TF-IDF - NLPにおける項頻度-逆文書頻度の理解
用語頻度-逆文書頻度(TF-IDF)の意義とその応用、特にMilvusのようなベクトルデータベースの機能強化について探求する。
シリーズ全体を読む
- 交差エントロピー損失:機械学習におけるその役割を解明する
- バッチとレイヤーの正規化 - ニューラルネットワークの効率性を引き出す
- ベクトル・データベースによるAIと機械学習の強化
- ラングチェーンツール先進のツールセットでAI開発に革命を起こす
- ベクターデータベース検索テクノロジーの未来を再定義する
- ローカル感度ハッシング (L.S.H.):包括的ガイド
- AIの最適化:安定した普及と効率的なキャッシュ戦略への手引き
- ネモ・ガードレールAIの安全性と信頼性を高める
- ベクトル・データベースに最適化されたデータ・モデリング技法
- カラーヒストグラムの謎を解く:画像処理と解析の手引き
- BGE-M3を探る:Milvusによる情報検索の未来
- BM25を使いこなす:Milvusにおけるアルゴリズムとその応用を深く掘り下げる
- TF-IDF - NLPにおける項頻度-逆文書頻度の理解
- ニューラルネットワークにおける正則化を理解する
- 初心者のためのヴィジョン・トランスフォーマー(ViT)理解ガイド
- DETRを理解する:トランスフォーマーによるエンドツーエンドのオブジェクト検出
- ベクトル・データベース vs グラフ・データベース
- コンピュータ・ビジョンとは?
- 画像認識のための深層残差学習
- トランスフォーマーモデルの解読:そのアーキテクチャと基本原理の研究
- 物体検出とは?総合ガイド
- マルチエージェントシステムの進化:初期のニューラルネットワークから現代の分散学習まで(アルゴリズム編)
- マルチエージェントシステムの進化:初期のニューラルネットワークから現代の分散学習まで(方法論編)
- CoCaを理解する:コントラスト・キャプションによる画像テキスト・ファウンデーション・モデルの進歩
- フローレンスマイクロソフトによるコンピュータビジョンの高度な基礎モデル
- トランスフォーマーの後継者候補マンバ
- ALIGNの説明ノイジー・テキスト教師による視覚・視覚言語表現学習のスケールアップ
自然言語処理(NLP)](https://zilliz.com/learn/A-Beginner-Guide-to-Natural-Language-Processing)において、文書内の単語の関連性と重要性を理解することは、インテリジェントな検索エンジンの構築から文書分類の自動化まで、多くのアプリケーションにとって極めて重要である。ここで、TF-IDF(Term Frequency-Inverse Document Frequency)統計は、単なる頻度カウントでは不可能な方法で単語の重要性を照らし出す基礎的なツールとして登場する。
TF-IDFは、文書中の各単語の出現頻度と、その単語が文書コーパス全体(つまり、対象となる文書全体)でどれだけ稀に出現するかとのバランスをとることで、特定のクエリやトピックと文書の関連性をピンポイントで特定するのに役立つ。ある文書の単語のTF-IDFスコアが高いということは、その単語がその文書で一般的であるだけでなく、文書セット全体でも稀であることを示し、その単語が文書の内容にとって重要である可能性が高いことを示している。
例えば、技術に関連する文書が多いコーパスでは、「コンピュータ」という単語が頻繁に登場するかもしれない。しかし、ある特定の文書で「quantum」という単語が、コーパス全体における出現頻度よりも高い頻度で使われている場合、この文書では「quantum」のTF-IDFスコアが高くなり、その特定の文脈における重要性が指摘される。一方、"is "や "of "のような一般的な単語は、ほとんどすべての英文に頻繁に出現するため、重要度は低くなる。このため、TF-IDFは、より広い議論の中で、より一般的ではなく、より具体的なトピックに関連する文書を区別するための優れたツールとなる。
TF-IDFを採用することで、NLPシステムは効果的に文書をランク付けし、分類することができ、ユーザーのクエリに基づいて最も関連性の高い文書を検索することが重要である検索エンジン最適化などのタスクを支援する。この技術はまた、文書の内容を定義する重要な用語をハイライトすることで要約作業を支援し、迅速かつ正確な情報検索を可能にする。Pythonを使ってTF-IDFを簡単に見てみよう:
# サンプルの帰属: scikit-learn
# TfidfVectorizerを初期化し、テキストドキュメントをTF-IDF行列に変換する準備をする。
from sklearn.feature_extraction.text import TfidfVectorizer.
# 分析したい文書(文)のリストがある。
# この例では、"docs "は4つの異なる文書を表す。
# この例では、"docs "は4つの異なる文書を表しています。
docs = ["これは最初の文書です、
"このドキュメントは2番目のドキュメントです"、
"そしてこれが3番目の文書です"、
"これが最初の文書ですか?"].
# このステップでは、文書内の各単語のTF-IDFを計算する。
適合部は文書の語彙を学習し、変換部は # TF-IDFを作成する。
# TF-IDF行列を作成する。
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(docs)
# これはvectorizerによって学習された語彙を表示します、
# アルファベット順に並べられた、ドキュメント内のそれぞれのユニークな単語を表示します。
print("変換のための出力特徴名: \n")
print(vectorizer.get_feature_names_out())
# これはTF-IDFスコアの疎行列表現を示しています。
# どの文書(行)とどの単語(列)に対応するかを示します。
# どの単語(列)に対応するスコアなのかを示します。
print("\nSparse Matrix:\n")
print(tfidf_matrix)
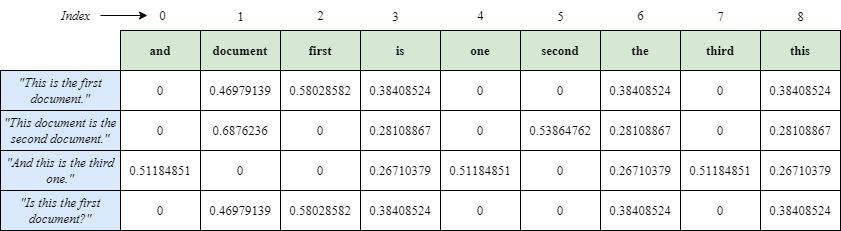
出力される:
変換のための出力特徴名:
['and''document''first''is''one''second''the''third''this']。
疎行列:
(0, 1) 0.46979138557992045
(0, 2) 0.5802858236844359
(0, 6) 0.38408524091481483
(0, 3) 0.38408524091481483
(0, 8) 0.38408524091481483
(1, 5) 0.5386476208856763
(1, 1) 0.6876235979836938
(1, 6) 0.281088674033753
(1, 3) 0.281088674033753
(1, 8) 0.281088674033753
(2, 4) 0.511848512707169
(2, 7) 0.511848512707169
(2, 0) 0.511848512707169
(2, 6) 0.267103787642168
(2, 3) 0.267103787642168
(2, 8) 0.267103787642168
(3, 1) 0.46979138557992045
(3, 2) 0.5802858236844359
(3, 6) 0.38408524091481483
(3, 3) 0.38408524091481483
(3, 8) 0.38408524091481483
デンス・マトリックス
[[0. 0.46979139 0.58028582 0.38408524 0. 0.
0.38408524 0. 0.38408524]
[0. 0.6876236 0. 0.28108867 0. 0.53864762
0.28108867 0. 0.28108867]
[0.51184851 0. 0. 0.26710379 0.51184851 0.
0.26710379 0.51184851 0.26710379]
[0. 0.46979139 0.58028582 0.38408524 0. 0.
0.38408524 0. 0.38408524]]
['and' 'document' 'first' 'is' 'one' 'second' 'the' 'third' 'this'].
この配列は、各単語がこのアルファベット順に並べられたリスト内の位置に従ってインデックス付けされていることを示している。このリストによると
and "は0番目のインデックス
document "は1番目のインデックス
"first "は2番目のインデックス
は3番目のインデックス
"one "は4番目のインデックス
"second "は5番目のインデックス
"the "は6番目のインデックス
"3番目 "は7番目のインデックス
"this "は8番目のインデックス
したがって、スパース行列のエントリ(0, 1) 0.46979138557992045は、単語 "document "に対応し、これは確かに最初の文書("This is the first document.")に現れる。これは、特徴名リストのインデックス1と一致します。密行列はTF-IDFスコアを2次元配列形式で表し、各行が特定の文書、各列が特徴リストの単語に対応します。この行列では、セルの値がそれぞれの文書内の各単語の TF-IDF スコアを示します。どのセルでもスコアがゼロの場合は、対応する単語がその文書に含まれていないことを示します。
TF-IDFを理解する
- 用語頻度(TF):** 用語頻度(TF)は、ある用語が文書に出現する頻度を測定する。テキスト分析やNLPの文脈では、TFは単純に文書内の単語総数で特定の単語の出現回数を割ることで計算される。この正規化によって、文書の長さが変化することを調整し、長い文書に含まれる用語の頻度が、短い文書に含まれる用語の頻度を、単語数が多いからといって本質的に上回らないようにする。 用語を𝑡、文書を𝑑とすると、TFは以下のように計算される:
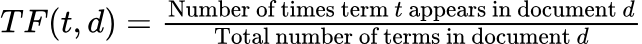
- 逆文書頻度(IDF):** TFは特定の単語が文書に出現する頻度を測定する。基本的な概念は、文書に対する単語の関連性は、その単語の出現頻度とともに高まるというものである。しかし、ある単語が過剰に出現すると、出現頻度は低いものの、文書の内容やテーマをより示唆する可能性のある他の単語の影が薄くなる可能性がある。このため、単語出現頻度は有用な指標であるが、テキスト内の単語の重要性をよりニュアンス豊かに把握するために、逆文書出現頻度(IDF)などの他の手法とバランスをとることが多い。このバランスにより、一般的だが情報量の少ない単語がテキストの特徴表現を支配するのを防ぐことができる。IDFは次のように計算される:
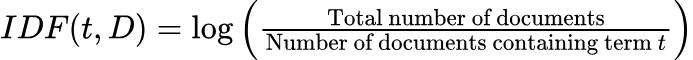
- TFとIDFの組み合わせ:** TF-IDFは、この2つの統計量を掛け合わせることで計算される:
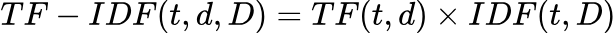
TF-IDF の実用的なアプリケーション
TF-IDFの出力を理解することは、機械学習モデルの特徴抽出、情報検索、テキスト分類など、多くのNLPタスクに役立つ。TF-IDFスコアは、クラスタリングアルゴリズムや、SVMやNaive Bayesのような分類アルゴリズムなど、生のテキストではなく数値入力を必要とするアルゴリズムの入力として役立つ。TF-IDFの応用例としては以下のようなものがある:
検索エンジンの強化:** TF-IDFは、クエリに頻出する用語を含む文書を優先する一方で、すべての文書にわたる各用語の希少性を考慮することで、検索エンジンの機能を劇的に改善することができる。これにより、返される結果がユーザーのクエリに対してより関連性の高いものになる。
ベクトルデータベースと文書の類似性:** ベクトルデータベースでは、文書はTF-IDF値のベクトルに変換される。これらのベクトルをコサイン類似度を用いて比較することで、文脈的に似ている文書を見つけることができる。このアプローチは推薦システムや文書分類タスクで特に有用である。
ベクターデータベースにおけるTF-IDFの応用
Milvus](https://milvus.io/)のようなベクトルデータベースは、ベクトルデータを効率的に管理・照会するために特別に設計されている。これらのデータベースは、自然言語処理から画像認識に至るまで、機械学習アプリケーションで一般的に見られる大量の高次元データを扱うのに理想的である。データをベクトルとして格納することで、空間的な関係やコサイン類似度やユークリッド距離のようなメトリックスを活用した非常に効率的な類似検索が可能になり、類似したアイテムを素早く検索することができる。
TF-IDFは、文書全体の出現頻度に基づいて単語に重みを割り当てることで、テキストを数値化するのに役立つ。これらの重みは、文書内の単語の重要度を示し、テキストのベクトル表現の作成を容易にする。Milvus](https://zilliz.com/what-is-milvus)のようなベクトルデータベースにおいて、TF-IDFはテキストデータのベクトル表現を強化し、検索と検索のプロセスをより効率的にすることができる。
ここでは、TF-IDFとベクトルデータベースとの統合について説明する:
検索精度の向上:** TF-IDFによって文書中の単語に重み付けをすることで、ベクトル・データベースはテキストのより正確で意味のあるベクトル表現を作成することができる。このプロセスでは、一般的な単語と文書の文脈を理解するために重要な単語を区別することで、検索結果の関連性と精度を高めます。
検索効率の向上:** TF-IDFは、各次元が用語のTF-IDFスコアに相関するベクトル表現の構築を支援する。これにより、ベクトルデータベースは効率的な類似度計算を行うことができ、検索クエリと文脈的に類似した文書の検索を支援する。このような機能は、セマンティック検索や文書クラスタリングなど、迅速かつ正確な文書検索を必要とするアプリケーションにおいて極めて重要である。
スケーラビリティとパフォーマンス:** TF-IDFは、テキスト解析におけるスケーラビリティの管理にも役立つ。重要な用語(TF-IDFスコアが高い用語)に焦点を当てることで、データの次元を減らし、より管理しやすいベクトルサイズにすることができる。この削減は、特に大規模なベクトルデータベースのパフォーマンスを維持するために不可欠であり、データ量が増大しても応答性を維持することができる。
Milvusの使用例:** オープンソースのベクトルデータベースとして、Milvusはベクトル埋め込みを使用したスケーラブルな類似検索に最適化されています。TF-IDFのような技術を用いてテキストデータから生成される大量のベクトルを保存し、検索することに長けています。この機能により、Milvusは、デジタルライブラリや電子商取引における商品の推奨など、テキストデータに基づく関連情報への迅速なアクセスが重要な業界やアプリケーションで特に役立ちます。
TF-IDFとMilvusの統合によるテキスト検索の強化
以前作業したPythonスクリプトを進め、tfidf_matrixをMilvusベクトルデータベースにうまく格納できるように改良してみよう。ここでは、TF-IDFベクトルをMilvusに統合し、効率的なクエリと検索のために適切なインデックスを作成する方法を説明します:
ステップ1:ライブラリのインポートとMilvusサーバへの接続
from pymilvus import (
connections、
FieldSchema、
コレクションスキーマ
DataType、
コレクション、
ユーティリティ
)
# Milvus サーバーへの接続
connections.connect(
alias="default"、
host='localhost'、
port='19530'
)
このコードは pymilvus ライブラリから必要なコンポーネントをインポートしている。そして、デフォルトのポート 19530 でローカルに動作している Milvus サーバーへの接続を確立する。
ステップ 2: フィールドの定義、スキーマの作成、Milvus でのコレクションの作成
# Milvus コレクションのフィールドを定義する
fields = [
FieldSchema(name = "id", dtype = DataType.INT64, is_primary = True, auto_id = True)、
FieldSchema(name = "embedding", dtype = DataType.SPARSE_FLOAT_VECTOR)
]
# スキーマとコレクションをMilvusで作成する。
schema = CollectionSchema(fields, description = "TF-IDF Vectors")
コレクション名 = "TFIDF_Collection"
コレクション = Collection(name = collection_name, schema = schema, consistency_level = "Strong")
このコードスニペットはTF-IDFベクトルを格納する新しいMilvusコレクション "TFIDF_Collection "のフィールドとスキーマを定義します。これは2つのフィールドを設定する:「id "は自動的に生成される主整数キーで、"embedding "は "vectorizer "によって抽出された特徴数で指定された次元の浮動小数点ベクトルデータを保持する。コレクションスキーマを定義した後、スクリプトはコレクションが既に存在するかどうかをチェックし、インデックス変更時の競合を避けるためにコレクションを解放する。また、コレクションに既存のインデックスがあるかどうかをチェックし、見つかった場合はそれを削除して、新しい操作やスキーマの更新に対応できるようにします。
ステップ3: Milvusへのデータ挿入
# インデックスパラメータを定義する
インデックスパラメータ
"index_type":"SPARSE_INVERTED_INDEX", # 必要に応じて適切なインデックスタイプを選択します。
"metric_type":"IP", # IP距離(内積)の利用
"params":{} # データセットのサイズに応じてパラメータを調整する
}
# インデックスの作成
collection.create_index(field_name = "embedding", index_params = index_params)
print("New index created successfully.")
collection.load()
# ベクターをMilvusに挿入する
mr = collection.insert([tfidf_matrix])
このコードはTF-IDFベクトルを管理するためにMilvusコレクションにインデックスを設定し、適用します。インデックスパラメータを定義し、効率的なベクトル検索のために "SPARSE_INVERTED_INDEX "を、距離測定のために "Inner Product "を選択し、検索パフォーマンスを最適化するために "nlist "を100に設定する。embedding "フィールドにインデックスを作成し、その作成を確認した後、データ操作のためにコレクションをロードする。そして、TF-IDFベクトルがMilvusコレクションに挿入される。
ステップ4:類似検索の実行
# クエリベクトルを定義する (別の TF-IDF ベクトルでもよい)
query_vector = tfidf_matrix[0:1, :] # クエリベクトルを定義する。
# 最も類似している上位3つのベクトルを検索する
search_params = {
"metric_type":"IP"、
"params":{}
}
results = collection.search(
query_vector、
"embedding"、
search_params、
limit=3)
# 結果を出力する
for hits in results:
for hit in hits:
print(f "hit: {hit}")
utility.drop_collection(collection_name)
最後のコードはクエリとしてTF-IDFベクトルを定義し、内積メトリックを使用してMilvusコレクション内の最も類似した上位3つのベクトルを検索し、見つかった各マッチの詳細を表示します。このステップでは、Milvusでベクトルベースの検索機能を実装し、テキスト類似性アプリケーションに利用する方法を効果的に示している。
高度な考察
TF-IDFはテキスト処理における基本的なツールであり、様々なシナリオにおいてその有効性を高めるいくつかのバリエーションがあります:
高い用語頻度の影響を軽減するために、TFは対数スケール、tf = 1 + log(tf)を使用して調整することができる。(参考文献https://nlp.stanford.edu/IR-book/html/htmledition/sublinear-tf-scaling-1.html)
正規化のテクニック:正規化、特にL2正規化**を適用することで、ベクトルを単位長さにスケールし、類似度の計算をベクトルの大きさではなくベクトル間の角度に集中させる。これにより、すべての文書の比較において一貫した測定値が保証され、正確な類似性と関連性の評価には欠かせません。
TF-IDFの他にも、特定のニーズに応じて、いくつかの用語重み付けスキームがより効果的かもしれない:
Word Embeddings:*Word2Vec や GloVe のような方法は、文脈に基づいた単語の密なベクトル表現を提供し、TF-IDFが見逃す可能性のある、より深い意味での意味を捕捉し、センチメント分析のようなアプリケーションで有用である。
潜在意味解析(LSA):** LSAは、特異値分解を適用してテキストデータの潜在パターンを発見し、次元を削減すると同時に、根底にある意味的関係を捕捉する。
TF-IDFの課題とBM25の対処法
TF-IDFは長い間、用語の関連性に基づく情報検索手法として普及してきたが、いくつかの大きな課題がある。ベストマッチング25(BM25)は基本的にTF-IDFの拡張であり、これらの問題に対処することで従来のTF-IDFを改善することができる。
以下に、TF-IDFの主な課題と、BM25がどのようにこれらの問題を解決できるかを示す。
1.用語頻度の重み付け:** TF-IDFでは、用語頻度(TF)は文書中の用語の重要度を測定する。しかし、文書の長さは結果を歪める可能性がある。長い文書は、当然、特定の用語の出現頻度が高くなる。BM25では、用語頻度に対数スケーリング係数を使用することで、この問題に対処している。
2.逆文書頻度:TF-IDFは逆文書頻度(IDF)を使用して、コーパス全体で頻出する用語の重みを減らす。しかし、IDFは外れ値の影響を受けやすく、用語の希少性を必ずしも効果的に捉えることができない。BM25では、IDFの推定に確率モデルを使用することで、この問題に対処している。このモデルはよりロバストで、さまざまな用語の分布によりよく適応する。
3.文書の長さの正規化: TF-IDFでは、用語の頻度が高いため、長い文書ほど一致する用語のスコアが高くなる傾向がある。このため、検索結果が長い文書に偏る可能性がある。BM25は、文書の長さに基づいてTF成分を調整する文書長正規化を組み込んでいるため、長い文書への偏りが緩和される。
4.パラメータの調整: TF-IDFには調整するパラメータはそれほど多くありませんが、IDFの平滑化と正規化の最適値を選択するのは難しく、ドメインの知識が必要になる場合があります。BM25では、BM25固有のパラメータk1やbなどの追加パラメータを導入しており、特定のデータセットやアプリケーションに対して検索性能を最適化するようにチューニングすることができる。
5.スケーラビリティ:* TF-IDFは比較的シンプルで計算効率が高いが、大規模な文書コレクションやリアルタイムの検索システムにはうまくスケールしない可能性がある。BM25は、特に転置インデックスのような効率的なインデックス構造で実装された場合、大規模な検索アプリケーションにおいて、よりスケーラブルで高性能になる可能性がある。
6.**TF-IDFはデータ中のノイズや異常値に対して敏感で、最適な検索結果が得られないことがある。BM25の確率的アプローチは、用語の絶対的な出現頻度ではなく、相対的な出現頻度に注目するため、ノイズの多いデータや異常値に対してより頑健である。
BM25のコンセプトとメカニズム、そしてMilvusベクトルデータベースでの実装方法については、ブログをご参照ください:Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvusをご参照ください。
結論
本稿では、TF-IDF(Term Frequency-Inverse Document Frequency)の意義とその応用、特にMilvusのようなベクトルデータベースの機能強化について検討した。TF-IDFがテキスト分析においていかに重要なツールであるか、コーパスに対する文書中の単語の重要性を定量的に把握する方法を提供することについて述べた。これは検索エンジン、文書分類、情報検索などのアプリケーションにおいて特に有益である。
Scikit-learnのようなライブラリを使ってTF-IDFベクトルを作成し、操作する。これらのベクトルをMilvusのようなベクトルデータベースに統合し、テキストの類似性に基づく効率的で意味のある検索結果を容易にするために、どのように保存、索引付け、クエリを行うことができるかを強調しました。
さらに、基本的なTF-IDFモデルを強化するための、非線形TFスケーリングや正規化技術などのバリエーションを含む、高度なトピックについても触れた。また、Word EmbeddingsのようなTF-IDFの代替案についても、プロジェクトの特定のニーズに応じて、異なるシナリオにおける潜在的な代替または補完として議論しました。
この記事では、自然言語処理(NLP)の分野におけるTF-IDFの適応性と永続的な関連性が強調された。NLPが進化し続ける中、TF-IDFとその亜種の探求と実験は、テキスト・データを効果的に活用しようとする人々にとって不可欠であり続ける。洗練された NLP アプリケーションを開発している場合でも、テキスト分析を始めたばかりの場合でも、ここで説明する原理とテクニックは、さらなる革新と研究のための強固な基盤となります。
参考文献
1.Langchain Milvusの統合 (https://python.langchain.com/docs/integrations/retrievers/self_query/milvus_self_query/)
2.情報検索入門 (https://nlp.stanford.edu/IR-book/)