




Leveraging Vector Databases for Next-Level E-Commerce Personalization
Explore the concepts of vector embeddings and vector databases and their role in improving the user experience in e-commerce.
Read the entire series
- Image-based Trademark Similarity Search System: A Smarter Solution to IP Protection
- HM-ANN Efficient Billion-Point Nearest Neighbor Search on Heterogeneous Memory
- How to Make Your Wardrobe Sustainable with Vector Similarity Search
- Proximity Graph-based Approximate Nearest Neighbor Search
- How to Make Online Shopping More Intelligent with Image Similarity Search?
- An Intelligent Similarity Search System for Graphical Designers
- How to Best Fit Filtering into Vector Similarity Search?
- Building an Intelligent Video Deduplication System Powered by Vector Similarity Search
- Powering Semantic Similarity Search in Computer Vision with State of the Art Embeddings
- Supercharged Semantic Similarity Search in Production
- Accelerating Similarity Search on Really Big Data with Vector Indexing (Part II)
- Understanding Neural Network Embeddings
- Making Machine Learning More Accessible for Application Developers
- Building Interactive AI Chatbots with Vector Databases
- The 2024 Playbook: Top Use Cases for Vector Search
- Leveraging Vector Databases for Enhanced Competitive Intelligence
- Revolutionizing IoT Analytics and Device Data with Vector Databases
- Everything You Need to Know About Recommendation Systems and Using Them with Vector Database Technology
- Building Scalable AI with Vector Databases: A 2024 Strategy
- Enhancing App Functionality: Optimizing Search with Vector Databases
- Applying Vector Databases in Finance for Risk and Fraud Analysis
- Enhancing Customer Experience with Vector Databases: A Strategic Approach
- Safeguarding Data: Security and Privacy in Vector Database Systems
- Integrating Vector Databases with Existing IT Infrastructure
- Transforming Healthcare: The Role of Vector Databases in Patient Care
- Creating Personalized User Experiences through Vector Databases
- The Role of Vector Databases in Predictive Analytics
- Unlocking Content Discovery Potential with Vector Databases
- Leveraging Vector Databases for Next-Level E-Commerce Personalization
- Enhancing Customer Experience with Vector Databases: A Strategic Approach
It's no secret that e-commerce is a fiercely competitive industry. Therefore, continuous innovation is essential to differentiate one platform from another. One effective way to achieve this goal is by implementing personalized product recommendations to improve user experiences.
To enhance user experiences through personalization, sophisticated technology is required to capture meaningful information about each user’s preferences. This is where we need the combination of vector embeddings and vector databases.
In this article, we'll explore the concepts of vector embeddings and vector databases, exploring their role in improving the user experience in e-commerce. So, let's dive in!
The Role of Vector Embeddings in E-Commerce
In the past, the go-to method for providing users with personalized product recommendations involved keyword or fuzzy matching between the user's query and product description. However, this method has significant drawbacks, leading to missed opportunities to provide users with relevant items for several reasons:
It only focuses on finding items that match the user's query terms.
Users often misspell search terms.
Users may use natural language to describe their needs, such as "Which shoes are best for hiking?"
Users may use different terms than those used in the product catalog, such as "wheels for my car" vs. "tires for my car."
Furthermore, users interact with a lot of unstructured content (audio, videos, images, etc.) beyond text, which could provide valuable information for delivering relevant results.
To address these challenges, we need a sophisticated method that captures two key aspects:
The intent of our users.
The meaning behind each product in our e-commerce catalog, regardless of its form (text, images, audio, etc.).
This is where vector embeddings come into play.
Vector embedding is a numerical representation of a specific item. In e-commerce, a vector embedding can represent a product, a user's session history, a query, product descriptions, or anything else. The semantic information contained in a vector is rich, and similar items are represented by vectors placed close to each other in the high dimensional vector space.
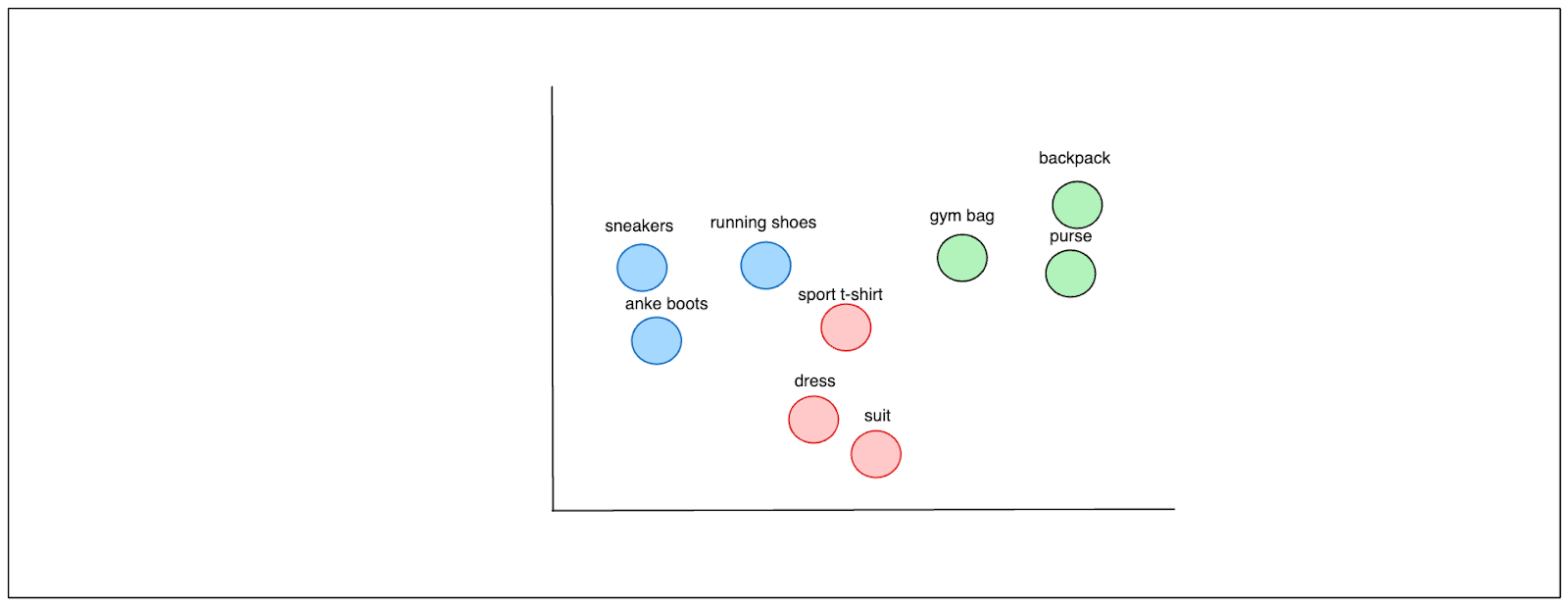 Visualization of simple 2D vector space
Visualization of simple 2D vector space
In general, there are two types of vectors: sparse vectors and dense vectors.
A dense vector is generated by a deep learning model like BERT to represent unstructured data such as text or images. It consists of mostly non-zero values, and its dimensions depend on the specific deep learning model that we use. Dense vectors capture the semantics of the input text and contain a lot of information in a relatively compact form. Common deep learning models to transform our data into a dense vector include sentence Transformers and OpenAI.
Meanwhile, a sparse vector can also represent text and has a high dimensionality, where most values are zero. Only the element with words in your input text will be non-zero in that vector. Sparse vectors generated by bag-of-words models like BM25 are usually used for keyword matching. Modern learned sparse vectors generated by machine learning models like SPLADE enrich the sparse representation with contextual information while retaining keyword-matching capabilities.
In e-commerce, we can convert product features, descriptions, and images, into vector embeddings, providing users with semantically similar recommendations to their queries. For instance, by converting product colors into vector embeddings, we can offer recommendations that include products with semantically similar colors, even when users search using non-standard color terms like turquoise or maroon. Additionally, depending on specific needs, we can store a product’s categorical metadata—such as its color, brand, price, and category—as metadata. This metadata can then be used as a filter before performing a vector search, thereby enhancing the efficiency and relevance of search results.
Once we have transformed the items into vector embeddings and stored them in a vector store like Milvus, we can perform a vector search. Vector search computes the semantic similarity between vector embeddings via metrics like cosine similarity, cosine distance, or inner product.
Vector search allows us to return relevant results even for queries without an exact match, reducing "no results" occurrences. It is also well-suited to handling conversational search queries and understanding user intent, providing visual discovery, and offering context-based recommendations. These all contribute to a more personalized and efficient user experience.
The Role of Vector Databases in E-Commerce
Now that we know that a vector contains rich information about an item, the question is: What if we have hundreds, thousands, millions, or even billions of vector embeddings? How should we handle them?
As the product catalog and the number of users on our e-commerce platform grow, managing and processing a vast number of vector embeddings becomes increasingly complex. This is where vector databases come into play.
Vector databases are designed to efficiently store large collections of high-dimensional vector embeddings. During the storage process for each embedding, vector databases create a specialized index. This index enables vector databases to perform operations on each embedding, such as vector similarity search and data filtering, with high efficiency.
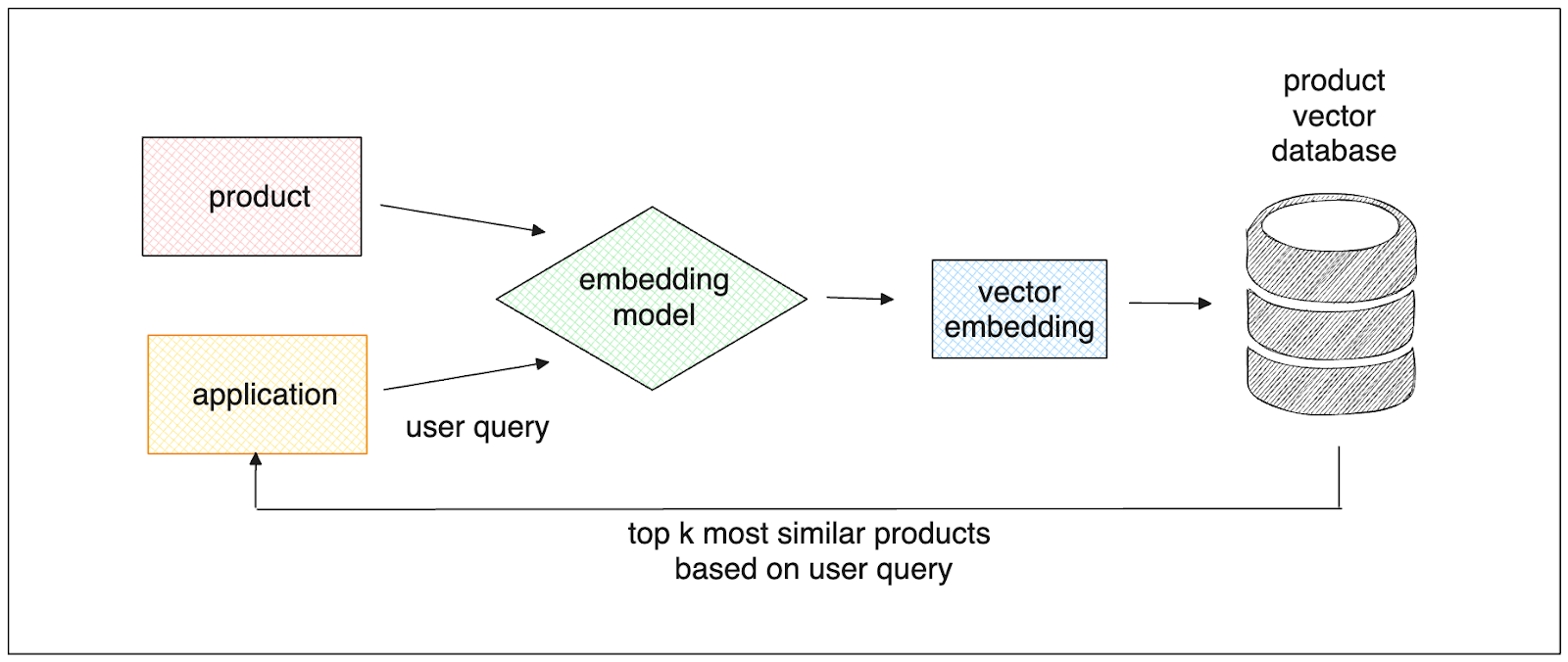 Simple retrieval process of similar products based on the user's query.
Simple retrieval process of similar products based on the user's query.
Milvus is a primary example of a robust vector database. It allows you to perform various customized vector search operations to enhance each user's personalization.
Let’s say you have a collection of dense vector embeddings inside of Milvus, each representing a product's text description. As soon as a user creates a query, Milvus will perform a vector search and return products whose descriptions are similar to that user’s query.
To give the user even more personalized and specific recommendations, we can also implement the so-called hybrid search with Milvus. This search capability enables us to simultaneously use the information contained in dense and sparse vectors. We’ll see the detailed implementation of this hybrid search in the next section.
Sometimes, you might also want to store the structured metadata of a product alongside the corresponding vector embedding. For example, you might want to store the price of each product so that when a user creates a query with a specific price range, you can recommend appropriate products to them. With Milvus, you can store these metadata alongside vector embedding and filter the data according to specific queries. We’ll also see its implementation in the next section.
Vector Database Implementation for an E-Commerce Use Case
In this section, we’ll show you how to enhance user personalization in your e-commerce with Milvus. See the full code in this notebook.
To follow along, install Milvus standalone and SDK first.
# Install and start Milvus
wget <https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh>
bash standalone_embed.sh start
# Install Python SDK
pip install pymilvus==2.4.0
Let’s first define the data that we’ll use in this implementation. Let’s say we have four products, each with a title, description, and color.
We’ll convert the product descriptions into dense vectors with the help of all-MiniLM-L6-v2 sentence Transformers model. We’ll also transform the product titles into sparse vectors with TF-IDF from scikit-learn.
!pip install sentence-transformers
from sentence_transformers import SentenceTransformer
from sklearn.feature_extraction.text import TfidfVectorizer
dense_vector_model = SentenceTransformer("all-MiniLM-L6-v2")
sparse_vector_encoder = TfidfVectorizer()
product_color = ['white','green','blue', 'blue']
product_title = ['Toilet Seat Bumpers', 'Soundcore Anker Motion Boom Speaker', 'Nelson Wood Shims', 'Momoho Multifunctional']
product_desc = ['Universal Toilet Replacement Bumper for Bidet Attachment Toilet Seat Bumper','Portable Bluetooth Speaker with Titanium Drivers, BassUp Technology','DIY Bundle Wood Shims 8-Inch Shims and High Performance Natural Wood', 'IPX7 Waterproof Bluetooth Speaker, Micro SD Support TWS Pairing']
product_description_vector = dense_vector_model.encode(product_desc)
product_title_vector = sparse_vector_encoder.fit_transform(product_title)
If you notice, now we have data in various formats: dense vectors (product_description_vector), sparse vectors (product_title_vector), and scalars (color). Next, we want to store all of these records inside Milvus. Let’s define the schema and insert the data into it.
from pymilvus import (
utility,
FieldSchema, CollectionSchema, DataType,
Collection, AnnSearchRequest, RRFRanker, connections,
)
connections.connect("default", host="localhost", port="19530")
fields = [
FieldSchema(name="pk", dtype=DataType.VARCHAR,
is_primary=True, auto_id=True, max_length=100),
FieldSchema(name="product_title", dtype=DataType.VARCHAR, max_length=512),
FieldSchema(name="product_description", dtype=DataType.VARCHAR, max_length=512),
FieldSchema(name="color", dtype=DataType.VARCHAR, max_length=512),
FieldSchema(name="product_title_vector", dtype=DataType.SPARSE_FLOAT_VECTOR),
FieldSchema(name="product_description_vector", dtype=DataType.FLOAT_VECTOR, dim=384)
]
schema = CollectionSchema(fields, "")
col = Collection("product_color_demo", schema)
sparse_index = {"index_type": "SPARSE_INVERTED_INDEX", "metric_type": "IP"}
dense_index = {"index_type": "FLAT", "metric_type": "COSINE"}
col.create_index("product_title_vector", sparse_index)
col.create_index("product_description_vector", dense_index)
# Insert data into schema
entities = [product_title, product_description, product_color, product_title_vector, product_description_vector]
col.insert(entities)
col.flush()
Basic Vector Search
So far, we have inserted the data into the Milvus database. Now, we can perform the basic vector search with it.
Let’s say we, as a user, want to find a product that can improve our music experience. Therefore, we ask, “What product should I buy to improve my music experience?” A vector database like Milvus can easily recommend the appropriate product by performing a vector similarity search between our query and the description of each product in the database.
from pymilvus import MilvusClient
# Set up a Milvus client
client = MilvusClient(
uri="<http://localhost:19530>"
)
collection = Collection("product_color_demo")# Get an existing collection.
collection.load()
product_query = "What product should I buy to improve my music experience?"
product_query_vector = dense_vector_model.encode([product_query])
res = client.search(
collection_name="product_color_demo",
data=product_query_vector,
anns_field="product_description_vector",
limit=2,
search_params={"metric_type": "COSINE", "params": {}},
output_fields =["product_title", "product_description", "color"]
)
print(res)
"""
# Output:
[[{'id': '449184705451132150', 'distance': 0.1673874706029892, 'entity': {'product_title': 'Soundcore Anker Motion Boom Speaker', 'product_description': 'Portable Bluetooth Speaker with Titanium Drivers, BassUp Technology', 'color': 'green'}}, {'id': '449184705451132152', 'distance': 0.14789678156375885, 'entity': {'product_title': 'Momoho Multifunctional', 'product_description': 'IPX7 Waterproof Bluetooth Speaker, Micro SD Support TWS Pairing', 'color': 'blue'}}]]
"""
As you can see, according to our query, the top two product recommendations are portable Bluetooth speakers from two different brands.
Scalar Filtered Vector Search
Consider the following use case: We want to buy a product to improve our music experience. However, we also want that product to be blue.
In this case, we can get a more specific recommendation with Milvus. This is because we can use metadata as the filtering criteria for our query. The way to do this is very similar to the basic vector search above. All we need to do is specify the filtering criteria inside the search method.
res = client.search(
collection_name="product_color_demo",
data=product_query_vector,
anns_field="product_description_vector",
filter='color == "blue"',
limit=1,
search_params={"metric_type": "COSINE", "params": {}},
output_fields =["product_title", "product_description", "color"]
)
print(res)
"""
# Output:
[[{'id': '449184705451132152', 'distance': 0.14789678156375885, 'entity': {'product_description': 'IPX7 Waterproof Bluetooth Speaker, Micro SD Support TWS Pairing', 'color': 'blue', 'product_title': 'Momoho Multifunctional'}}]]
"""
And there we have it. This time, we got a different recommendation: a blue portable Bluetooth speaker.
Hybrid Search
Hybrid search is a vector search that combines the information of dense vectors with sparse vectors. This helps e-commerce platforms give more personalized recommendations to users. Let's explore a scenario where we want to implement a hybrid search using product embeddings (dense vectors) and title embeddings (sparse vectors).
To achieve this goal, Milvus initiates separate vector search sessions—one for dense vectors and another for sparse vectors—using approximate nearest neighbors (ANN). Then, it merges these two sessions and ranks the results using fusion methods. A commonly used fusion method is reciprocal rank fusion, which ranks documents based on their reciprocal positions.
Imagine the following use case: We want to buy a speaker, and we want that speaker to be specifically from Anker. Fortunately, our Milvus database has a sparse vector representing each product's title.
Then, we can combine the dense vector representing a product's description with the sparse vector representing its title and utilize a hybrid search to recommend the product to users. Below is how we can implement this with Milvus.
product_query = "I want to buy a speaker"
product_title_query = "Anker"
product_query_vector = dense_vector_model.encode([product_query])
product_title_query_vector = sparse_vector_encoder.transform([product_title_query])
sparse_req = AnnSearchRequest(product_title_query_vector,
"product_title_vector", {"metric_type": "IP"}, limit=2)
dense_req = AnnSearchRequest(product_query_vector,
"product_description_vector", {"metric_type": "COSINE"}, limit=2)
res = collection.hybrid_search([sparse_req, dense_req], rerank=RRFRanker(),
limit=1, output_fields=["product_title", "product_description", "color"])
print(res)
"""
['["id: 449184705451132150, distance: 0.032786883413791656, entity: {\\'color\\': \\'green\\', \\'product_title\\': \\'Soundcore Anker Motion Boom Speaker\\', \\'product_description\\': \\'Portable Bluetooth Speaker with Titanium Drivers, BassUp Technology\\'}"]']
"""
And there we have it. We got a recommendation for a portable Bluetooth speaker from Anker, which is just like our query and preferred color.
Vector Database Success Stories
All the advantages mentioned above highlight the necessity of using a vector database in e-commerce platforms. The application of Milvus as an open-source vector database in the e-commerce landscape has led to several success stories, such as:
VIPSHOP
VIPSHOP, an online retailer headquartered in China, faced the challenge of building a scalable infrastructure as its business rapidly expanded. They sought a more efficient and faster solution for storing vectors and providing personalized recommendations to their users.
Previously, they used Elasticsearch for their recommendation systems, which took around 300 ms to retrieve similar vectors from a collection of millions. However, after switching to Milvus, VIPSHOP experienced a significant performance improvement.
Milvus' efficient vector data updates and recall process enabled VIPSHOP to achieve the same task 10 times faster than the previous Elasticsearch implementation. Additionally, Milvus supports distributed deployment and horizontal scaling, allowing it to handle increases in data volumes without compromising performance.
Tokopedia
Another example comes from Tokopedia, Indonesia’s largest e-commerce platform. They utilize Milvus as their vector search optimization engine to match low-fill-rate user search keywords with high-fill-rate user search keywords.
This optimization resulted in a 10-fold increase in Tokopedia's click-through and conversion rates. To ensure the stability and reliability of its semantic search system, Tokopedia also relies on tools offered by Milvus, such as a cluster-sharding middleware called Mishards.
Read more Milvus success stories in the e-commerce landscape.
Conclusion
Vector embedding is a sophisticated method that efficiently captures the user’s intent and the semantic meaning of each product. We can perform a vector search on vector embeddings, which allows us to return personalized products to users even for queries without an exact match.
To efficiently store a large collection of these embeddings, we can rely on a vector database like Milvus. It offers several vector search operations, such as basic search, scalar-filtered search, and hybrid search, which allow us to give the user even more specific and personalized recommendations.
Considering all these benefits, e-commerce businesses must consider the strategic adoption of vector databases to gain a competitive advantage.

- The Role of Vector Embeddings in E-Commerce
- The Role of Vector Databases in E-Commerce
- Vector Database Success Stories
- Conclusion
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Building an Intelligent Video Deduplication System Powered by Vector Similarity Search
Learn how to use the Milvus vector database to build an automated solution for identifying and filtering out duplicate video content from archive storage.

Making Machine Learning More Accessible for Application Developers
Learn how Towhee, an open-source embedding pipeline, supercharges the app development that requires embeddings and other ML tasks.

Creating Personalized User Experiences through Vector Databases
Explore how vector databases enhance personalized user experiences