースにおけるデータモデルの最適化
ベクターデータベースは、ベクターデータの保存と検索に焦点を当てています。従来のデータベースはベクトルデータの最適化の可能性を見落としており、複数のクエリベクトルを利用するような機能が含まれていない可能性があります。そのため、後述するようなベクトルデータベース特有のデータモデリング技術や最適化が採用されている:
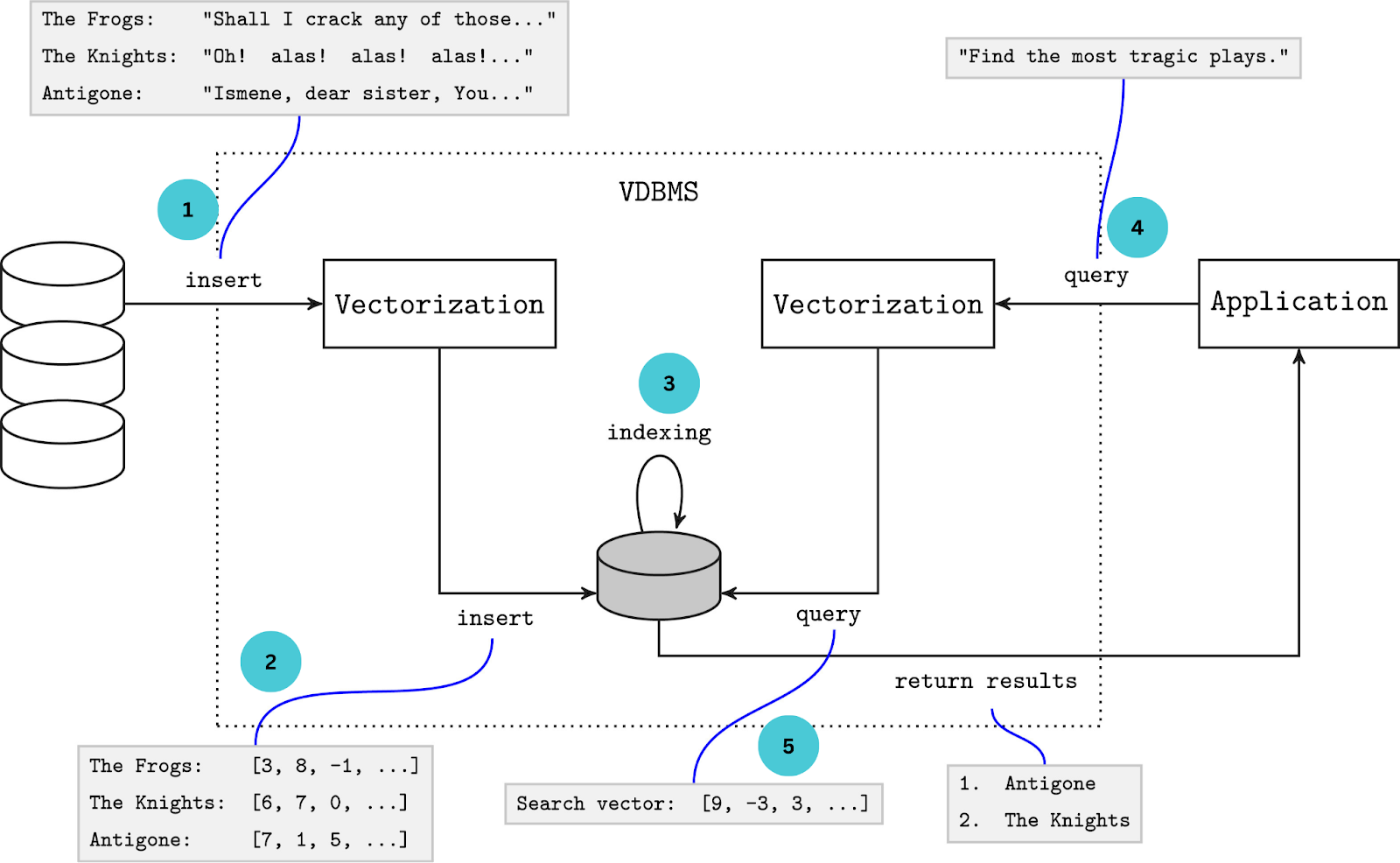
データベースシステムの簡略化された描写で、ベクトルデータベースへの情報の移動とベクトルデータベースからの情報の変更を示す - Source_
- 埋め込み戦略:**様々なアルゴリズムが、テキストのような非構造化データから埋め込みを計算します。よく使われる手法としては、Sentence Transformer、OpenAI Embedding、BGE Embeddingなどがあります。この図は、埋め込みアルゴリズムがどのようにオブジェクトをベクトル表現に変換するかを表しています。
<br
各アルゴリズムには処理能力があり、異なるユースケースに適合します。正しいアルゴリズムを選択することは、ベクトル化ステップを最適化するために不可欠です。
索引付け戦略:** データオブジェクトがベクトル化され、ベクトルデータベースに格納されると、索引付けはクエリのパフォーマンスを向上させます。インデックス作成アルゴリズムのトレードオフは、精度と速度のバランスをとることです。よく使われるProduct Quantizationのような手法は、高次元のベクトルをより小さな部分に分割することで次元削減を行い、精度を犠牲にすることで記憶領域を削減します。他のテクニックとしては、locality-sensitive hashing や hierarchical navigable small worlds がある。
距離メトリック: ベクトルデータベースは、クエリとインデックス付きベクトルを比較し、最近傍を見つけるために距離メトリックを利用します。一般的なメトリクスには、余弦類似度、ユークリッド距離、ドット積があります。この機能は、画像やテキストの検索システムなど、類似したベクトルを見つけることが重要な様々なアプリケーションで特に有用です。下の図は、直交図上のベクトル間の距離が、どのようにそれらの類似性を表すかを示しています。
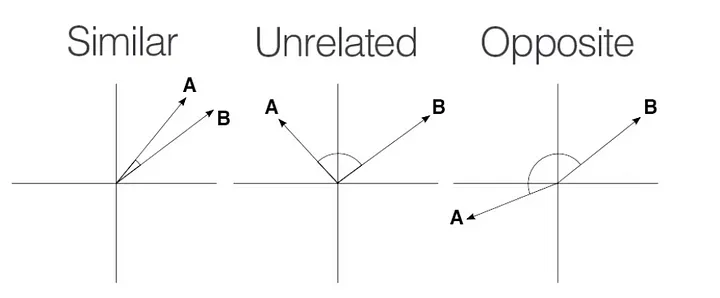
ベクトルの類似性 - ソース_
アプリケーションと使用例
伝統的なデータベースとは対照的に、ベクトル・データベースは高次元のデータに重点を置いており、ユニークなユースケースを提供している。以下にその使用例を紹介する:
セマンティック検索](https://zilliz.com/glossary/semantic-search):** NLPと機械学習(ML)を用いて、ユーザーの検索クエリの文脈と重要性を把握する。ベクトル・データベースは、類似性のためにベクトルでデータを保存、比較、検索することで、セマンティック検索の効率と精度を向上させることができる。セマンティック検索エンジンの例としては、Google、Bing、Yummly、IBM Watson Discovery**などがある。
推薦システム](https://zilliz.com/vector-database-use-cases/recommender-system):**ベクターデータベースの類似検索機能は推薦アルゴリズムに力を与える。これらのシステムは、入力ベクトルをベクトル・データベースに格納されているベクトルと比較し、類似の一致を検索するアルゴリズムを使用する。このプロセスは、eコマースストアやNetflixのようなストリーミングサイトを推薦する。
ベクトルデータベースは、データのベクトル表現を利用することで、クラスタリング、分類、異常検知などの複雑なデータ分析タスクを推進します。このアプローチにより、企業は大規模なデータセット内の隠れたパターン、関係、洞察を発見し、データ主導の意思決定、業務の最適化、競争優位性を促進することができます。
結論
ベクトルデータベースは、高次元ベクトルを格納し、リッチな非構造化データをカプセル化する先進的なデータモデルである。このモデルは従来のデータベースシステムとは大きく異なるため、特殊なデータモデリング技術と最適化が必要となる。これらの手法は、複雑なデータアプリケーションを処理するためのベクトルデータベースの可能性を最大限に引き出します。AIの時代におけるデータ管理の未来として、これらのテクニックと最適化を深く理解することは、洗練されたデータ環境で卓越することを目指すデータ実務家にとって極めて重要である。
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS