




画像認識のための深層残差学習
ディープ残差学習は劣化問題を解決し、ニューラルネットワークを訓練しながら、その性能を向上させることができる。
シリーズ全体を読む
- 交差エントロピー損失:機械学習におけるその役割を解明する
- バッチとレイヤーの正規化 - ニューラルネットワークの効率性を引き出す
- ベクトル・データベースによるAIと機械学習の強化
- ラングチェーンツール先進のツールセットでAI開発に革命を起こす
- ベクターデータベース検索テクノロジーの未来を再定義する
- ローカル感度ハッシング (L.S.H.):包括的ガイド
- AIの最適化:安定した普及と効率的なキャッシュ戦略への手引き
- ネモ・ガードレールAIの安全性と信頼性を高める
- ベクトル・データベースに最適化されたデータ・モデリング技法
- カラーヒストグラムの謎を解く:画像処理と解析の手引き
- BGE-M3を探る:Milvusによる情報検索の未来
- BM25を使いこなす:Milvusにおけるアルゴリズムとその応用を深く掘り下げる
- TF-IDF - NLPにおける項頻度-逆文書頻度の理解
- ニューラルネットワークにおける正則化を理解する
- 初心者のためのヴィジョン・トランスフォーマー(ViT)理解ガイド
- DETRを理解する:トランスフォーマーによるエンドツーエンドのオブジェクト検出
- ベクトル・データベース vs グラフ・データベース
- コンピュータ・ビジョンとは?
- 画像認識のための深層残差学習
- トランスフォーマーモデルの解読:そのアーキテクチャと基本原理の研究
- 物体検出とは?総合ガイド
- マルチエージェントシステムの進化:初期のニューラルネットワークから現代の分散学習まで(アルゴリズム編)
- マルチエージェントシステムの進化:初期のニューラルネットワークから現代の分散学習まで(方法論編)
- CoCaを理解する:コントラスト・キャプションによる画像テキスト・ファウンデーション・モデルの進歩
- フローレンスマイクロソフトによるコンピュータビジョンの高度な基礎モデル
- トランスフォーマーの後継者候補マンバ
- ALIGNの説明ノイジー・テキスト教師による視覚・視覚言語表現学習のスケールアップ
ディープニューラルネットワークの導入は、画像分類、画像認識、物体検出、テキスト分類など、いくつかの分野で多くのブレークスルーをもたらした。これらのブレークスルーの背後にある高レベルの直観は単純である:学習するネットワークが深ければ深いほど、その性能は向上する。残差ネットワークを導入する前は、さまざまな画像分類ベンチマークで最高の性能を発揮するモデルは、非常に深い層のスタックを持つ傾向があった。
ニューラルネットワークの深さが性能向上に不可欠であるように見えるという事実は、疑問を投げかける:**ディープ・ラーニング・モデルの性能を向上させるのは、より多くの層を積み重ねるのと同じくらい単純なことなのだろうか?
より多くの層を積み重ねることが、必ずしも学習性能の向上につながるとは限らないことが判明した。この現象の根本的な原因は、消失勾配問題と、より深いニューラルネットワークは最適化がより複雑であるという事実である。これらの問題を緩和し、学習プロセスを安定させるために導入されたのが残差ネットワークの概念である。この記事では、残差ネットワークについて詳しく説明する。
ディープ・ニューラル・ネットワークにおける消失勾配と劣化問題
多くのベンチマークデータセットで実証されているように、ディープラーニングモデルの性能は、そのアーキテクチャが深くなるほど向上する傾向がある。例えばImageNetデータセットでは、最も優れた性能を持つモデルは16層から30層までの深さを持つ。
この観察から、ニューラルネットワークの性能を向上させたければ、より多くの層を追加すればよいと考えるのは自然である。この仮説を証明する上での主な課題は、学習中に消失勾配が現れることだった。
消失勾配とは、層数の多いニューラルネットワークでよく起こる問題である。これは、勾配が多数の層を通して逆伝播されるにつれて極端に小さくなる現象を指す。ご想像の通り、勾配がゼロに近づけば近づくほど、各層の学習は困難になります。勾配がゼロであれば、レイヤーが学習することは何もない。
バッチ正規化は、消失勾配の問題を解決するためにトレーニング中によく適用される。バッチ正規化のアイデアは、各レイヤーの入力が活性化関数を通過した後、結果の値が大きすぎたり小さすぎたりしないように正規化することです。全体として、バッチ正規化は学習中のモデルの学習と収束を助ける。
バッチ正規化のおかげで、レイヤーを深く積み重ねたニューラルネットワークを収束するまで訓練し、より深いネットワークが常に良いパフォーマンスを発揮するという仮定を検証することができる。しかし、レイヤーを増やしてもパフォーマンスが向上するとは限らないことがわかった。むしろ、ある特定の時点では、レイヤーを増やすとモデルのパフォーマンスが低下し、トレーニングエラーが増加する。
CIFAR-10データセットでのトレーニングの進捗。破線は学習誤差、太線はテスト誤差を示す。.png](https://assets.zilliz.com/Training_progress_on_the_CIFAR_10_dataset_Dashed_lines_denote_training_error_and_bold_lines_denote_testing_error_581ccaf664.png)
20層と56層の標準ネットワークによるCIFAR-10の学習エラー(左)とテストエラー(右) Source._.
この性能低下は、モデルのオーバーフィッティングから来るものではなく、より深いニューラルネットワークは最適化がより難しいという事実から来るものです。深い残差学習は、この劣化問題を解決するために導入された概念であり、深いニューラルネットワークを訓練しながら、潜在的にその性能を向上させることができます。
ディープ残差学習の概念
簡単に言うと、ディープ残差学習とは、残差接続を使ってディープ・ニューラル・ネットワークを訓練することである。残差接続は、ある層の入力を後の層の出力に直接追加することを可能にし、以下の視覚化でわかるように、ネットワークを通る近道経路を作る:
ディープ残差学習におけるショートカット接続。.png](https://assets.zilliz.com/Shortcut_connection_in_deep_residual_learning_5bde09a8df.png)
深い残差学習におけるショートカット接続. ソース._.
では、この残差接続は、ディープ・ニューラル・ネットワークの層間の通常の接続とどう違うのだろうか?標準的なディープ・ニューラル・ネットワークでは、各層の出力が次の層の入力になる:
y=fx.png](https://assets.zilliz.com/y_fx_6b2f6e34f5.png)
ここでyは特定の層の出力を表し、F(x)はその層によって学習された入力から出力へのマッピングである。残差接続では、代わりにこうなる:
y=fx+x.png](https://assets.zilliz.com/y_fx_x_83c8ce2637.png)
ここで、xはマッピング処理なしの元の入力である。つまり、入力xにF(x)とxを足して出力yを生成するショートカットを作成する。
この単純な概念は、勾配の消失や性能劣化の問題を緩和するのに非常に役立つ。残差接続はディープ・ニューラル・ネットワークの最適化を容易にする。同一性マッピングがすでに最適であれば、ネットワークはF(x)をゼロにするだけでよく、ショートカット接続は入力を変更せずに前方に運ぶ。一方、バックプロパゲーションの間、勾配はショートカット接続を直接流れることができ、メインパスで消失する可能性を避けることができる。
このショートカット接続のもう一つの特徴は、F(x) + xの要素ごとの加算がごくわずかであるため、余分なパラメータや計算量を導入しないことである。このため、残差接続の概念は非常に魅力的であり、残差ニューラルネットワークと標準的なニューラルネットワークの性能を簡単に比較することもできる。
次のセクションでは、残差ニューラルネットワークと標準的なニューラルネットワークの性能を比較します。
残差ニューラルネットワークの性能比較
残差ネットワークの性能はImageNetデータセットで評価された。ImageNetデータセットは10,000の異なるクラスを持つ画像分類データセットである。パフォーマンスを比較するために、まず2つの標準的なニューラルネットワークをトレーニングした。
次に、これら2つのモデルの残差ネットワークバージョンも、同じデータセットとセットアップで学習した。以下は34層の標準ネットワークとその残差ネットワークの視覚化である:
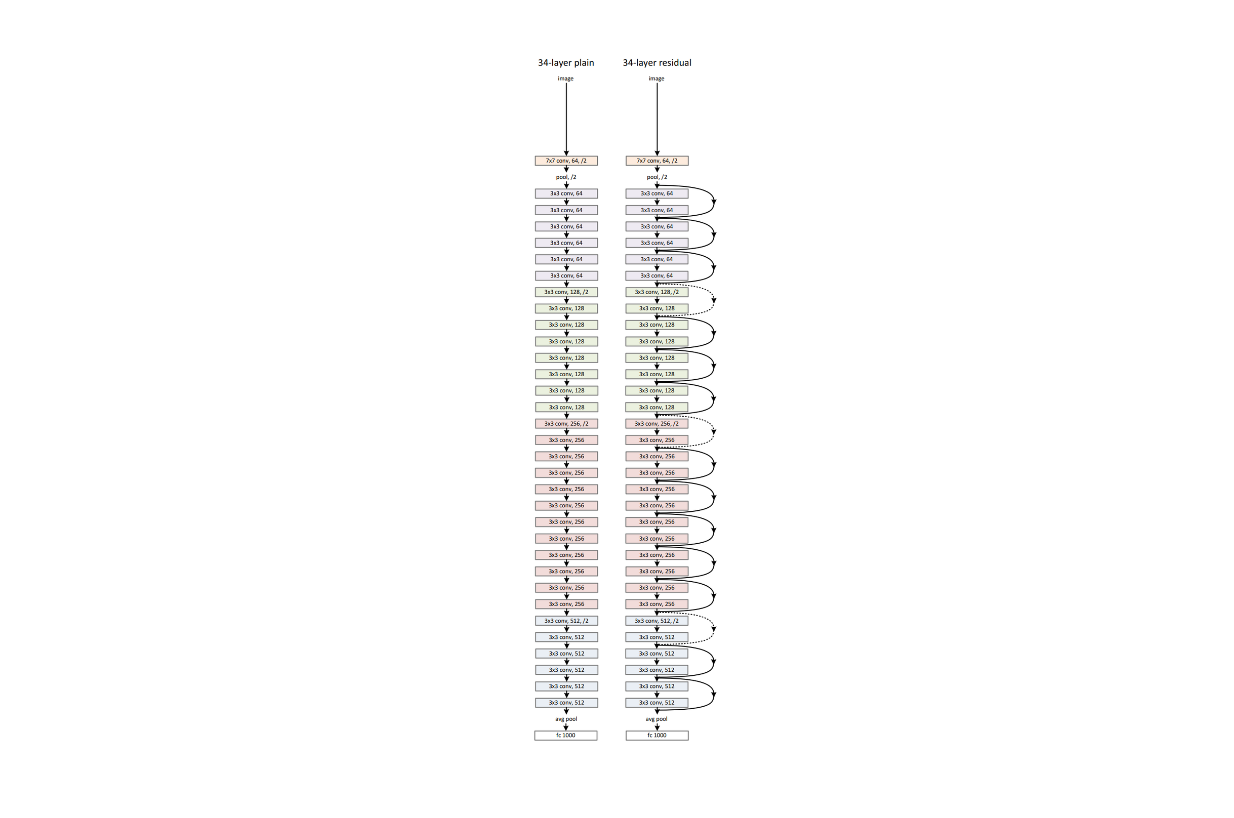 標準ニューラルネットワーク(左)とその残差ネットワーク(右)のネットワーク・アーキテクチャ例.png
標準ニューラルネットワーク(左)とその残差ネットワーク(右)のネットワーク・アーキテクチャ例.png
標準ニューラルネットワークのネットワーク・アーキテクチャ例(左)とその残差版(右) Source._.
ご覧のように、残差ネットワークには層間にいくつかのショートカット接続があります。これらのショートカット接続は、モデル学習中に余分なパラメータや計算の複雑さをもたらすことはありません。
標準的なニューラルネットワークの学習結果を見ると、下の可視化に示されているように、34層のネットワークは18層のネットワークよりも学習手順全体を通して学習誤差が大きいことがわかります。これは前節で説明した性能劣化の一例である。層数の多いネットワークは、浅いモデルに比べて収束率が低く、最適化が難しいため、学習誤差が大きくなると推測される。
CIFAR-10における20層と56層の標準ネットワークの学習誤差(左)とテスト誤差(右).png](https://assets.zilliz.com/Training_error_left_and_test_error_right_on_CIFAR_10_with_20_layer_and_56_layer_standard_networks_532fc4576c.png)
CIFAR-10における20層と56層の標準ネットワークによる学習。細い曲線が学習誤差、太い曲線が検証誤差を示す Source._.
さて、残差ネットワークの学習結果を見ると、34層のネットワークが18層のネットワークを上回っている。34層のネットワークは学習誤差が小さいだけでなく、検証誤差も一貫して小さく、このモデルの結果が一般化可能であることを示している。このことは、残差ネットワークに導入されたショートカット接続が、ディープ・ニューラル・ネットワークで一般的に発生する性能劣化の問題を緩和するのに非常に有効であることを示している。
上の可視化を検証すると、18層の残差ネットワークは34層のものよりも早く収束していることがわかる。これは、層が浅いモデルでは、ショートカット接続が初期段階で収束を早めることで、最適化プロセスを緩和することを示している。残差ネットワークの性能をさらに評価するために、より深いモデルを構築した。具体的には、50層、101層、152層の3つの残差ネットワークを構築した。
これらのより深いネットワークにおいてショートカット接続をより効率的にするために、その配置を変更した。つの層のスタックの間に配置する代わりに、ボトルネックデザインを模倣した3つの畳み込み層の間に配置した。ボトルネック設計と呼ばれるのは、3つの層が1x1、3x3、1x1の畳み込みを持っているからだ。注目すべき点は、152層の残差モデルの深さはVGG19より大きいが、その複雑さはより低いことだ(113億FLOPs対196億FLOPs)。
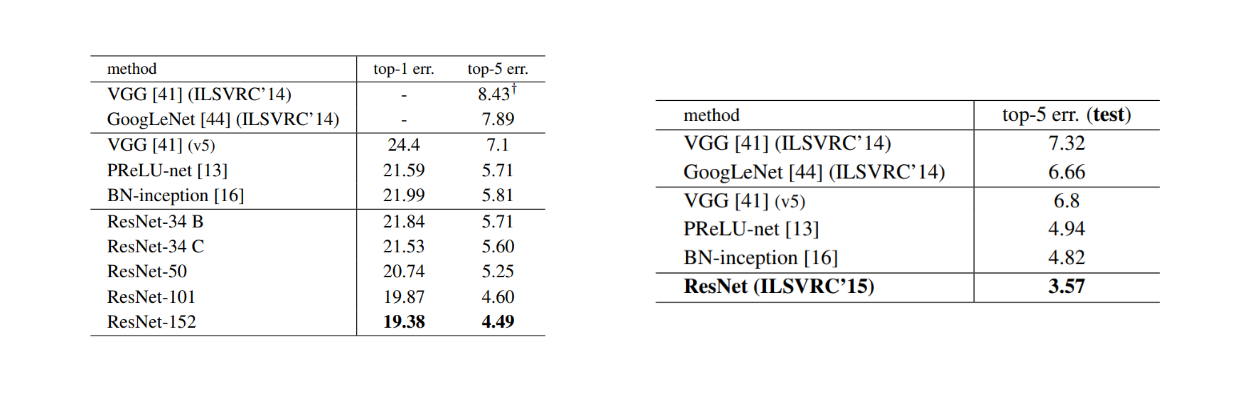 単一モデルの結果(左)とアンサンブル(右)のエラー率(%).png
単一モデルの結果(左)とアンサンブル(右)のエラー率(%).png
単一モデルの結果(左)とアンサンブル(右)のエラー率(%) ソース._.
ご覧のように、これらのショートカット接続により、モデルの深さが増すにつれて性能向上を享受することができます。検証ImageNetデータでの誤差は、152層の最も深いモデルが、VGG、GoogLeNet、PReLU-netのような他の残差ネットワークのバリエーションや最先端のモデルよりも優れていることを示しています。
この残差手法は、ImageNetデータセットだけでなく、異なるデータセットや機械学習のユースケースにおいても一貫した性能を示す。以下の視覚化では、残差ネットワークは、CIFARデータセットでより低い訓練誤差と検証誤差を記録することで、訓練プロセス全体を通して標準的な対応モデルを上回っています。
ImageNetにおける学習の進捗。細い曲線は訓練誤差、太い曲線は検証誤差を示す。.png](https://assets.zilliz.com/Training_progress_on_Image_Net_Thin_curves_denote_training_error_and_bold_curves_denote_validation_error_1ce5bd9b05.png)
CIFAR-10データセットにおける学習の進捗。破線は訓練誤差、太線はテスト誤差を表す。 Source._.
物体検出タスクにおいても、残差ネットワークはPASCALとMS COCOの両データセットにおいて、VGGのような最先端モデルを凌駕している。下の表に示すように、残差ネットワークの平均平均精度(mAP)はVGGよりも高い。
 PASCALのVOCデータセット(左)とCOCOデータセット(右)における物体検出のmAP(%).png
PASCALのVOCデータセット(左)とCOCOデータセット(右)における物体検出のmAP(%).png
PASCAL VOC(左)とCOCOデータセット(右)の物体検出mAP(%). Source._.
さまざまなデータセットにおける残差ネットワークの一貫した性能と柔軟性は、コンピュータビジョンのタスクだけでなく、Transformersのような有名なアーキテクチャに残差の概念が見られる自然言語のタスクにも適応されるようになりました。
残差ネットワークの実装
このセクションでは、残差ネットワークが画像分類のユースケースにどのように使用できるかを見ていきます。訓練済みの残差ネットワークをロードして、それを使って画像のクラスを予測します。
PyTorchの torchvision ライブラリを使って、以下のコードで事前に学習した残差ネットワークをロードすることができます:
インポートトーチ
from torchvision import models, transforms
from PIL import Image
インポートリクエスト
from io import BytesIO
# 学習済みのResNetモデルをダウンロードしてロードする。
model = models.resnet50(pretrained=True)
model.eval()
上記のコードでは、50層で事前にトレーニングされた残差ネットワークをロードしている。しかし、101層や152層、あるいは34層や18層など、より多くの層を持つネットワークをロードすることもできます。
次に、ImageNetデータセットで利用可能な10,000のクラスのいずれかに画像を予測したいので、モデルの予測から予測されたクラスの実際の名前へのマッピングとして、これらの10,000のクラスの名前もロードする必要があります。
# ImageNetのクラスラベルをダウンロードする
labels_url = "<https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt>"
response = requests.get(LABELS_URL)
labels = [line.strip() for line in response.text.splitlines()](行の分割)
print(labels)
"""
出力:
出力: ['テンチ', '金魚', 'ホオジロザメ', 'イタチザメ', 'シュモクザメ', '電気エイ', 'エイ', ......] ]。
"""
残差ネットワークを使って画像を予測する前に、画像を変換する必要があります。このステップでは、画像を訓練データと同じ次元にリサイズし、訓練データから収集した平均と標準偏差に従って正規化します。
ImageNetの学習データは256 x 256の画像サイズである。一方、平均と標準偏差はそれぞれ[0.485, 0.456, 0.406]と[0.229, 0.224, 0.225]です。これらの変換を一度に行うこともできます。
transform = transforms.Compose([)
transforms.Resize(256)、
transforms.CenterCrop(224)、
transforms.ToTensor()、
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])、
])
下の可視化のように、トラ猫の画像を予測してみる。
image_url = "<https://upload.wikimedia.org/wikipedia/commons/thumb/3/3a/Cat03.jpg/1200px-Cat03.jpg>"
 テスト画像. .png
テスト画像. .png
テスト画像._
画像を予測する前の最後のステップは、予測関数を作成することです。この関数は画像を入力として受け取ります。そして、上で書いたコードで画像を変換し、予測値を得るためにモデルを呼び出し、予測値をImageNetで利用可能なクラスの1つにマッピングします。
def predict(image_url):
response = requests.get(image_url)
img = Image.open(BytesIO(response.content))
img_t = transform(img)
batch_t = torch.unsqueeze(img_t, 0)
with torch.no_grad():
出力 = model(batch_t)
_, predicted_idx = torch.max(output, 1)
predicted_label = labels[predicted_idx.item()].
return predicted_label
では、この関数を呼び出して画像を予測してみよう。
prediction = predict(image_url)
print(f "The image is predicted to be: {prediction}")
"""
出力
画像は次のように予測されます:トラ猫
"""
結論
ディープ残差学習を導入することで、ディープ・ニューラル・ネットワークでよく起こる勾配の消失や性能低下に関する問題を解決することができた。ある層の入力を後の層の出力に直接加えることができるショートカット接続を導入することで、より深いネットワークを性能向上とともに訓練することができる。このようなショートカット接続により、計算の複雑さや余分なパラメータを増やすことなく、ディープネットワークの最適化と効率的な学習が容易になります。
また、残差ネットワークは汎用性が高く、画像分類、物体検出、物体位置特定など、多くの機械学習のユースケースで実装されている。残差結合の概念は、コンピュータビジョンのタスクで成功を収めているだけでなく、自然言語処理などの深層学習の他の分野にも適応されており、トランスフォーマーのようなアーキテクチャに組み込まれている。
その他のリソース
ベクトルデータベースとは何か、どのように機能するか](https://zilliz.com/learn/what-is-vector-database)
RAGとは](https://zilliz.com/learn/Retrieval-Augmented-Generation)
ジェネレーティブAIリソースハブ|Zilliz](https://zilliz.com/learn/generative-ai)
あなたのGenAIアプリのためのトップパフォーマンスAIモデル|Zilliz](https://zilliz.com/ai-models)



