




Popular Machine-learning Algorithms Behind Vector Searches
In this post, we’ll explore the essence of vector searches and some popular machine learning algorithms that power efficient vector search, such as ANN and ANN.
Read the entire series
- Raft or not? The Best Solution to Data Consistency in Cloud-native Databases
- Understanding Faiss (Facebook AI Similarity Search)
- Information Retrieval Metrics
- Advanced Querying Techniques in Vector Databases
- Popular Machine-learning Algorithms Behind Vector Searches
- Hybrid Search: Combining Text and Image for Enhanced Search Capabilities
- Ranking Models: What Are They and When to Use Them?
- Navigating the Nuances of Lexical and Semantic Search with Zilliz
- Enhancing Efficiency in Vector Searches with Binary Quantization and Milvus
- Model Providers: Open Source vs. Closed-Source
- Embedding and Querying Multilingual Languages with Milvus
- An Ultimate Guide to Vectorizing and Querying Structured Data
- Understanding HNSWlib: A Graph-based Library for Fast Approximate Nearest Neighbor Search
- What is ScaNN (Scalable Nearest Neighbors)?
- Getting Started with ScaNN
- Next-Gen Retrieval: How Cross-Encoders and Sparse Matrix Factorization Redefine k-NN Search
- What is Voyager?
- What is Annoy?
Vector search is a fundamental part of modern data retrieval and similarity queries. Think about a facial recognition technology that automates security monitoring in high-traffic locations like airports or stadiums. Each face is converted into a high-dimensional vector representing unique facial features. Then, this vector is compared with data on criminals and other security threats stored in a vector database like Milvus using vector similarity search to identify potential risks and prevent security issues timely.
Vector search is like having a super-smart assistant that understands the essence of your query and quickly finds the best matches in a sea of data. Whether you're hunting for a product online, exploring recommendations on a streaming service, or analyzing complex datasets, vector search makes it happen quickly.
In this post, we’ll explore the essence of vector searches and some popular machine learning algorithms that power efficient vector search, such as K-Nearest Neighbors (ANN) and Approximate Nearest Neighbors (ANN).
The Essence of Vector Search
Vector search, also known as vector similarity search or nearest neighbor search, is a technique in information retrieval systems designed to identify data points closely aligned with a specified query vector. This approach represents unstructured data like images, text, and audio as vectors within a high-dimensional space, aiming to efficiently locate and retrieve vectors that closely match the query vector.
Distance metrics such as Euclidean distance or cosine similarity are commonly used to assess the similarity between vectors, with proximity in vector space indicating closeness. To facilitate effective organization and retrieval, vector search algorithms employ indexing structures like tree-based structures or hashing techniques.
The development of vector search has advanced with the growth of AI-driven applications, fundamentally changing data processing and analysis. Integral to functions from powering recommendation systems to facilitating natural language processing, vector search engines act as a critical component in AI applications across diverse sectors, including e-commerce, healthcare, and finance. As these technologies advance, vector search is poised to play an increasingly transformative role, reshaping how we engage with and understand complex datasets in the digital era.
Two popular machine-learning algorithms power efficient vector search: the K-nearest Neighbors (KNN) algorithm and the Approximate Nearest Neighbor (ANN) algorithm. In the following sections, we’ll explore what they are and how they work to power vector search.
What is a K-Nearest Neighbors (KNN) Algorithm?
The K-Nearest Neighbors (KNN) algorithm is a widely used machine learning method for classification and regression tasks. This algorithm operates on the principle that similar data points cluster together in a high-dimensional space, making it logical and intuitive for pattern recognition in data.
During its data training phase, KNN does not build a conventional model but instead retains the entire dataset for reference. When making predictions, it measures the distance between a new input data point and all the existing points in the training dataset using a selected distance metric, such as Euclidean or Cosine Distance. The algorithm then identifies the K closest training examples—or "neighbors"—to the new data point. In classification tasks, KNN assigns the class label most frequently represented among these K neighbors to the new data point. In regression tasks, the algorithm predicts a value based on the average or a weighted average of the values from these neighbors.
The graphic below shows how KNN algorithms work. To categorize a new data point, KNN computes the distance between this point and the K nearest neighbors from each category, such as Category A and Category B. After determining the distances, the algorithm assigns the data point to the category that is most prevalent among its K nearest neighbors based on these calculated distances. In this example, the new point is assigned to Category B.
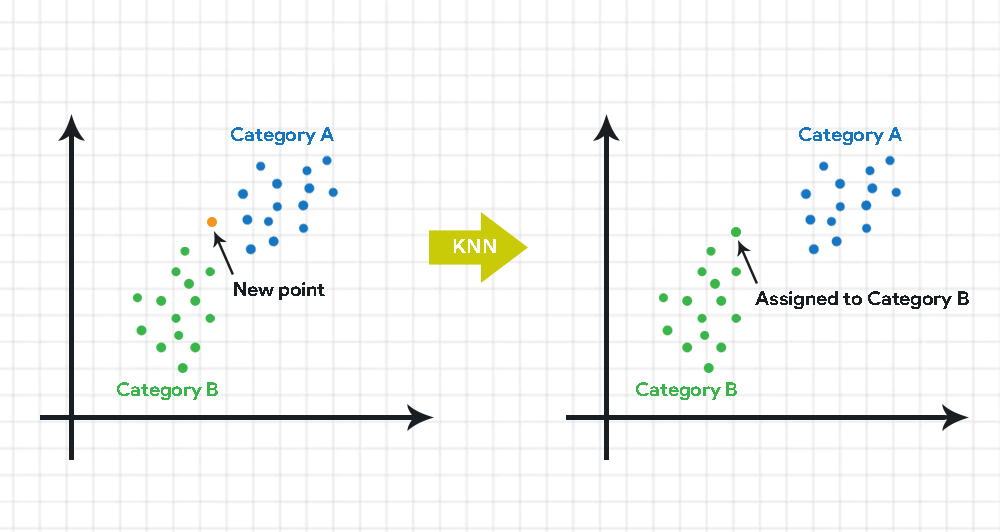 How K-Nearest Neighbors (KNN) Algorithms Work
How K-Nearest Neighbors (KNN) Algorithms Work
How K-Nearest Neighbors (KNN) Algorithms Work
The effectiveness of the KNN algorithm will be influenced by the choice of K (the number of nearest neighbors considered) and the distance metric used. Therefore, tuning these parameters is crucial to achieving optimal performance.
For more information about ANN algorithms, refer to our blog: What Is K-Nearest Neighbors (KNN) Algorithm in ML?
Application of KNN in Vector Search
In vector search applications, where each data point is represented as a high-dimensional vector, KNN algorithms can efficiently retrieve vectors similar to a specified query. This algorithm calculates the distances between the query vector and every other vector in the dataset, subsequently selecting the Top-K nearest vectors based on these calculated distances.
Adjusting the value of 'K' provides the flexibility to optimize the balance between vector search precision and efficiency. This flexibility makes the KNN algorithm extremely valuable in various domains, such as recommendation systems, image retrieval, and text semantic search, where the rapid identification of similar vectors is crucial.
What is an Approximate Nearest Neighbors (ANN) Algorithm?
Approximate Nearest Neighbor (ANN) algorithms are a popular machine learning and data science technique for efficient nearest-neighbor searches within large datasets stored in highly performant vector databases like Zilliz Cloud.
You can think of ANN as an optimized version of the K-Nearest Neighbors (KNN) algorithm. Instead of conducting an exhaustive search through every data point in the dataset, ANN algorithms identify an approximate nearest neighbor with a high probability, significantly reducing computational costs. This optimization makes ANN highly suitable for applications requiring rapid query responses, even in expansive datasets.
Application of ANN in Vector Search
ANN algorithms streamline vector searches by constructing specialized index structures during the indexing phase, much like drawing a map that delineates regions likely to contain similar vectors. This mapping allows ANN to efficiently hone in on potential neighbors during the query phase without evaluating every vector individually. Instead, it uses these pre-constructed maps to make informed estimations about the nearest neighbors.
While these predictions may not always achieve 100% accuracy, they are sufficiently precise for many applications, offering a significant speed advantage. This efficiency is critical for managing large datasets and navigating high-dimensional spaces, making ANN indispensable in fields like recommendation systems and image searches where rapid and effective querying is essential.
For more information about ANN, see our page: What is approximate nearest neighbor search (ANNS)?
KNN vs. ANN Searches
The key difference between the ANN search and the KNN search lies in the precision of the search results and the performance in terms of speed and computational resource requirements.
Precision and Accuracy
KNN Search: This algorithm finds the exact k-nearest neighbors to a query point in the dataset. It guarantees accuracy by evaluating all possible neighbors to determine the closest ones based on the specified distance metric.
ANN Search: Unlike KNN, ANN search aims to find approximate nearest neighbors. It trades off some accuracy for improved speed and efficiency. This approach doesn’t always guarantee the exact nearest neighbors but provides results that are close enough, which is sufficient for many practical applications.
Performance (Speed and Resource Usage)
KNN Search: While extremely accurate, KNN can be computationally expensive and slow, especially with large datasets, because it requires comparing every single point. This can also lead to significant memory and processing power requirements.
ANN Search: By focusing on approximate results, ANN search algorithms like Locality-Sensitive Hashing (LSH), trees, or graph-based methods can quickly retrieve results with less computational overhead. These methods are particularly beneficial when dealing with large datasets or real-time applications where speed is critical.
Range Search: Enhancing Vector Search Precision
While KNN and ANN are proficient algorithms for vector searching, they are limited to returning a predetermined number of nearest neighbors. This can lead to redundancy in results. For instance, with a KNN or ANN-powered vector search, a sports news aggregator might repeatedly recommend articles about the same football game due to one initial read. Such limitations can reduce content diversity and user engagement. Additionally, vector search technologies, including vector databases, have a Top-K constraint, so a query on a dataset of millions or billions of data points could potentially overlook thousands of relevant results, overburdening system resources by processing and transmitting extensive data volumes.
The Milvus vector database introduces the Range Search feature, an optimized search approach on top of KNN and ANN algorithms. This method allows for a more balanced retrieval by specifying a distance range between the input and database vectors during a query. This level of precision is particularly advantageous for applications that demand meticulous control over search outcomes, such as data deduplication or copyright infringement detection, ensuring no similar candidates are missed.
Here’s how to utilize the Range Search feature to define search distance parameters:
# Adding radius and range_filter to the search parameters
search_params = {"params": {"nprobe": 10, "radius": 10, "range_filter": 20}, "metric_type": "L2"}
res = collection.search(
vectors, "float_vector", search_params, topK,
"int64 > 100", output_fields=["int64", "float"]
)
In this code snippet, the search is configured to return vectors within a distance of 10 to 20 units from the input vector, providing a precise subset of results.
Summary
In summary, the essence of vector search lies in efficiently processing and retrieving high-dimensional data vectors across various applications. KNN ensures precise data classification by analyzing the proximity of data points in a high-dimensional space, making it invaluable for tasks requiring high accuracy. On the other hand, ANN provides a speed-efficient solution for large datasets by approximating the nearest neighbors, thus balancing performance with computational efficiency. Both algorithms are instrumental in transforming fields like security, e-commerce, healthcare, and more by enhancing the capabilities of machine learning systems to analyze and interpret vast datasets effectively.
While both ANN and KNN algorithms are efficient for vector searches, they have limitations and room for performance improvement. Milvus vector database provides a Range Search feature that allows users to specify the distance between the input vector and vectors stored in Milvus during a query, resulting in more accurate and balanced retrieval results.
Learn More: Deep Dives and Resources
These resources will help you understand vector search technologies and their applications across various domains.
Academic Papers
[1603.09320] Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs by _Yu. A. Malkov and D. A. Yashunin.
[2204.07922] A Survey on Efficient Processing of Similarity Queries over Neural Embeddings_ by _Yifan Wang
[1806.09823] Approximate Nearest Neighbor Search in High Dimensions_ by _Alexandr Andoni, Piotr Indyk, Ilya Razenshteyn
Tutorials and Blogs
 Fendy Feng
Fendy FengFendy Feng is the Product Marketing Manager at Zilliz. She has extensive experience developing and enhancing the impact of open-source projects in various global markets by producing high-quality, tailored content. Before joining Zilliz, Fendy worked as a Content Strategist at PingCAP, a fast-growing E-Series startup renowned for its open-source distributed SQL database.

- The Essence of Vector Search
- What is a K-Nearest Neighbors (KNN) Algorithm?
- What is an Approximate Nearest Neighbors (ANN) Algorithm?
- KNN vs. ANN Searches
- Range Search: Enhancing Vector Search Precision
- Summary
- Learn More: Deep Dives and Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Information Retrieval Metrics
Understand Information Retrieval Metrics and learn how to apply these metrics to evaluate your systems.

Hybrid Search: Combining Text and Image for Enhanced Search Capabilities
Milvus enables hybrid sparse and dense vector search and multi-vector search capabilities, simplifying the vectorization and search process.

Enhancing Efficiency in Vector Searches with Binary Quantization and Milvus
Binary quantization represents a transformative approach to managing and searching vector data within Milvus, offering significant enhancements in both performance and efficiency. By simplifying vector representations into binary codes, this method leverages the speed of bitwise operations, substantially accelerating search operations and reducing computational overhead.