




NLP Essentials: Understanding Transformers in AI
This article will introduce you to the field of Natural Language Processing (NLP) and the breakthrough architecture, the transformer.
Read the entire series
- An Introduction to Natural Language Processing
- Top 20 NLP Models to Empower Your ML Application
- Unveiling the Power of Natural Language Processing: Top 10 Real-World Applications
- Everything You Need to Know About Zero Shot Learning
- NLP Essentials: Understanding Transformers in AI
- Transforming Text: The Rise of Sentence Transformers in NLP
- NLP and Vector Databases: Creating a Synergy for Advanced Processing
- Top 10 Natural Language Processing Tools and Platforms
- 20 Popular Open Datasets for Natural Language Processing
- Top 10 NLP Techniques Every Data Scientist Should Know
- XLNet Explained: Generalized Autoregressive Pretraining for Enhanced Language Understanding
You have probably used ChatGPT (Chat Generative Pretrained Transformer) before. Have you wondered how chatbots like ChatGPT process natural language so well? This article will introduce you to the field of Natural Language Processing (NLP) and the breakthrough architecture, transformer, first launched in 2017 by the “Attention is all you need” paper.
Introduction to NLP
Natural Language Processing (NLP) is a facet of AI that interprets human language, powering tasks like translation, speech recognition, and sentiment analysis. Utilized across various sectors—including healthcare, law, and finance—NLP enhances search functions, social media analytics, and digital assistants, streamlining the handling of vast amounts of unstructured data like text, video, and audio.
As illustrated in Figure 1 below, natural language models have evolved significantly since the 2000s. Early models could convert words into vector embeddings but struggled with context within sequences. For instance, in "I arrived at the bank after crossing the river," the word "bank" could imply a financial institution or a riverbank. With their innovative attention mechanisms, transformers have overcome this problem by contextualizing vectors, leading to a more precise representation of language, a concept we'll explore further in this article.
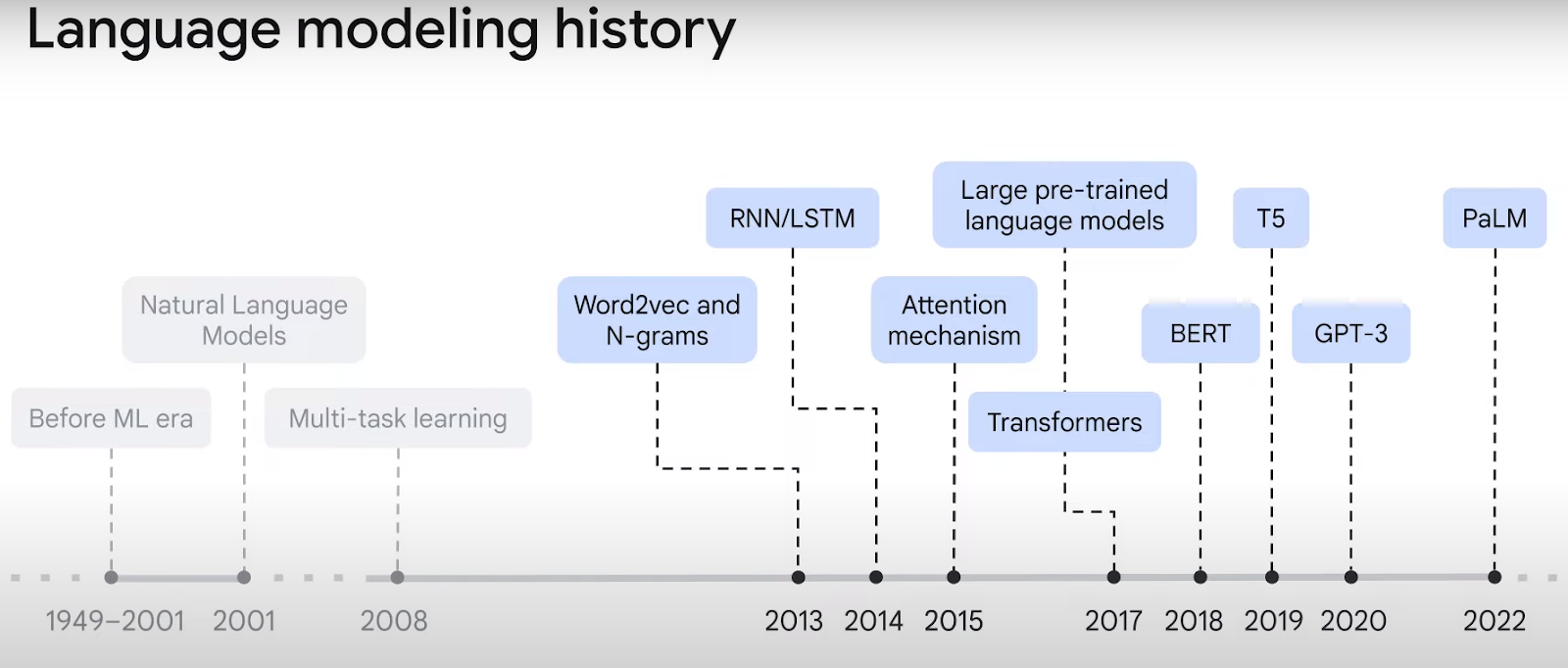
Fig 1. Source: Tutorial video by Google
Understanding Transformer Models
As visualized in Figure two, a transformer is an encoder-decoder model that uses the attention mechanism instead of recurrence or convolutions to transform the input sequence to output.
![]()
Fig 2. Transformer model basic architecture structure (Image by Author)
The authors of the “Attention is all you need” paper evaluated the transformer layers against the convolutional (CNN) and recurrent (RNN) layers based on three criteria shown in Table one. They showed that transformer layers are superior to CNN and RNN layers.
![]()
Table 1. Transformers vs. RNN vs. CNN
Main Components of the Transformer
Embedding and Positional Encoding Layer
A sequence of input and target tokens has to be converted to vectors. However, the attention layers see these sets of vectors with no order. For example, “how are you”, “how you are”, and “you how are" are indistinguishable vectors. The transformer's positional encoding part encodes the position to the embedding vectors.
The Encoder and Decoder
The encoder takes in the embedding tokens of the input sequence. It passes them through self-attention to enable the model to weigh the importance of different tokens within the sequence, resulting in contextualized vector representation. The decoder receives the representation from the encoder together with a start sequence word to output the appropriate output, as visualized in Figure 3.
![]()
Fig 3. Information flow in the transformer (Image by Author)
Self-attention in More Depth
Suppose you wanted to translate a French statement, “Je m'appelle Juma” to English, “My name is Juma”. The encoder will receive the French sentence as input embedding with positional encoding, as shown in Figure 4. Self-attention will break this input into query, key and value (QKV) vectors. Once we have the QKV vectors, we can attend to the most relevant value given a query using formula one below in a process illustrated in Figure 4.
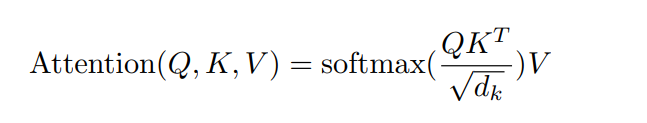
Formula 1. For computing, the attention function on a set of queries simultaneously.
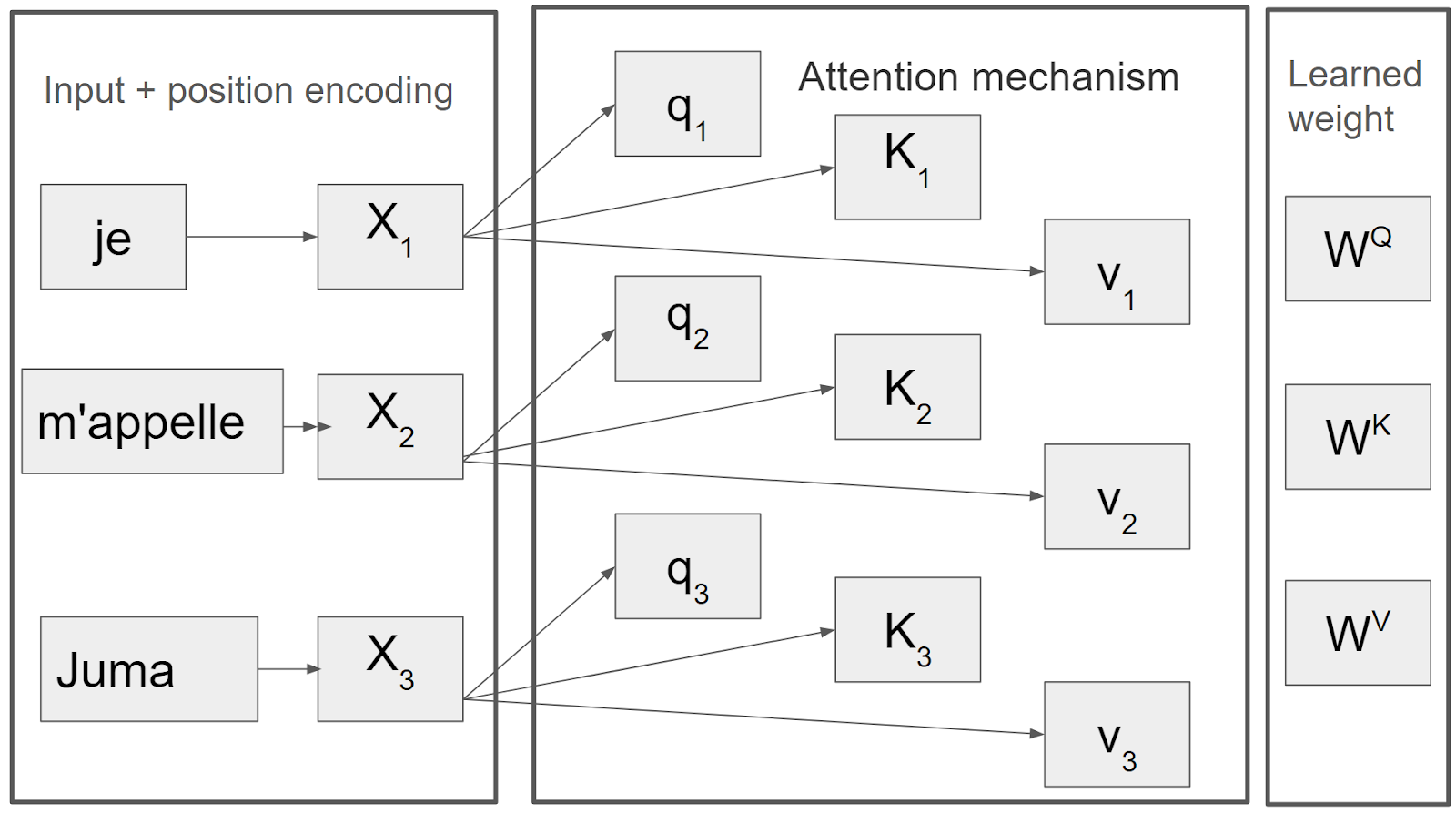
Fig 4. The attention mechanism is the backbone of the self-attention block, breaking down an input sequence into query key and value vectors computed from the transformer's learned weights.(Image by Author)
The decoder takes the context-rich vector from the encoder and begins the translation process using a start-of-sequence token. It first predicts the translation of "Je" to "My" and then generates the subsequent words autoregressively until it completes the translation, as shown in Figure 5.
![]()
Figure 5. Illustration of a translation task using the transformer (Image by Author)
Key Applications and Examples Of Transformers
There are multiple variations of transformer models. Some are based upon both the encoder and decoder, while others on decoder or encoder only.
Generative pre-trained transformers (GPT) stacked transformer decoders to generate text sequences, resulting in chatbots and digital assistants.
Bidirectional encoder representations from transformers (BERT) models is an encoder-only architecture trained to learn deeper context from past and future tokens for word understanding now applied in search engines.
Vision transformer, which repurposed the transformer architecture to process an image as a sequence of patches instead of a grid, is now applied in multi-modal tasks.
Conclusion
The field of NLP has undergone a significant transformation with the advent of the transformer model, a groundbreaking architecture. We delved into the workings of the attention mechanism, highlighting its advantages over traditional methods like RNNs and CNNs, and demonstrated how transformers operate through a practical example. Furthermore, we observed the adaptation of transformer model variants to real-world applications. To further your understanding of transformers and their capabilities, the resources provided in the resources section may be useful in offering implementation details. Zilliz contains more learning resources that may enhance your learning.
Resources

- Introduction to NLP
- Understanding Transformer Models
- Main Components of the Transformer
- Key Applications and Examples Of Transformers
- Conclusion
- Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Top 20 NLP Models to Empower Your ML Application
Learn about the 10 most popular LLMs taking 2023 by storm and another 10 basic NLP models.

Unveiling the Power of Natural Language Processing: Top 10 Real-World Applications
NLP makes our lives much easier. Learn about the top 10 most popular NLP applications and how they have an impact on our lives.

NLP and Vector Databases: Creating a Synergy for Advanced Processing
Finding photos, recommending products, or enabling facial recognition, the power of vector databases lies in their ability to make sense of the complexity of the world around us.