




Sentence Transformers for Long-Form Text
Deep diving into modern transformer-based embeddings for long-form text.
Read the entire series
- Natural Language Processing Fundamentals: Tokens, N-Grams, and Bag-of-Words Models
- Primer on Neural Networks and Embeddings for Language Models
- Sparse and Dense Embeddings
- Sentence Transformers for Long-Form Text
- Training Your Own Text Embedding Model
- Evaluating Your Embedding Model
- Class Activation Mapping (CAM): Better Interpretability in Deep Learning Models
- CLIP Object Detection: Merging AI Vision with Language Understanding
- Discover SPLADE: Revolutionizing Sparse Data Processing
- Exploring BERTopic: A New Era of Neural Topic Modeling
- Streamlining Data: Effective Strategies for Reducing Dimensionality
- All-Mpnet-Base-V2: Enhancing Sentence Embedding with AI
- Time Series Embedding in Data Analysis
- Enhancing Information Retrieval with Learned Sparse Retrieval
- What is BERT (Bidirectional Encoder Representations from Transformers)?
- What is Mixture of Experts (MoE)?
Introduction
In the previous post, we briefly discussed the strengths (and weaknesses) of both dense and sparse embeddings for semantic search before going through a sentiment classification example using the IMDB dataset. Specifically, we used embeddings from a pre-trained RNN (RWKV) and a TF-IDF vectorizer. In this instance, TF-IDF performed slightly better - by about two percentage points.
This post will dive deep into "modern" transformer-based embeddings for long-form text. We'll briefly cover the Sentence-BERT architecture and again use examples from the IMDB dataset to evaluate different transformer-based dense embedding models.
Let's dive in.
What is a sentence transformer?
From transformers to sentence-transformers
We've already covered the anatomy of a neural network, along with how a standard feedforward network can be modified to become a recurrent network. While RNNs model temporal interactions very well, they have a couple of disadvantages that make them difficult to train and use in practice:
- Sensitivity to errors: Many RNNs are trained via teaching forcing, a training strategy where the model's prediction at a one-time step is not used as the input for the next step. Instead, the actual or expected output from the training dataset is used, accelerating and stabilizing training but causing errors to accumulate during inference (since the model was not trained to correct mistakes).
Bias towards recent timesteps: Recurrent networks depend on an input hidden state to process information at each timestep. Because this hidden state is not infinite, among other reasons, this biases the hidden state towards retaining information for recent timesteps. LSTM, GRU, and other special recurrent neural network cells have been developed to tackle this problem with limited success.
Sequential inference: This is perhaps the biggest drawback to recurrent networks. Because RNNs output information one token at a time, it is difficult to parallelize training and inference for a single sample since every timestep output depends on the previous timestep's hidden state.
Enter transformers - a neural network architecture analogous to a large, feedforward neural network (an unrolled RNN) with dense attention across each token column. We'll only briefly recap how transformers work; if you're unfamiliar with the full transformer model and architecture, please check out the original paper or Jay Alammar's Illustrated Transformer blog post first.
When it comes to embeddings, we're almost exclusively interested in the encoder stack of the transformer architecture, which takes a sequence of tokens as an input and outputs a sequence of token embeddings (one embedding per input token). The most popular encoder-only architecture is known as BERT (Bidirectional Encoder Representations from Transformers) and is a conceptually simple but powerful way to pre-train an encoder-only transformer to achieve strong performance on various natural language processing and understanding tasks.
It's important to note that BERT outputs one embedding per input token. This means that, for a sentence with 20 tokens, we get 20 output embeddings, none of which represent the entire input sentence! To remedy this problem, we can average by pooling layer the embeddings across each token, which simply computes the mean of all embeddings:
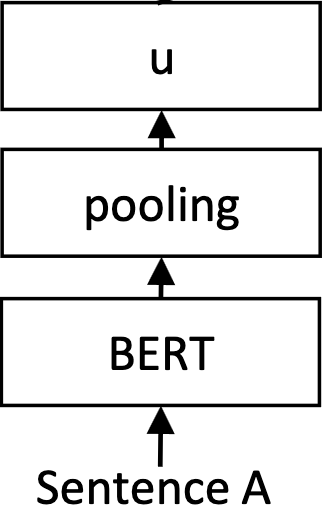 bert pool
bert pool
In pseudocode, that would look something like:
>>> outputs = BERT("this is a sentence")
>>> embedding = np.mean(outputs, axis=0)
As you can imagine, this is not a great way since BERT and other encoder-only transformer models are trained at the token level rather than the sentence level. Since our primary application is a similarity score for search, an alternative is to adopt what's known as a cross-encoder architecture, where two sequences input data are fed into a single BERT model, and then this model outputs a similarity score:
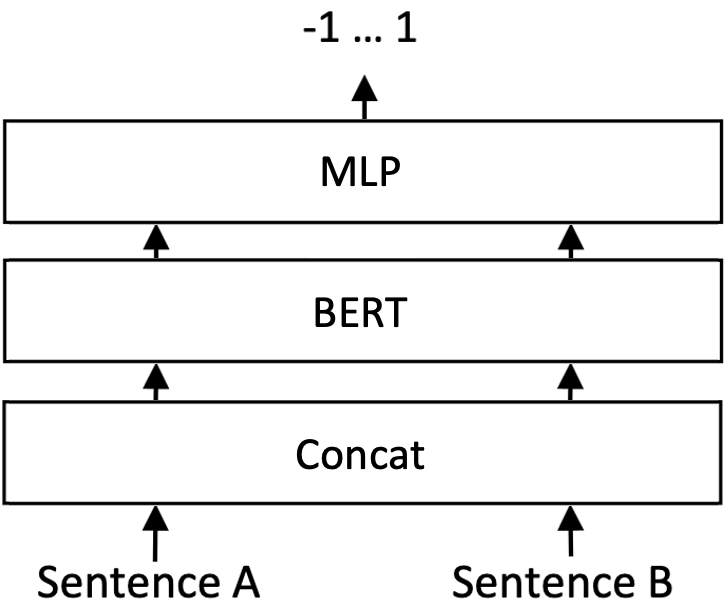
However, this approach is incredibly inefficient - to compute the similarity between an input query sentence and 1 million sentences in my corpus, I would need to run this model a million times!
SBERT vs BERT
Sentence-BERT (SBERT) to the rescue. SBERT is a straightforward but powerful modification of BERT that allows for more semantically rich sequence-level text embeddings. Unlike BERT, SBERT is trained to maximize the similarity between two pooled versions of two sentences such that similar text will correspond to one another, making it extremely useful in applications such various tasks such as text classification and semantic search:
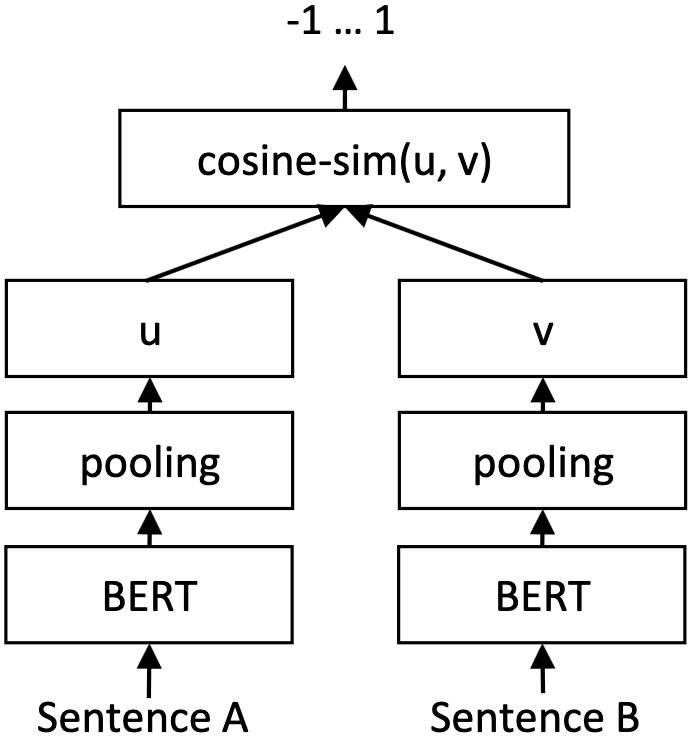
Sentence-BERT is straightforward but powerful. Source
In the above diagram, an identical BERT model given sentence two is run twice, once for sentence A and once for sentence B. Both results are pooled, but a separate fine-tuning step occurs with cosine of sentence similarity used as the loss function. Ground truth values for similar sentence pairs are labeled as 1, while sentences very different from each other are labeled -1.
The SBERT paper was released in 2019 along with the corresponding sentence-transformers library. Although sentence-transformers now contain many more models beyond the original, all of these are based in some way, shape, or form on SBERT.
Let's dive into an example of how to use this powerful library.
Classification example revisited
Let's go back to the IMDB dataset from the previous blog:
from datasets import load_dataset
# load the IMDB dataset
train_dataset = load_dataset("imdb", split="train")
test_dataset = load_dataset("imdb", split="test")
Let's modify our generate_embeddings function to output SBERT embeddings.
from sentence_transformers import SentenceTransformer
# instantiate the tokenizer and model
model = SentenceTransformer("intfloat/e5-small-v2")
def generate_embeddings(dataset):
"""Generates embeddings for the input dataset.
"""
return model.encode([row["text"] for row in dataset])
# generate train and test embeddings
train_embeddings = generate_embeddings(train_dataset)
test_embeddings = generate_embeddings(test_dataset)
Note how, unlike HuggingFace's transformers library, sentence-transformers is meant solely for sentence embeddings. This makes the code much more compact and concise, especially since we don't need to specify torch.no_grad() either.
Let's train a support vector classifier on these embeddings like before.
from sklearn.svm import SVC
# train an linear SVM classifier using the computed embeddings and the labelled training data
classifier = SVC(kernel="linear")
classifier.fit(train_embeddings, train_dataset["label"])
from sklearn.metrics import accuracy_score
# predict on the test set
test_predictions = classifier.predict(test_embeddings)
# score the classifier by % correct
accuracy = accuracy_score(test_dataset["label"], test_predictions)
print(f"accuracy: {accuracy}")
You can check out a full list of sentence-transformers models here: https://huggingface.co/sentence-transformers.
SBERT Performance
In the SBERT paper mentioned above, they discuss how SBERT was tested on many Semantic Textual Similarity (STS) tasks, both unsupervised and supervised. In unsupervised STS, SBERT outperformed InferSent and Universal Sentence Encoder on most datasets, except SICK-R. In supervised STS, SBERT got state-of-the-art on STS benchmark. The model was also tested on more difficult tasks, like Argument Facet Similarity (AFS) corpus, where it performed well on standard evaluation but struggled with cross-topic generalization. And SBERT outperformed previous methods by a lot on Wikipedia Sections Distinction task.
To get more insights into SBERT’s performance, an ablation study was done to see the impact of different pooling strategies and concatenation methods. The study showed that for NLI tasks trained data, pooling has a small impact, but concatenation has a bigger impact. SBERT’s computational efficiency was also tested, and with smart batching, it’s faster than InferSent and Universal Sentence Encoder on GPUs. These tests across many tasks and the ablation study give a full picture of SBERT’s capabilities and design choices, so it’s a state-of-the-art method to generate sentence embeddings.
Wrapping up
In this post, we looked at Sentence-BERT and showed how to use the sentence-transformers library to classify the IMDB dataset, and briefly talked about sentence embeddings for semantic search. Today, many SBERT-like models are part of the sentence-transformers library, with a broad benchmark available via the MTEB leaderboard.
Text embeddings are powerful ways to improve the performance of any retrieval system, and training them on your own data can be a powerful way to boost the performance of your application. In the next tutorial, we'll continue talking about sentence-transformers by fine-tuning our own model.
Additional resources
A History of Embedding | Check out my talk at the Unstructured Data meetup where I go over the history of embeddings, in particular sentence and vision transformers that help us generate multimodal embeddings for Multimodal RAG!
AI Model Gallery. This gallery showcases a number of sentence transformer models like 35-large-v2, all-MiniLM-L12-v2, voyage-large-2 and more!
Check out the other learn articles that cover topics like cosine similarity, natural language processing, and even more details in on training sentence embeddings!
 Frank Liu
Frank LiuFrank Liu is the Director of Operations & ML Architect at Zilliz, where he serves as a maintainer for the Towhee open-source project. Prior to Zilliz, Frank co-founded Orion Innovations, an ML-powered indoor positioning startup based in Shanghai and worked as an ML engineer at Yahoo in San Francisco. In his free time, Frank enjoys playing chess, swimming, and powerlifting. Frank holds MS and BS degrees in Electrical Engineering from Stanford University.
- Introduction
- What is a sentence transformer?
- Classification example revisited
- SBERT Performance
- Wrapping up
- Additional resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Natural Language Processing Fundamentals: Tokens, N-Grams, and Bag-of-Words Models
This post covers Natural Language Processing fundamentals that are essential to understanding all of today’s language models.

CLIP Object Detection: Merging AI Vision with Language Understanding
CLIP Object Detection combines CLIP's text-image understanding with object detection tasks, allowing CLIP to locate and identify objects in images using texts.

What is Mixture of Experts (MoE)?
Mixture of Experts (MoE): a neural network architecture to improve model efficiency and scalability by selecting specialized experts for different tasks.