




Transforming Text: The Rise of Sentence Transformers in NLP
Everything you need to know about the Transformers model, exploring its architecture, implementation, and limitations
Read the entire series
- An Introduction to Natural Language Processing
- Top 20 NLP Models to Empower Your ML Application
- Unveiling the Power of Natural Language Processing: Top 10 Real-World Applications
- Everything You Need to Know About Zero Shot Learning
- NLP Essentials: Understanding Transformers in AI
- Transforming Text: The Rise of Sentence Transformers in NLP
- NLP and Vector Databases: Creating a Synergy for Advanced Processing
- Top 10 Natural Language Processing Tools and Platforms
- 20 Popular Open Datasets for Natural Language Processing
- Top 10 NLP Techniques Every Data Scientist Should Know
- XLNet Explained: Generalized Autoregressive Pretraining for Enhanced Language Understanding
Natural Language Processing (NLP) is a popular field in AI due to its numerous applications, ranging from simple tasks like sentiment analysis to more complex ones like chatbots. When we encounter use cases requiring NLP, we typically have text as input and want a deep-learning model to perform a specific task.
However, deep learning models cannot process text directly. We need to transform the text into a high-dimensional vector, known as an embedding. This embedding is what our deep learning model can understand. In this article, we'll explore the evolution of different methods to convert text into embeddings and discuss how sentence Transformers have revolutionized text embedding techniques.
Word2Vec and Glove: The Early Method
Before the introduction of advanced deep learning models, two common methods were used to transform text into embeddings: Word2Vec and GloVe. Word2Vec is a basic feed-forward neural network with only one hidden layer, trained to learn the embedding of each word. In contrast, GloVe is an algorithm designed to capture the word-to-word co-occurrence in a text corpus.
While these two methods differ in their training approaches, they share a common goal: converting words into embeddings. These embeddings are not just random vectors; they contain semantic information related to the corresponding word. This means that the embeddings of similar words tend to be close to each other in the vector space.
 Embedding in Vector Space | Ruben Winastwan .png
Embedding in Vector Space | Ruben Winastwan .png
As an example, the embedding of the word “dog” would be close to “puppy” in the vector space, while their embeddings might be far from the embedding of the word “crime” due to their dissimilar semantic meanings.
However, using both Word2Vec and GloVe presents at least two significant challenges.
Firstly, Word2Vec and GloVe are word embedding models. Specific techniques are required to obtain embeddings at the sentence level. A common approach is to average the word embeddings using a naive method or employing the TF-IDF method for weighting. Unfortunately, these methods often yield suboptimal results.
Secondly, consider the two sentences: “I walk my dog in the park” and “I park my car in the garage”. Despite the word “park” being used in two different contexts, it will have the same embedding in both sentences.
This limitation shows that both Word2Vec and GloVe struggle to capture the contextual meaning of each word within a sentence, leading to inaccuracies in various tasks.
This is where Transformers come into play.
Transformers in a Nutshell
Transformers are one of the most significant breakthroughs in the AI domain, as they have a flexible architecture that enables them to handle a diverse range of tasks, from text classification to text generation. Leading NLP models such as BERT, XLM-Roberta, and GPT all integrate Transformers as the backbone of their architecture. So, what exactly makes Transformers so powerful?
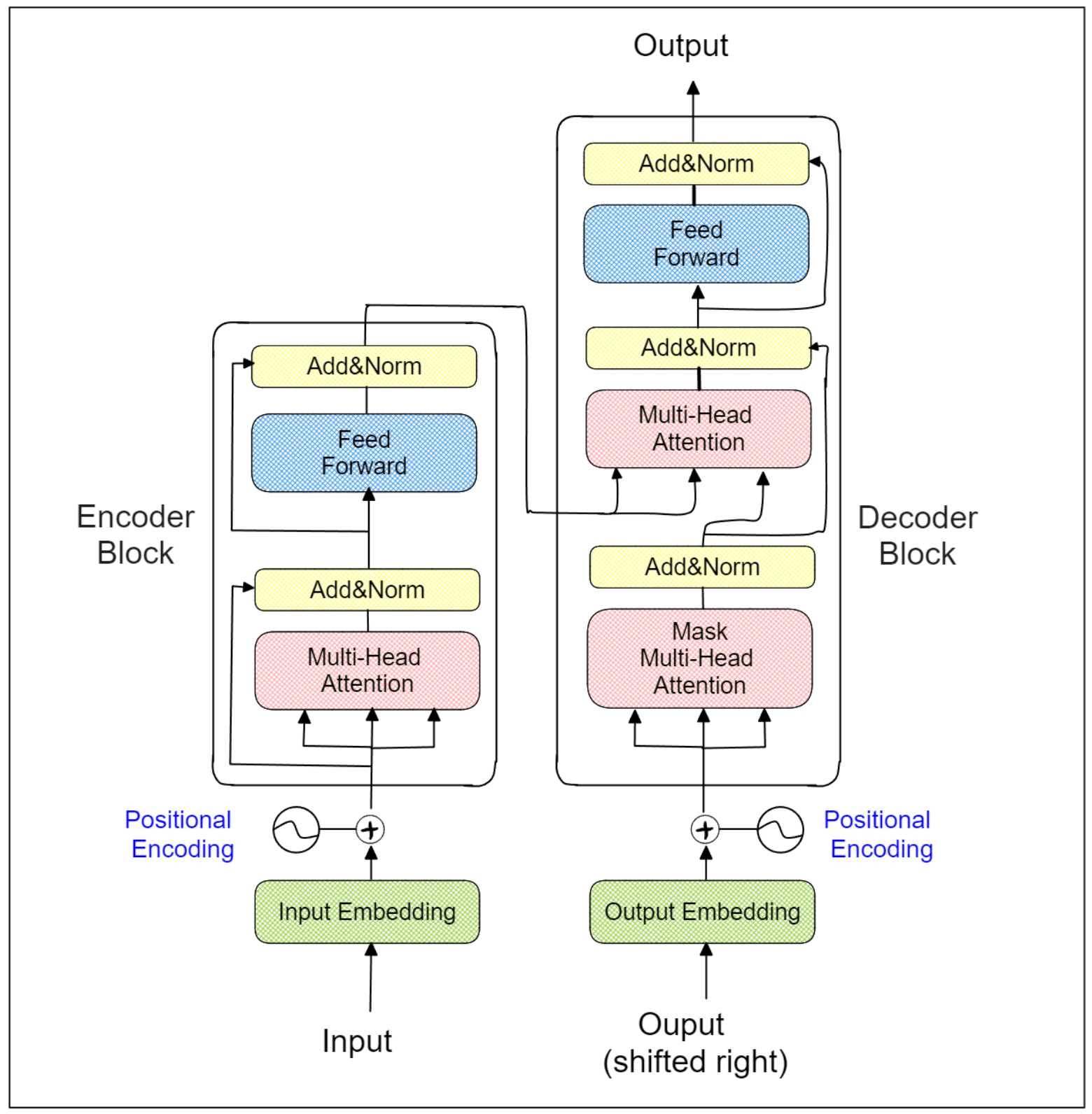 Transformer Architecture | Ruben Winastwan.png
Transformer Architecture | Ruben Winastwan.png
In a nutshell, the Transformers architecture consists of multiple encoder and decoder blocks. Each block includes a specialized attention layer, enabling the model to learn the context of each word (or token) in relation to the entire sentence. As a result, the word “park” in the sentences “I walk my dog in the park” and “I park my car in the garage” will be embedded differently.
The encoder component of Transformers is primarily used for classification tasks, such as sentiment analysis, question answering, and named-entity recognition. State-of-the-art models that leverage Transformer encoders include BERT, DistilBERT, and XLM-Roberta. On the other hand, the decoder component is frequently used for sequence generation. A prime example of a model utilizing Transformer decoders is the GPT family, which serves as the foundation for ChatGPT.
Overview of Sentence Transformers
Sentence Transformers utilize the encoder part of Transformers to generate the embedding of a sentence. Essentially, you can think of it as a fine-tuned version of encoder-based Transformer models like BERT, Roberta, or XLM-Roberta.
To illustrate the inner workings of sentence Transformers, let's consider a BERT-base model as an example. A BERT-base model consists of a total of 12 Transformer-encoder blocks, as illustrated in the diagram below:
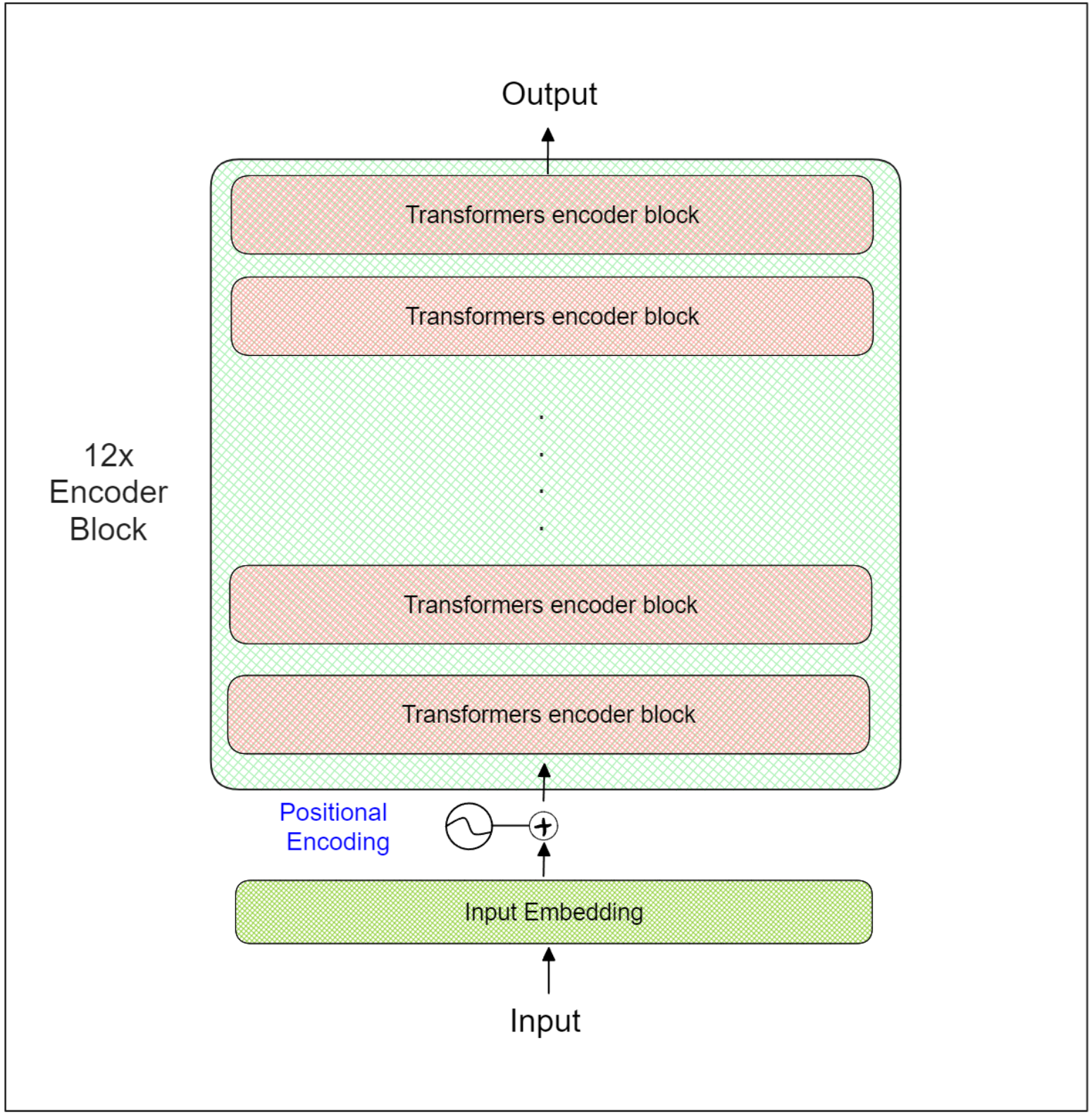 12x Encoder Block | Ruben Winastwan.png
12x Encoder Block | Ruben Winastwan.png
The BERT-base model takes the entire sequence as input. The initial step involves adding two special tokens at the beginning and end of the input sequence, namely [CLS] and [SEP]. For example, the input sequence "I love food" would be transformed into "[CLS] I love food [SEP]."
Next, the input sequence is transformed into a collection of tokens, each representing a word, a sub-word, or even a character. Within the context of BERT, each token represents a sub-word. The tokenized input traverses through an embedding layer, which outputs a 768-dimensional vector for each token.
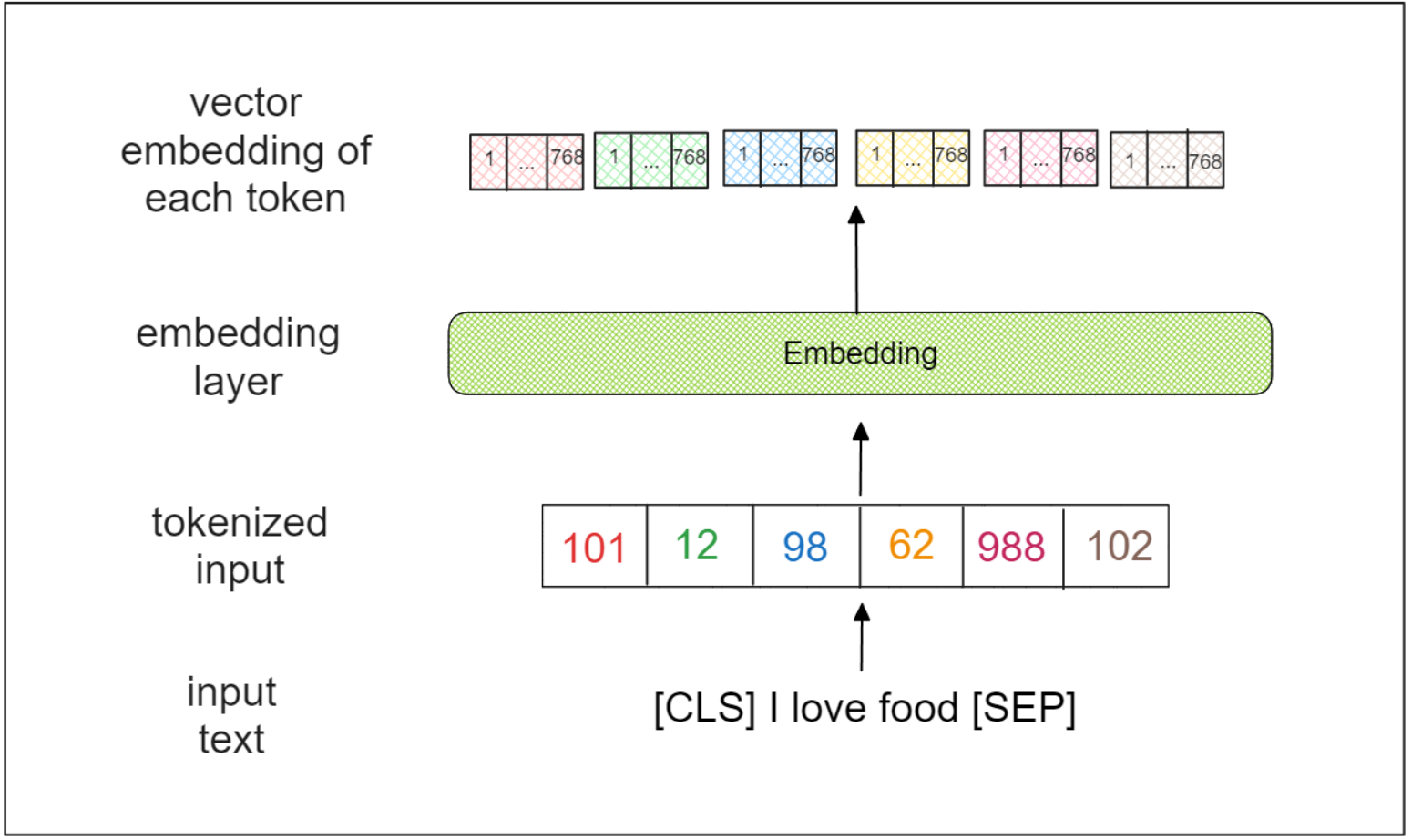 Vector Embedding of each Token | Ruben Winastwan.png
Vector Embedding of each Token | Ruben Winastwan.png
Following this, the vector embedding of each token passes through a sequence of 12 Transformer-encoder blocks. Within each block, the attention layer learns the context of each token in relation to the entire input sequence.
We obtain the learned vector embedding for each token in the final Transformer-encoder block. However, the vector embedding remains at the token level. Now, the question is: How do we get the vector embedding at the sentence level?
Sentence Transformers incorporate an additional pooling layer on top of the last Transformer-encoder block. Three recommended pooling strategies when utilizing sentence Transformers are:
- Directly using only the vector embedding of the [CLS] token.
- Utilizing the mean value of the embedding of all tokens.
- Employing the max-over-time value of the embedding of all tokens.
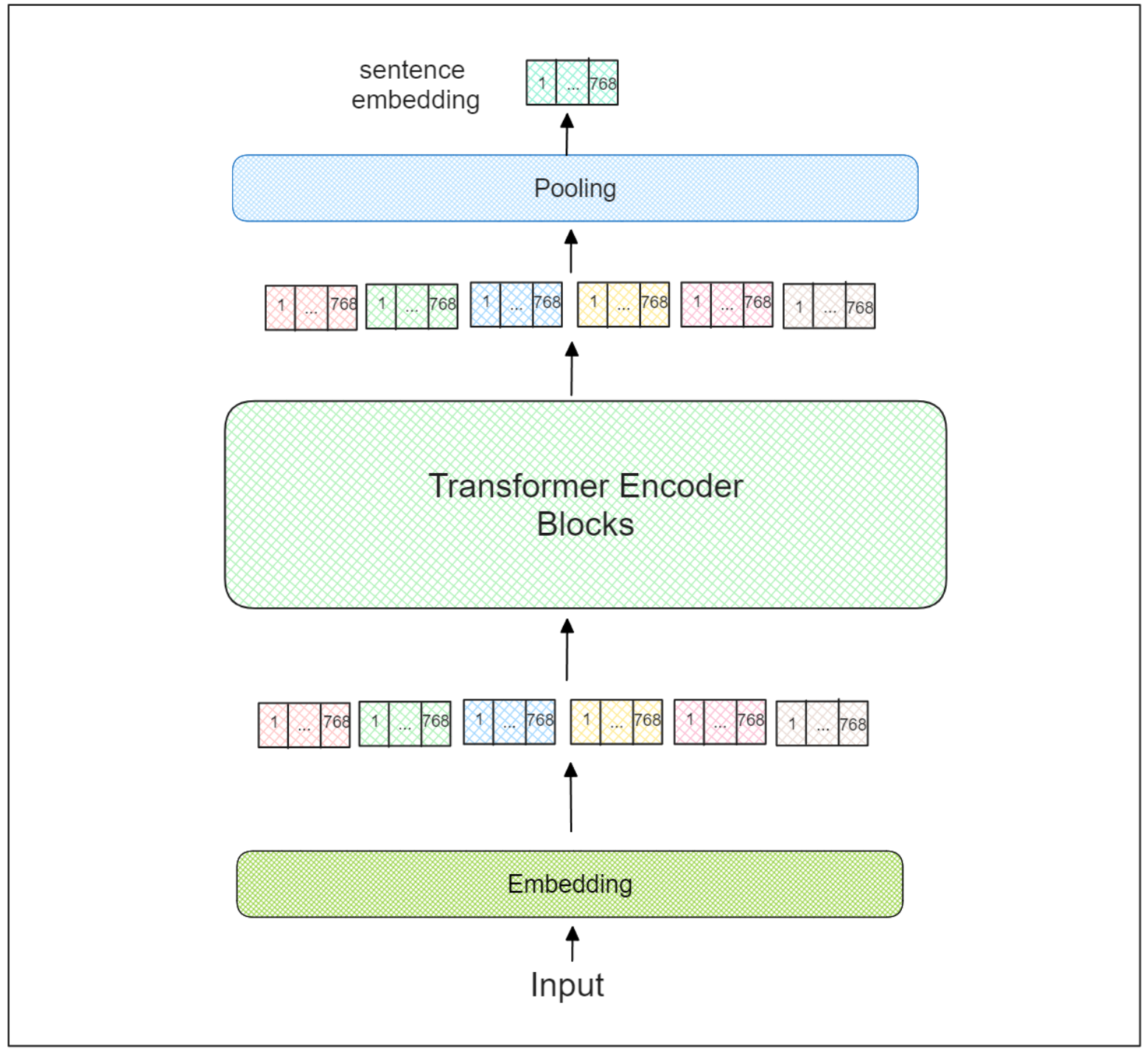 Transfore Encoding Block | Ruben Winastwan.png
Transfore Encoding Block | Ruben Winastwan.png
The outcome of this pooling layer essentially represents the embedding vector of the entire input sequence. This embedding can then be used for various tasks, which we will discuss in the next section.
Implementation of Sentence Transformers
We can use the sentence-level embedding obtained from our sentence Transformers model for a variety of tasks, such as text similarity, text sentiment analysis, information retrieval, document summarization, clustering, and more.
Among these tasks, text similarity and information retrieval stand out as the most common applications for sentence Transformers. Therefore, in this section, we will show you how to implement these two tasks using the sentence-transformers library in PyTorch.
In the following example, we will use a pre trained sentence Transformers model named all-MiniLM-L6-v2. Suppose we wish to obtain the vector embedding of the sentence “I love food”. We can do this easily by invoking the model.encode() method as shown below:
!pip install sentence-transformers
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("all-MiniLM-L6-v2")
# Our sentences to encode
sentences = "I love food."
# Sentences are encoded by calling model.encode()
embeddings = model.encode(sentences)
print(embeddings)
"""
# Output
[ 8.35129712e-03 -1.36965998e-02 5.85979000e-02 7.40111247e-02
-2.90784426e-02 -2.50987854e-04 8.10163021e-02 -5.44814840e-02
3.77929062e-02 7.24284165e-03 2.29576509e-02 -6.07334115e-02
...
...
...
7.86333159e-02 5.17795160e-02 4.13309932e-02 -1.12455534e-02
2.45422567e-03 -1.25547433e-02 1.07740775e-01 1.18402615e-02
3.46895605e-02 7.11588934e-02 -1.47232888e-02 -1.09383598e-01
]
Now we can use the embedding for multiple things. As an example, we can compare this embedding with the embedding of other texts to find the most similar text.
sentences1 = ["I love food"]
sentences2 = [
"I love steak",
"A woman watches TV",
"The new movie is so great",
]
# Compute embedding for both lists
embeddings1 = model.encode(sentences1, convert_to_tensor=True)
embeddings2 = model.encode(sentences2, convert_to_tensor=True)
# Compute cosine-similarities
cosine_scores = util.cos_sim(embeddings1, embeddings2)
# Output the pairs with their score
for i in range(len(sentences2)):
print("{} \\t\\t {} \\t\\t Score: {:.4f}".format(
sentences1[0], sentences2[i], cosine_scores[0][i]
))
"""
# Output
I love food I love steak Score: 0.6131
I love food A woman watches TV Score: 0.0898
I love food The new movie is so great Score: 0.1875
As you can see, the text “I love steak” has the highest semantic similarity to the text “I love food” compared to the other examples. This result makes sense, as steak is a subset of food, whereas the other texts have no thematic association with food.
Another common use case of sentence Transformers is in the information retrieval domain. In this case, we normally store the embedding of individual text in a dedicated database, such as a vector database. Then, we fetch the embedding from the database when we need information about a particular text.
As an example, let’s say we have the following texts in our database:
corpus = [
"A man is eating food.",
"The girl is carrying a baby.",
"A man is riding a horse.",
"A woman is playing violin.",
]
corpus_embeddings = model.encode(corpus, convert_to_tensor=True)
Let's consider a scenario where we have a query: “A man is sitting at the dinner table. What’s he doing?” and our goal is to retrieve the most probable answer from our database. To achieve this, we can compute the similarity between our query and each entry in our database.
query = "A man is sitting at the dinner table. What's he doing?"
# Find the closest 2 sentences of the corpus for each query sentence based on cosine similarity
top_k = min(2, len(corpus))
query_embedding = model.encode(query, convert_to_tensor=True)
# We use cosine-similarity and torch.topk to find the highest 5 scores
cos_scores = util.cos_sim(query_embedding, corpus_embeddings)[0]
top_results = torch.topk(cos_scores, k=top_k)
print("Query:", query)
print("\\nTop 2 most similar sentences in corpus:")
for score, idx in zip(top_results[0], top_results[1]):
print(corpus[idx], "(Score: {:.4f})".format(score))
"""
Output:
Query: A man is sitting at the dinner table. What's he doing?
Top 2 most similar sentences in corpus:
A man is eating food. (Score: 0.4170)
A man is riding a horse. (Score: 0.2206)
From our perspective, the most fitting response to our query would be “A man is eating food”, and this aligns with what the embedding similarity shows.
In recent advancements, the embeddings produced by sentence Transformers can be used to improve the accuracy of the GPT model within a Retrieval-Augmented Generation (RAG) framework. This methodology enables the GPT model to retrieve internal information more effectively, facilitating the generation of responses that are contextually relevant.
Sentence Transformers Training Procedure
If you notice, in the implementation section above, we used a pretrained model to generate the text embedding. However, what should be done if the embeddings produced by the pretrained models are not good enough? Or, in cases where we need to generate the embedding for a text in a foreign language for which pretrained models are unavailable?
This is the scenario where we might need to train a sentence Transformers model on our own.
The training process of a sentence Transformers model is exactly the same as the training process of a regular siamese neural network. It takes two inputs, and the goal is to determine the similarity between these two inputs based on their semantic meaning. Embeddings for dissimilar pairs are pushed farther apart, while those for similar pairs are brought closer.
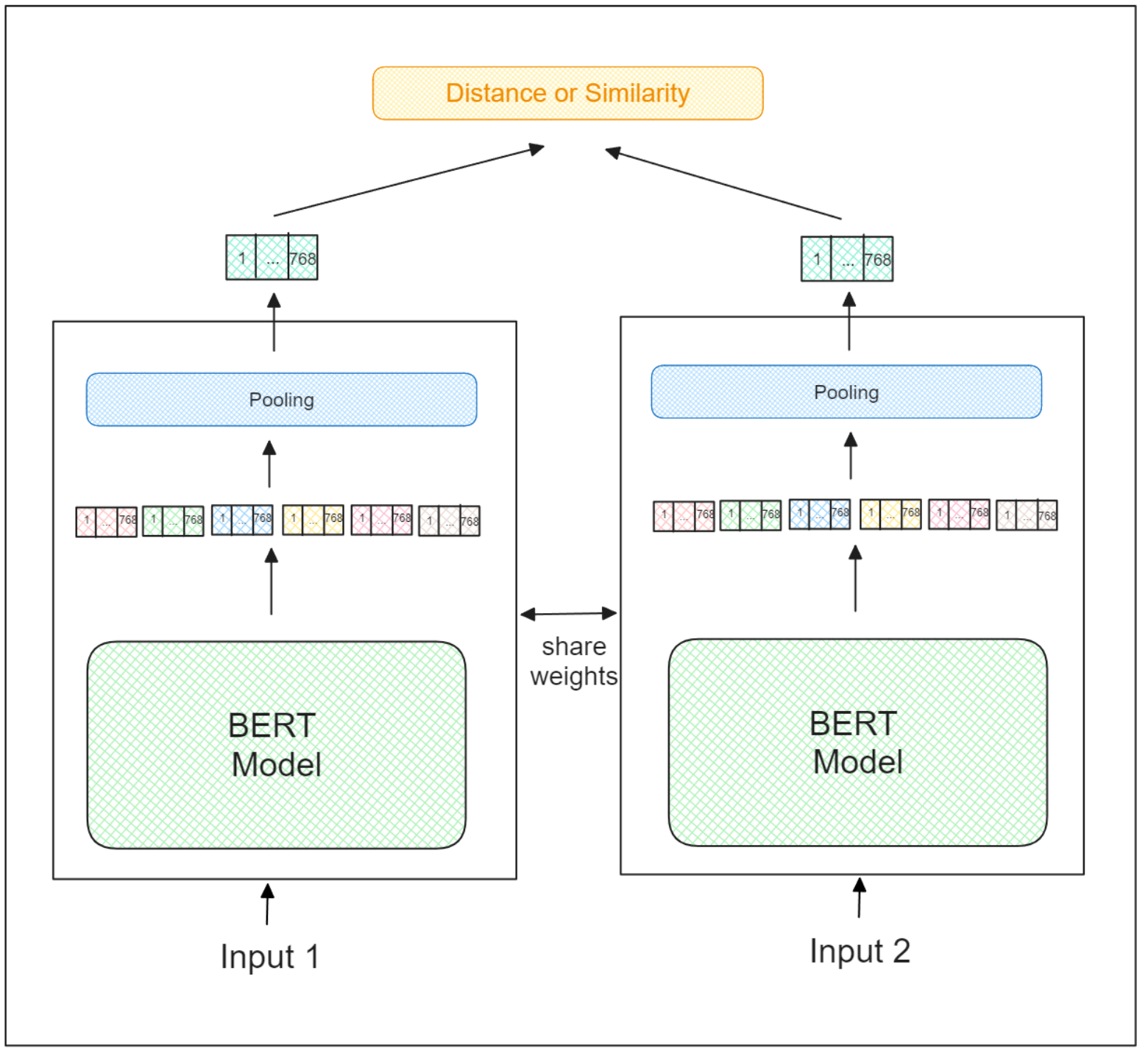 BERT Model input | Ruben Winastwan.png
BERT Model input | Ruben Winastwan.png
Therefore, a good amount of training data is required to train a sentence Transformers model, where each piece of data consists of two sentences as inputs and their corresponding degree of similarity as the label.
However, there isn't a one-size-fits-all approach to set the degree of similarity between two sentences. This is because it largely depends on your objectives and the structure of your data.
For example, you might opt to set a higher similarity between two sentences within the same report compared to two sentences from different reports. Similarly, the similarity between adjacent sentences could be set higher than that between non-adjacent sentences. Also, you could label the training data with binary similarity values; if two sentences contradict each other, the similarity degree should be 0, and conversely, if they align, the similarity degree should be 1.
Challenge and Improvement of Sentence Transformers
In general, the ability of sentence Transformers to generate accurate embeddings at the sentence level surpasses that of more traditional methods like Word2Vec or GloVe, thanks to its advanced Transformers architecture. However, as illustrated in the previous section, the training process for a sentence Transformers model demands extensive effort in preparing the training data. You need to explicitly label the similarity degree between two input texts. To address this challenge, there is currently active research aimed at identifying the best unsupervised methods for training sentence Transformers.
One example is TSDAE, an unsupervised sentence embedding learning technique based on denoising auto-encoders. In this method, noise is introduced into the input text. Then, the encoder maps this noisy input to vector embeddings. The decoder then attempts to reconstruct the original text by eliminating the noise. Finally, we use the encoder as the sentence embedding method.
Another approach is simCSE, a straightforward unsupervised sentence embedding learning technique where the same input text is encoded twice. Due to the dropout mechanism inside the Transformers architecture, the resulting vector embeddings will be positioned slightly differently. The objective then is to minimize the distance between these two embeddings while maximizing the distance to vector embeddings of other input texts in the same batch.
Nevertheless, the research in the area of unsupervised learning to train a sentence Transformers model still has a long way to go, since the performance of the model trained in unsupervised way is still far inferior compared to its supervised version.
Conclusion
In this article, we have learned everything we need to know about the Transformers model, exploring its architecture, implementation, and limitations. Overall, the sentence Transformers model is an important breakthrough in the AI domain, as it enables the generation of sentence-level embeddings, which offer broader applicability compared to token-level embeddings.
Sentence-level embeddings provide more accurate and context-aware representations of text. This makes them invaluable for a wide range of natural language processing tasks, including semantic similarity, information retrieval, semantic search, text classification, and more. Also, the integration of sentence Transformers embeddings with models like GPT in RAG scenarios has demonstrated promising results in improving the accuracy and relevance of the generated responses.
I hope that this article is helpful to get you started with sentence Transformers!

- Word2Vec and Glove: The Early Method
- Transformers in a Nutshell
- Overview of Sentence Transformers
- Implementation of Sentence Transformers
- Sentence Transformers Training Procedure
- Challenge and Improvement of Sentence Transformers
- Conclusion
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Unveiling the Power of Natural Language Processing: Top 10 Real-World Applications
NLP makes our lives much easier. Learn about the top 10 most popular NLP applications and how they have an impact on our lives.

20 Popular Open Datasets for Natural Language Processing
Learn the key criteria for selecting the ideal dataset for your NLP projects and explore 20 popular open datasets.

Top 10 NLP Techniques Every Data Scientist Should Know
In this article, we will explore the top 10 techniques widely used in NLP with clear explanations, applications, and code snippets.