




BM25を使いこなす:Milvusにおけるアルゴリズムとその応用を深く掘り下げる
Milvusを使えば、文書とクエリをスパースベクトルに変換するBM25アルゴリズムを簡単に実装できる。そして、これらのスパースベクトルは、特定のクエリに従って最も関連性の高い文書を見つけるためのベクトル検索に使用することができる。
シリーズ全体を読む
- 交差エントロピー損失:機械学習におけるその役割を解明する
- バッチとレイヤーの正規化 - ニューラルネットワークの効率性を引き出す
- ベクトル・データベースによるAIと機械学習の強化
- ラングチェーンツール先進のツールセットでAI開発に革命を起こす
- ベクターデータベース検索テクノロジーの未来を再定義する
- ローカル感度ハッシング (L.S.H.):包括的ガイド
- AIの最適化:安定した普及と効率的なキャッシュ戦略への手引き
- ネモ・ガードレールAIの安全性と信頼性を高める
- ベクトル・データベースに最適化されたデータ・モデリング技法
- カラーヒストグラムの謎を解く:画像処理と解析の手引き
- BGE-M3を探る:Milvusによる情報検索の未来
- BM25を使いこなす:Milvusにおけるアルゴリズムとその応用を深く掘り下げる
- TF-IDF - NLPにおける項頻度-逆文書頻度の理解
- ニューラルネットワークにおける正則化を理解する
- 初心者のためのヴィジョン・トランスフォーマー(ViT)理解ガイド
- DETRを理解する:トランスフォーマーによるエンドツーエンドのオブジェクト検出
- ベクトル・データベース vs グラフ・データベース
- コンピュータ・ビジョンとは?
- 画像認識のための深層残差学習
- トランスフォーマーモデルの解読:そのアーキテクチャと基本原理の研究
- 物体検出とは?総合ガイド
- マルチエージェントシステムの進化:初期のニューラルネットワークから現代の分散学習まで(アルゴリズム編)
- マルチエージェントシステムの進化:初期のニューラルネットワークから現代の分散学習まで(方法論編)
- CoCaを理解する:コントラスト・キャプションによる画像テキスト・ファウンデーション・モデルの進歩
- フローレンスマイクロソフトによるコンピュータビジョンの高度な基礎モデル
- トランスフォーマーの後継者候補マンバ
- ALIGNの説明ノイジー・テキスト教師による視覚・視覚言語表現学習のスケールアップ
情報検索アルゴリズムは、検索エンジンにおいて、ユーザーのクエリに対する検索結果の関連性を保証するために重要である。
特定のトピックに関する研究論文を探すユースケースを想像してほしい。検索エンジンでキーワードとして「RAG」と書いたとき、私たちは明らかに、他の一般的なNLP手法ではなく、さまざまなRAG手法について述べた論文のコレクションを得たいと思う。ここで情報検索アルゴリズムがその役割を果たす。情報検索アルゴリズムは、Milvusのようなベクトルデータベース内で検索効率を最適化する高度な索引付け技術を利用することで、キーワードと関連性の高い論文を確実に取得する。スパースや密ベクトル戦略を含むこれらの技術は、AIアプリケーションのデータ検索性能を向上させ、大規模データセットを効果的に処理します。
さらに、Milvusの検索機能を強化することは、検索操作の効率と精度を向上させるために極めて重要である。AI統合やパラメータチューニングなどの高度な機能と最適化技術は、優れた検索結果に貢献し、システムが複雑なクエリや大規模データセットをより効果的に処理できるようにします。
情報検索によく適用されるアルゴリズムには、TF-IDFとBM25の2つがある。この記事では、BM25について説明します。BM25は基本的にTF-IDFを拡張したものだからだ。
用語頻度-逆文書頻度(TF-IDF)は、統計的手法に基づく情報検索アルゴリズムである。TF-IDFは、文書内のキーワードの重要度を、文書の集合との相対的な関係で測定する。
その名前からわかるように、TF-IDFは2つの要素から構成されている:用語頻度(TF)と逆文書頻度(IDF)である。これらは異なる側面を測定しますが、最終的には2つのコンポーネントを掛け合わせ、文書内の単語の関連性を推定する最終スコアを得ます。
従来のTF-IDFのTF成分は、文書内の特定のキーワードの出現率を測定する。

上の式は非常に直感的である。文書内でキーワードのインスタンスが見つかれば見つかるほど、TF値は高くなる。
一方、IDFコンポーネントは、キーワードを含むコレクションの文書の割合を測定する。言い換えれば、この部分はキーワードがどれだけの文書に含まれているかを示す。

キーワードが文書中に頻繁に出現すればするほど、IDFスコアが低くなることがわかる。これは、'a'、'an'、'is'などの一般的な単語は多くの文書に出現する傾向があるため、ペナルティを課したいからです。
TF成分とIDF成分を計算した後、その結果を掛け合わせ、キーワードの最終的なTF-IDFスコアを得る。
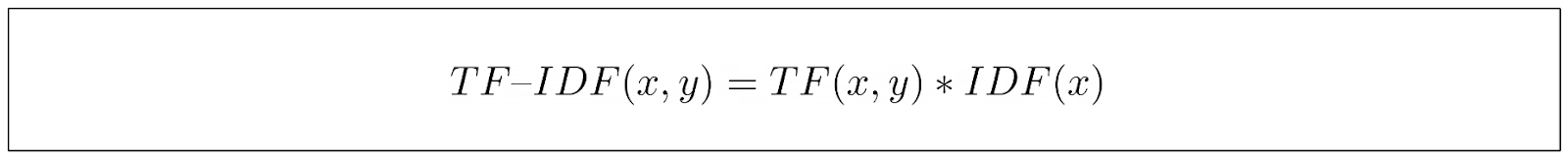
上記の最終式から、TF-IDFは、ある文書に頻繁に登場するが、他の文書にはほとんど登場しないキーワードに高いスコアを割り当てることで、キーワードの重要性を捉えていることがわかる。
ユーザーのキーワードやクエリが与えられると、検索エンジンはTF-IDFスコアを使って、キーワードとドキュメントのコレクションとの関連性を測定することができる。そして、検索エンジンは文書をランク付けし、最も関連性の高いものをユーザーに提示することができる。
TF-IDF式には、改善できる問題が2つある。
まず、クエリとして「rabbit」という単語があり、比較する文書が2つあるとする。文書Aでは「rabbit」は10回出現し、その文書には1000語ある。一方、文書Bではキーワードは1回しか出現せず、その文書の単語数は10である。
よく見ると、TF-IDFの限界がすぐにわかる。文書AのTFスコアは10であるのに対し、文書Bのスコアは1である。したがって、文書Aは文書Bに比べて推奨されることになる。
著者による画像](https://assets.zilliz.com/Image_by_author_876949a4c2.png)
しかし、文書の長さを考慮に入れると、文書Aよりも文書Bを好むと言えるかもしれない。
文書が非常に短く、「ウサギ」が一度だけ含まれている場合、その文書が本当にウサギについて語っていることを示す説得力が増す。逆に、何千語もある文書で「ウサギ」が10回も出てきたら、その文書がウサギについて具体的に語っていることを確実に保証することはできない。
この問題に対処するため、TF-IDFの正規化バリアントはTFを文書の長さで割る。TF部分のTF方程式は次のようになる:
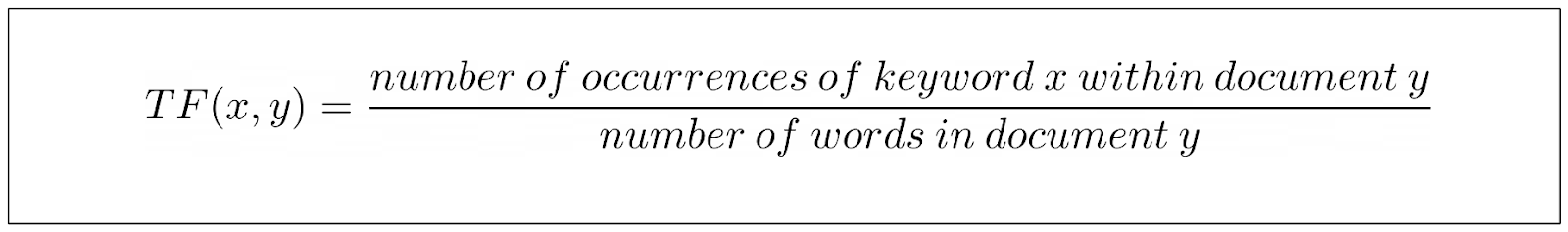
しかし、これにはまだ最適化しなければならない問題がある。
TF-IDFのTFの部分を見てみると、文書からキーワードが見つかれば見つかるほど、TFは高くなる。この関係は直線的で、キーワードを含む文書には継続的に報酬を与えたいので、これは良いことのように思えます。しかし、ある文書で「ウサギ」というキーワードが400回見つかったとして、この文書が200回しか出現しない別の文書よりも2倍関連性があるということになるのだろうか?
キーワード「ウサギ」が文書中にこれほど多く出現するのであれば、この文書は確実にキーワードに関連していると言える、と私たちは主張することができます。この文書にキーワードが追加で出現しても、その関連性が直線的に高まることはないはずだ。
文書内のキーワード出現回数が2回から4回になることによるスコアの跳ね上がりは、200回から400回に跳ね上がるよりもインパクトがあるはずだ。そして、これは現在TF-IDFの式に欠けているものである。
画像は著者による](https://assets.zilliz.com/Image_by_author_2_4633c7e592.png)
上のビジュアライゼーションからわかるように、文書内の単語数を100に固定した場合、TF-IDFのTFスコアは、キーワードの出現率が増加するにつれて直線的に増加します。
では、どうすればTF-IDFを改善できるのでしょうか?そこでBM25アルゴリズムが必要になる。
上の可視化からわかるように、文書内の単語数を100に固定した場合、TF-IDFのTFスコアはキーワードの出現率が上がるにつれて直線的に増加します。
では、どうすればTF-IDFを改善できるのでしょうか?そこでBM25アルゴリズムが必要になる。
Best Matching 25 (BM25)は、前節で述べたTF-IDFの問題点をすべて解決することで、従来のTF-IDFを改善したアルゴリズムといえる。
まずキーワードの飽和について説明しよう。TF-IDFのTF部分は、文書中のキーワードの出現回数が増えるにつれて直線的に成長する。2キーワードから4キーワードへのスコアのジャンプは、50キーワードから52キーワードへのジャンプと同じになる。
BM25では、TF-IDFと比較して、TFの部分に少し異なる式を導入しています。私たちは、ボンネットの下で何が起こっているのかを理解しやすくするために、ゆっくりと各要素を1つずつ明らかにしていきます。
まず、キーワードの出現回数だけに頼るのではなく、BM25はTF式に新しいパラメーターを導入している:

上記のパラメータkは、キーワードの各増分出現のTFスコアへの寄与を制御するパラメータとして機能します。k_の影響を見るために下の視覚化を見てみましょう。
画像は著者による](https://assets.zilliz.com/Image_by_author_3_66c0fd5503.png)
ご覧のように、最初の数回のキーワード出現が全体のTFスコアに与える影響は大きいです。しかし、キーワードが文書中にどんどん出現するにつれて、全体のTFスコアへの寄与はより無関係になります。k*の値が高いほど、キーワードの各出現のTFスコアへの寄与の伸びは遅くなります。これにより、キーワードの飽和に関連するTF-IDFの欠点が解決される。
従来のTF-IDFと比較したBM25のもう一つの基本的な改良点は、BM25が文書の長さを考慮に入れていることである。BM25では、10個のキーワードを含む1000語の文書よりも、1個のキーワードを含む10語の文書の方が強い候補となる。

D|$は文書の長さを表し、avg(D)はコーパスの文書の平均長さを表す。この文書の正規化がkパラメータに与える影響はすでにおわかりでしょう。もし文書が平均より短ければ、TF/(TF+k)の値は増加し、逆も同様です。言い換えると、短い文書は長い文書よりも早く飽和点に近づきます。
しかし、すべてのコーパスを同じように扱うことはできない。あるコーパスでは文書の長さが非常に重要だが、あるコーパスでは文書の長さはまったく重要ではない。そこで、TF式に追加パラメータbを導入し、総合スコアにおける文書の長さの重要性を制御する。

b_の値を0にすると、D/avgDの比は全く考慮されない、つまり、文書の長さを重要視しないことがわかります。一方、1の値は、文書の長さを非常に重視していることを示します。
上の式がBM25で使われるTF部分の最終式である。しかし、IDFの部分はどうだろうか?
BM25のIDFパートは、TF-IDFとは少し異なる式を持っている。BM25のIDF方程式は以下のように定義できる:
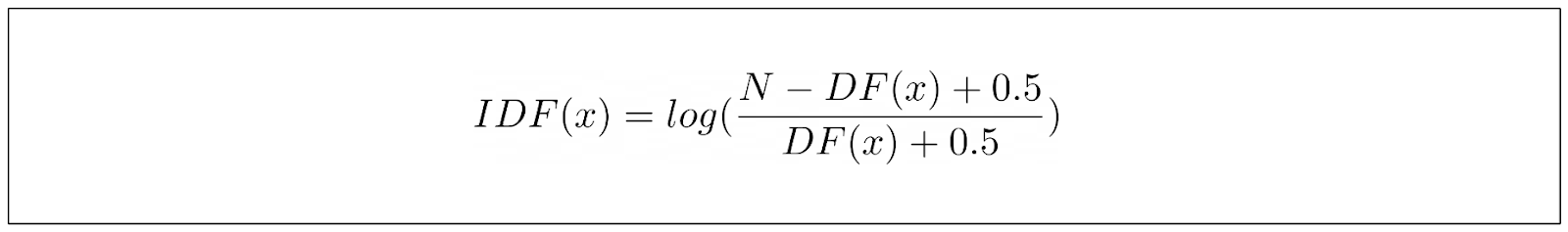
ここで、Nはコーパスに含まれる文書の総数、DFはキーワードを含む文書の数である。上記の式は、単に値を実験してベストを期待するのではなく、ランキング関数の振る舞いをとらえることのできる式を導き出せるようにと、研究者たちが行った経験的観察から生まれたものである。
しかし、このIDF方程式には1つ大きな問題がある。コーパスの半分以上にキーワードが見つかると、マイナスの値になってしまうのだ。これは情報検索のユースケースでは意味をなさない。情報検索では、キーワードがコーパスのどの文書にも見つからない場合よりもスコアが低くなることはありえない。
この問題を軽減するために、一般的にIDF式にスカラー値1が追加され、TF-IDFのIDF項と同じになる。
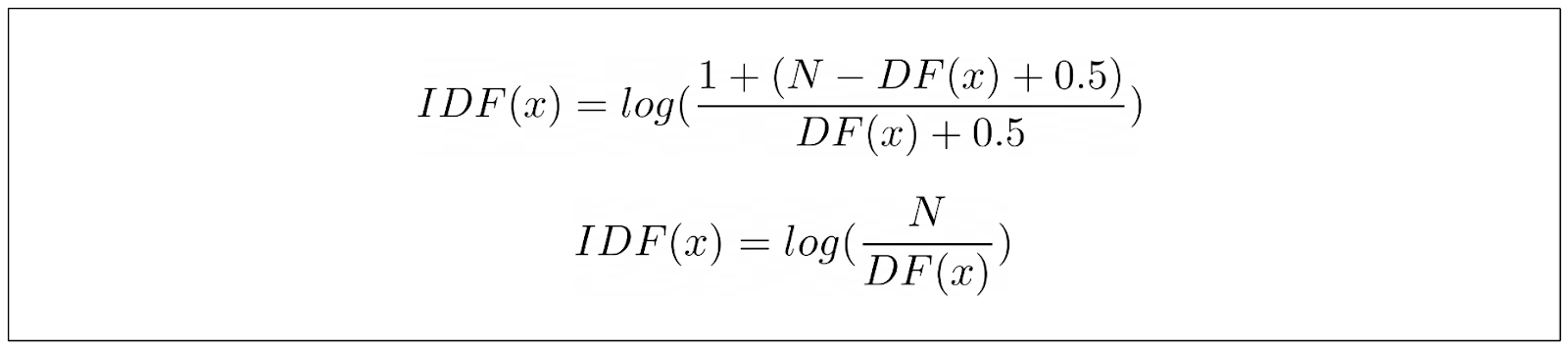
以下は、文書中の特定のキーワードのスコアを計算するBM25の最終式である:
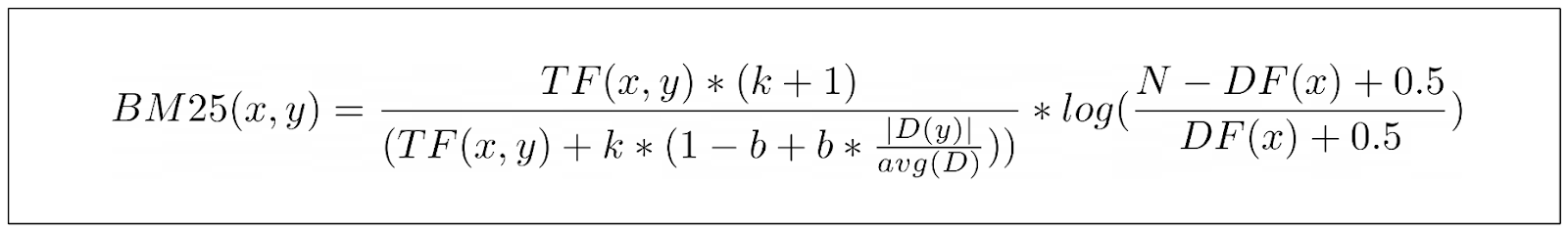
余談だが、上のTFの分子の項(k+1)についてはあまり触れていない。しかし、この項はBM25の結果全体の関係には影響しないので、この項は無視しても構わない。
前のセクションでは、BM25にはユースケースに応じて調整できる2つのパラメータがあることを学びました:1つはkと呼ばれるもので、もう1つはbと呼ばれるものです。さて、問題は、この2つのパラメータにどのような値を設定すればよいかということである。
実際のアプリケーションでは、k = 1.2、b = 0.75の値がほとんどのコーパスでうまく機能します。しかし、使用するケースに最適な値を見つけるために、両方のパラメータの値を試すことができます。これは、kとbの値を選択することが、「タダより高いものはない」理論に従うからで、つまり、すべてのユースケースに普遍的な「ベスト」なkとbの値は存在しないということです。
実験によると、kの値は0.5から2の範囲で最適になる傾向があり、bの値は0.3から0.9の間で最適になる傾向がある。
k_の値をチューニングする際には、次のように自問してください:私の文書の平均的な長さはどれくらいか?
非常に長い文書のコレクションがある場合、文書がそのキーワードについて本当に議論していなくても、キーワードが数回出現する可能性が高くなります。このような状況では、TFスコアの飽和点にあまり早く到達しないように、k値を高い範囲に設定するとよいでしょう。逆もまた真なりです。文書の平均的な長さが短い場合は、k値を低めに設定した方がよいでしょう。
b_値については、次のように自問してみてください:どのような文書があり、私のユースケースにおける文書の長さはキーワードの関連性に影響するだろうか?
例えば、長い科学的文書を集めている場合、それらの文書に含まれる単語のほとんどが重要である可能性があります。したがって、bを低い範囲に設定することをお勧めします。一方、意見的で主観的な文書を集めている場合は、短い文書と長い文書の両方で潜在的なキーワード・スパミングにペナルティを与えるため、b値を高い範囲に設定するとよいでしょう。
BM25は確かに従来のTF-IDF法を改良したものです。しかし、これはTF-IDFよりもBM25を使うべきだという意味ではありません。TF-IDFはBM25よりもシンプルで計算コストが低いため、TF-IDFで十分な場合もある。
以下は、TF-IDFとBM25の関連性スコアリング(TF-IDFとBM25の最終結果)、精度、より長い文書の処理能力、最適な使用シナリオの比較分析リストです。
| -------------------------------- | --------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------- | | アスペクト** | トラディショナルTF-IDF | BM25 | | 用語頻度 (TF) と逆文書頻度 (IDF) に依存して関連性スコアを計算する。 | 飽和項を導入し、経験則に基づいてパラメータkとbを調整することで、TF-IDFを改良。 | | 文書内では頻度が高いが、文書全体では稀な用語に高い重みを割り当てる。| 特に長い文書に対しては、用語の飽和と文書の長さの正規化を考慮することで、より洗練された関連性スコアリングを提供する。| | 小規模なデータセットや、文書全体の用語の分布が比較的均一な場合に有効。 | TF-IDFよりもノイズの多いデータや疎なデータを効果的に扱うことができる。 | | 文書の類似性やキーワードベースの検索など、完全一致が重要なタスクに有効。 | データ品質にばらつきがある場合や、文書コレクションに異常値がある場合、より高い精度が得られる。 | | 文書の長さが正規化されていないため、長い文書に偏る可能性がある。 | 文書の長さを正規化することで、長い文書への偏りに対処。 | | BM25と比較して、長い文書に対するランキングや関連性スコアの精度が低い。 | - 長い文書に対してより正確なランキングと関連性スコアを提供。 | | シンプルで解釈しやすい。 | まばらでノイズの多いデータ。 | | 完全一致。 | 長い文書。 |
このセクションでは、セマンティック検索のためにBM25を実装し、そのプロセス全体をMilvusと統合します。よろしければ、このノートブックをご覧ください。
BM25のMilvusインテグレーションを始める前に、MilvusスタンドアロンとSDKをインストールしてください。Milvusドキュメントページ](https://milvus.io/docs/install_standalone-docker.md)にインストールガイドがあります。
まず、必要なライブラリをすべて読み込みましょう。
import pymilvus
import pandas as pd
from pymilvus import MilvusClient
from pymilvus import (
ユーティリティ
FieldSchema, CollectionSchema, DataType、
Collection, AnnSearchRequest, RRFRanker, connections、
)
from pymilvus.model.sparse.bm25.tokenizers import build_default_analyzer
from pymilvus.model.sparse import BM25EmbeddingFunction
データとして、Kaggleで自由にダウンロードできるeコマースのデータセットを使う。データセットをロードし、MilvusでBM25モデルをインスタンス化してみよう。
df = pd.read_csv('.../amazon_products.csv')
df.columns
"""
出力
Index(['asin', 'title', 'imgUrl', 'productURL', 'stars', 'reviews', 'price'、
'listPrice', 'category_id', 'isBestSeller', 'boughtInLastMonth']、
dtype='object')
"""
上で見たように、データセットにはいくつかのカラムがある。ベクトル検索のデモンストレーションのために、titleカラムだけをコーパスとして使うことにする。
BM25EmbeddingFunction`クラスはBM25 埋め込みモデル のMilvus実装で、文書やクエリを疎な埋め込み表現に変換する。しかし、文書やクエリをスパース埋め込みに変換する前に、BM25モデルをコーパスに当てはめて、各トークンの統計情報を収集する必要があります。
analyzer = build_default_analyzer(language="en")
# 商品タイトルからコーパスを作成
コーパス = df["title"].values.tolist()
コーパス = [str(i) for i in corpus].
# アナライザを使ってBM25EmbeddingFunctionをインスタンス化する
bm25_ef = BM25EmbeddingFunction(analyzer)
# コーパスの統計量を得るためにコーパスにモデルをフィットする
bm25_ef.fit(corpus)
上記の build_default_analyzer 関数はMilvusの組み込み関数で、いくつかの機能を実行する。まず、特定の言語でよく使われるストップワードを除去し、残った単語をトークン化し、各トークンの関連性の統計情報を収集する。
ここで、5つの商品タイトルがあるとします。各商品タイトルを encode_documents メソッドを使ってスパースベクトル表現にすることができる。
product_title = ['7th Dragon III Code:VFD - ニンテンドー3DS (リニューアル版)'、
'Mesh Bags Drawstring Bag Set - Nylon Mesh Drawstring Bags with Cord Lock Closure'、
'FIFA 20 スタンダードエディション - Xbox One'、
ヘッドケースデザインズ公式ライセンス トムとジェリー アウトドアチェイスコミックグラフィック ビニールステッカー ゲーミング』、『ヘッドケースデザインズ公式ライセンス トムとジェリー アウトドアチェイスコミックグラフィック ビニールステッカー ゲーミング』、
Cloudz "The Big Bag "トラベル&スポーツダッフルバッグ'']
# 商品タイトルの埋め込みを作成
product_title_embeddings = bm25_ef.encode_documents(product_title)
print("Sparse dim:", bm25_ef.dim, list(product_title_embeddings)[0].shape)
"""
出力
スパース dim: 673273 (1, 673273)
"""
各文書のベクトル次元は、build_default_analyzer関数内でstopwordsフィルタリング処理を行った後の、コーパス内の利用可能なトークンの総数に相当する。各ベクトル要素は文書内の各トークンの関連性スコアを表す。
これらのvector embeddingsをMilvusベクトルデータベースに挿入してみましょう。まず、テーブルのスキーマを定義する。次に、ベクトル検索を行う際に使用する適切なインデックスと類似度メトリクスを選択する。
BM25はスパースベクトルを生成するので、転置インデックスやWeak-AND(WAND)アルゴリズムのようなインデックス作成方法を使用することができます。しかし、我々のスパースベクトルは高次元であるため、転置インデックスを使用することができます。この方法は、各次元を埋め込みにおける非ゼロ値に対応付け、検索プロセスにおいて関連データへの直接アクセスを提供します。
ベクトル探索のメトリックスとして、Milvusは現在内積しかサポートしていないので、それを使うことにします。
connections.connect("default", host="localhost", port="19530")
fields = [
フィールドスキーマ(name="pk", dtype=DataType.VARCHAR、
is_primary=True, auto_id=True, max_length=100)、
FieldSchema(name="product_title",dtype=DataType.VARCHAR,max_length=512)、
FieldSchema(name="product_title_vector", dtype=DataType.SPARSE_FLOAT_VECTOR)、
]
schema = CollectionSchema(fields, "")
col = Collection("bm25_demo", schema)
sparse_index = {"index_type":index_type": "SPARSE_INVERTED_INDEX", "metric_type":"IP"}。
col.create_index("product_title_vector", sparse_index)
# スキーマにデータを挿入する
エンティティ = [product_title, product_title_embeddings] # スキーマにデータを挿入
col.insert(entities)
col.flush()
これで、ベクトル検索を実行する準備が整いました。クエリがあるとしよう:"旅行用にどんな商品を買えばいいでしょうか?"_.そして、このクエリを encode_queries を使って埋め込みに変換します。次に、最も類似した商品を得るためにベクトル検索を実行します。
# Milvusクライアントをセットアップする
client = MilvusClient(
uri="<http://localhost:19530>"
)
collection = Collection("bm25_demo") # 既存のコレクションを取得する。
collection.load()
queries = ["旅行用にどんな商品を買えばいいのか"]] # query_embeddings = bm25_ef.encode_queries(queries)
query_embeddings = bm25_ef.encode_queries(queries)
res = client.search(
コレクション名="bm25_demo"、
data=query_embeddings[0]、
anns_field="product_title_vector"、
limit=1、
search_params={"metric_type":"IP", "params":{}},
output_fields =["product_title"])
)
print(res)
"""
出力:
[[{'id': '449258959812952449', 'distance':4.3612961769104, 'entity':{'product_title':'Cloudz "The Big Bag" Travel & Sport Duffle Bag'}}]].
"""
ということになります。検索結果によると、私たちのクエリに最も類似した製品は'Cloudz "The Big Bag" Travel & Sport Duffle Bag',で、私たちが持っている製品タイトルのカタログを考慮すると正確です。
Milvusを使用すると、他の高度なベクトル検索を実行することもできます。例えば、ベクトル検索と並行してメタデータフィルタリングを実行することで、さらに高い検索精度を得ることができます。
さらに、ハイブリッド検索を行うこともできる。この検索では、BM25の疎なベクトルと、文TransformersやOpenAIのディープラーニングモデルが一般的に生成する密なベクトルを組み合わせることで、さらに精度の高い商品レコメンドを行うことができる。
BM25アルゴリズムの進化
BM25は広く使われている情報検索アルゴリズムで、クエリ用語に基づいて文書を正確にランク付けすることで検索効率を高める。BM25の基礎を理解することは、最適な検索パフォーマンスを実現する上で非常に重要です。この記事では、BM25の基礎、ベクトルデータベースでの応用、Milvusでの実装を探求しながら、BM25の世界を掘り下げていきます。
##BM25の基礎を理解する
BM25は従来のTF-IDF法を拡張し、その限界に対処したものです。kとbの2つのパラメータを使用し、用語頻度の飽和と文書長の正規化の影響を制御する。これらのパラメータを組み込むことで、BM25は文書をランク付けするためのより微妙なアプローチを提供し、短いクエリと長い文書を扱う場合に特に効果的です。
パラメータkは用語頻度の飽和を制御し、関連性スコアがキーワードの出現回数に対して線形に増加しないようにする。これにより、用語頻度の高い文書が過度に強調されるのを防ぐことができる。一方、パラメータbは文書の長さが関連性スコアに与える影響を調整する。この正規化により、関連語を含む短い文書が長い文書に比べて不当にペナルティを受けることがない。
BM25は特に複雑なシナリオにおいて優れた検索精度を提供するが、TF-IDFはよりシンプルで計算コストの低い代替手法であることに変わりはない。TF-IDFは、小規模なデータセットや計算リソースが限られているアプリケーションでは十分かもしれない。
ベクターデータベースにおけるBM25
Milvusのようなベクターデータベースはスケーラブルな類似検索に最適化されており、検索の関連性を高めるためにBM25を統合するのに理想的です。Milvusでは、BM25EmbeddingFunctionクラスが文書やクエリをスパースなベクトル表現に変換するのに使われ、効率的な情報検索に利用されます。
Milvusのbuild_default_analyzer関数はこのプロセスで重要な役割を果たす。この関数は一般的なストップワードを除去し、残りの単語をトークン化し、各トークンの統計情報を収集する。この前処理ステップは、正確なスパースベクトルを生成するために不可欠である。
BM25モデルがコーパスに当てはまると、encode_documentsメソッドを使って文書をスパースベクトル表現に変換することができる。これらのスパースベクトルはMilvusベクトルデータベースに格納され、与えられた検索クエリに基づく関連文書の高速かつ正確な検索を可能にする。
スパースベクトルと埋め込みを扱う
スパースベクトルやエンベッディングは、その解釈のしやすさと領域外の汎化能力の高さから、ますます採用されるようになってきています。BM25は、SPLADEのような他の手法と比較して、非ゼロ値の少ないスパースベクトルを生成し、最も関連性の高い用語にフォーカスすることで検索プロセスを強化します。
BM25が重要な用語を強調するスパースベクトルを生成することに優れているのに対し、SPLADEは各入力語に対して意味的に類似した用語を含めるという利点を提供する。BERTの基礎に根ざしたこの機能により、SPLADEは、クエリの語彙がコーパスに存在しない場合でも、良い結果を出せる可能性がある。
BM25は、スパースベクトルの長所を活用することで、優れた検索効率と精度を保証し、自然言語処理と情報検索の領域で価値あるツールとなっている。



