




コンピュータ・ビジョンとは?
コンピュータ・ビジョンは人工知能の一分野であり、機械が人間と同じように世界から視覚情報を取り込み、解釈することを可能にする。
シリーズ全体を読む
- Cross-Entropy Loss: Unraveling its Role in Machine Learning
- Batch vs. Layer Normalization - Unlocking Efficiency in Neural Networks
- Empowering AI and Machine Learning with Vector Databases
- Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
- Vector Databases: Redefining the Future of Search Technology
- Local Sensitivity Hashing (L.S.H.): A Comprehensive Guide
- Optimizing AI: A Guide to Stable Diffusion and Efficient Caching Strategies
- Nemo Guardrails: Elevating AI Safety and Reliability
- Data Modeling Techniques Optimized for Vector Databases
- Demystifying Color Histograms: A Guide to Image Processing and Analysis
- Exploring BGE-M3: The Future of Information Retrieval with Milvus
- Mastering BM25: A Deep Dive into the Algorithm and Its Application in Milvus
- TF-IDF - Understanding Term Frequency-Inverse Document Frequency in NLP
- Understanding Regularization in Neural Networks
- A Beginner's Guide to Understanding Vision Transformers (ViT)
- Understanding DETR: End-to-end Object Detection with Transformers
- Vector Database vs Graph Database
- What is Computer Vision?
- Deep Residual Learning for Image Recognition
- Decoding Transformer Models: A Study of Their Architecture and Underlying Principles
- What is Object Detection? A Comprehensive Guide
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Algorithmic)
- The Evolution of Multi-Agent Systems: From Early Neural Networks to Modern Distributed Learning (Methodological)
- Understanding CoCa: Advancing Image-Text Foundation Models with Contrastive Captioners
- Florence: An Advanced Foundation Model for Computer Vision by Microsoft
- The Potential Transformer Replacement: Mamba
- ALIGN Explained: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
#はじめに
コンピュータ・ビジョンは人工知能の一分野であり、機械が人間のように世界から視覚情報を取り込み、解釈することを可能にする。コンピュータ・ビジョンは、物体を認識し、情景を理解し、視覚データを分析した後に判断を下す人間の視覚システムを自動化することを目的としている。
過去20年間で、カメラ技術の進歩、計算資源の増加、大量のデータの利用可能性のおかげで、コンピュータビジョンのアプリケーションは劇的に増加した。医療分野では、脳腫瘍や乳がんなどの致命的な病気の早期発見に役立っている。自動車分野では、自動運転車が物体を認識し、道路状況を把握するのに役立っている。製造業では自動化された品質管理の恩恵を受け、小売業では在庫管理やパーソナライズされたショッピング体験にコンピューター・ビジョンが活用されている。コンピュータ・ビジョンの多様な応用により、様々な分野で効率が向上し、技術革新が促進され、世界に大きな利益をもたらしている。
コンピュータビジョンとは?
コンピュータ・ビジョンは、人間が現実世界のビジュアルを見たり、分析したり、解釈したりする能力をコンピュータに与えます。例えば、写真に写っているのが犬なのか猫なのかを識別したり、プレイされているスポーツがホッケーなのかクリケットなのかをビデオから認識したりすることをコンピューターに教えることを想像してみてください。面白そうだろう?
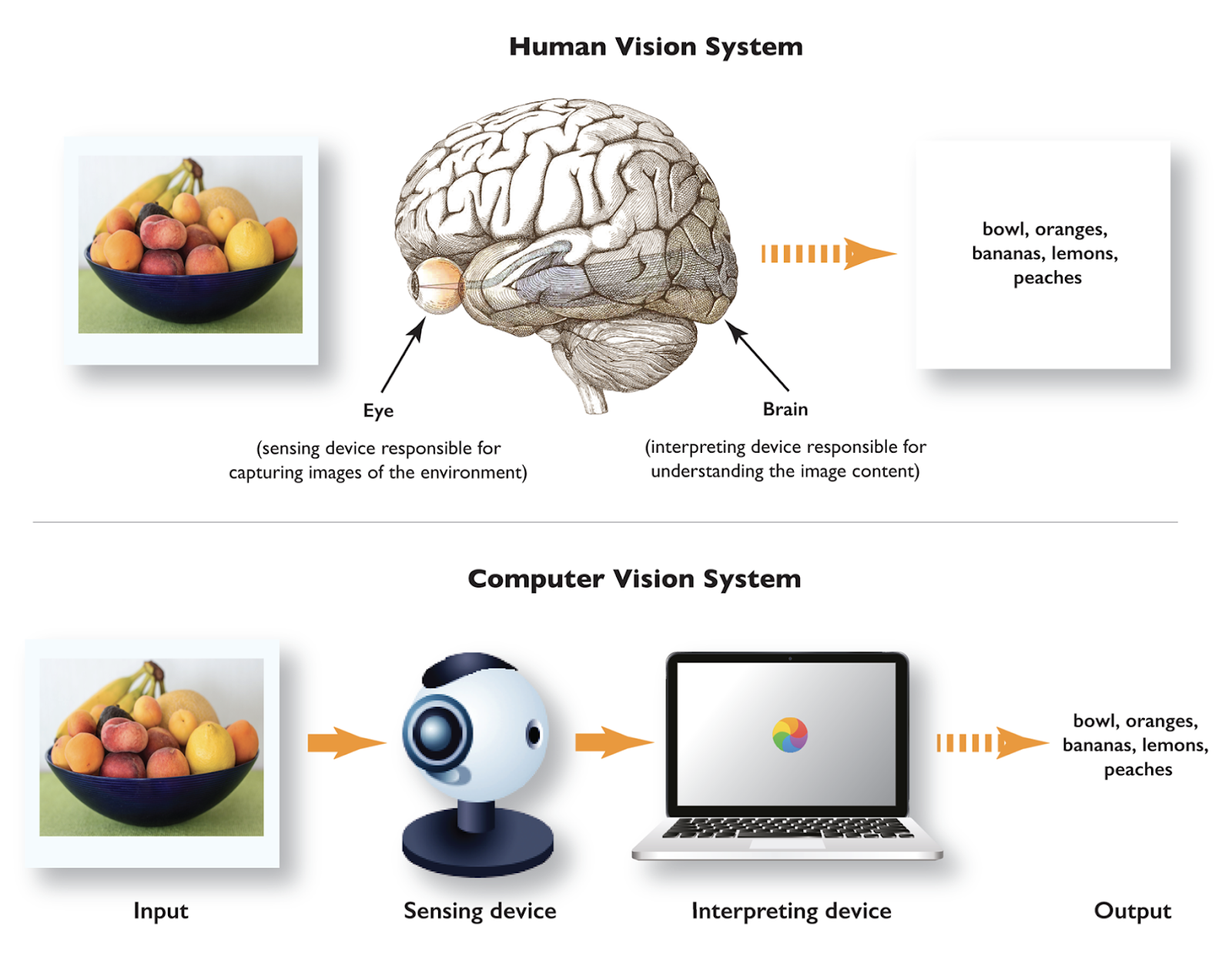 コンピュータ・ビジョンとは.png
コンピュータ・ビジョンとは.png
コンピュータ・ビジョンとは?(Source)
私たちの日常生活では、コンピュータ・ビジョンを利用したアプリケーションが頻繁に使われている。そのひとつが、スマートフォンの顔認証だ。顔IDの設定中にあなたの顔がスキャンされると、アルゴリズムはあなたの顔のキーポイントを検出し、将来の使用のために情報を保存します。もうひとつの例は、Snapchatのフィルターで、自分の顔に犬の耳や面白い帽子を追加することができる。さらに、ビジュアル検索を使えば、ユーザーがeコマースサイトでオンラインショッピングをしているときに気に入った商品の写真をアップロードすれば、システムが類似商品を探してくれる。このように、コンピューター・ビジョンはすでに私たちの日常業務に不可欠な役割を果たしている。
コンピュータビジョンの仕組み
コンピュータ・ビジョン・アルゴリズムの基本的な動作には、以下のようにいくつかの段階があります。
画像取得**-最初のステップは、カメラやセンサーなどのデバイスで画像やビデオをキャプチャして取得することです。このデータは生データであり、次の前処理ステップへの入力となる。
データの前処理***-生データは、不要なノイズを除去し、画質を向上させ、さらなる分析に適するように前処理を受けます。
特徴抽出**-処理されたデータは、画像から特徴(パターン)を抽出するコンピュータビジョンアルゴリズムに渡されます。初期の特徴としては、エッジ、形状、テクスチャなどがある。さらにアルゴリズムを繰り返すことで、より高度な特徴を検出できるようになります。
高レベルの理解**-プロセスの最終段階は高レベルの理解である。ここで、抽出された特徴は画像を解釈するための推論にかけられる。出力は、分類、 検出、または別のタスクなど、実行された特定のタスクに基づいている。
コンピュータビジョンにおけるタスク
- 画像分類***-画像分類は画像をいくつかの定義済みのカテゴリー/クラスに分類する。モデルは画像とそのラベルを入力するので、これは教師ありタスクである。例えば、花を認識するように訓練された画像分類アルゴリズムは、「ひまわり」、「パンジー」、「水仙」などの画像を分類することができます。
 花の画像分類.png
花の画像分類.png
花の画像分類 (出典)
- 物体検出**-物体検出は、画像にどのような物体が写っているかを識別し、位置を特定します。このモデルは、検出する物体のタイプ(クラス)とその座標とともに、画像という入力を必要とする。つまり、単に画像に犬と猫が写っていると言う代わりに、物体検出はそれらが画像内のどこにあるかを示します。また、このアルゴリズムは複数の物体を同時に検出することもできる。
 動物の物体検出.png
動物の物体検出.png
動物の物体検出 (ソース)
- セマンティック・セグメンテーション**-セマンティック・セグメンテーションは、画像内の各ピクセルに特定のクラスをラベル付けする。物体の周りのバウンディングボックスに注目する物体検出とは異なり、セマンティックセグメンテーションはシーンの詳細な理解を提供する。たとえば、自律走行の場合、車線、歩道、障害物の境界を示すバウンディングボックスだけでは不十分な場合がある。
自律走行のためのセマンティック・セグメンテーション.png](https://assets.zilliz.com/Semantic_Segmentation_for_Autonomous_Driving_f3c4d7c44d.png)
自律走行のためのセマンティック・セグメンテーション (出典)
- インスタンスセグメンテーション**-インスタンスセグメンテーションは、同じオブジェクトクラスの複数のインスタンスを区別するセマンティックセグメンテーションの拡張である。例えば、複数の自動車がある画像では、インスタンスセグメンテーションは、すべての自動車にラベルを付けるだけでなく、個々の自動車を区別し、それぞれに固有のラベルを割り当てる。
 車のインスタンスセグメンテーション.png
車のインスタンスセグメンテーション.png
車のインスタンスセグメンテーション (ソース)
- キーポイント検出**-キーポイント検出は、箱の角や人体の関節など、オブジェクト内の特定の注目点を識別します。この技術は、目、鼻、口のような主要な顔の特徴を検出することが正確な識別に必要な、顔認識のようなアプリケーションでよく使用されます。この技術は、キーポイントが物体を定義し、その軌跡を監視することができる物体追跡にも使用することができます。
 顔認識のためのキーポイント検出.png
顔認識のためのキーポイント検出.png
顔認識のためのキーポイント検出 (出典)
コンピュータビジョンの技術とモデル
**ディープラーニングにおけるコンピュータビジョンモデルとは、画像や動画などのビジュアルデータを処理・分析するために設計されたアルゴリズムのことである。最も一般的なコンピュータビジョンモデルをいくつか見てみましょう。
畳み込みニューラルネットワーク(CNN)
90年代後半に発表された畳み込みニューラルネットワーク (CNNs)は、画像分類と特徴抽出に革命をもたらした深層学習における最も人気のあるコンピュータビジョンモデルの1つです。CNNは、入力画像に畳み込みフィルタを適用することで動作し、色やエッジなどの単純な特徴から階層的に特徴を抽出することで、後続の層でより大きな要素を識別し、対象物の識別につなげる。
畳み込みニューラルネットワーク・アーキテクチャ (出典)
物体検出モデル
様々な物体検出モデルが市場に出回っているが、計算効率、リアルタイム解析、精度によって異なる。以下は最も一般的に使用されているものである。
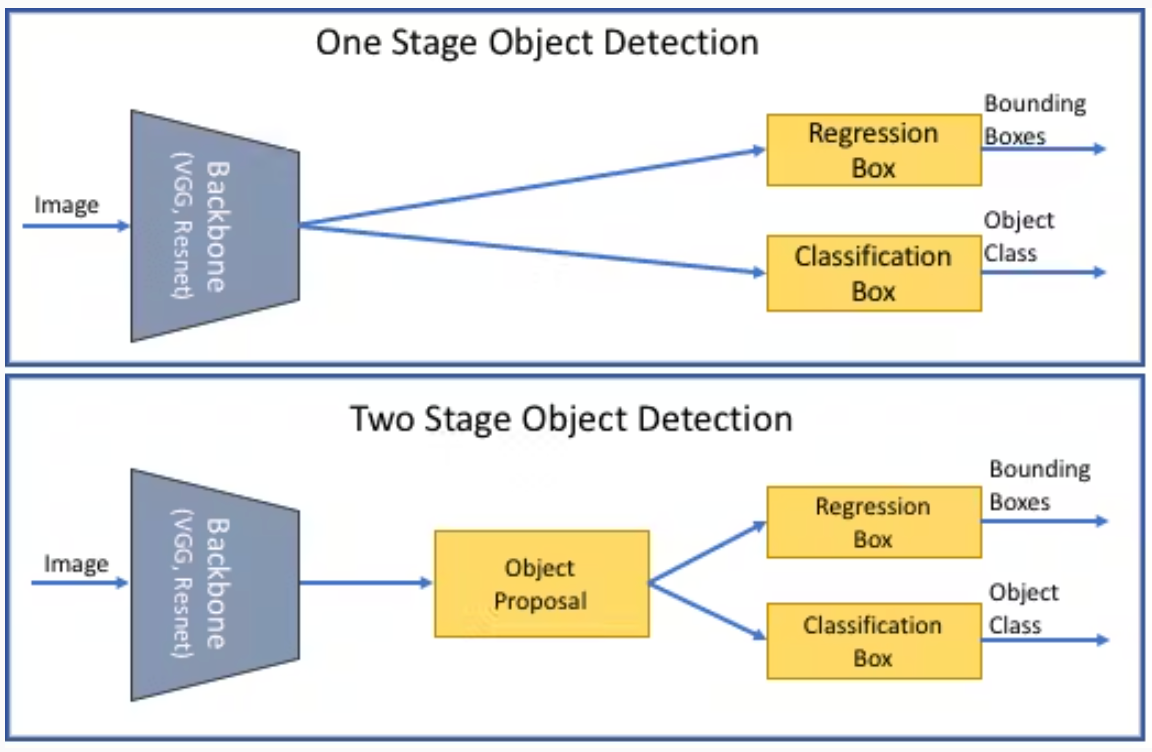 1段階と2段階の物体検出の違い.png
1段階と2段階の物体検出の違い.png
1段階と2段階の物体検出の違い (出典)
YOLO (You Only Look Once)- YOLOは画像全体をシングルパスで処理し、同時にバウンディングボックスとクラス確率を予測します。このアプローチにより、YOLOは非常に高速になり、自律運転のようなリアルタイムアプリケーションに適している。しかし、その速度は、特に小さいオブジェクトや密集したオブジェクトの場合、精度を犠牲にすることがある。
より高速なR-CNN-より高速なR-CNNは2段階の検出器であり、領域提案を生成し、次にこれらの提案を改良して物体の分類と位置特定を行う。2段階のプロセスのため、このモデルはYOLOより遅いが、複雑なシーンで高い精度を達成する。より高速なR-CNNは、速度よりも精度が重要なアプリケーションに最適である。
SSD(シングルショット・マルチボックス検出器)- YOLOと同様、SSDは画像をシングルパスで処理するが、異なるスケールで複数の特徴マップを使用し、様々な大きさの物体を検出する。SSDはFaster R-CNNよりも高速ですが、一般的にYOLOよりも精度が高いため、効率性と信頼性の両方が求められるシナリオに適しています。
RetinaNet-RetinaNetは、YOLOやSSDのような1段検出器であるが、新しい焦点損失関数によってクラス不均衡の課題に対処している。このアプローチは、乱雑な環境における小さな物体の検出に特に効果的です。RetinaNetは速度と精度のバランスに優れています。
画像分割モデル
画像セグメンテーションモデルは、画像をセグメントに分割し、それぞれが画像内で予測される所定のオブジェ クトクラスに対応する。画像セグメンテーションモデルには、主に3つのタイプがある。
意味的セグメンテーション(Semantic Segmentation)*** 画像の各画素にクラスラベルが割り当てられる。
インスタンス・セグメンテーション(Instance Segmentation)***-各画素にラベルを付け、同じオブジェクトクラスの異なるインスタンスを区別する。
パノプティックセグメンテーション(Panoptic Segmentation)***-この手法は、セマンティックセグメンテーションとインスタンスセグメンテーションを組み合わせたものである。各ピクセルが分類され、該当する場合はインスタンスIDが割り当てられる。
一般的な画像セグメンテーションモデルには、U-Net、FCNs、Mask R-CNN、DeepLabなどがある。
生成モデル
入力データに基づいてラベルやクラスを予測することに重点を置く識別モデルとは異なり、生成モデルはデータの根本的な分布を理解し捉えることを目的としており、元のデータに類似した新しいサンプルを作成することができる。一般的な生成モデルには、Generative Adversarial Networks (GANs)、Variational Autoencoders (VAEs)、Autoregressive models、Flow-based modelsなどがある。これらのモデルは、画像合成(リアルな画像の作成)、超解像(画質の向上)、スタイル転送(画像に芸術的なスタイルを適用)、データ増強(追加学習データの生成)などに応用できる。
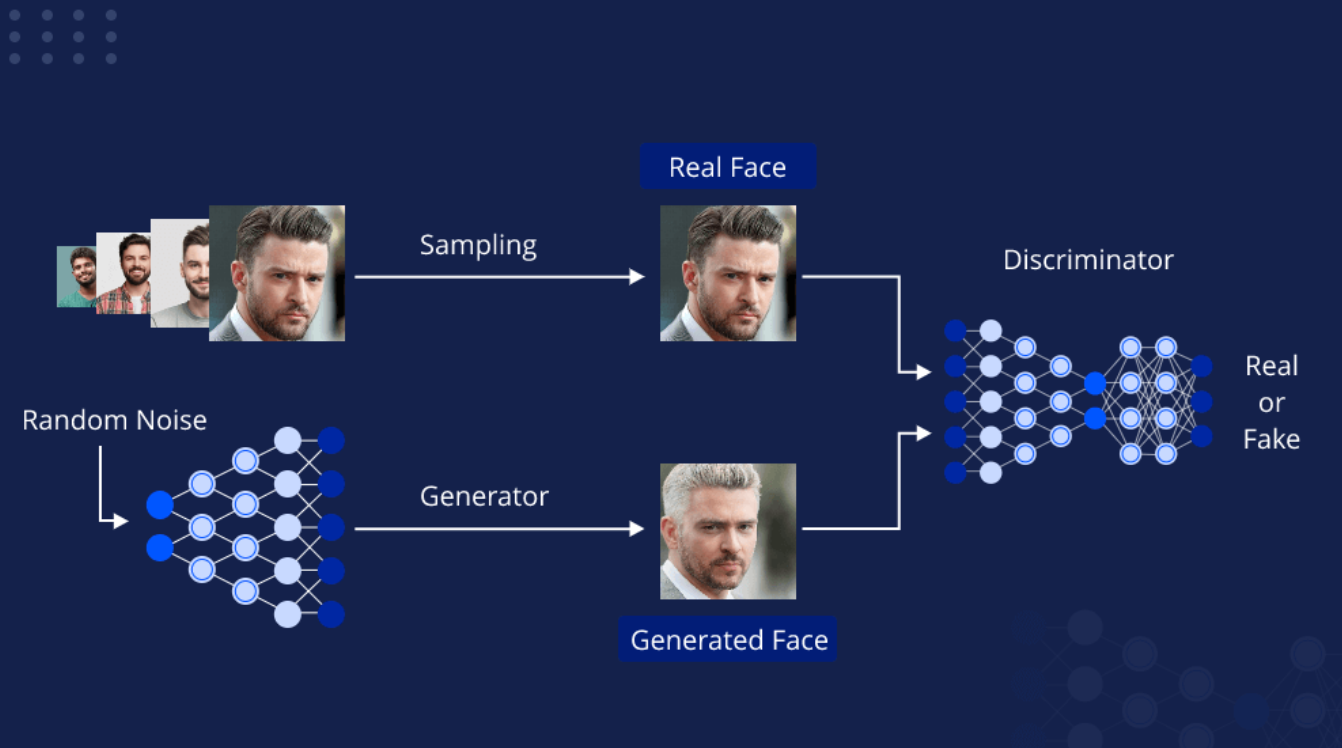 GANの基本パイプライン.png
GANの基本パイプライン.png
GANの基本パイプライン (出典)
特徴抽出モデル
特徴抽出モデルは、あらゆるコンピュータビジョンパイプラインのバックボーンである。これらのモデルは、入力データの本質的な特徴(特徴)を捕捉し、その後の下流のコンピュータビジョンタスク処理に役立てます。特徴抽出モデルは、入力データの次元を減らし、関連情報を強化し、システムをより堅牢にします。一般的な従来の特徴抽出手法には、SIFT (Scale-Invariant Feature Transform)、SURF (Speeded-Up Robust Features)、HOG (Histogram of Oriented Gradients)などがあります。これらのモデルは手動でのチューニングが必要で、複雑なパターンを捉えることができなかったが、CNNのような深層学習モデルが登場した。現在、限られたデータで新しいタスクの特徴を抽出するために、VGGNet、ResNet、Inceptionのような事前に訓練されたCNNモデルを、新しいデータセットでの微調整のために活用することができる。
オブジェクト追跡モデル
オブジェクト追跡モデルは、ビデオフレームを移動するオブジェクトを監視し、追跡します。これらのモデルは継続的にオブジェクトの位置を更新し、外観、スケール、背景の変化にもかかわらず、時間経過とともにその同一性を維持します。通常、オブジェクト検出フェーズから始まり、最初のフレームでオブジェクトが識別されます。その後、トラッキングモデルは、後続のフレームにおけるオブジェクトの位置を予測し、多くの場合、オプティカルフロー、カルマンフィルター、またはディープラーニングベースのトラッカーのような技術を使用します。これらのモデルは、監視、自律走行車、スポーツ分析、拡張現実などに適用可能である。
3Dビジョンモデル
3Dビジョン・モデルとは、2次元の画像やビデオから3次元構造を解釈・再構成するアルゴリズムである。これらのモデルにより、機械は奥行き、形状、空間的関係を認識できるようになり、3次元の世界を理解できるようになる。ステレオビジョン(異なる角度からの2つ以上の画像を組み合わせる)、動きからの構造(動画内の動きの手がかりから3D構造を推測する)、奥行き推定(カメラからの物体の距離を予測する)などの技術を使用する。3Dビジョンモデルの応用例としては、自律走行車、ロボット工学、拡張現実(AR)、医療画像などがある。
 シンプルな3Dビジョンモデルの可視化.png
シンプルな3Dビジョンモデルの可視化.png
単純な3Dビジョンモデルの視覚化 (ソース)
視覚トランスフォーマー
ヴィジョン・トランスフォーマー(ViTs)は、もともと自然言語処理(NLP)用に設計されたトランスフォーマーアーキテクチャを画像解析に応用したものである。従来のCNNとは異なり、ViTは画像をパッチのシーケンスとして処理し、各パッチを文中の単語と同様に扱う。画像を固定サイズのパッチに分割して平坦化し、それらをベクトルに線形に埋め込む。これらのベクトルは、位置エンコーディングとともに、標準的な変換モデルに供給される。ViTモデルは、CNNと比較して、コンピュータビジョンのタスクで顕著な性能を示しており、その結果、現在最先端のモデルとなっている。ViTモデルには主に3つのタイプがある:標準的なViT、ハイブリッドモデル(CNNと変換器を組み合わせたもの)、DeiT(Data-efficient Image Transformers)であり、より少ない学習データで高い性能を達成できる。
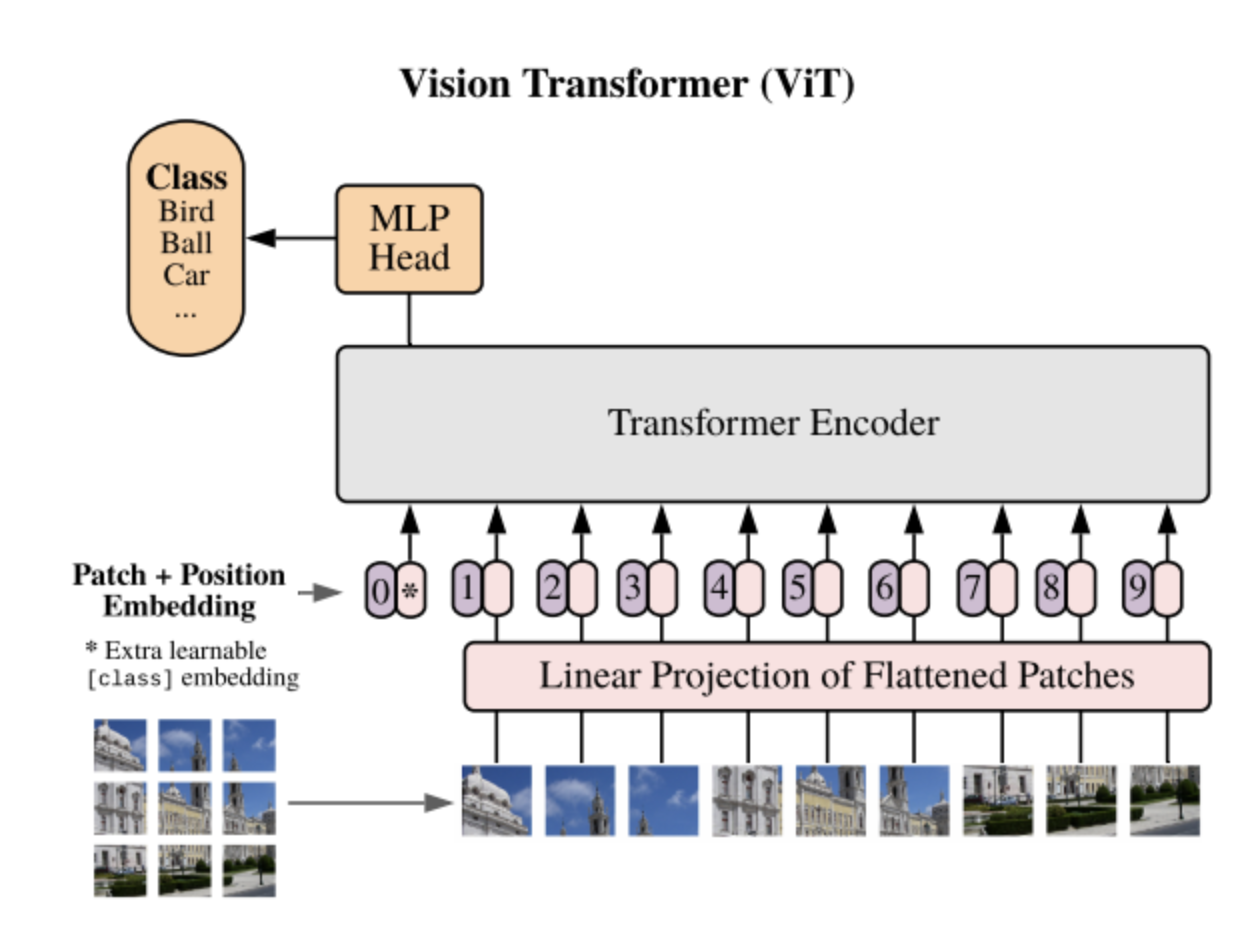 ViTアーキテクチャ.png
ViTアーキテクチャ.png
ViTアーキテクチャ (出典)
視覚変換器とベクトルデータベースによる効率的な画像検索
効率的な画像検索には、膨大なデータセットの中からクエリ画像に似た画像を見つけることが必要です。このプロセスは、ビジュアル検索エンジン、デジタル資産管理、コンテンツ推薦システムなどのアプリケーションにとって極めて重要です。
MilvusやZilliz Cloudのようなベクトルデータベース(フルマネージドMilvus)は、高度なコンピュータビジョンモデルを使用して画像から抽出された特徴の数値表現である高次元ベクトルとして画像を格納することにより、この画像検索プロセスにおいて重要な役割を果たします。これらのベクトルは画像の本質的な特徴を捉えており、データベースは高次元空間におけるベクトル間の距離を比較することで、類似画像を効率的に検索することができる。
ヴィジョン・トランスフォーマー(ViTs)は、画像をパッチに分割し、これらのパッチ間の大域的な関係を捕捉するために自己注意メカニズムを使用することによって、このプロセスを強化する。処理後、ViTsは画像全体を表す特徴ベクトルを出力する。画像がシステムに入力されると、ViTはその特徴ベクトルを生成し、ベクトル・データベースに格納する。
類似画像を検索するには、クエリ画像をViTで処理して特徴ベクトルを生成する。次に、ベクトルデータベースは、このクエリベクトルと、保存されているすべての画像のベクトルとを比較し、ベクトル空間における近接性に基づいて、最も類似した画像を検索する。このアプローチは、ViTの強力な特徴抽出機能を活用することで、大規模なデータセットであっても、高精度で効率的な画像検索を実現する。
ViTsとベクトルデータベースを組み合わせることで、企業はより高速で正確な画像検索機能を実現し、業界を問わずさまざまな画像ベースのアプリケーションのパフォーマンスを大幅に向上させることができます。
要約
コンピュータビジョンは、機械が世界からの視覚情報を解釈し理解することを可能にする変革的な分野である。コンピュータビジョンシステムは、人間の視覚機能を再現し、画像分類、物体検出、画像分割などのタスクを実行することで、様々なプロセスを自動化する。この分野は、CNN、Faster R-CNN、U-Netのような基礎モデルから始まり、大きく発展してきた。今日では、生成モデル、3Dビジョンモデル、Vision Transformers (ViTs)などの高度なアプローチが、視覚データの処理・解析方法を再構築しています。さらに、ViTのような先進的なコンピュータビジョン技術をベクトルデータベースと統合することで、様々な産業に利益をもたらす強力なアプリケーションを引き出すことができます。
推薦図書
ビジョントランスフォーマー(ViT)とは - Zillizブログ](https://zilliz.com/learn/understanding-vision-transformers-vit)
ベクターデータベースとは何か、どのように機能するのか - Zilliz blog](https://zilliz.com/learn/what-is-vector-database)
コンピュータビジョンについて知りたかったことすべて。| イリヤ・ミハイロヴィッチ著|データサイエンスに向けて](https://towardsdatascience.com/everything-you-ever-wanted-to-know-about-computer-vision-heres-a-look-why-it-s-so-awesome-e8a58dfb641e)
効率的な検索拡張世代(RAG)を構築するための3つの重要な戦略を探る - Zilliz blog](https://zilliz.com/blog/exploring-rag-chunking-llms-and-evaluations)
 Yesha Shastri
Yesha ShastriYesha Shastri, Freelance Technical Writer in AI/ML


{kind=link}