




Getting Started with LLMOps: Building Better AI Applications
The emergence of OpenAI’s ChatGPT has catalyzed a wave of interest in large language models (LLMs) among corporations. Major tech firms and research organizations are now making LLMs more accessible, endeavoring to enhance data infrastructure, fine-tune models for tailored applications, and monitor issues like hallucinations and biases. This growing interest has also led to a surge in demand for technology vendors that support large language model operations (LLMOps). These vendors provide comprehensive workflows for developing, fine-tuning, and deploying LLMs into production environments.
At our recent Unstructured Data Meetup, Sage Elliott, a machine learning engineer at Union.ai, discussed deploying and managing LLMs, offering valuable insights into the tools, strategies, and best practices necessary for integrating these models into business applications. His presentation was particularly helpful for AI developers and operations managers, focusing on ensuring the reliability and scalability of LLM applications in production settings.
In this post, we’ll recap the key insights from Sage’s talk and discuss the concept and methodologies of LLMOps.
<< Watch the Replay of Sage Elliott’s Talk >>
What are LLMOps?
LLMOps stands for Large Language Model Operations, which are analogous to MLOps but specifically for large language models (LLMs). To understand LLMOps, let's first unpack MLOps.
MLOps (Machine Learning Operations) refers to the practices and tools used to efficiently deploy and maintain machine learning models in production environments. It is an extension of DevOps (Development and Operations), which integrates application development and operations into a cohesive process. This approach ensures that both development and operations are considered together rather than functioning in separate silos.
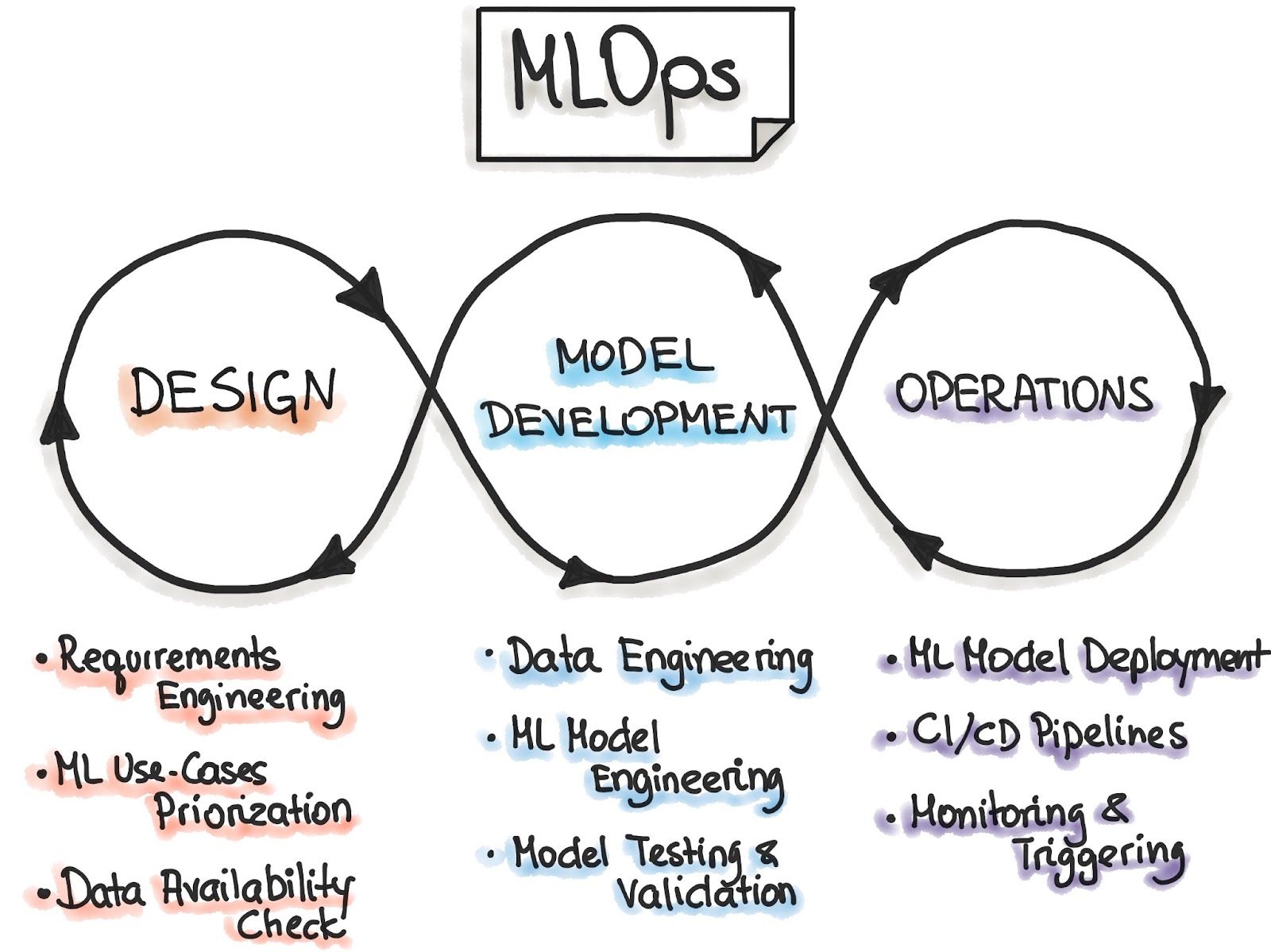 What are MLOps?
What are MLOps?
What are MLOps? Image Source: https://ml-ops.org/content/MLOps-principles
Before the DevOps methodology emerged, development teams focused on writing applications or updates as quickly as possible, while operations teams prioritized the application's stability, efficacy, and user experience. This compartmentalized approach often resulted in inefficiencies, leading to sub-optimal applications with slow development and infrequent updates.
DevOps transforms this process by fostering collaboration between development and operations teams, ensuring a more streamlined and efficient workflow. MLOps extends these principles to machine learning, addressing the challenges of deploying and maintaining ML models.
LLMOps hones in on the holistic approach of MLOps by applying its principles to large language model (LLM) applications. It is concerned with all aspects of the development, deployment, maintenance, and continual improvement of LLM applications.
The central philosophy of cooperation is also inherent in Sage’s definition of LLMOps—“Building AI Together,” which emphasizes the idea that all relevant business units, e.g., development, operations, product management, etc., must work together to produce the most performant LLM applications in a timely and cost-effective manner.
Continuous Integration and Continuous Delivery/Deployment (CI/CD)
As with DevOps, one of the core principles of LLMOps is Continuous Integration/Continuous Deployment (CI/CD): the process of automating the LLM application development lifecycle.
Continuous integration (CI) is the practice of automatically taking application updates and merging them with the main branch, i.e., the version of the LLM application currently running in production. When a developer submits code to a repository, such as GitHub, this action triggers an automated workflow that validates whether the updates are ready for integration. CI encourages frequent changes by development teams and helps avoid code merging conflicts.
Continuous delivery/deployment (CD) refers to the process of automatically deploying changes to the application in a production environment after integration and validation. This process includes further tests, such as functional and user acceptance testing and infrastructure configuration.
Although continuous delivery and deployment are often used interchangeably, there’s a difference between them. Continuous delivery stops short of automatic production deployment, typically for human final checks to ensure organizational and regulatory compliance. Conversely, continuous deployment automatically releases application updates to users. With this concept in mind, true continuous deployment is rare - particularly in LLM application development, which is still nascent.
Who Should Be Using LLMOps?
In short, anyone developing an LLM application should utilize LLMOps to some degree.
On the one hand, LLMOps is essential for production-level AI applications, with the exact infrastructure dependent on the application's needs. In contrast, even a simple, personal AI project will benefit from implementing a simple LLMOps pipeline.
Integrating LLMOps into your AI application offers the following benefits:
Resource management and scalability: being aware of your use of computational resources to deliver an optimal user experience. LLMs require large amounts of memory to run effectively, so being able to determine whether your hardware, i.e., GPUs, is sufficient for the needs of your application is crucial.
Model updating and improvements: being aware of a model’s failures or shortcomings in less time and updating them accordingly.
Ethical and responsible AI practices: being conscious of the intended purpose of your AI application and the potential consequences of its malfunction. One of the main concerns about LLMs is their tendency to “hallucinate,” i.e., to provide inaccurate or irrelevant output; this problem could prove catastrophic in an application for giving medical advice, for example.
Simplified LLMOps Pipeline Example
The market map created by CBInsights identifies 90+ companies across 12 categories that help enterprises manage LLM projects from start to finish. This landscape also shows the size of the LLMOps market.
 LLMOps market landscape
LLMOps market landscape
LLMOps market landscape: 90+ companies across 12 different categories helping enterprises bring LLM projects from start to finish.
To make it easier to understand, Sage created a simplified LLMOps pipeline.
A simplified LLMOps pipeline
Let’s explain the elements of this diagram:
Sys Prompt: The user input becomes part of the system prompt and is fed into the LLM.
Model: The LLM underpins the application for answer generation.
Guardrail: The controls you’ve put in place to ensure the user only enters appropriate input, i.e., trying to get the model to generate harmful or offensive content.
Data Store: Vector databases like Milvus and Zilliz Cloud (the managed Milvus). These databases provide the LLM with long-term memory and contextual query information and help the LLM generate more accurate results. This component is particularly beneficial in Retrieval Augmented Generation (RAG) applications.
Monitor: The tools used to continuously monitor the LLM application
CI/CD Orchestrator: A platform that manages your application and helps automate its integration and deployment to production environments.
Getting Started with LLMOps
Although LLMOps is changing rapidly and vendors are releasing new LLMOps tools daily, fortunately, the core principles of LLMOps remain the same.
Here is a simple three-step philosophy for starting with LLMOps.
Ship the model
Monitor the model’s performance
Improve the model
Let’s look at each step in greater detail.
Ship Your Model
Shipping the model refers to deploying your LLM application to a production environment as soon as possible. This approach is essential as it enables you to obtain accurate data from users interacting with the model and quickly learn how to fit your LLM application to the user’s needs. A prime example is a chatbot application, whereby it’s far more helpful to obtain examples of real user input and what the model outputs in response than merely predicting input in a test environment.
HuggingFace Spaces is a fantastic resource that streamlines the shipping of your model into production. It is a hosting platform for most ML applications, providing low-cost cloud GPUs to power LLMs, which makes it ideal for prototyping. You can also deploy your application to a private space, providing limited access to those you want to test your LLM application or make it public to gain feedback from HuggingFace’s large and active community.
 HuggingFace Spaces
HuggingFace Spaces
HuggingFace Spaces
HuggingFace offers more than just Spaces for model deployment; it provides a comprehensive ecosystem for developing and deploying applications. Central to their offerings is a vast collection of over 640,000 open-source ML models, including speech, computer vision, and language models. Additionally, HuggingFace provides several libraries that include all the necessary components for building end-to-end LLM applications, along with the datasets needed for training.
To illustrate how you can build LLM applications with HuggingFace, let’s look at how to download and train a model using its Transformer (for accessing the LLMs) and Datasets (for accessing training data) libraries.
First, you need to install the appropriate libraries:
pip install torch transformers datasets
Next, we will download the LLM we wish to use within our application. As stated above, HuggingFace features hundreds of thousands of models, each providing the necessary code to integrate into your application. For example, we’re going to load the Llama 3 model as follows:
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct”)
Next, we need to load the dataset to fine-tune the model. For this example, we will use one of HuggingFace's many available datasets. However, if you prefer to use your own data for a domain-specific or task-specific purpose, you simply need to replace the file path with the one pointing to your training data folder.
from datasets import load_dataset
dataset = load_dataset("talkmap/telecom-conversation-corpus")
After loading the dataset, we need to tokenize it by converting it into sub-word tokens that the LLM can easily process. We must use the tokenizer associated with the Llama 3 model to ensure the data is tokenized consistently with the pre-training process and maintains the same tokens-to-index, or "vocabulary." You can complete this step with just a few lines of code.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")
# Define tokenizer function
def tokenize_function(examples):
return tokenizer(examples["text"], padding="True", truncation=True)
tokenized_dataset = dataset.map(tokenize_function, batched=True)
Now, we need to set the hyperparameter configurations to fine-tune our model using a TrainingArguments object. This configuration offers 109 optional parameters, giving you granular control over the training process. If you prefer, you can rely on the default settings by not passing any specific parameters.
from transformers import TrainingArguments
training_args = TrainingArguments()
Lastly, after defining the elements of our model, we just need to place them inside a training object and call the associated train function as follows:
With the elements of our trainer object configured, all that’s left is putting it together and calling the train function to fine-tune our Llama 3 base model.
from transformers import Trainer
trainer = Trainer(
model=model,
dataset=dataset,
args=training_args,
)
trainer.train()
And there you have it - with just a few lines of code, you can download and train a language model that can be used to power an LLM application.
For a more specific and in-depth example of how HuggingFace simplifies the development of LLM applications, see our tutorial on building a QA application with Milvus
Continuous Monitoring and Evaluation
Once you deploy your LLM app to a production environment, it’s essential to monitor your app for the following reasons:
To determine how your model performs in production, do they fulfill their intended use case? Does it align with the user’s expectations?
How can you improve the model?
Subsequently, when you make improvements to the model, do they result in the expected performance enhancements, or if further changes are required?
The computational resources your model consumes: Do you need to allocate more resources, e.g., GPUs, to make your application perform better? Additionally, with the resources it consumes, how scalable is your application?
How does it perform after changes, e.g., additional training, fine-tuning?
Evaluation metrics help you measure your model’s ability to produce correct output in response to a user’s prompt. The most commonly used metrics include BLEU, ROUGE, and BERTScore, which are described below.
| Metric | Purpose |
| BLEU (Bilingual Evaluation Understudy) | Often used in machine translation, measures the similarity between model-generated text and reference text based on n-gram (n consecutive words) overlap |
| ROUGE (Recall-Oriented Understudy for Gisting Evaluation) | Evaluates the quality of model-generated summaries by comparing n-gram overlap, word sequences, and word pairs with reference summaries. |
| BERTScore (Bidirectional Encoder Representations from Transformers) Score | Measures textual similarity by leveraging BERT embeddings to capture semantic meaning; provides a more detailed assessment than surface-level n-gram overlap, as with BLEU and ROUGE. |
Additionally, there are other qualitative ways to evaluate the performance of your LLM application.
Assessing the accuracy and relevance of output: A response may be well crafted, but how helpful is it about the input prompt? Does it provide the value the user expects?
Determining how users use your LLM application and if you must fine-tune it accordingly.
Assessing the sentiment of responses: does the application respond in the desired tone?
Are there any jailbreaking attempts, i.e., trying to get the model to produce output that it shouldn’t? For example, asking a chatbot how to make homemade weapons. This approach determines whether you should include guardrails in your application or improve those you may have already implemented.
Continuously monitoring your LLM applications isn’t complicated. Many tools are available in the market to evaluate your LLM-powered applications, including LangKit, as Sage highlighted in his talk, Ragas, Continuous Eval, TruLens-Eval, LlamaIndex, Phoenix, DeepEval, LangSmith, and OpenAI Evals.
To learn more about evaluating LLM applications, take a look at our article on RAG evaluation.
Improving Your Model
Using the metrics and feedback from monitoring your model, you can make new iterations of your LLMs in far less time. A powerful and efficient way of implementing improvements is by integrating an MLOps orchestrator like Flyte into your pipeline. An MLOps orchestrator simplifies the management of your LLM application in the following ways:
Automated testing: automatically running tests whenever changes are made.
Software builds: compiling the code and preparing it for deployment.
Deployment: moving the latest version of the application into production.
Monitoring and reporting: tracking the status of builds, tests, and deployments and providing feedback.
An orchestrator manages your application through workflows, which are a series of steps required to execute a specific task or objective. Each step within a workflow can be individually executed, tested, and verified while the orchestrator handles the sequence in which each task is performed. Examples of workflows include training or fine-tuning an LLM, deploying an application to an environment, or integrating new features into an application running in production.
Workflows streamline the development and maintenance of LLM applications in several ways. Firstly, workflows are reproducible, so an existing workflow can be copied across different pipelines, saving considerable time and effort. Similarly, workflows can be versioned, ensuring you can revert a pipeline to how it was at a given time.
In reality, an MLOps orchestrator is best suited for enterprise-level LLM applications developed by multiple people or teams and is likely overkill for a smaller application. Instead of an orchestrator, shipping your model to production, monitoring its use, and manually updating your application according to the insights you’ve gained is a more practical approach.
Summary
So, to recap Sage Elliot’s talk on LLMOps:
LLMOps refer to a collection of philosophies and technologies that facilitate the efficient development, deployment, maintenance, and improvement of LLM applications.
LLMOps can also be defined as "Building AI Together," meaning that, like DevOps (from which it’s derived), different teams within an organization collaborate to build LLM applications instead of operating in silos with contrasting objectives.
Despite seeming overwhelming, you can get started with LLMOps with a three-step process:
Ship: deploy a model into production ASAP for real user feedback
Monitor: use metrics to evaluate its performance
Improve: use insights from monitoring to improve your application.
HuggingFace is an excellent resource for quickly deploying prototypes into production. The Transformer library allows you to download and fine-tune models easily, the Datasets library provides the data to fine-tune it, and Spaces provides a hosting platform to quickly deploy it to production.
Flyte is an example of an MLOps orchestrator that simplifies the management of your LLM application.
Further Resources
We encourage you to explore the resources below to further your understanding of LLMOps and learn how to apply it to your AI application development process.
To learn more about vector databases, large language models (LLMs), and other key AI and machine learning concepts, visit the Zilliz Learn knowledge base.
Keep Reading

Data Deduplication at Trillion Scale: How to Solve the Biggest Bottleneck of LLM Training
Explore how MinHash LSH and Milvus handle data deduplication at the trillion-scale level, solving key bottlenecks in LLM training for improved AI model performance.

VidTok: Rethinking Video Processing with Compact Tokenization
VidTok tokenizes videos to reduce redundancy while preserving spatial and temporal details for efficient processing.

What is the K-Nearest Neighbors (KNN) Algorithm in Machine Learning?
KNN is a supervised machine learning technique and algorithm for classification and regression. This post is the ultimate guide to KNN.